目录
包装类
认识包装类
什么是包装类
Java中包装类是指8种基本数据类型对应的引用类型。
| 基本类型 | 包装类型 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| boolean | Boolean |
| char | Character |
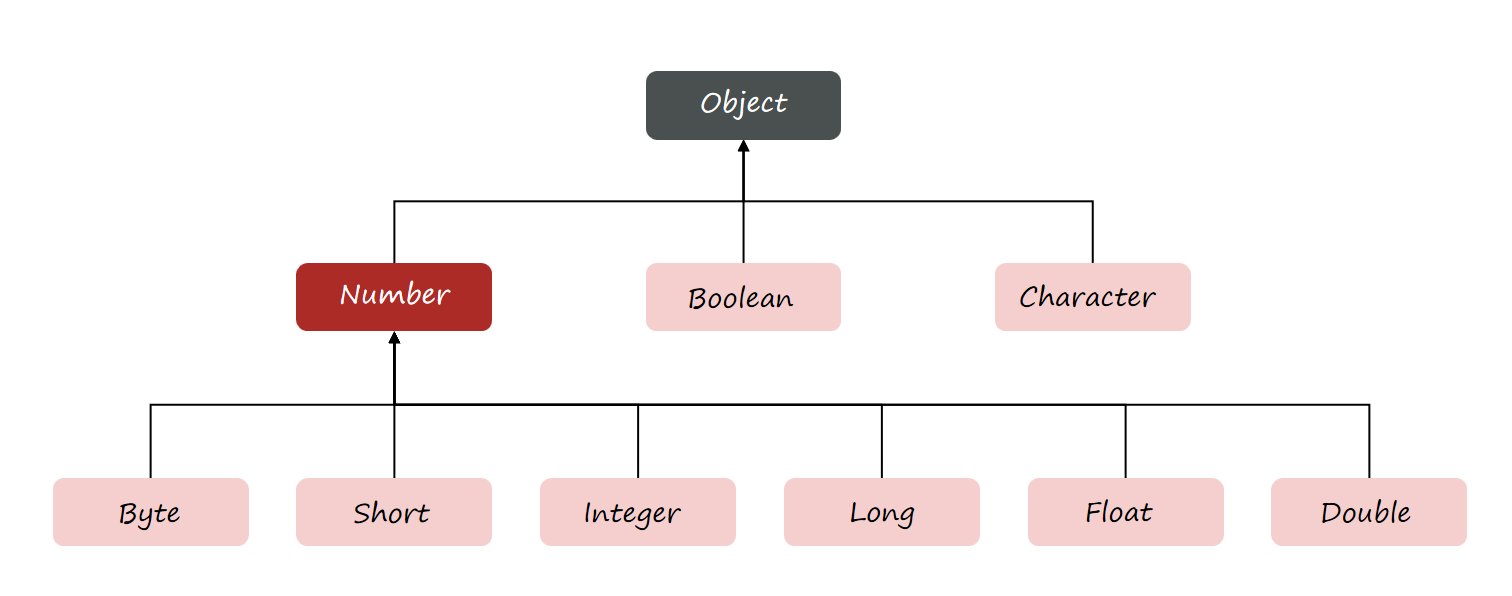
java中包装类的继承关系
为什么要用包装类
1)封装了许多有用的方法
2)支持null值(注册时需求可以不写年龄,但是age不能等于0)
3)支持泛型
做项目写实体类时,我们推荐使用包装类。
使用包装类
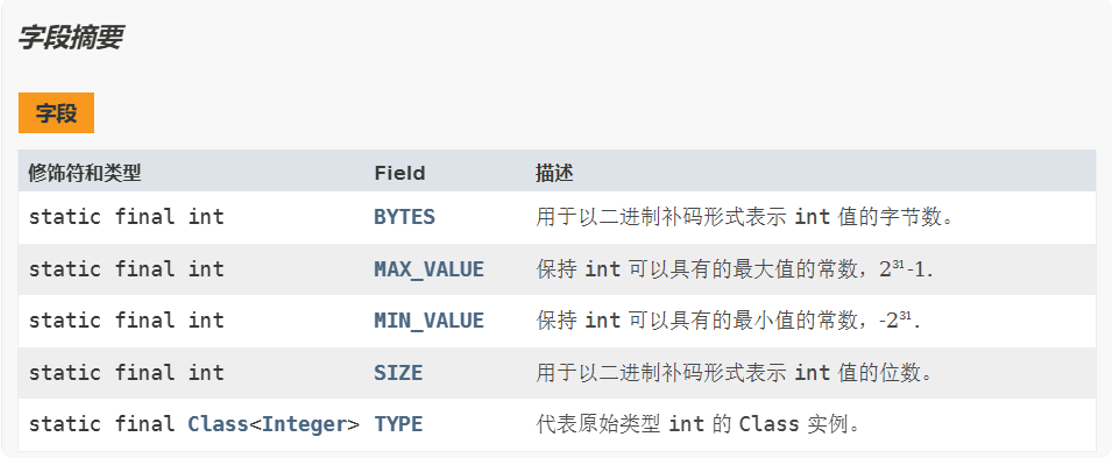
静态常量
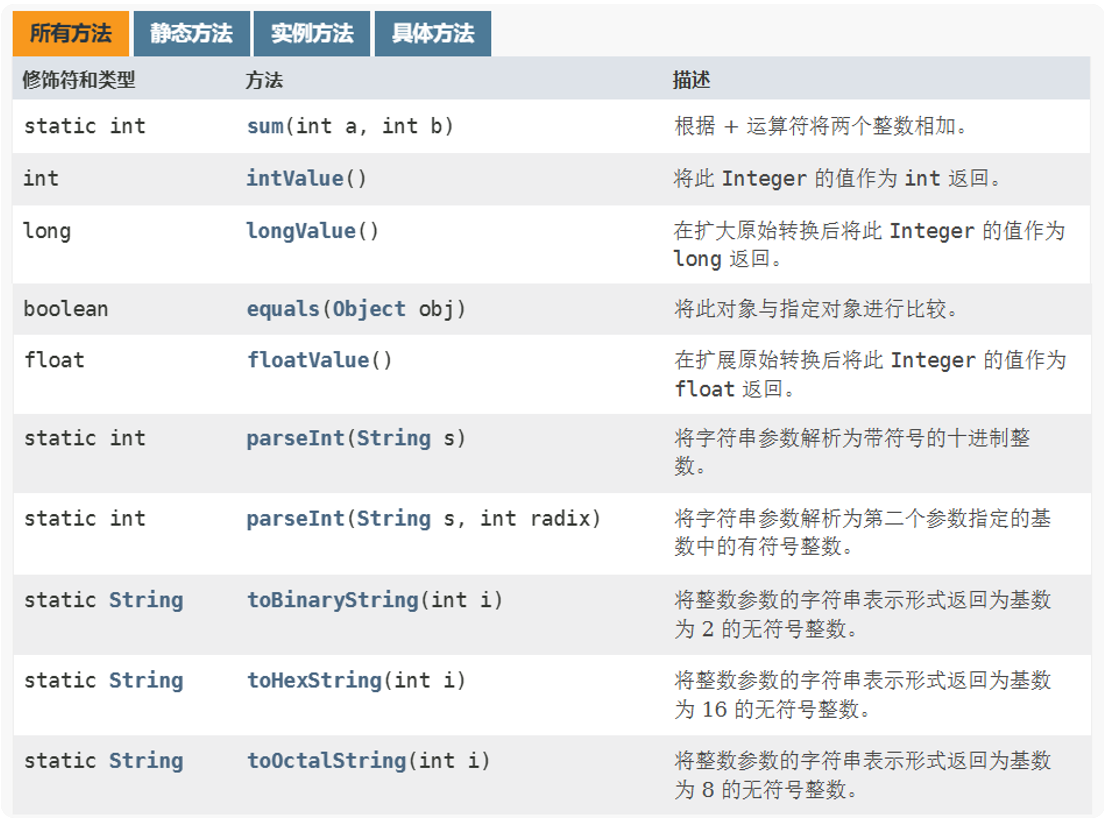
静态方法

常用的成员方法或静态成员方法:
java
public static void main(String[] args) {
// 1.静态常量
System.out.println(Integer.MAX_VALUE); // 2147483647
System.out.println(Integer.MIN_VALUE); // -2147483648
// 2.创建对象
Integer i1 = Integer.valueOf(100);
Integer i2 = Integer.valueOf("100");
System.out.println(i1);
System.out.println(i2);
// 3.调用方法
System.out.println(i1.equals(i2)); // true
int num1 = i1.intValue();
float num2 = i1.floatValue();
System.out.println("num1: " + num1);
System.out.println("num2: " + num2);
// 4.调用静态方法
String hexString = Integer.toHexString(100);
System.out.println(hexString);
int num3 = Integer.parseInt(hexString, 16);
System.out.println("num3: " + num3);
}自动装箱和拆箱
开发中就会存在一个出现非常频繁的需求:把包装类与基本类型互相转换。
JDK5开始Java引入了自动装箱和拆箱机制,实现了包装类与基本类型之间的自动转换。
当我们把基本类型当成包装类来用的时候就是自动装箱。
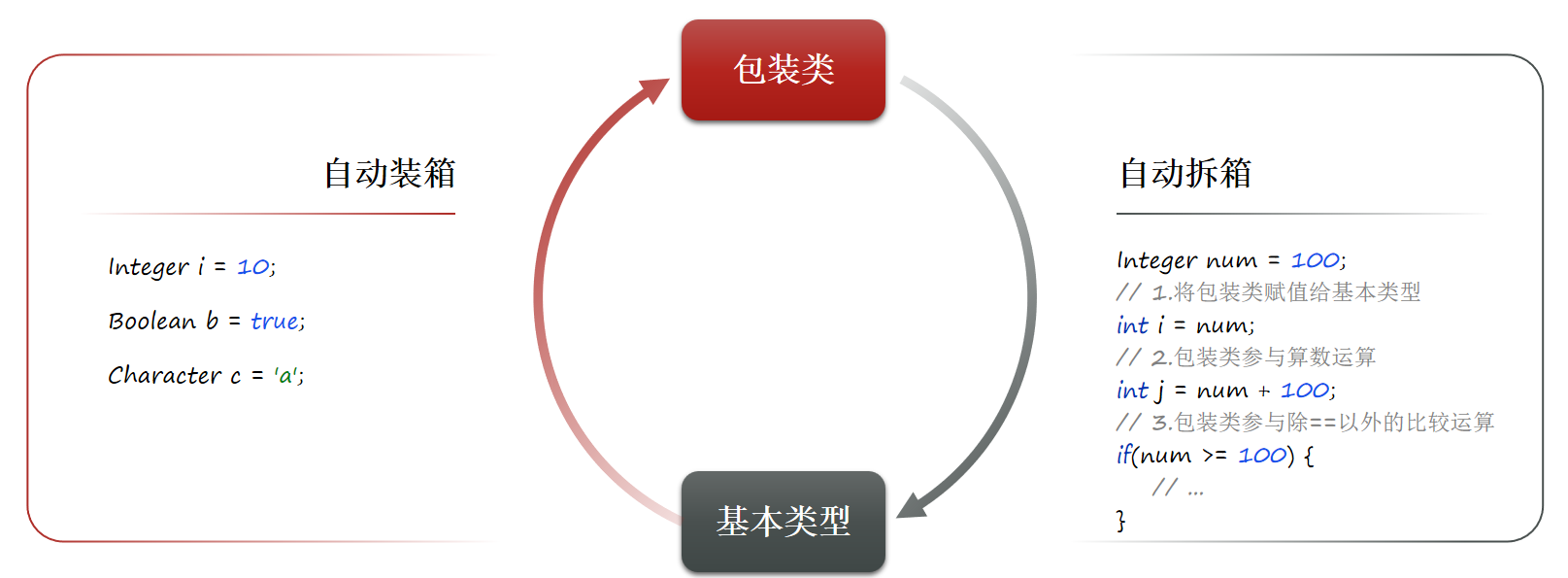
自动装箱,其本质就是jvm帮我们调用了valueOf方法
自动拆箱,本质就是调用了包装类的intValue()方法
注意 :自动拆箱本质是调用了包装类的成员方法,例如Integer中的intValue()方法。
所以包装类的变量如果为null,自动拆箱将触发空指针异常。
享元模式
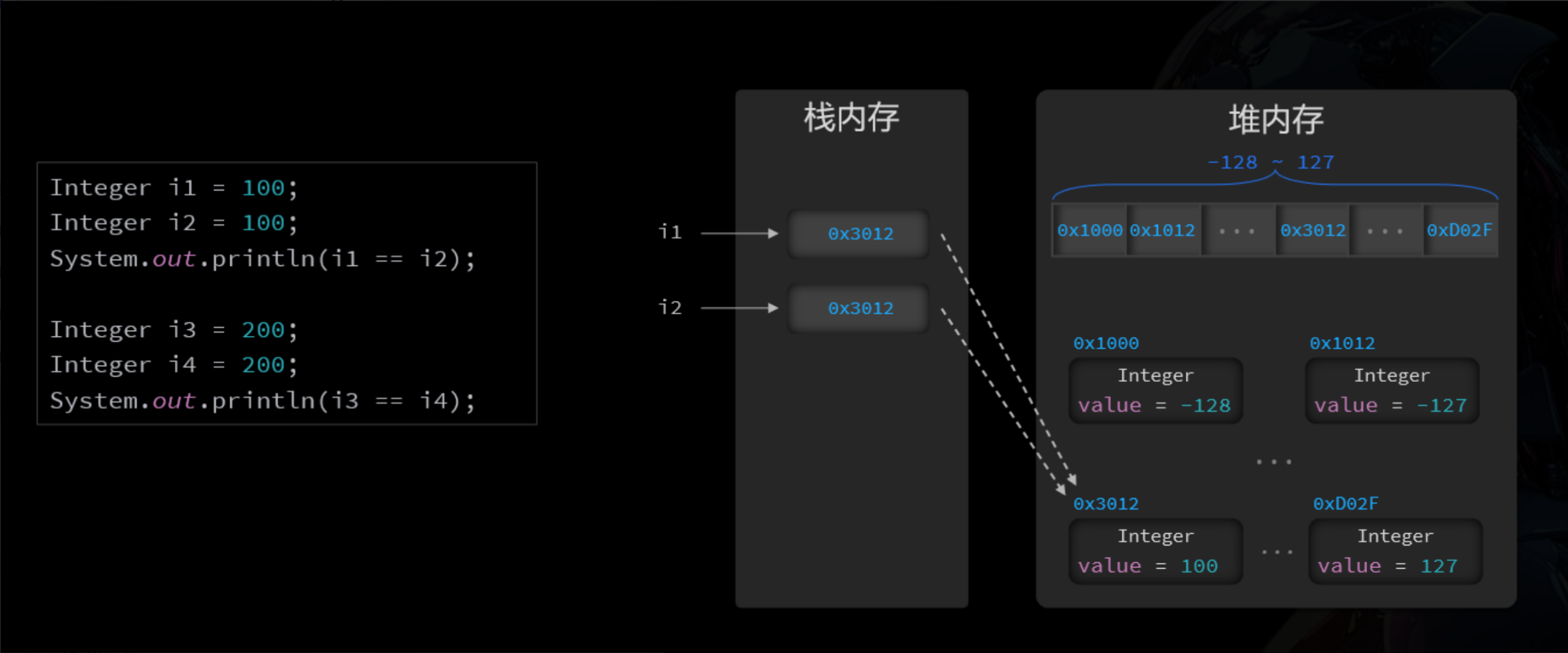
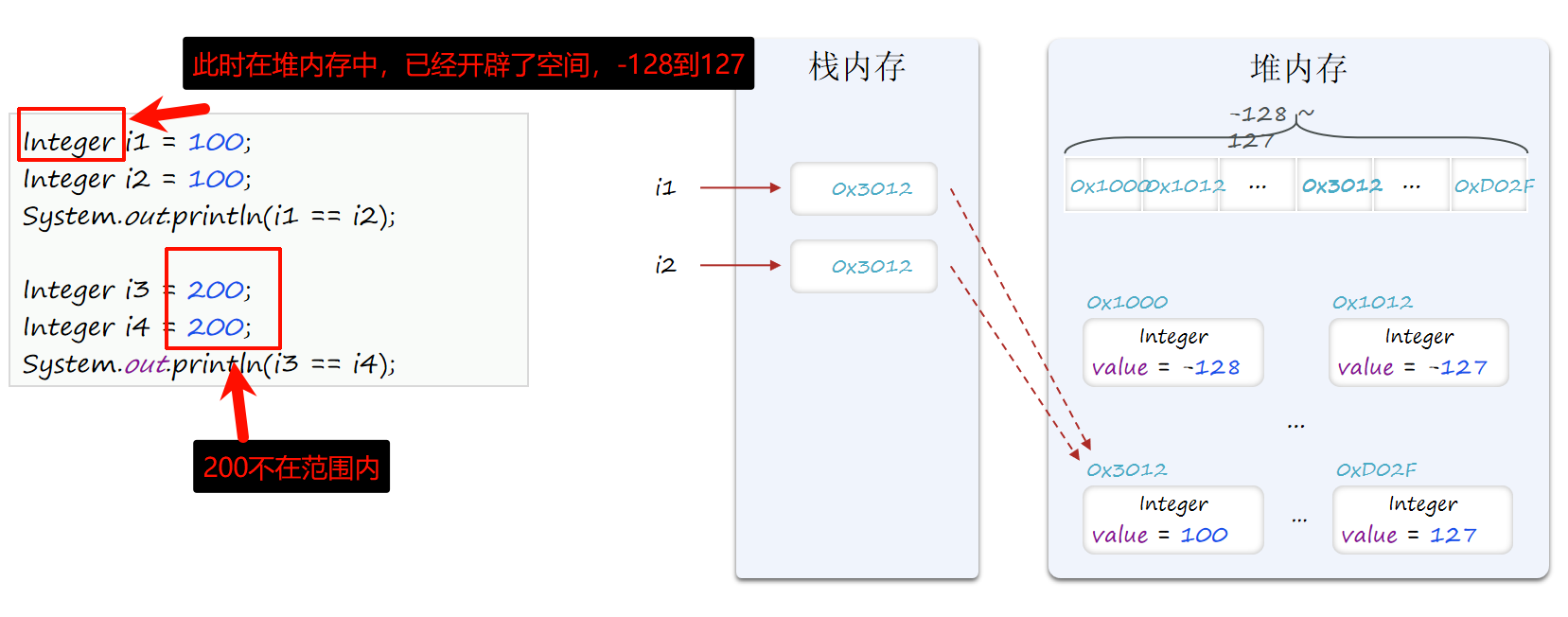
问:以下代码的运行结果是什么?
java
Integer i1 = 100;
Integer i2 = 100;
System.out.println(i1 == i2);//true
Integer i3 = 200;
Integer i4 = 200;
System.out.println(i3 == i4);//false享元模式(Flyweight) 是一种设计模式,其作用是通过共享对象 来减少创建对象的数量,以达到节省内存提高性能 的目的。实现方式就是在第一次创建对象时将对象缓 存起来,下次就不再创建,直接使用。
泛型
泛型类
1)泛型(Generics),也叫参数化类型(TypeParameter),也就是说类型是不确定的,可以像参数一样传递和赋值。
2)类上定义泛型,语法是 类名<泛型类型> { }
java
public class 类名 <泛型> {
// ...
}3)泛型类型可以自定义,但是通常我们有一些约定:
用单个字母表示泛型类型
T:表示Type
E:表示Element(集合多数)
K:表示Key
V:表示Value
类上的泛型不确定,在创建本类对象的时候才确定的
java
public class GenericList<E>{
}
java
GenericList<String> strList = new GenericList<>();
strList.add("word");
泛型可以约束集合类型
泛型无需自己强转,定义的是什么类型,取出来就是什么类型

注意:
定义在类上的泛型是在创建类的对象时才传入类型参数,确定真实数据类型的。所以类上的泛型是属于对象的泛型,在实例化阶段才能使用,它只能用成员变量、成员方法上。
因此,类中的静态方法、静态变量是无法使用类上定义的泛型的。
泛型接口
java
public interface InterfaceName<泛型> {
// 泛型接口中的方法都可以直接使用泛型
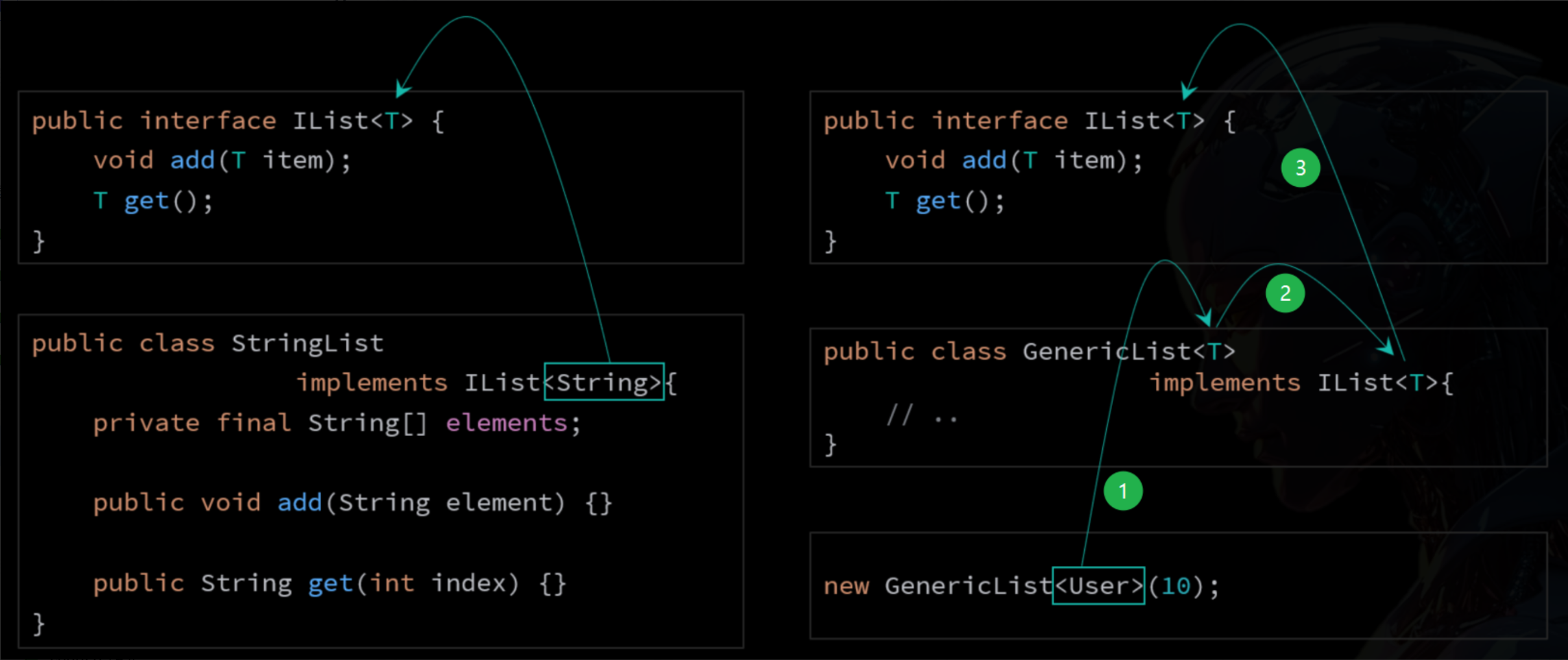
}泛型接口就是在接口名后面定义了泛型的接口。
java
public interface IList<E>{
void add(E e);
E get(int index);
int size();
}泛型接口无法创建对象,只能通过实现类 或实现类的对象来传递泛型类型。
java
public class IntList implements IList<Integer>{
}
java
public class GenericList<E> implements IList<E>{
}
泛型方法
静态方法 无法使用类上定义的泛型,需要在方法上单独声明泛型,这样的方法就是泛型方法。
static <泛型类型> 返回值 方法名(泛型类型 参数)
java
public <泛型> 返回值类型 方法名(参数类型 参数名, ...) {
}注意:泛型方法的泛型要写在返回值类型之前,其它修饰符之后。
定义一个方法,可以接收任意元素类型的数组,并打印其中的元素,可以这样写:
java
public static <T> void printArray(T[] array) {
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
}
java
public static void main(String[] args) {
String[] arr = {"张三", "李四", "王五"};
printArray(arr);
}
public static <T> void printArray(T[] array) {
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
}
在方法调用的时候才确定泛型中的具体类型。
泛型方法不仅在方法内部可以使用泛型,返回值也同样可以是泛型,例如:
java
public static void main(String[] args) {
String[] arr = {"张三", "李四", "王五"};
// 传入String类型数组,返回值就是String
String element = getElement(arr, 1);
System.out.println(element);
Integer[] nums = {10, 20, 30};
// 传入Integer类型数组,返回值就是Integer
Integer num = getElement(nums, 1);
System.out.println(num);
}
// 方法的返回值也使用泛型,在调用方法传参时,泛型确定了,返回值也确定了。
public static <T> T getElement(T[] array, int index) {
if (index < 0 || index >= array.length) {
return null;
}
return array[index];
}
public static <T> void printArray(T[] array) {
// ... 略
}泛型通配符
当使用泛型类或泛型接口时,通常需要给泛型传入真实的数据类型。但如果你使用的时候依然不确定该传递什么数据类型,就可以使用泛型通配符:?
1.无限制通配符,可以理解为object,可以接收任意泛型类型,但无法访问真实类型中的成员,也无法向集合中写入数据
java
public static void print(IList<?> list) {
Object o = list.get(0);
}2.上限通配符,可以理解为Number的某个子类,可以接收任意Number子类类型的泛型,比如Integer、Long
java
public static void print(GenericList<? extends Number> list) {
Number number = list.get(0);
}3.下限通配符,可以理解为Number的某个父类,无法访问Number成员
java
public static void print(GenericList<? super Number> list) {
}集合
数组是内存中的连续空间,如果有其他程序占用内存,会紧接着数组存储。
数组大小不可变,数组查找速度慢
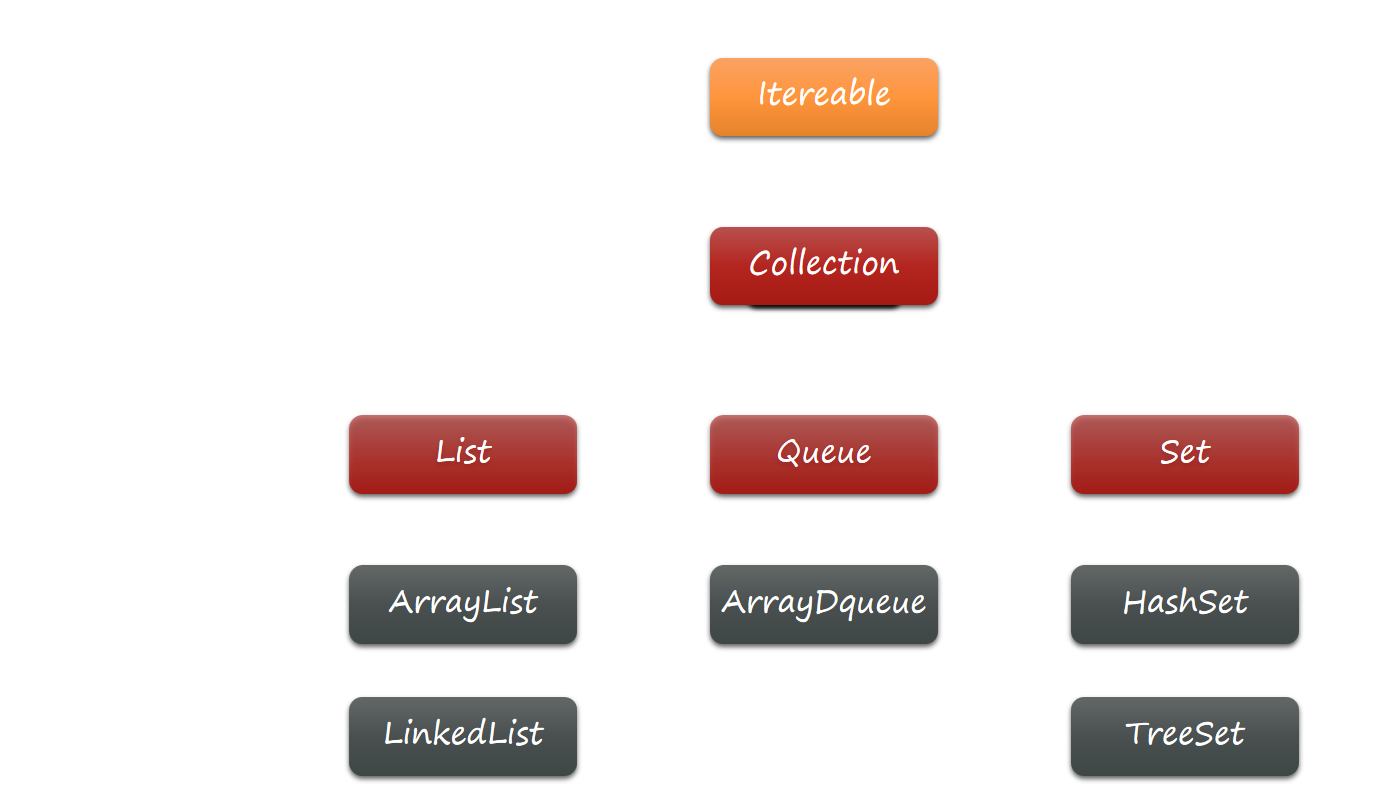
集合框架包含很多种不同的集合,大体上可以分两大类:
-
Collection:每个元素都是单个数据 的集合,也叫单列集合 -
Map:每个元素都是成对数据 的集合,也叫双列集合
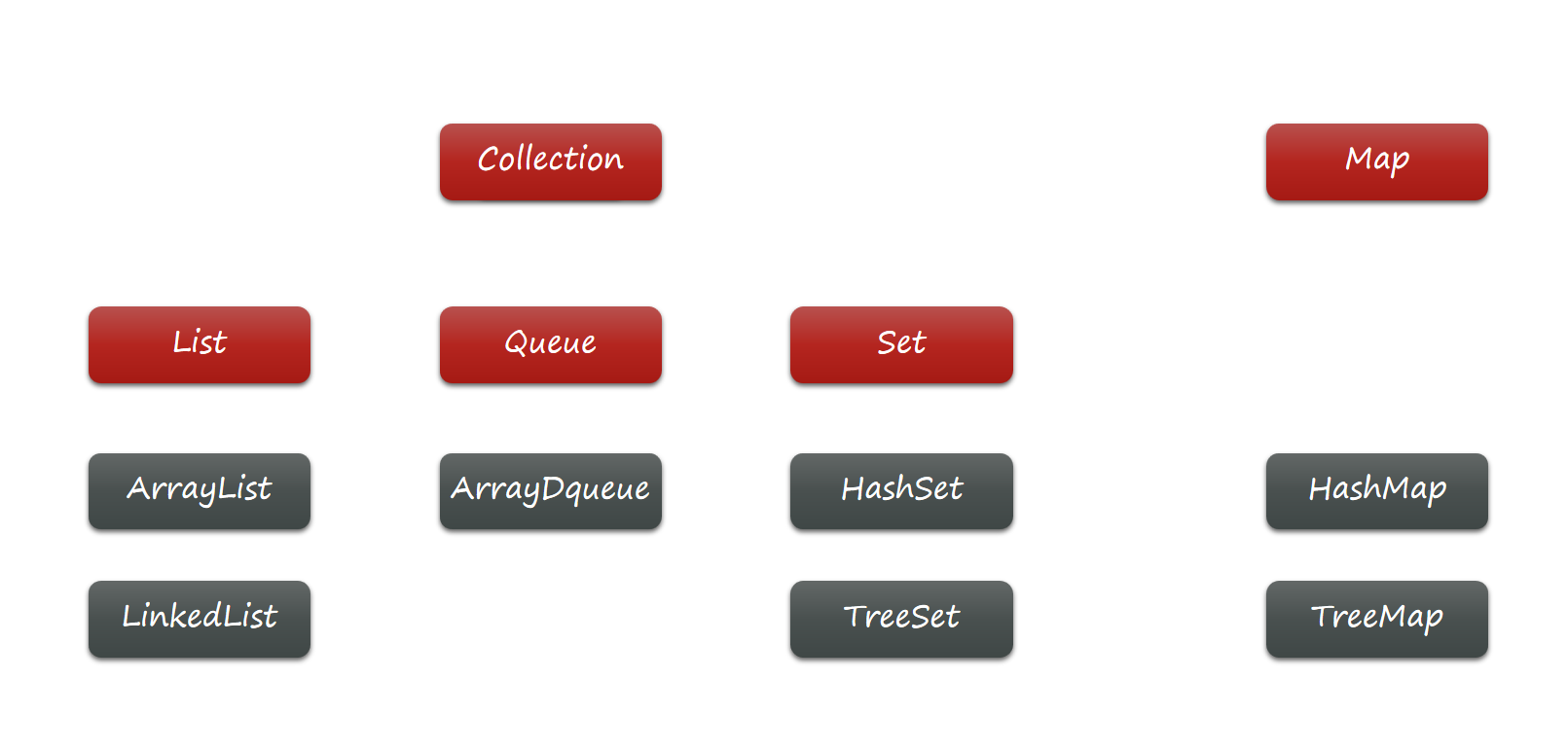
最上面的红色部分全都是接口(Interface),而下方灰色的的则是各种不同的实现类(class)
-
List: 表示元素为固定序列的集合,元素都可以用索引(index)进行随机访问 -
Queue:表示队列类型的集合,强调元素读写的顺序,通常只能按照特定的顺序读写数据 -
Set:表示无重复元素的集合,强调元素的唯一性,元素顺序则无法保证
Collection
通用API
Collection定义了集合中的通用操作方法,包括:
|-------------|-------------------------------------|------------------------------|
| 返回值 | 方法 | 描述 |
| boolean | add(E e) | 添加元素到集合 |
| boolean | remove(Object o) | 从当前集合中移除与指定元素一样的第一个元素 |
| int | size() | 返回集合中的元素个数 |
| boolean | contains(Object o) | 判断当前集合中是否包含指定元素 |
| boolean | isEmpty() | 判断当前集合中是否为空集合 |
| void | clear() | 清空当前集合中所有元素 |
| boolean | addAll(Collection<? extends E> c) | 将指定集合中的所有元素添加到当前集合 |
| boolean | removeAll(Collection<?> c) | 移除当前集合中与指定集合中一样的元素 |
| boolean | retainAll(Collection<?> c) | 保留当前基于与指定集合中都存在的元素(求交集) |
| <T> T | toArray(T\[\] arr) | 返回一个包含集合中所有元素的数组,其类型是指定的数组类型 |
上面表格中加黑加粗的是相对更常用的一些方法。
java
public static void main(String[] args) {
// 1.创建集合对象,这里使用Collection下的一个实现类,ArrayList
Collection<String> c1 = new ArrayList<>();
// 2.添加元素
c1.add("hello");
c1.add("world");
c1.add("java");
System.out.println("初始:" + c1);
// 3.获取集合中元素数量
System.out.println("size: " + c1.size());
// 4.删除元素
c1.remove("world");
System.out.println("删除world:" + c1);
System.out.println("size: " + c1.size());
// 5.判断集合中是否包含某个元素
System.out.println("contains hello: " + c1.contains("hello"));
System.out.println("contains world: " + c1.contains("world"));
// 6.判断集合是否为空
System.out.println("isEmpty: " + c1.isEmpty());
c1.clear();
System.out.println("after clear, isEmpty: " + c1.isEmpty());
System.out.println("after clear: " + c1);
}
java
初始:[hello, world, java]
size: 3
删除world:[hello, java]
size: 2
contains hello: true
contains world: false
isEmpty: false
after clear, isEmpty: true
after clear: []总结:
集合相比数组的最大区别是:集合长度可变,数组长度固定
集合的常用API有哪些:
1)add:添加元素
2)remove:删除元素
3)clear:清空集合
4)size:集合元素数量
5)contains:是否包含指定元素
集合遍历
Iterable(迭代器)
迭代器的方法:
| 返回值类型 | 方法名 | 描述 |
|---|---|---|
| boolean | hasNext() | 如果有未迭代的元素则返回 true,否则返回 false |
| E | next() | 返回下一个未迭代的元素 |
| void | remove() | 从集合中删除最近一次next方法返回的元素,一次next后只能调用一次remove |
每个集合都应该有一个自己的迭代器。每个集合都可以实现自己的迭代方法进行遍历。
java
public interface Iterator<E>{
//判断是否有更多为迭代的元素,有则返回true
boolean hasNext();
//返回下一个要迭代的元素
E next();
//删除上一次迭代的元素,一定用在next后
void remove();
}迭代器遍历
迭代器遍历集合的原理:
在Iterator中会维护一个指向下一个未迭代元素的指针,每次调用next()方法迭代一个元素后,指针都会向后移动一次,直到所有元素都迭代完毕。
因此,使用Iterator的流程通常是这样的:
-
利用
hasNext方法判断是否有未迭代的元素 -
如果有,则用
next方法获取下一个未迭代的元素,此时迭代器指针会移动到集合中的下一个未迭代元素 -
回到步骤1
java
public static void main(String[] args) {
Collection<String> c = new ArrayList<>();
c.add("hello");
c.add("world");
c.add("java");
// 1.获取迭代器对象
Iterator<String> it = c.iterator();
// 2.判断迭代器中是否有未迭代的元素
while (it.hasNext()) {
// 3.获取迭代器中的下一个未迭代元素
String element = it.next();
System.out.println(element);
}
}增强for遍历
语法:
java
for(元素类型 变量名 : 集合) {
// ...
}
java
public static void main(String[] args) {
Collection<String> c = new ArrayList<>();
c.add("hello");
c.add("world");
c.add("java");
for (String str : c) {
System.out.println(str);
}
}List
List是有序 集合,允许重复 元素,而且可以精确控制每个元素在集合中的位置,通过索引插入或访问元素。
常见方法:
| 返回值 | 方法 | 描述 |
|---|---|---|
| boolean | add(int index, E e) | 添加元素到集合中的指定index位置 |
| E | set(int index, E e) | 用指定的元素替换此list中指定位置的元素,返回被替换的元素 |
| E | get(int index) | 返回集合中指定index位置的元素 |
| E | remove(int index) | 删除list中指定位置的元素,并返回该元素 |
| List<E> | subList(int from, int to) | 返回此List中从from到to索引之间的部分,不包含to |
| static List<E> | of(E ... elements) | 返回一个包含任意数量元素的不可修改的List |
java
package com.itheima.p24;
import java.util.ArrayList;
import java.util.List;
public class ListDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("小丽");
list.add("小妮");
list.add("小美");
list.add("小美");
// 1.向指定位置插入元素
list.add(3, "小泰");
// 2.修改指定位置的元素
list.set(0, "小吉");
// 3.利用索引遍历元素
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
// 4.删除指定位置的元素
String remove = list.remove(2);
System.out.println("删除的元素是:" + remove);
System.out.println(list);
}
}输出结果:
java
小吉
小妮
小美
小泰
小美
删除的元素是:小美
[小吉, 小妮, 小泰, 小美]可以看出:
-
List集合可以有重复元素
-
List集合可以用索引操作
-
List集合遍历出元素的顺序是确定的
-
List除了可以用迭代器、增强for,也可以用fori遍历
需要注意的是,如果我们使用List.of创建List集合,创建好的集合是不可变的 ,也就是说不能修改、删除、添加集合中的元素是只读的。
java
List<String> list2 = List.of("hello", "world", "java");
list2.add("java");
list2.remove("java");
list2.set(0, "java");程序会报错!!!

Set
Set是无序集合 ,不允许 重复元素,无法通过索引 插入或访问元素。
| 返回值 | 方法 | 描述 |
|---|---|---|
| static Set<E> | of(E ... elements) | 返回一个包含任意数量元素的不可修改的Set |
Set集合最常见的实现类是HashSet。
创建Set集合的元素,一定要实现equals方法,否则集合不知道是否重复。代码示例中String类型是引用类型,需要用equals进行比较,这是一个隐含条件。
java
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("小黑");
set.add("小马");
set.add("小马");
set.add("小珍");
set.add("小珍");
set.add("小牛");
set.add("小牛");
System.out.println(set);
for (String s : set) {
System.out.println(s);
}
}
java
[小珍, 小马, 小牛, 小黑]
小珍
小马
小牛
小黑可以看出,尽管我们向Set集合中重复添加了大量元素,但最终重复元素都只能存储一份,证明了Set集合是不允许重复元素的。
另外添加元素的顺序是:"黑,马,珍,牛",最终打印的却是:"珍,马,牛,黑",可见元素遍历顺序与添加顺序不一致。
当使用Set.of方法创建Set集合时,如果元素有重复会直接报错:
java
Set s = Set.of("小黑", "小马", "小马", "小珍", "小珍", "小牛", "小牛");
System.out.println(s);程序会报错!!!

总结:
List集合有什么特点?
有序:存储和遍历的顺序一致
有索引:可以用索引操作元素
允许重复:允许存储重复元素
Set集合有什么特点
无序:存储和遍历的顺序不一定相同(大概率是不同)
无索引:不能用索引操作元素
不允许重复:不允许存储重复元素(存储是Java对象时需要重写equals和hashcode)
Map
Collection集合存储的元素都是单个值,而Map集合的元素则是成对出现,每一个元素都要包含key和value两部分,或者换句话说,Map中的元素是key和value的键值对。
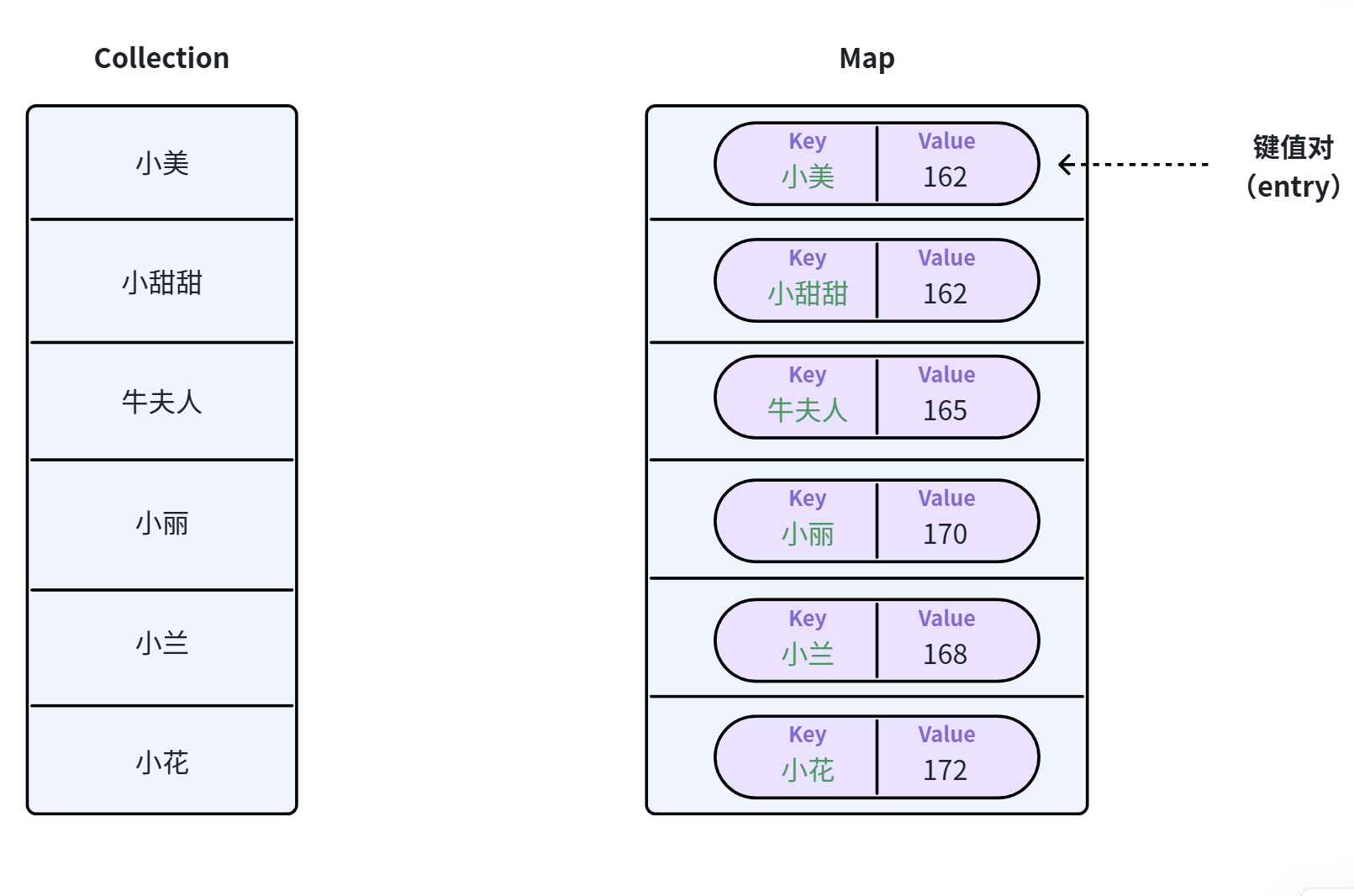
Map集合可以看作是把key与value之间建立了一种映射关系,因此Map中的大多数操作都是与key有关:
-
根据key查询value
-
根据key删除键值对
-
...
Map集合有很多不同实现类,其底层实现原理也各不相同:
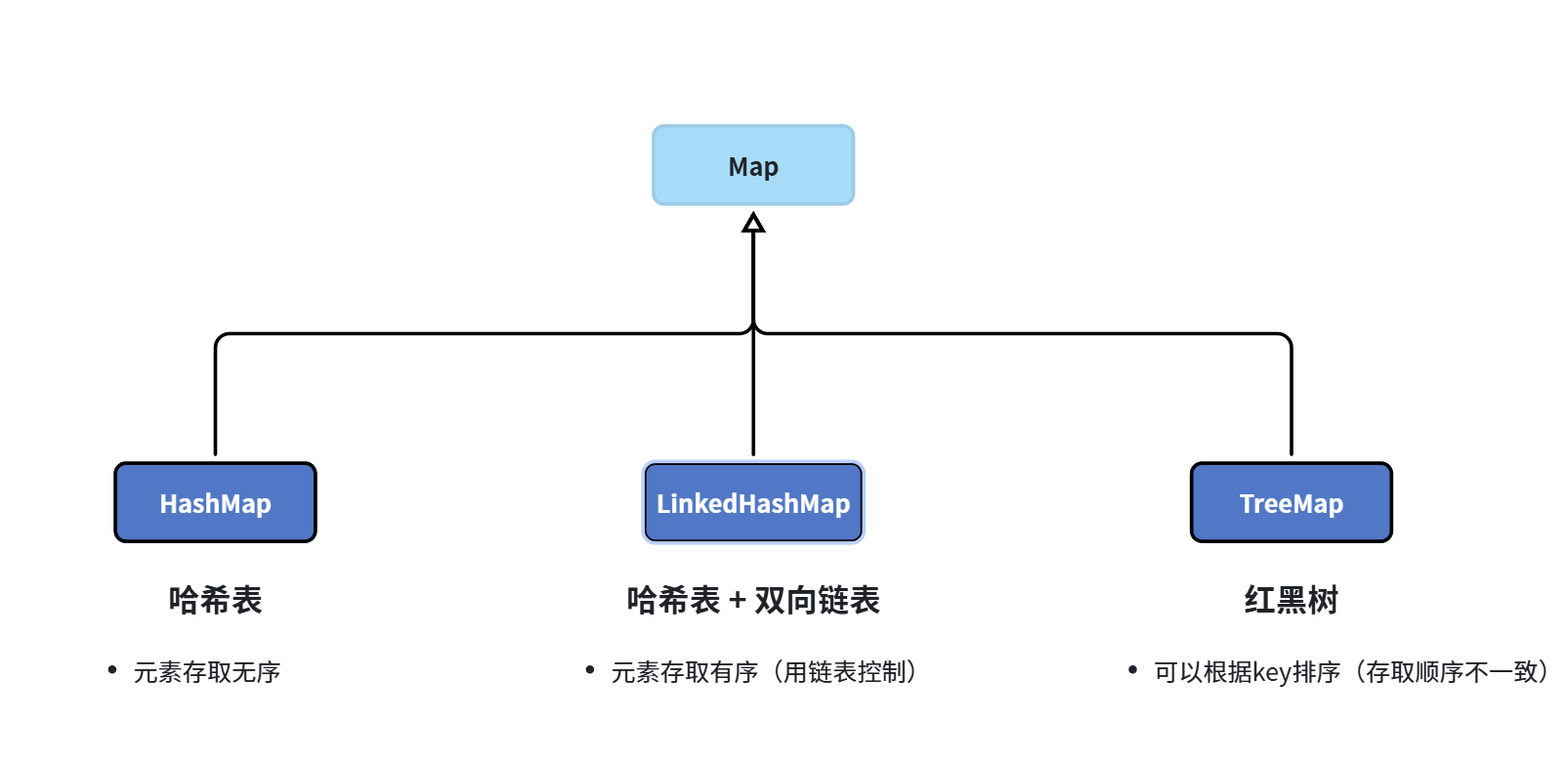
常用API
| 返回值 | 方法 | 描述 |
|---|---|---|
| V | put(K key, V value) | 将指定的value与指定的key关联,如果key已经存在则覆盖旧值并返回 |
| V | get(K key) | 返回指定key对应的value,不存在则返回null |
| V | remove(Object key) | 从map中删除指定key对应的键值对,并返回其value |
| int | size() | 返回此map中键值对的数量 |
| boolean | containsKey(K key) | 判断此map中是否包含指定的key的映射 |
| boolean | isEmpty() | 判断此map是否为空 |
| void | clear() | 清空此map中的所有键值映射 |
java
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("乔峰", "阿朱");
map.put("杨过", "小龙女");
map.put("郭靖", "黄蓉");
map.put("张无忌", "周芷若");
map.put("张无忌", "赵敏");
map.put("令狐冲", "东方不败");
System.out.println(map);// {令狐冲=东方不败, 杨过=小龙女, 乔峰=阿朱, 郭靖=黄蓉, 张无忌=赵敏}
String value = map.get("张无忌");
System.out.println(value); // 赵敏
System.out.println("contains: " + map.containsKey("张无忌")); // contains: true
map.remove("张无忌");
System.out.println("contains: " + map.containsKey("张无忌")); // contains: false
System.out.println("isEmpty: " + map.isEmpty()); // false
map.clear();
System.out.println("isEmpty: " + map.isEmpty()); // true
}Map集合具备以下特点:
-
Map的键(key)不可重复
-
Map的值(value)可以重复
-
每一个key有且只有一个value与之对应
遍历
Map集合是双列集合,存储的是键值对信息,所以没有办法用传统方式遍历。
| 返回值 | 方法 | 描述 |
|---|---|---|
| Set<K> | keySet() | 返回包含此map中所有key的Set集合 |
| Collection<V> | values() | 返回包含此map中所有value的Collection集合 |
| Set<Map.Entry<K,V>> | entrySet() | 返回此map中所有的键值对的Set集合 |
-
keySet :返回的是
Map中所有key的Set集合,这是因为key是不可重复的,而Set刚好具备不可重复的特性 -
values :返回的是
Map中所有value的集合,这里用Collection,因为value值是可重复的,不能用set -
entrySet :返回的则是键值对的集合,注意,这里键值对是一个整体,是
Map的一个内部类型Map.Entry,其中既有键,也有值
我们遍历Map集合也就有了三种不同的方式。
1、keySet
keySet方法返回的是Map中所有key的Set集合,而拿到key以后,我们就可以调用Map的get方法,根据key获取value了
java
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("乔峰", "阿朱");
map.put("杨过", "小龙女");
map.put("郭靖", "黄蓉");
map.put("张无忌", "赵敏");
map.put("令狐冲", "东方不败");
loopByKeySet(map);
}
private static void loopByKeySet(Map<String, String> map) {
// 1.获取所有的key
Set<String> keySet = map.keySet();
// 2.遍历key
for (String key : keySet) {
// 3.根据key获取value
String value = map.get(key);
System.out.println(key + " ♥ " + value);
}
}2、values
values方法返回的是Map中所有value的集合。由于Map是从key到value的映射,我们可以根据key找value,但反过来就不行。
因此,使用values方法你只能拿到所有value,拿不到key。
java
private static void loopByValues(Map<String, String> map) {
// 1.获取所有的value
Collection<String> values = map.values();
// 2.遍历value
for (String value : values) {
System.out.println("? ♥ " + value);
}
}3、entrySet
entrySet方法返回的则是键值对 的集合,注意,这里键值对是一个整体 ,是Map的一个内部类型Map.Entry,其中既有键,也有值,也提供了获取键和值的方法。
java
public interface Map<K,V> {
Set<Map.Entry<K, V>> entrySet();
// ...
interface Entry<K, V> { // 在类的内部也可以定义类,我们称为内部类
K getKey();
V getValue();
// ...
}
}由于Map中的每一个键值对都是唯一的,所以,entrySet方法的返回值是一个Set集合。而集合的元素类型就是Map中的Entry类型,写作Map.Entry.
另外它与Map一样有两个泛型,K表示key的类型,V表示value的类型,因此完整写法就是Map.Entry<K,V>。如果再把它放到Set<>集合的泛型中,就是Set<Map.Entry<K,V>>。
拿到了Set集合,我们就能遍历它,获取其中的每一个Entry,再调用Entry中的getKey和getValue获取键和值。
java
private static void loopByEntrySet(Map<String, String> map) {
// 1. 获取所有的键值对(Map.Entry)
Set<Map.Entry<String, String>> entrySet = map.entrySet();
// 2. 遍历集合,获取每一个键值对
for (Map.Entry<String, String> entry : entrySet) {
// 3. 获取键值对中的键和值
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + " ❤ " + value);
}
}Map最强大的功能就在于根据key可以快速查找Value,例如,我需要实现根据id查找Girl的功能。
如果是用Collection集合,你只能遍历整个集合,一个个匹配集合中的元素,直到找到id匹配的为止
java
private static Girl searchInCollectionById(int id) {
List<Girl> list = List.of(
new Girl(1, "小花", 162, "A"),
new Girl(2, "小美", 162, "D"),
new Girl(3, "小丽", 168, "C"),
new Girl(4, "小琪", 170, "B")
);
for (Girl girl : list) {
if (girl.getId() == id) {
return girl;
}
}
return null;
}如果是用Map集合,只需要一个get方法:
java
private static Girl searchInMapById(int id) {
Map<Integer, Girl> map = new HashMap<>();
map.put(1, new Girl(1, "小花", 162, "A"));
map.put(2, new Girl(2, "小美", 162, "D"));
map.put(3, new Girl(3, "小丽", 168, "C"));
map.put(4, new Girl(4, "小琪", 170, "B"));
return map.get(id);
}