Lab4AI大模型实验室是面向AI开发者、科研党与学习者打造的一站式AI实践平台,深度绑定高性能弹性算力,支持模型复现、训练、推理全流程,以按需计费、低价高效破解高端算力紧缺与成本高昂难题;同步Arxiv前沿论文并提供翻译、导读、分析服务,支持各类大模型一键复现与数据集微调,对接孵化资源助力科研成果转化;同时搭载多样化AI在线课程,实现理论学习与代码实操同步推进,全方位覆盖AI研发、科研创新与技能学习全场景需求。
文章链接:https://www.lab4ai.cn/arxiv?utm_source=csdn_daily_paper
作者信息
作者包括Ruisi Wang, Zhongang Cai等,分别来自商汤科技、南洋理工大学、加州大学伯克利分校、加州大学圣地亚哥分校和卡内基梅隆大学。
研究背景
近年来,视频生成模型取得了显著进展,并意外地展现出非平凡的推理能力。先前的研究将这种能力归因于"帧链"机制,假设推理是沿着视频帧的时间顺序依次展开的。然而,尽管这一发现引人入胜,视频推理背后的底层机制在很大程度上仍未被探索。随着大规模视频推理数据集和开源基础模型的发布,现在有机会系统性地调查这一能力。本研究旨在填补这一空白,挑战现有的"帧链"假设,通过全面的解剖分析,揭示扩散视频模型中推理能力的真实发生机制,从而为理解视频生成模型的内在智能提供新的视角。
研究目的
本研究旨在挑战先前关于视频推理沿时间维度(帧链)展开的假设,通过系统的解剖分析,揭示扩散视频模型中推理能力的真实发生机制。具体目标包括:
- 阐明推理过程主要沿着扩散去噪步骤展开而非视频帧,确立"思维步"机制;
- 识别并分析模型中涌现出的关键推理行为,如工作记忆、自我修正与增强以及"先感知后行动"的决策模式;
- 深入分析Diffusion Transformer内部的层级功能分化,理解不同层在推理过程中的具体作用;
- 基于机制发现,探索提升视频推理性能的有效策略。
核心贡献
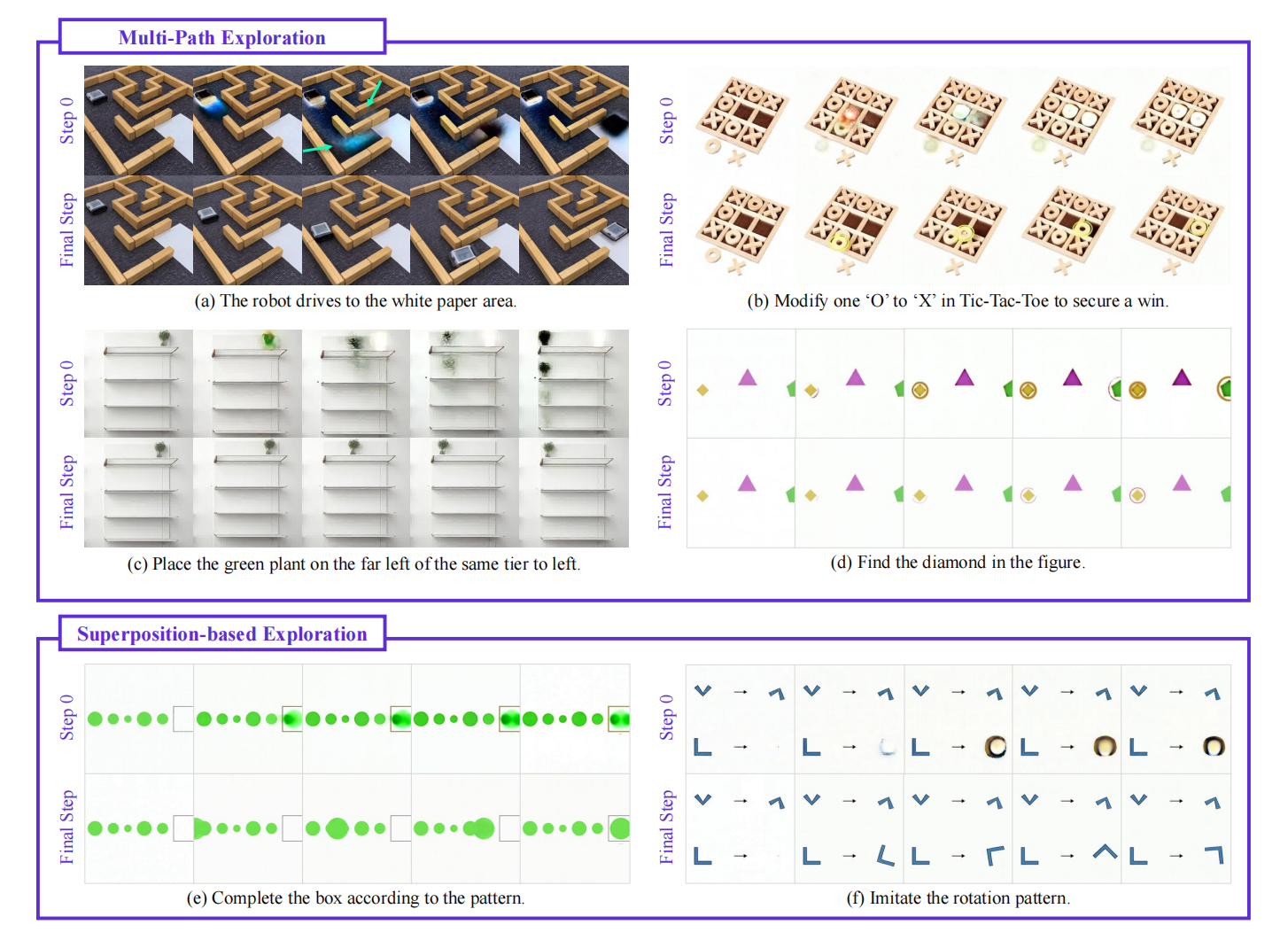
- 提出了"思维步"机制,挑战了传统的"帧链"观点,证明视频推理主要沿着扩散去噪步骤展开,模型在早期步骤探索多种假设,随后逐渐收敛收敛至最终答案,而非沿时间维度顺序推理。
- 识别了视频推理模型中涌现的多种关键行为,包括工作记忆(保持持久引用)、自我修正与增强(从错误中恢复)以及"先感知后行动"(早期步骤建立语义基础,后期步骤执行结构化操作),这些行为与大型语言模型中的表现惊人相似。
- 揭示了Diffusion Transformer内部在单步去噪过程中的自演化功能分层,发现早期层编码密集的感知结构,中间层执行核心推理,后期层整合潜在表征。
- 基于上述发现,提出了一种简单的免训练推理策略,通过集成不同随机种子的潜在轨迹,鼓励模型保留更丰富的候选推理路径,从而提升推理准确性。
研究方法
研究主要基于VBVR-Wan2.2模型,结合定性分析与定量实验。核心方法包括:
- 可视化分析:通过观察每个扩散步骤估计的干净潜变量,分析模型内部决策动态,识别多路径探索和叠加探索模式;
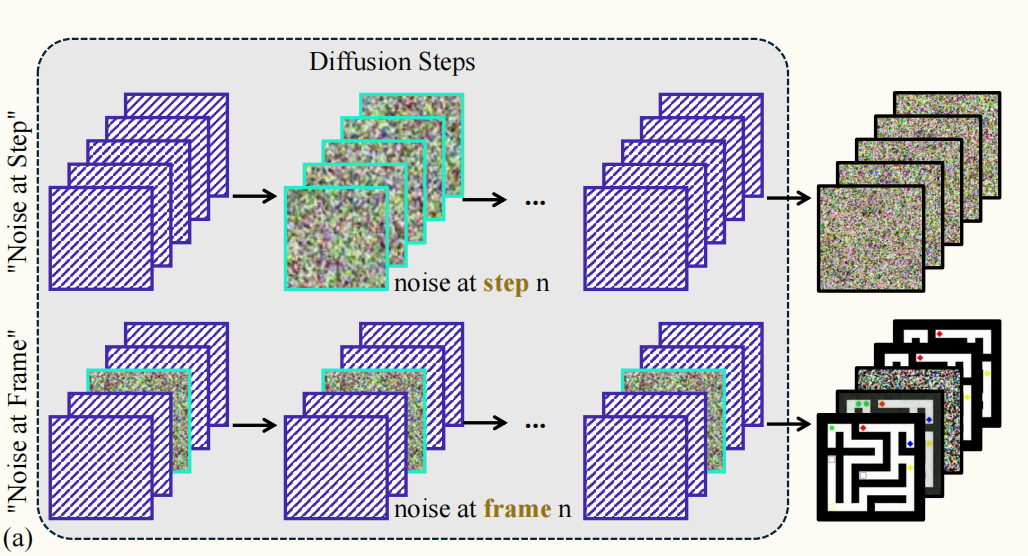
- 噪声扰动实验:设计"步骤噪声"和"帧噪声"两种注入方案,对比其对模型性能的影响,以隔离推理发生的维度;
- 信息流分析:利用中心核对齐(CKA)差异度测量噪声扰动后的信息传播,量化推理结论固化的阶段;
- 层级机制分析:通过前向钩子捕获Diffusion Transformer的隐藏状态,计算Token激活强度的L2范数进行可视化,并进行层级潜在交换实验,因果评估各层对最终结果的影响;
- 免训练集成方法:在关键推理步骤(如第0步)对中间层(第20-29层)的潜在表征进行多种子平均,以过滤噪声并增强逻辑一致性。
研究结果
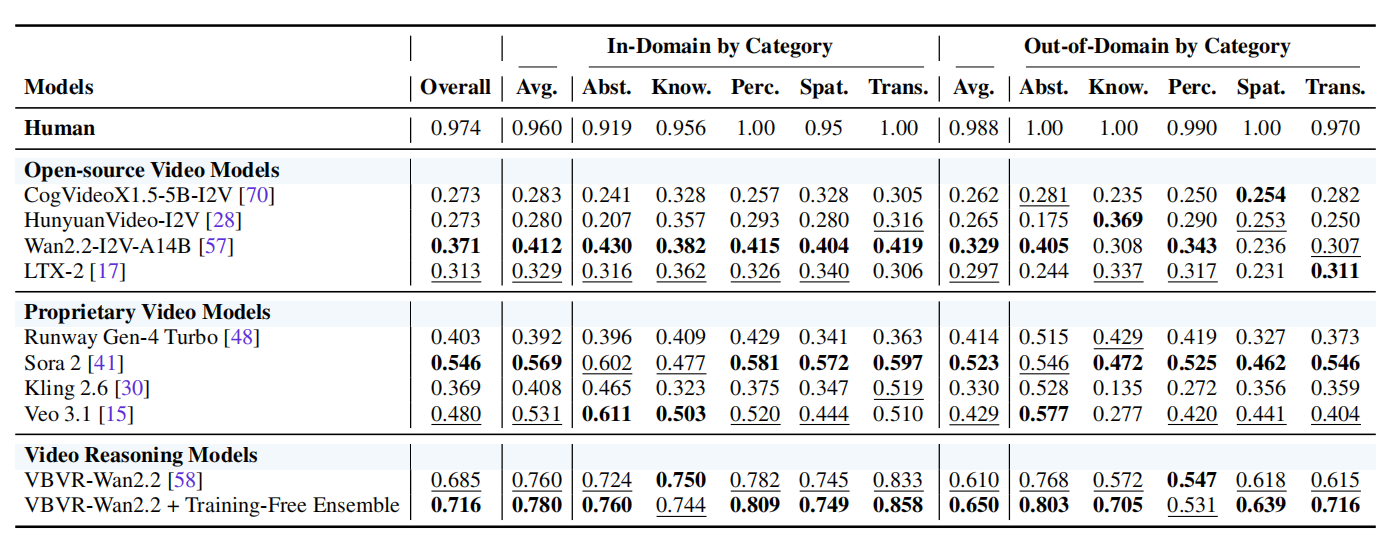
实验结果表明,视频推理主要遵循"思维步"机制。噪声扰动分析显示,在特定扩散步骤注入噪声会导致性能从0.685显著下降至0.3以下,而在特定帧注入噪声影响较小,证实了推理对扩散步骤的高度敏感性。定性分析发现,模型在迷宫求解、井字棋等任务中,早期步骤会同时探索多种路径或叠加多种候选状态,随去噪进程逐步剪枝收敛。信息流分析表明,推理结论主要在中间扩散步骤(20-30步)固化。层级分析显示,中间层(如第20层)包含决定性的语义信息,交换该层表征可导致推理结果翻转。基于此提出的免训练集成策略在VBVR-Bench上取得了约2%的绝对性能提升(从0.685提升至0.716),证明了利用模型内在推理动态的有效性。
总结与展望
本研究系统性地揭示了扩散视频模型中推理能力的内在机制,将其定义为"思维步"过程,并识别了伴随其产生的涌现行为。研究发现,推理并非沿时间维度展开,而是发生在去噪轨迹上,且模型具备类似LLM的工作记忆和自我修正能力。通过层级分析,进一步阐明了模型内部的功能分化。基于这些发现,研究提出的免训练集成方法展示了无需额外训练即可提升性能的潜力。总体而言,这项工作为理解视频推理提供了系统性的视角,将视频定位为机器智能的下一代有前途的基座,为未来研究如何更好地利用视频模型的内在推理动力学奠定了基础。