当你同时播放音乐、收到消息提示音、还有游戏背景音效,三路音频毫无干扰地同时从扬声器流出------这背后的魔法,就是本文的主角:AudioFlinger 混音机制。
这也是整个音频子系统里最复杂的部分。前三篇我们分别看了 AudioFlinger 整体架构、AudioTrack 播放流程和 AudioRecord 录制流程。这一篇我们进入"引擎舱",看 AudioFlinger 如何同时处理几十路音频流:选择线程、混合数据、实时调度、音效处理,一气呵成。
本文主要内容:
- PlaybackThread 四种类型:什么时候用哪种线程?
- Track 管理机制:Active/Inactive 状态、音量控制
- 混音算法:多路 PCM 数据如何叠加?整数混音防溢出
- FastMixer 设计:SCHED_FIFO、Lock-free StateQueue、抖动优化
- AudioEffect 效果链:均衡器/混响/低音增强的挂载原理
- 性能优化:CPU、延迟、功耗三角平衡
源码版本 :Android 15 AOSP 关键路径 :
frameworks/av/services/audioflinger/Threads.cpp、Tracks.cpp、FastMixer.cpp、AudioMixer.cpp
PlaybackThread 四种类型
AudioFlinger 不是用一个通用线程处理所有播放,而是根据场景选择最合适的线程类型。
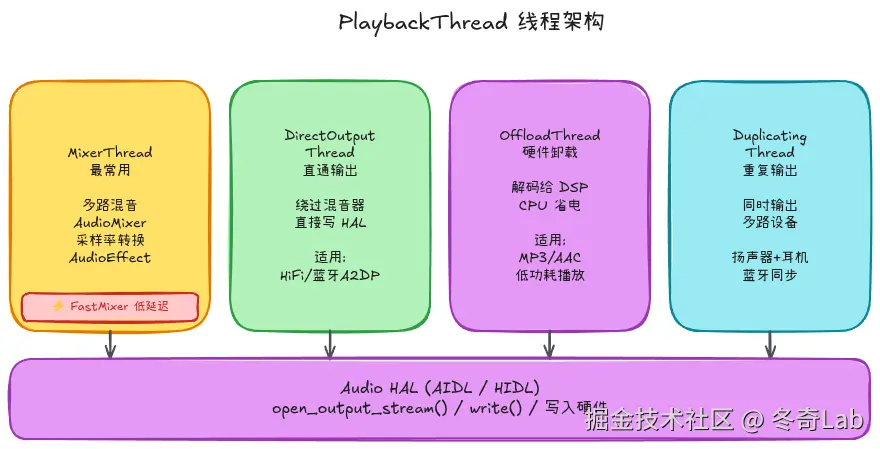
MixerThread:最常用的混音线程
MixerThread 是默认选择,绝大多数 AudioTrack 都跑在这里。它的核心能力是多路混音:把多个 Track 的 PCM 数据按比例相加,输出一路信号给 Audio HAL。
scss
MixerThread 数据流:
Track A (44100Hz PCM) ──┐
Track B (16000Hz PCM) ──┤→ AudioMixer(重采样+混合) → HAL write()
Track C (48000Hz PCM) ──┘何时创建 MixerThread? 当 AudioPolicyService 决定路由到某个输出设备(如扬声器、耳机插孔)时,AudioFlinger 会为该设备创建一个 MixerThread。如果该设备已经有 MixerThread,新的 Track 直接加入现有线程。
DirectOutputThread:直通输出
DirectOutputThread 的特点是绕过软件混音器,把 PCM(或编码格式)数据直接交给 HAL。
cpp
// frameworks/av/services/audioflinger/Threads.cpp
// DirectOutputThread 不创建 AudioMixer
AudioFlinger::DirectOutputThread::DirectOutputThread(...)
: PlaybackThread(audioFlinger, output, id, type) {
// 注意:没有 mAudioMixer = new AudioMixer(...)
}适用场景:
- HiFi 高清播放:需要保证信号路径干净,不经过软件混音引入失真
- 蓝牙 A2DP:编码格式(SBC/AAC/LDAC)由 HAL 处理,上层只传 PCM
- 空间音频:需要精确控制声道映射
代价:同时只能有一个 Track(不支持混音),第二个 Track 请求时会被拒绝或降级到 MixerThread。
OffloadThread:硬件解码卸载
OffloadThread 把音频解码工作交给硬件 DSP,主 CPU 几乎不参与处理。
cpp
// 检查设备是否支持 Offload
bool AudioFlinger::isOffloadSupported(const audio_offload_info_t& info) {
return AudioSystem::isOffloadSupported(info);
// 底层查询 HAL 的 is_offload_supported()
}典型使用:锁屏播放音乐时,Offload 允许 AP 进入深度睡眠,由 DSP 单独运行,续航可增加 20-30%。
Android 15 中的变化 :Offload Track 现在支持 AudioEffect(通过 HAL 侧的效果处理),而之前版本的 Offload 完全不支持效果链。
DuplicatingThread:重复输出
DuplicatingThread 继承自 MixerThread,它可以同时输出到多个设备:
cpp
// DuplicatingThread 持有多个输出目标
class DuplicatingThread : public MixerThread {
SortedVector<OutputTrack*> mOutputTracks; // 多个输出
// threadLoop 写数据时,遍历所有 OutputTrack
void threadLoop_write() {
for (auto& outputTrack : mOutputTracks) {
outputTrack->write(mSinkBuffer, mNormalFrameCount);
}
}
};典型场景 :车载系统同时输出音乐到扬声器和蓝牙耳机,或开发者通过 AudioRecord 同时录制麦克风和正在播放的音乐(需要系统权限)。
线程选择逻辑
cpp
// AudioFlinger::openOutput() 中的线程选择
sp<PlaybackThread> AudioFlinger::openOutput_l(..., audio_output_flags_t flags) {
sp<PlaybackThread> thread;
if (flags & AUDIO_OUTPUT_FLAG_DIRECT) {
// 请求直通 → DirectOutputThread
thread = new DirectOutputThread(this, output, id, ...);
} else if (flags & AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD) {
// 请求 Offload → OffloadThread
thread = new OffloadThread(this, output, id, ...);
} else {
// 默认 → MixerThread(包含 FastMixer 支持)
thread = new MixerThread(this, output, id, ...);
}
mPlaybackThreads.add(id, thread);
return thread;
}Track 管理机制
Track 的生命周期状态
每个 Track 在 PlaybackThread 内部有独立的状态机:
scss
IDLE(创建后初始)
↓ AudioTrack.play()
ACTIVE(加入混音队列)
↓ AudioTrack.pause()
PAUSING → PAUSED(等待当前数据处理完)
↓ AudioTrack.stop()
STOPPING_1 → STOPPING_2 → STOPPED(等待数据播完)
↓ AudioFlinger 发现 Track 停止
FLUSHED → IDLE(缓冲区清空)
cpp
// frameworks/av/services/audioflinger/Tracks.cpp
// Track 的核心状态转换
void AudioFlinger::PlaybackThread::Track::setState(State state) {
// 状态转换中会更新 mState 并通知 PlaybackThread
Mutex::Autolock _l(mLock);
mState = state;
mCblk->mFutex++; // 通过 futex 通知消费者
}TrackHandle:跨进程代理
App 持有的 IAudioTrack 实际上是 TrackHandle,它是 Binder 服务端:
cpp
// AudioFlinger 端
class TrackHandle : public android::BnAudioTrack {
sp<PlaybackThread::Track> mTrack;
// App 调用 start() → Binder → TrackHandle::start()
status_t start() override {
return mTrack->start();
}
// App 调用 setVolume() → 但实际上 App 直接写 mCblk->mVolumeLR
// 不需要经过 Binder!这是一个关键的性能优化
};音量控制的两种路径
这是 Track 管理里最精妙的设计:
cpp
// 路径1:快速音量(共享内存直接写,无 Binder IPC)
// AudioTrack.setStereoVolume() 直接修改 mCblk->mVolumeLR
void AudioTrack::setStereoVolume(float left, float right) {
mCblk->setVolumeLR(gain_from_float(left), gain_from_float(right));
}
// 路径2:Stream 音量(经过 Binder 到 AudioFlinger)
// AudioManager.setStreamVolume() → AudioService → AudioFlinger
// → PlaybackThread 更新所有对应 Stream 类型的 Track 音量
void AudioFlinger::setStreamVolume(audio_stream_type_t stream, float value) {
Mutex::Autolock _l(mLock);
mStreamTypes[stream].volume = value;
// 通知各 PlaybackThread 刷新 Track 音量
for (auto& thread : mPlaybackThreads) {
thread->invalidateTracks(stream);
}
}结论 :调 AudioTrack.setVolume()(个人音量)几乎是瞬时且无开销;调 AudioManager.setStreamVolume()(系统音量)有一次 Binder IPC 延迟,但影响所有同类型 Track。
混音算法实现
AudioMixer 的工作原理
AudioMixer 是混音核心,它维护最多 32 个 Track 的混音状态:
cpp
// frameworks/av/media/libaudioprocessing/AudioMixer.cpp
class AudioMixer {
// 每个 Track 的独立状态
struct track_t {
void* bufferProvider; // Ring Buffer 读取器
float volume[MAX_NUM_CHANNELS]; // 每声道音量
bool needsRamp; // 是否需要音量渐变
AudioResampler* resampler; // 采样率转换器(如需要)
int32_t sessionId;
uint32_t sampleRate;
};
track_t mState.tracks[MAX_NUM_TRACKS];
uint32_t mTrackNames; // bitmask: 哪些 track 槽位在使用
// 核心处理函数
void process();
};process() 会根据当前活跃 Track 的组合,动态选择最优的处理函数:
cpp
void AudioMixer::process() {
// ... 根据 track 的特性选择最优处理函数 ...
// 典型:所有 track 同采样率,无 effect
// → process__TwoTracks16BitsStereoNoResampling (高度优化的 NEON 汇编)
// 有重采样的 track
// → process__genericResampling
// 有 AudioEffect 的
// → process__genericNoResampling + EffectChain 处理
}整数混音防溢出
多路 PCM 数据相加最大的挑战是溢出 (int16_t 范围 -32768 到 32767):
cpp
// frameworks/av/media/libaudioprocessing/AudioMixerOps.h
// 混音核心:使用 int32_t 累加,最后再转换回 int16_t
template <int MIXTYPE, typename TO, typename TI, typename TV>
void MixMul(TO* out, TI* in, TV vol) {
// 步骤1:先转换为 32bit 整数做累加(防止 16bit 溢出)
int32_t l = mul(in[0], vol[0]); // mul 返回 int32_t
int32_t r = mul(in[1], vol[1]);
// 步骤2:累加到输出缓冲区(也是 int32_t)
out[0] = clamp16(out[0] + (l >> 12)); // 固定点右移 12 位
out[1] = clamp16(out[1] + (r >> 12));
}
// clamp16:截断到 int16_t 范围
inline int16_t clamp16(int32_t sample) {
if ((sample >> 15) ^ (sample >> 31))
sample = 0x7FFF ^ (sample >> 31);
return sample;
}关键设计:
- 输出缓冲区
mMixBuffer是int32_t(32位),避免中间溢出 - 每个 Track 的贡献量先乘以音量(固定点乘法),再累加
- 最终转换成
int16_t时才做截断(clamp)
采样率转换(Resampler)
混音时各 Track 可能有不同采样率,AudioMixer 用 AudioResampler 转换:
cpp
// 三种重采样质量(性能 vs 质量权衡)
AudioResampler::kDefaultQuality // 线性插值,CPU 开销最低
AudioResampler::kMedQuality // 低阶 sinc,适合普通场景
AudioResampler::kHighQuality // 高阶 sinc,适合专业音频
AudioResampler::kVeryHighQuality // 非常高质量,CPU 开销极大
// 实际创建时:
sp<AudioResampler> resampler = AudioResampler::create(
format,
numChannels,
targetSampleRate, // 硬件输出采样率(通常 48000)
quality // 根据 Track 的 PERFORMANCE_MODE 选择
);性能数据(Snapdragon 8 Gen 3,8 路混音):
- 全部 48kHz,无重采样:CPU ~2%
- 2 路 44.1kHz 需要重采样(kDefaultQuality):CPU ~4%
- 2 路 44.1kHz(kHighQuality):CPU ~7%
这就是为什么 FAST Track 要求采样率与硬件一致------省掉了重采样开销。
FastMixer 设计详解
FastMixer 是 AudioFlinger 中最"极客"的部分,专为毫秒级延迟设计。
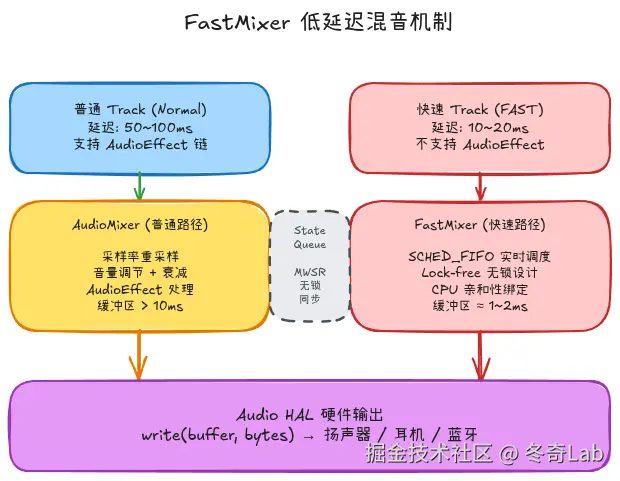
为什么需要 FastMixer?
普通 MixerThread 的延迟来自:
- 缓冲区大小(通常 2
4 个 HAL 周期 × 10ms = 2040ms) - 等待 Track 数据、处理 AudioEffect、Binder 调用 → 偶发性抖动(Jitter)
- Linux 的 SCHED_OTHER 调度策略 → 无法保证及时唤醒
FastMixer 的方案:
arduino
普通路径(高延迟):
NormalMixer → 2×HAL Period Buffer → HAL write
↑ 约 20~80ms
快速路径(低延迟):
FastMixer ──→ 1×HAL Period Buffer → HAL write
SCHED_FIFO ↑ 约 5~15msSCHED_FIFO 实时调度
cpp
// frameworks/av/services/audioflinger/FastMixer.cpp
void FastMixerState::onStateChange() {
// 设置实时调度策略
pid_t tid = gettid();
// 1. 设置为 SCHED_FIFO(实时调度,优先级高于所有 SCHED_OTHER 线程)
struct sched_param param = {};
param.sched_priority = 19; // 1~99,19 是 AudioFlinger 使用的典型值
sched_setscheduler(tid, SCHED_FIFO, ¶m);
// 2. CPU 亲和性:绑定到特定核心,避免核间迁移开销
// 通常绑定到一个"小核",保证实时性同时节省功耗
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(kFastMixerCpuHint, &cpuset); // 设备厂商可配置
sched_setaffinity(tid, sizeof(cpuset), &cpuset);
// 3. mlockall:锁定内存,防止缺页中断
mlockall(MCL_CURRENT | MCL_FUTURE);
}为什么不把所有 AudioFlinger 线程都设为 SCHED_FIFO? 因为 SCHED_FIFO 的线程一旦进入 CPU 就不会主动让出,除非主动 sleep 或被更高优先级抢占。如果有 Bug 导致死循环,整个系统会挂死。FastMixer 的代码路径极短(< 1ms),风险可控。
Lock-free StateQueue
FastMixer 线程和主线程(配置 FastMixer 参数)之间的通信,不能用 Mutex(会引入不确定延迟)。Android 设计了一套 MWSR(Multi-Writer Single-Reader)无锁队列:
cpp
// frameworks/av/services/audioflinger/StateQueue.h
template<typename T>
class StateQueue {
static const int kN = 4; // 状态槽位数(固定大小,避免动态分配)
T mStates[kN]; // 状态快照数组
volatile int32_t mIndex; // 当前活跃状态索引(原子变量)
volatile int32_t mAck; // 确认序号
public:
// 写端(主线程,多写者竞争用 CAS)
void push(SharedBuffer* newState) {
int next = (android_atomic_acquire_load(&mIndex) + 1) % kN;
memcpy(&mStates[next], newState, sizeof(T));
// 原子发布(内存屏障确保写入顺序)
android_atomic_release_store(next, &mIndex);
}
// 读端(FastMixer 单独读取)
const T* poll() {
int index = android_atomic_acquire_load(&mIndex);
return &mStates[index];
// 零延迟!无锁、无系统调用
}
};零拷贝状态更新 的好处:FastMixer 每个周期(约 1ms)都调用 poll() 获取最新配置(Track 列表、音量等),这个操作只有一次原子读取,耗时约 10~100 纳秒。
FastMixer 的 threadLoop
cpp
// frameworks/av/services/audioflinger/FastMixer.cpp
bool FastMixer::threadLoop() {
while (!exitPending()) {
// 1. 非阻塞获取最新状态(无锁)
const FastMixerState* state = mSQ.poll();
// 2. 处理每个 Fast Track
for (int i = 0; i < state->mFastTracksGen; i++) {
FastTrack* ft = &state->mFastTracks[i];
if (ft->mBufferProvider == nullptr) continue;
// 从 Ring Buffer 获取数据(也是无锁的)
AudioBufferProvider::Buffer buffer;
ft->mBufferProvider->getNextBuffer(&buffer);
// 直接写入混音缓冲区(pointer arithmetic,无拷贝)
// ... ARM NEON 优化的混音代码 ...
}
// 3. 调用 HAL write(这是唯一的"慢"操作,但 HAL 保证及时返回)
mOutputSink->write(mMixBuffer, state->mFrameCount);
// 4. 上报时间戳(供 AudioTrack.getTimestamp() 使用)
mTimestampProvider->push(timestamp);
}
}Fast Track 进入条件(与第2篇对照)
回顾一下 FAST Track 的判断条件(详细代码见第2篇),关键是:
| 条件 | 原因 |
|---|---|
| 采样率 = 硬件采样率 | FastMixer 不做重采样(省时间) |
| 格式 = PCM_16BIT 或 PCM_FLOAT | FastMixer 只处理线性 PCM |
| 无 AudioEffect 链 | 效果处理不确定时间,破坏实时性 |
| 缓冲区足够小 | 避免引入太大延迟 |
PERFORMANCE_MODE_LOW_LATENCY |
明确声明需要低延迟 |
AudioEffect 效果链
AudioEffect 是 Android 音频效果处理框架,支持**均衡器(EQ)、混响(Reverb)、低音增强(BassBoost)、虚拟化(Virtualizer)**等。
EffectChain 的挂载位置
scss
App Track ──→ EffectChain(Session=X) ──→ MixerThread 输出缓冲区
↑ ↑
Session级效果 Global级效果
(只影响该Session) (影响所有输出)
cpp
// frameworks/av/services/audioflinger/Effects.cpp
// Session 级效果:挂载到特定 AudioSession
sp<EffectChain> AudioFlinger::MixerThread::getEffectChain_l(audio_session_t sessionId) {
for (auto& chain : mEffectChains) {
if (chain->sessionId() == sessionId) {
return chain;
}
}
return nullptr;
}
// Global 级效果(SESSION_OUTPUT_MIX):挂载在混音后
// 典型场景:系统 EQ,影响所有 App 的输出EffectChain 的处理时序
cpp
// MixerThread::threadLoop_mix()
void AudioFlinger::MixerThread::threadLoop_mix() {
// 1. AudioMixer 混合所有 Track → mMixBuffer
mAudioMixer->process();
// 2. 对混音结果应用 Session 级效果
// 注意:AudioEffect 不在 FAST Track 路径上
for (auto& chain : mEffectChains) {
chain->process_l(); // 在 mMixBuffer 上原地处理
}
// 3. 写入输出
mOutput->write(mSinkBuffer, mNormalFrameCount * mFrameSize);
}实现自定义 AudioEffect
java
// Java 层创建均衡器效果
Equalizer eq = new Equalizer(0, audioTrack.getAudioSessionId());
eq.setEnabled(true);
// 获取支持的频段数
short numBands = eq.getNumberOfBands(); // 通常 5 段
// 设置每个频段的增益(单位:millibels,1000 millibels = 10 dB)
eq.setBandLevel((short)0, (short)300); // 低频 +3dB
eq.setBandLevel((short)4, (short)-200); // 高频 -2dB
// 查询频段中心频率
int[] freqs = new int[numBands];
for (int i = 0; i < numBands; i++) {
int[] range = eq.getBandFreqRange((short)i);
freqs[i] = (range[0] + range[1]) / 2;
Log.d(TAG, "Band " + i + ": " + freqs[i]/1000 + " Hz");
// 典型输出:60Hz, 230Hz, 910Hz, 3600Hz, 14000Hz
}
// 用完要 release()!否则 audioserver 会泄漏 EffectChain
eq.release();EffectModule 和 HW Effect
cpp
// effects 可以是软件实现,也可以是硬件加速
class EffectModule : public RefBase {
effect_handle_t mEffectInterface; // 实际是 function pointer table
// 软件 Effect:在 CPU 上运行(libaudioeffects.so)
// HW Effect:通过 HAL 调用,在 DSP 上运行(更低延迟,更低功耗)
status_t process() {
// 调用 effect 的 process() 接口(统一抽象)
return (*mEffectInterface)->process(mEffectInterface,
&mConfig.inputCfg.buffer,
&mConfig.outputCfg.buffer);
}
};性能优化与调试
CPU 优化:NEON SIMD 混音
AudioMixer 的热路径使用 ARM NEON 指令集优化,一条指令处理 8 个 int16_t:
cpp
// 示意性代码(实际是汇编或 intrinsic)
// 标准 C 版本(慢):
for (int i = 0; i < frameCount; i++) {
out[i] = clamp16(out[i] + (in[i] * vol >> 12));
}
// NEON 优化版本(快 8x):
int16x8_t vin = vld1q_s16(in); // 一次加载 8 个 int16_t
int16x8_t vout = vld1q_s16(out);
int16x8_t vvol = vdupq_n_s16(vol); // 广播音量到 8 个通道
int32x4_t vmul_lo = vmull_s16(vget_low_s16(vin), vget_low_s16(vvol));
// ... 更多 NEON 指令 ...
vst1q_s16(out, result); // 一次写回 8 个结果Android 15 新增 :支持 float32 混音路径(AUDIO_FORMAT_PCM_FLOAT),避免 int16_t 的量化噪声,尤其在低音量混音时差异明显。
延迟优化:缓冲区调整
bash
# 查看当前 HAL 缓冲区配置
adb shell dumpsys media.audio_flinger | grep -A 5 "HAL buffer"
# 典型输出:
# Output: id=1 samplingRate=48000 format=01 frameCount=480 latency=10ms
# frameCount=480 at 48000Hz = 10ms latency
# 设备通常设为 480 或 960 帧
java
// App 层的低延迟实践
AudioManager am = (AudioManager) context.getSystemService(Context.AUDIO_SERVICE);
// 获取设备的最优采样率和缓冲区大小
String sampleRate = am.getProperty(AudioManager.PROPERTY_OUTPUT_SAMPLE_RATE);
String framesPerBuffer = am.getProperty(AudioManager.PROPERTY_OUTPUT_FRAMES_PER_BUFFER);
Log.d(TAG, "最优参数: " + sampleRate + "Hz, " + framesPerBuffer + "帧/缓冲");
// 使用这两个值创建 AudioTrack,可以最大化 FAST Track 进入概率功耗优化:智能线程调度
cpp
// MixerThread 在没有 Active Track 时进入休眠
bool AudioFlinger::MixerThread::threadLoop() {
while (!exitPending()) {
{
Mutex::Autolock _l(mLock);
// 没有活跃 Track → 进入休眠(CPU 空闲)
if (mActiveTracks.isEmpty()) {
if (mOutput) {
// 关闭 HAL 输出(允许音频硬件进入低功耗状态)
mOutput->standby();
}
// 等待新 Track 到来
mWaitWorkCV.wait(mLock);
continue;
}
}
// ... 混音处理 ...
}
}关键优化 :当所有 Track 都暂停或停止,MixerThread 调用 HAL 的 standby(),通知音频硬件进入低功耗状态。在有音频播放的设备上,这一机制显著降低了静默时的功耗。
调试工具速查
bash
# 1. 查看所有 PlaybackThread 状态
adb shell dumpsys media.audio_flinger | grep -A 50 "Output thread"
# 关注字段:
# "type 0 (MixerThread)" → 线程类型
# "frameCount=480" → 缓冲区帧数(480@48kHz=10ms)
# "latency=20 ms" → 当前总延迟
# "FAST" → 是否有 Fast Track 活跃
# 2. 检查 FastMixer 运行状态
adb shell dumpsys media.audio_flinger | grep -A 20 "FastMixer"
# 典型输出:
# FastMixer state queue: index=3 ack=3
# state: 1 tracks, gen=7, frameCount=240
# underruns: total=0 <-- 这个必须是0!
# 3. Systrace 分析混音周期
adb shell atrace --async_start -b 32768 audio
# ... 播放音频 ...
adb shell atrace --async_stop
# 在 Perfetto UI 查看 "AudioMixer::process" 和 "FastMixer" 的 CPU 占用和周期间隔
# 4. 实时音频日志
adb logcat -s AudioFlinger:V AudioMixer:V实战案例:诊断混音延迟
java
// 场景:游戏音效延迟明显,想确认是否进入了 FastMixer
public class AudioLatencyDiagnostic {
public static void diagnose(AudioTrack track) {
// 1. 检查性能模式
int mode = track.getPerformanceMode();
String modeStr;
switch (mode) {
case AudioTrack.PERFORMANCE_MODE_LOW_LATENCY:
modeStr = "LOW_LATENCY (可能进了FastMixer)";
break;
case AudioTrack.PERFORMANCE_MODE_POWER_SAVING:
modeStr = "POWER_SAVING (省电模式,高延迟)";
break;
default:
modeStr = "NONE (标准模式)";
}
Log.d(TAG, "性能模式: " + modeStr);
// 2. 测量实际延迟
long startNs = System.nanoTime();
// [这里写入一个特殊的可识别音频信号]
track.play();
AudioTimestamp ts = new AudioTimestamp();
int maxRetry = 50;
while (maxRetry-- > 0) {
if (track.getTimestamp(ts)) {
long latencyNs = ts.nanoTime - startNs;
Log.d(TAG, "实测延迟: " + latencyNs / 1_000_000 + " ms");
break;
}
try { Thread.sleep(2); } catch (InterruptedException e) { break; }
}
// 3. 查询硬件输出延迟
AudioManager am = ...;
String framesStr = am.getProperty(
AudioManager.PROPERTY_OUTPUT_FRAMES_PER_BUFFER);
String rateStr = am.getProperty(
AudioManager.PROPERTY_OUTPUT_SAMPLE_RATE);
int frames = Integer.parseInt(framesStr);
int rate = Integer.parseInt(rateStr);
Log.d(TAG, "HAL 延迟: " + (frames * 1000 / rate) + " ms");
// 4. dumpsys 验证(仅调试用)
// adb shell dumpsys media.audio_flinger | grep -i "FAST"
}
}总结
从这篇文章我们完整地走了一遍 AudioFlinger 混音的核心机制:
| 组件 | 职责 | 关键技术 |
|---|---|---|
| MixerThread | 多路 PCM 混音 | AudioMixer、NEON 优化 |
| DirectOutputThread | 直通输出 | 绕过混音、HiFi/蓝牙专用 |
| OffloadThread | 硬件解码 | DSP 加速、低功耗 |
| DuplicatingThread | 多设备输出 | 链式 OutputTrack |
| AudioMixer | 具体混音算法 | 定点数防溢出、重采样 |
| FastMixer | 低延迟路径 | SCHED_FIFO、Lock-free StateQueue |
| EffectChain | 音频效果处理 | Session/Global 两级挂载 |
三个最重要的结论:
- FastMixer 是双刃剑:能实现 10ms 以内延迟,但要求严格(无 Effect、固定采样率),且代码路径必须足够短,不能有阻塞操作
- 混音是加法,不是复杂算法:防溢出用 int32 累加 + clamp,这才是效率的关键
- standby 是最好的功耗优化:没有活跃 Track 时,整个音频硬件会休眠,这一行为由 MixerThread 自动触发
下一篇,我们从"混"跳到"管"------AudioPolicyService 策略管理:当你插上耳机、连上蓝牙、或者进入通话模式,系统如何决定音频路由到哪个设备?