- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
前言
-
实验环境
python 3.9.2
tensorflow 2.10.0
Jupyter Notebook: 7.4.5
代码实现
设置gpu
python
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
# 设置GPU显存用量按需使用
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True)
tf.config.set_visible_devices([gpus[0]],"GPU")
# 打印出检测到的 GPU 列表
print(gpus)
导入数据
python
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import pathlib
# 隐藏警告
import warnings
warnings.filterwarnings('ignore')
data_dir = "../../datasets/catdog"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:{}".format(image_count))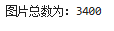
数据加载
python
batch_size = 8
img_height = 224
img_width = 224
# 数据加载
# 加载数据集,自动完成:调整尺寸、打乱数据、划分验证集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset = "training",
seed = 12,
image_size = (img_height, img_width),
batch_size = None) # 确保进入 map 的是单张图片而非批次。因为大多数官方提供的 tf.image 函数(如 random_crop, random_brightness)是为单张图片设计的。
python
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
输出标签
python
class_names = train_ds.class_names
print(class_names)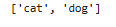
再次检查数据
python
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
数据增强
-
data_augment函数各层功能详解-
tf.image.random_flip_left_right(image)- 作用:对图像进行 随机水平翻转(左右镜像)。
- 触发概率:约 50% 的概率进行翻转,50% 保持原样。
- 目的:让模型明白物体的左右朝向不影响其类别判定。
-
tf.image.random_contrast(image, lower=0.8, upper=1.2)-
作用:随机调整图像的 对比度。
-
角度范围:对比度系数在
[0.8, 1.2]之间随机抽取。 -
目的:模拟不同的光照强弱环境,增强模型对图像明暗对比变化的鲁棒性。
-
-
tf.image.random_brightness(image, max_delta=0.2)-
作用:随机调整图像的 亮度。
-
调整范围:在
[-0.2, 0.2]范围内随机给像素值加上一个增量。 -
目的:模拟拍摄时曝光不足或曝光过度的情况,防止模型对特定的亮度值产生依赖。
-
-
random_zoom(image)(自定义随机裁剪) -
作用:实现 随机缩放/裁剪 效果。
-
逻辑详解:
- 计算尺寸:随机选取原图的 80% 到 100% 区域作为裁剪窗口。
random_crop:在原图中随机选取一个起始点进行裁剪,获得局部视图。resize:将裁剪出的局部区域拉伸回原始尺寸( 224x224)。
-
目的:模拟拍摄时的远近焦距变化,让模型学习局部特征(如只看到猫头也能识别出是猫)。
-
tf.clip_by_value(image, 0.0, 1.0)-
作用:设置 值域护栏,将像素值强制锁定在
[0.0, 1.0]之间。 -
必要性:由于亮度和对比度操作可能导致像素值超过 1.0 或低于 0.0。
-
后果:如果不进行截断,会导致可视化图像色彩失真,并可能引发模型训练过程中的数值不稳定。
-
-
python
# 随机裁剪并恢复到原始尺寸
# 假设原始是 224x224,我们先随机裁剪出 80%~100% 的区域
def random_zoom(image):
shape = tf.shape(image)
height, width = shape[0], shape[1]
# 随机选择一个缩放比例
scale = tf.random.uniform([], 0.8, 1.0)
new_h, new_w = tf.cast(scale * tf.cast(height, tf.float32), tf.int32), \
tf.cast(scale * tf.cast(width, tf.float32), tf.int32)
# 裁剪并重置大小
image = tf.image.random_crop(image, size=[new_h, new_w, 3])
image = tf.image.resize(image, [height, width])
return image
def data_augment(image, label):
# 随机水平翻转
image = tf.image.random_flip_left_right(image)
# 随机对比度
image = tf.image.random_contrast(image, lower=0.8, upper=1.2)
# 随机亮度
image = tf.image.random_brightness(image, max_delta=0.2)
# 随机裁剪
image = random_zoom(image)
# 确保像素值保持在 [0, 1] 范围内,避免增强操作导致数值越界
image = tf.clip_by_value(image, 0.0, 1.0)
return image, label处理数据集以及优化数据加载效率
python
AUTOTUNE = tf.data.AUTOTUNE
# 将图像像素值从 [0, 255](通常是 uint8 类型)缩放到 [0, 1] 的浮点范围。
def preprocess_image(image,label):
return (image/255.0,label)
# 归一化处理,.map(func)表示对数据集中的每个元素应用 func。num_parallel_calls=AUTOTUNE表示并行执行预处理操作。
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
# 数据增强,仅仅只对训练集进行数据增强
train_ds = train_ds.map(data_augment, num_parallel_calls=AUTOTUNE)
train_ds = train_ds.cache().shuffle(1000).batch(batch_size).prefetch(buffer_size=AUTOTUNE) # .batch(batch_size)将数据按 batch_size 分组,形成批次(batch),供模型批量训练
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)数据可视化
python
plt.figure(figsize=(15, 10)) # 图形的宽为15高为10
for images, labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(5, 8, i + 1)
plt.imshow(images[i])
plt.title(class_names[labels[i]])
plt.axis("off")
构建模型
-
各部分功能详解
-
预训练网络 (VGG16 Base Model)
-
weights='imagenet': 加载在 ImageNet 数据集上训练好的权重。这相当于给模型请了一位"见过世面"的资深老师。 -
include_top=False: 去掉原有的 1000 类全连接分类层。因为我们的目标是二分类(猫狗),不需要原模型末端的复杂结构。 -
base_model.trainable = False(冻结层):- 作用:在训练初期保持卷积层权重不变。
- 原理:预训练权重已经具备了极强的特征提取能力(如边缘、形状、纹理),冻结它们可以防止在自定义训练初期破坏这些宝贵的参数,同时大大加快训练速度。
-
-
全局平均池化层 (GlobalAveragePooling2D)
-
作用: 将卷积块输出的 7 × 7 × 512 7 \times 7 \times 512 7×7×512 特征图直接压缩为 1 × 1 × 512 1 \times 1 \times 512 1×1×512 的向量。
-
优势: 相比于
Flatten,它极大地减少了参数量(从 25,088 减小到 512),能有效防止过拟合,并增强模型对空间平移的鲁棒性。
-
-
新增全连接分类层
-
Dense(256): 将提取出的 512 维特征进一步映射到 256 维的空间,进行非线性组合,学习针对猫狗分类的特定逻辑。
-
Dropout(0.2):
- 作用:随机断开 20% 的神经元。
- 调整:由于使用了预训练权重且参数量较少,Dropout 率从 0.5 降至 0.2,以平衡特征学习与正则化。
-
输出层 (Dense(num_classes)): 最终输出"猫"和"狗"的概率分布。
-
-
为什么引入预训练模型(迁移学习)?
- 上周拔高要求考虑怎么简化代码结构,我就想能不能调用官方预训练模型来简化
-
python
num_classes = len(class_names)
# 加载预训练的 VGG16 模型,不包含顶部的全连接层
base_model = tf.keras.applications.VGG16(
weights='imagenet',
include_top=False,
input_shape=(img_height, img_width, 3)
)
# 冻结卷积层,防止权重被破坏
base_model.trainable = False
# 构建最终模型
model = tf.keras.Sequential([
base_model,
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(num_classes, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()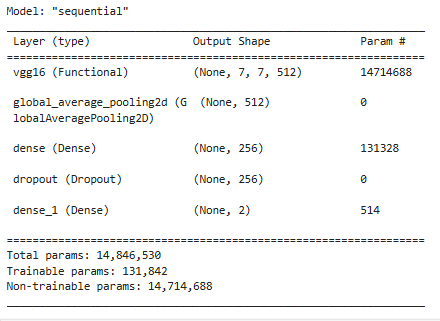
训练模型
model.train_on_batch(x, y)是 对单个 batch 的数据执行一次前向传播、损失计算、反向传播和参数更新。相比model.fit()(自动处理整个数据集、epoch、batch 等),train_on_batch可以自定义训练循环。tqdm是一个 Python 进度条库,能为可迭代对象添加进度条。- 参数说明:
total: 总步数(用于计算百分比)desc: 前缀描述(如 "Epoch 1/10")mininterval: 最小更新间隔ncols: 进度条总宽度(字符数)set_postfix(): 在进度条末尾动态显示额外信息(如 loss、acc)update(n): 手动推进 n 步
- 参数说明:
python
from tqdm import tqdm
import tensorflow.keras.backend as K
import numpy as np
epochs = 10
lr = 1e-5
# 记录训练数据,方便后面的分析
history_train_loss = []
history_train_accuracy = []
history_val_loss = []
history_val_accuracy = []
for epoch in range(epochs):
train_total = len(train_ds)
val_total = len(val_ds)
"""
total:预期的迭代数目
ncols:控制进度条宽度
mininterval:进度更新最小间隔,以秒为单位(默认值:0.1)
"""
with tqdm(total=train_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=1,ncols=100) as pbar:
lr = lr*0.98
K.set_value(model.optimizer.lr, lr)
train_loss = []
train_accuracy = []
for image,label in train_ds:
# 这里生成的是每一个batch的acc与loss
history = model.train_on_batch(image,label)
train_loss.append(history[0])
train_accuracy.append(history[1])
pbar.set_postfix({"train_loss": "%.4f"%history[0],
"train_acc":"%.4f"%history[1],
"lr": K.get_value(model.optimizer.lr)})
pbar.update(1)
history_train_loss.append(np.mean(train_loss))
history_train_accuracy.append(np.mean(train_accuracy))
print('开始验证!')
with tqdm(total=val_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=0.3,ncols=100) as pbar:
val_loss = []
val_accuracy = []
for image,label in val_ds:
# 这里生成的是每一个batch的acc与loss
history = model.test_on_batch(image,label)
val_loss.append(history[0])
val_accuracy.append(history[1])
pbar.set_postfix({"val_loss": "%.4f"%history[0],
"val_acc":"%.4f"%history[1]})
pbar.update(1)
history_val_loss.append(np.mean(val_loss))
history_val_accuracy.append(np.mean(val_accuracy))
print('结束验证!')
print("验证loss为:%.4f"%np.mean(val_loss))
print("验证准确率为:%.4f"%np.mean(val_accuracy))

模型评估
python
from datetime import datetime
current_time = datetime.now() # 获取当前时间
epochs_range = range(epochs)
plt.figure(figsize=(14, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, history_train_accuracy, label='Training Accuracy')
plt.plot(epochs_range, history_val_accuracy, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)
plt.subplot(1, 2, 2)
plt.plot(epochs_range, history_train_loss, label='Training Loss')
plt.plot(epochs_range, history_val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()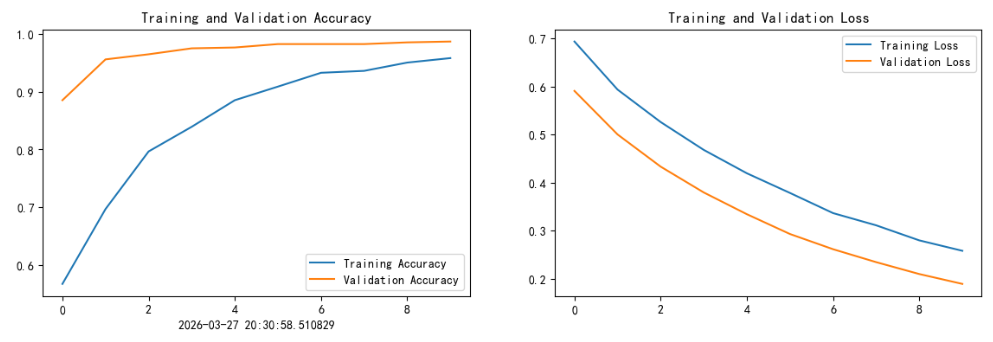
预测
python
plt.figure(figsize=(20, 6), dpi=150)
plt.suptitle("模型预测结果展示", fontsize=18, y=1.02)
for images, labels in val_ds.take(1):
# 隐藏进度条
predictions = model.predict(images, verbose=0)
for i in range(8):
ax = plt.subplot(1, 8, i + 1)
# 归一化显示处理
img_to_show = images[i].numpy()
img_to_show = np.clip(img_to_show, 0.0, 1.0)
plt.imshow(img_to_show)
# 获取索引和名称
pred_idx = np.argmax(predictions[i])
true_idx = labels[i].numpy()
pred_name = class_names[pred_idx]
true_name = class_names[true_idx]
title_text = f"预测:{pred_name}\n(真实:{true_name})"
# pad 参数可以增加标题和图片之间的距离
title_obj = plt.title(title_text, fontsize=11, pad=10)
# 预测错误标红
if pred_idx != true_idx:
title_obj.set_color('red')
title_obj.set_weight('bold') # 错误时加粗更显眼
plt.axis("off")
# wspace=0.3 增加子图之间的横向距离
plt.subplots_adjust(wspace=0.3, top=0.85)
plt.show()
学习总结
-
遇到问题:
- 在做随机裁剪等数据增强时,我发现必须在加载数据时设置
batch_size=None。这是因为大多数官方提供的 tf.image 函数(如 random_crop, random_brightness)是为单张图片设计的,通常只能处理"单张图片"(3维),如果过早把图片打包成批次(4维 ,多了一维Batch),就会导致裁剪尺寸对不上而报错。 - 亮度、对比度等增强操作本质上是数学运算,很容易让归一化后的像素值跑出 0 , 1 0, 1 0,1 的合法区间(比如变成 1.2 1.2 1.2 或 − 0.1 -0.1 −0.1),导致可视化时色彩诡异且训练不稳定。我的解决方法是在增强流水线的最后一步,雷打不动地加上
tf.clip_by_value(image, 0.0, 1.0)。这就像是在出厂前做最后一次"值域质检",确保喂给模型的数据在归一化范围内。

- 在做随机裁剪等数据增强时,我发现必须在加载数据时设置
-
在本次实现中,我应用了翻转、亮度、对比度及随机裁剪这套来对训练样本进行数据增强,尽管好心办坏事,增强过度导致边界超出了,不过最后还是解决问题了。