一、模型压缩简介
Ø 深度学习(Deep Learning)因其计算复杂度或参数冗余,在一些场景和设备上限制了相 应的模型部署,需要借助模型压缩、优化加速、异构计算等方法突破瓶颈。
Ø 模型压缩算法能够有效降低参数冗余,从而减少存储占用、通信带宽和计算复杂度,有助 于深度学习的应用部署,具体可划分为如下几种方法(后续重点介绍剪枝与量化):
① 线性或非线性量化:1/2bits, int8 和 fp16等;
② 结构或非结构剪枝:deep compression, channel pruning 和 network slimming等; ③ 知识蒸馏与网络结构简化(squeeze-net, mobile-net, shuffle-net)等;
二、剪枝
1、简介
本质是:0参数的替代,降低模型的推理复杂度
2、剪枝方式
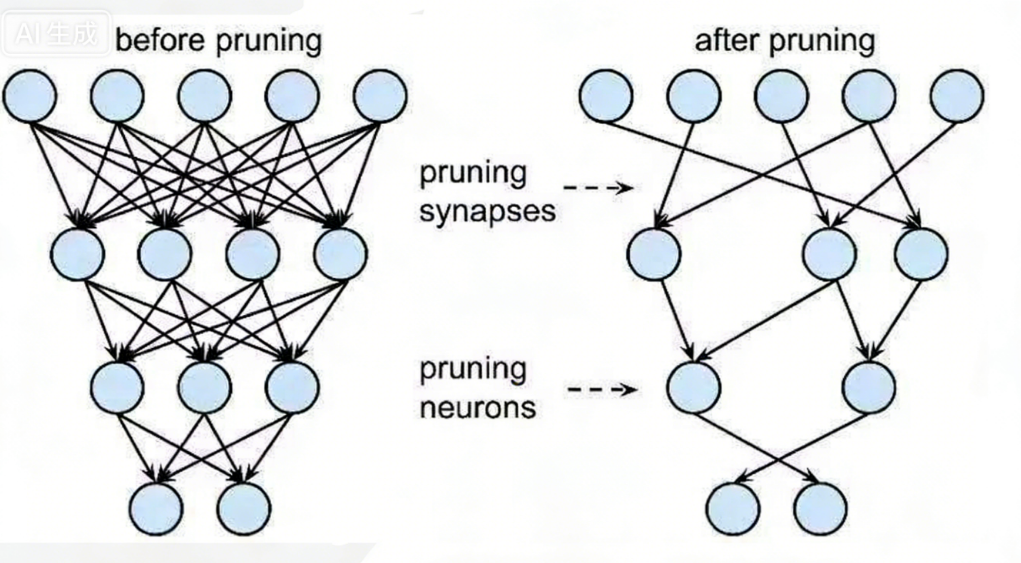
Ø非结构剪枝:通常是连接级、细粒度的剪枝方法,精度相对较高,但依赖于特定算法库或硬件平台的支持
Ø 结构剪枝:是filter级或layer级、粗粒度的剪枝方法,精度相对较低,但剪枝策略更为有效,不需要特定算法库或硬件平台的支持,能够直接在成熟深度学习框架上运行
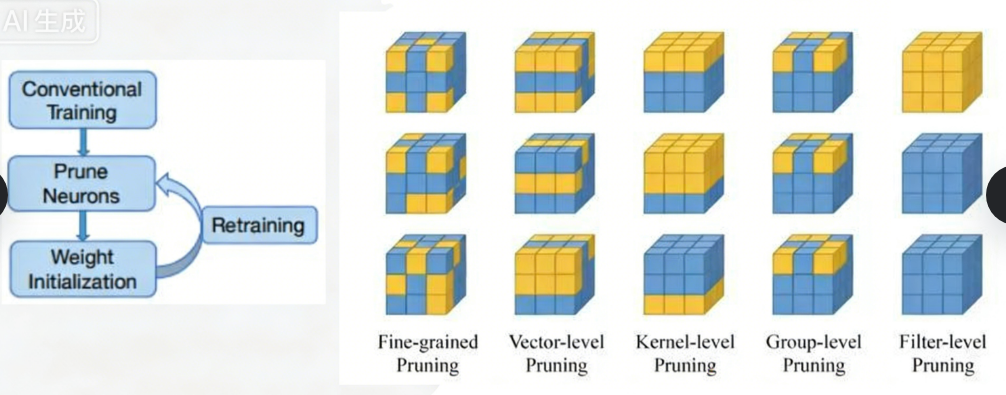
Ø局部方式的、通过layer by layer方式的、最小化输出FM重建误差的Channel Pruning,ThiNet Discrimination-aware Channel Pruning ;
Ø 全局方式的、通过训练期间对BN层Gamma系数施加L1正则约束的Network Slimming
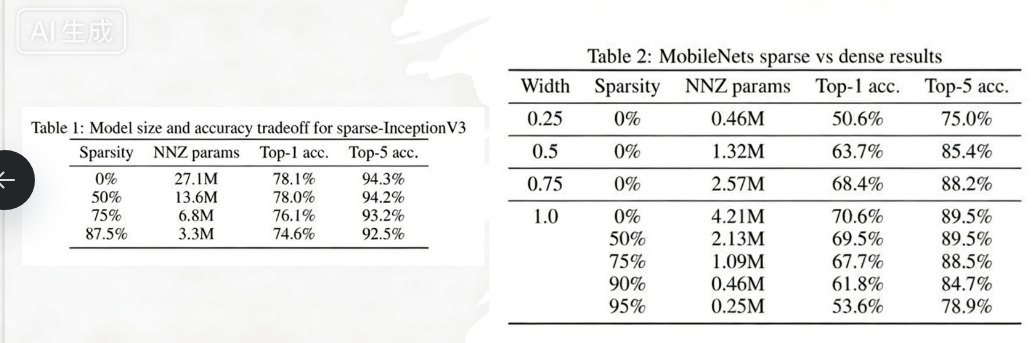
3、剪枝效果
参考
第一:无法降低模型的参数量
第二:剪枝本身是不可控的
第三:可能陷入循环
三、量化
1、(学术界)
Ø 低精度(Low precision)可能是最通用的概念。常规精度一般使用 FP32(32位浮点,单精度)存储模型权重;低精度则表示 FP16(半精度浮点),INT8(8位的定点整数)等等数值格式。不过目前低精度往往指代 INT8。
Ø 混合精度(Mixed precision)在模型中使用 FP32 和 FP16 。 FP16 减少了一半的内存大小,但有些参数或操作符必须采用 FP32 𝒜 格式才能保持准确度。如果您对该主题感兴趣,请查看 Mixed-Precision Training of Deep Neural Networks 。
Ø 量化一般指INT8。
Ø 根据存储一个权重元素所需的位数,还可以包括:
① 二值神经网络:在运行时权重和激活只取两种值(例如 +1,-1)的神经网络,以及 在训练时计算参数的梯度。
② 三元权重网络:权重约束为+1,0和-1的神经网络。
③ XNOR网络:过滤器和卷积层的输入是二进制的。 XNOR 网络主要使用二进制运算来近 似卷积。
2、(工业界)
理论是一回事,实践是另一回事。如果一种技术方法难以推广到通用场景,则需要进行大量的额外支持。花哨的研究往往是过于棘手或前提假设过强,以至几乎无法引入工业界的软件栈。
工业界最终选择了 INT8 量化------ FP32 在推理(inference)期间被 INT8 取代,而训练(training)仍然是 FP32。TensorRT,TensorFlow,PyTorch,MxNet 和许多其他深度学习软件都已启用(或正在启用)量化。
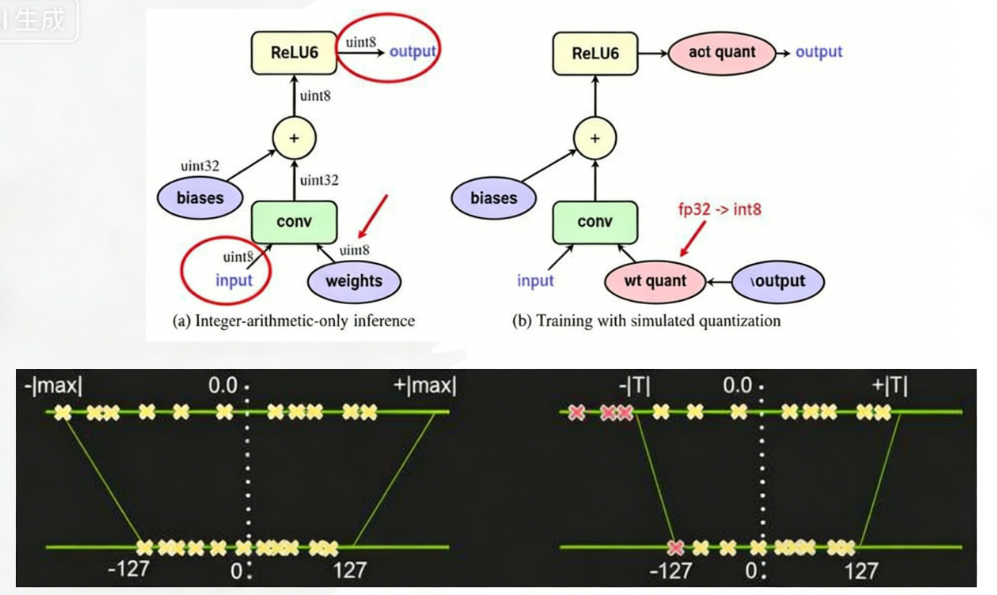
通常,可以根据 FP32 和 INT8 的转换机制对解决方案进行分类。一些框架简单地引入了Quantize 和 Dequantize 层,当从卷积或全链接层送入或取出时,它将 FP32 转换为INT8 或相反。在这种情况下,如图四的上半部分所示,模型本身和输入/输出采用 FP32格式。深度学习框架加载模型,重写网络以插入Quantize 和 Dequantize 层,并将权重转换为 INT8 格式。
3、量化原理
不影响模型的参数,比如以前是10w,量化后还是10w
只不过存储精度变低了,从1.000023521,变成了1.00001,,类似
但是在参与模型运算的参数/层,用的是原来的精度或者更高,计算完后再量化成8
4、效果
1、完全可控,计算复杂度成倍数降低
2、体积降低
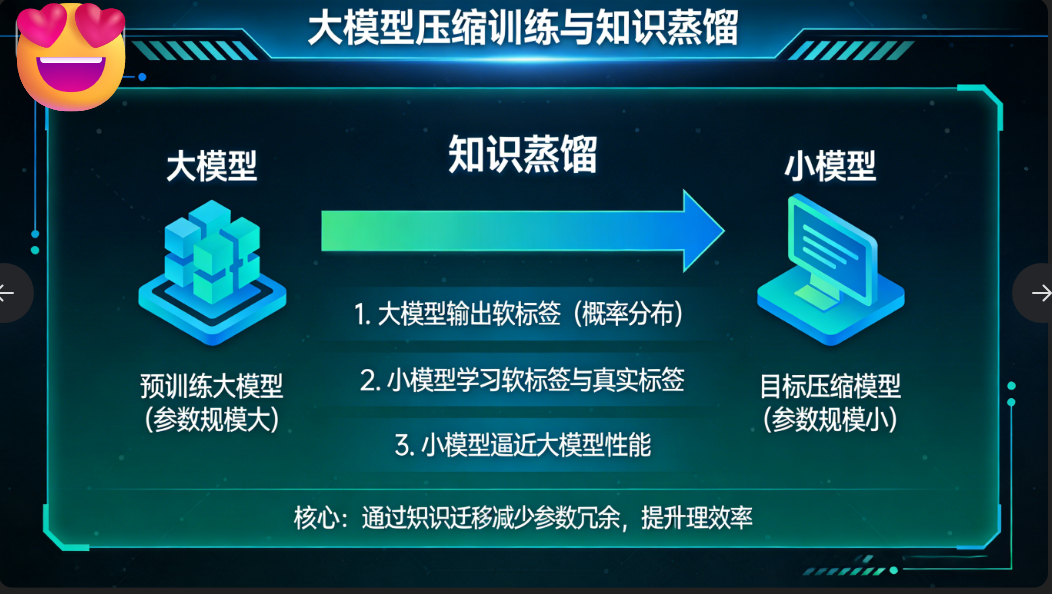
四、知识蒸馏
一般是为了小成本开发一个小模型,来实现商业落地比如YOLO
1、简介
本质:让一个小模型,去学习大模型已经学习好的知识
缺点:只能无限逼近大模型的成绩(二次预训练有可能达到或者超过)
前提:基于当前数据集,已经有一个训练好的大模型
困难:这个小模型怎么设计把控
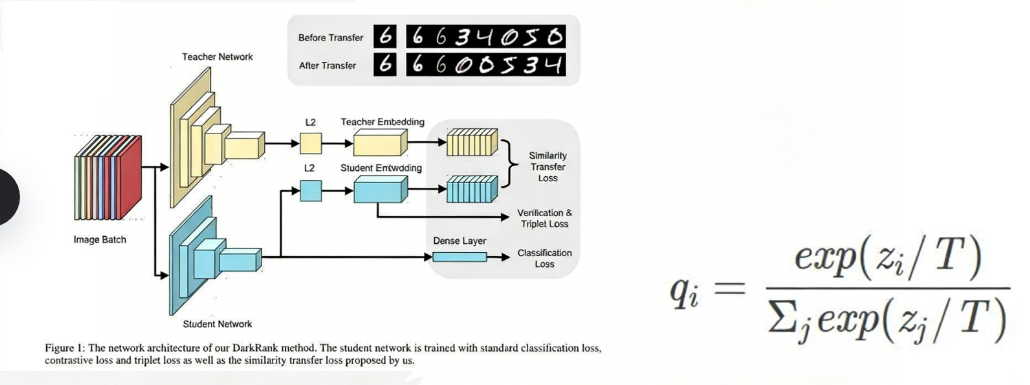
2、知识蒸馏在大模型中的应用
DeepSeek作为中国人工智能领域的代表性大模型, , 其训练过程中深度应用了知识蒸馏技术(Knowledge Dististillation),通过将大模型的知识迁移至小模型,实现了性能与效率的平衡。
3、知识蒸馏在DeepSeek中的核心意义
3.1.降低算力与成本
DeepSeek通过蒸馏技术将模型训练成本压缩至OpenAI同类模型的1/20。例如,DeepSeek-V3仅消耗278.8万GPU小时(成本约557.6万美元),而OpenAI类似模型的训练成本高达数亿美元49。这种低成本特性使中小企业也能负担高性能AI模型的开发。
3.2.加速推理与边缘部署
蒸馏后的小模型(如32B/70B版本)推理速度提升3倍以上,延迟从850ms降至150ms,显存占用从320GB减少至8GB。这使得模型可在手机、工业设备等边缘端实时运行,满足医疗诊断、自动驾驶等场景的低延迟需求
3.3.推动行业应用落地
教育领域:DeepSeek蒸馏模型可快速生成个性化学习内容,根据学生反馈动态调整教学策略,降低教育平台运营成本。
工业场景:本地化部署的蒸馏模型减少对云端的依赖,数据隐私与响应速度显著提升,助力智能制造中的质检、 ▾ 供应链优化等任务。
内容创作:AI写作工具结合蒸馏模型,创作效率提升 50% ,同时API调用成本仅为OpenAI的1/4,推动新媒体运营与创意产业发展。
3.4.技术自主可控
面对美国GPU芯片禁运,DeepSeek通过蒸馏技术降低对算力的依赖,结合FP8混合精度训练和DualPipe流水线机制,在国产芯片(如华为昇腾)上实现高性能推理,增强中国AI产业的自主可控能力。
4、蒸馏示例代码
环境在llama factory
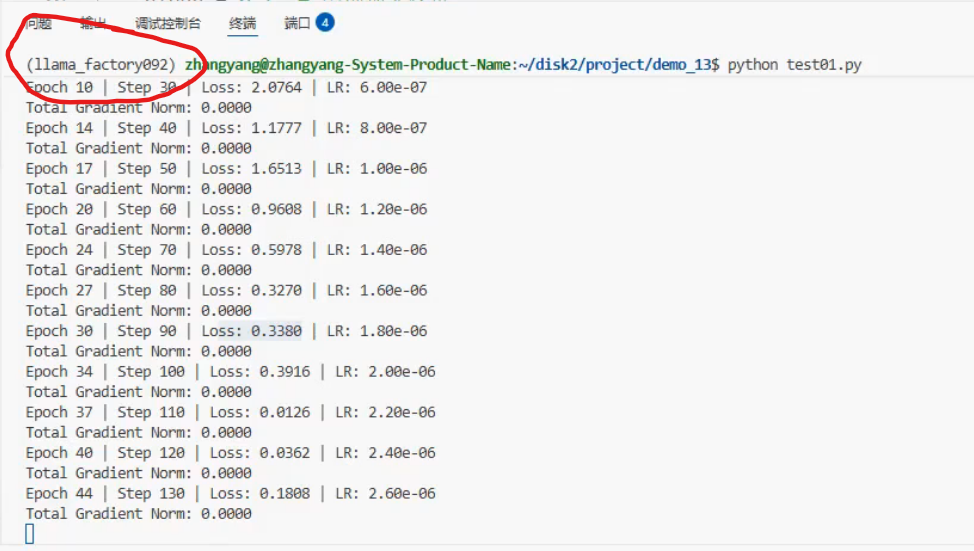
本地
在企业中,修改一下数据集,批次和模型就好了
pythonimport torch from transformers import AutoTokenizer, AutoModelForCausalLM from torch.utils.data import Dataset, DataLoader import torch.nn.functional as F from torch.optim import AdamW # ========== 配置参数 ========== class Config: # 模型设置 teacher_model_name = "/root/autodl-tmp/Qwen/Qwen1.5-1.8B-Chat" student_model_name = "/root/autodl-tmp/Qwen/Qwen1.5-0.5B-Chat" # 训练参数 batch_size = 1 num_epochs = 30 learning_rate = 1e-5 # 降低学习率 max_seq_length = 512 temperature = 3.0 # 降低温度值 alpha = 0.7 # 蒸馏损失权重 # 设备设置 device = "cuda" if torch.cuda.is_available() else "cpu" grad_accum_steps = 4 # 梯度累积步数 # 使用float32避免混合精度问题 dtype = torch.float32 config = Config() # ========== 数据加载 ========== class DistillationDataset(Dataset): def __init__(self, tokenizer, sample_texts=None): self.tokenizer = tokenizer self.examples = [] # 示例数据(实际需替换为真实数据集) sample_texts = [ "人工智能的核心理念是", "大语言模型蒸馏的关键在于", "深度学习模型的压缩方法包括", "知识蒸馏如何提高小模型性能", "Transformer架构的核心组件是", "注意力机制的工作原理", "模型量化如何减少计算资源", "神经网络剪枝的基本方法", "模型蒸馏中的温度参数作用", "如何评估蒸馏后模型的质量", "软标签与硬标签的区别", "蒸馏损失函数的设计原则", "教师模型与学生模型的选择", "蒸馏训练中的学习率调度", "如何防止蒸馏过程中的过拟合" ] for text in sample_texts: encoding = tokenizer( text, max_length=config.max_seq_length, padding="max_length", truncation=True, return_tensors="pt" ) self.examples.append(encoding) def __len__(self): return len(self.examples) def __getitem__(self, idx): return { "input_ids": self.examples[idx]["input_ids"].squeeze(), "attention_mask": self.examples[idx]["attention_mask"].squeeze() } # ========== 模型初始化 ========== def load_models(): # 加载教师模型(冻结参数) teacher = AutoModelForCausalLM.from_pretrained( config.teacher_model_name, device_map="auto", torch_dtype=config.dtype ).eval() # 加载学生模型 student = AutoModelForCausalLM.from_pretrained( config.student_model_name, device_map="auto", torch_dtype=config.dtype ).train() return teacher, student # ========== 蒸馏损失函数 ========== class DistillationLoss: @staticmethod def calculate( teacher_logits, # 教师模型logits [batch, seq_len, vocab] student_logits, # 学生模型logits [batch, seq_len, vocab] attention_mask, # 注意力掩码 temperature=config.temperature, alpha=config.alpha ): # 1. 添加数值稳定性处理 teacher_logits = torch.clamp(teacher_logits, min=-1e4, max=1e4) student_logits = torch.clamp(student_logits, min=-1e4, max=1e4) # 2. 软目标蒸馏损失 soft_teacher = F.softmax(teacher_logits / temperature, dim=-1) soft_student = F.log_softmax(student_logits / temperature, dim=-1) # 3. 添加掩码处理,避免填充位置影响损失 mask = attention_mask.unsqueeze(-1).expand_as(soft_teacher) kl_loss = F.kl_div( soft_student, soft_teacher, reduction="none", log_target=False ) kl_loss = (kl_loss * mask).sum() / mask.sum() # 平均每个token的损失 kl_loss = kl_loss * (temperature ** 2) # 4. 学生自训练损失(交叉熵) shift_logits = student_logits[..., :-1, :].contiguous() shift_labels = teacher_logits.argmax(-1)[..., 1:].contiguous() # 5. 使用掩码过滤填充位置 shift_mask = attention_mask[..., 1:].contiguous() ce_loss = F.cross_entropy( shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1), reduction="none" ) ce_loss = (ce_loss * shift_mask.view(-1)).sum() / shift_mask.sum() # 6. 确保损失值有效 if torch.isnan(kl_loss).any() or torch.isnan(ce_loss).any(): kl_loss = torch.tensor(0.0, device=kl_loss.device) ce_loss = torch.tensor(0.0, device=ce_loss.device) print("NaN loss detected, resetting to zero") return alpha * kl_loss + (1 - alpha) * ce_loss # ========== 训练流程 ========== def train(): # 初始化组件 tokenizer = AutoTokenizer.from_pretrained(config.teacher_model_name) teacher, student = load_models() # 确保学生模型在正确设备上 student.to(config.device) # 数据集示例 dataset = DistillationDataset(tokenizer) dataloader = DataLoader(dataset, batch_size=config.batch_size) # 优化器设置 optimizer = AdamW(student.parameters(), lr=config.learning_rate, weight_decay=0.01) step_count = 0 # 训练循环 for epoch in range(config.num_epochs): for batch_idx, batch in enumerate(dataloader): inputs = {k: v.to(config.device) for k, v in batch.items()} # 教师模型前向(不计算梯度) with torch.no_grad(): teacher_outputs = teacher(**inputs) # 学生模型前向 student_outputs = student(**inputs) # 添加注意力掩码到损失计算 loss = DistillationLoss.calculate( teacher_outputs.logits, student_outputs.logits, inputs["attention_mask"] ) # 检查损失是否为NaN if torch.isnan(loss): print("NaN loss detected, skipping backward pass") optimizer.zero_grad() continue # 反向传播(带梯度累积) (loss / config.grad_accum_steps).backward() if (batch_idx + 1) % config.grad_accum_steps == 0: # 梯度裁剪 torch.nn.utils.clip_grad_norm_(student.parameters(), 1.0) # 参数更新 optimizer.step() optimizer.zero_grad() step_count += 1 # 学习率调整(示例) warmup_steps = 500 if step_count < warmup_steps: lr = config.learning_rate * step_count / warmup_steps else: lr = config.learning_rate * (warmup_steps ** 0.5) / (step_count ** 0.5) for param_group in optimizer.param_groups: param_group['lr'] = lr # 打印训练信息 if step_count % 10 == 0: print(f"Epoch {epoch + 1} | Step {step_count} | Loss: {loss.item():.4f} | LR: {lr:.2e}") # 添加梯度检查 total_grad_norm = 0.0 for name, param in student.named_parameters(): if param.grad is not None: grad_norm = param.grad.data.norm(2).item() total_grad_norm += grad_norm ** 2 if torch.isnan(param.grad).any() or torch.isinf(param.grad).any(): print(f"NaN or Inf gradient in {name}") if grad_norm > 1e3: # 梯度值过大 print(f"Large gradient in {name}: {grad_norm:.4f}") total_grad_norm = total_grad_norm ** 0.5 print(f"Total Gradient Norm: {total_grad_norm:.4f}") # 保存蒸馏后的模型 student.save_pretrained("./distilled_qwen") tokenizer.save_pretrained("./distilled_qwen") if __name__ == "__main__": train()
api
python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F
from torch.optim import AdamW
import openai
import os
from tqdm import tqdm
import json
# ========== 配置参数 ==========
class Config:
# API 设置(DeepSeek)
api_key = "your-deepseek-api-key" # 请替换为真实 API Key
base_url = "https://api.deepseek.com/v1" # DeepSeek API 地址
teacher_model_name = "deepseek-chat" # DeepSeek-V3 模型名
student_model_name = "/root/autodl-tmp/Qwen/Qwen1.5-0.5B-Chat" # 本地学生模型
# 训练参数
batch_size = 1
num_epochs = 30
learning_rate = 1e-5
max_seq_length = 512
temperature = 3.0 # 已不再使用,保留兼容
alpha = 0.7 # 已不再使用,保留兼容
# 设备设置
device = "cuda" if torch.cuda.is_available() else "cpu"
grad_accum_steps = 4
# 数据缓存文件(可选,避免重复调用API)
cache_file = "teacher_outputs.json"
config = Config()
# 初始化 OpenAI 客户端(DeepSeek 兼容 OpenAI 接口)
client = openai.OpenAI(
api_key=config.api_key,
base_url=config.base_url
)
# ========== 教师模型 API 调用类 ==========
class DeepSeekTeacher:
def __init__(self, client):
self.client = client
def generate(self, prompt: str, max_tokens=256, temperature=0.7):
"""调用 DeepSeek API 生成文本"""
try:
response = self.client.chat.completions.create(
model=config.teacher_model_name,
messages=[
{"role": "user", "content": prompt}
],
max_tokens=max_tokens,
temperature=temperature,
stream=False
)
return response.choices[0].message.content
except Exception as e:
print(f"API 调用失败: {e}")
return ""
# ========== 数据集类(含教师生成缓存) ==========
class DistillationDataset(Dataset):
def __init__(self, tokenizer, teacher, sample_texts=None, cache_file=None):
self.tokenizer = tokenizer
self.examples = []
if sample_texts is None:
sample_texts = [
"人工智能的核心理念是",
"大语言模型蒸馏的关键在于",
"深度学习模型的压缩方法包括",
"知识蒸馏如何提高小模型性能",
"Transformer架构的核心组件是",
"注意力机制的工作原理",
"模型量化如何减少计算资源",
"神经网络剪枝的基本方法",
"模型蒸馏中的温度参数作用",
"如何评估蒸馏后模型的质量",
"软标签与硬标签的区别",
"蒸馏损失函数的设计原则",
"教师模型与学生模型的选择",
"蒸馏训练中的学习率调度",
"如何防止蒸馏过程中的过拟合"
]
# 尝试从缓存加载教师输出
if cache_file and os.path.exists(cache_file):
with open(cache_file, 'r', encoding='utf-8') as f:
cached = json.load(f)
for text in sample_texts:
if text in cached:
teacher_output = cached[text]
else:
# 缓存缺失则调用 API 并保存
teacher_output = teacher.generate(text)
cached[text] = teacher_output
with open(cache_file, 'w', encoding='utf-8') as f:
json.dump(cached, f, ensure_ascii=False, indent=2)
else:
# 无缓存,逐条调用 API
cached = {}
for text in tqdm(sample_texts, desc="调用教师模型生成"):
teacher_output = teacher.generate(text)
cached[text] = teacher_output
if cache_file:
with open(cache_file, 'w', encoding='utf-8') as f:
json.dump(cached, f, ensure_ascii=False, indent=2)
# 构建训练样本(输入 prompt + 教师输出)
for text in sample_texts:
teacher_output = cached[text]
if not teacher_output:
continue # 跳过生成失败的样本
# 将 prompt 和教师输出拼接成完整输入
full_text = text + teacher_output
encoding = tokenizer(
full_text,
max_length=config.max_seq_length,
padding="max_length",
truncation=True,
return_tensors="pt"
)
# 标签:教师输出的 token ids(需要对齐输入)
# 注意:教师输出的起始位置是 len(text tokens) 之后
input_ids = encoding["input_ids"].squeeze()
attention_mask = encoding["attention_mask"].squeeze()
# 计算教师输出在输入中的起始位置
prompt_tokens = tokenizer(text, add_special_tokens=False)["input_ids"]
prompt_len = len(prompt_tokens)
# 标签序列:教师输出的 token ids(忽略 prompt 部分)
# 需要与输入对齐,在 prompt 部分使用 -100 忽略损失
labels = input_ids.clone()
labels[:prompt_len] = -100 # 忽略 prompt 部分的损失
# 确保 labels 长度与输入一致
labels[prompt_len:] = input_ids[prompt_len:]
self.examples.append({
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
})
def __len__(self):
return len(self.examples)
def __getitem__(self, idx):
return {
"input_ids": self.examples[idx]["input_ids"],
"attention_mask": self.examples[idx]["attention_mask"],
"labels": self.examples[idx]["labels"]
}
# ========== 模型初始化 ==========
def load_student():
student = AutoModelForCausalLM.from_pretrained(
config.student_model_name,
device_map="auto",
torch_dtype=torch.float32
).train()
return student
# ========== 损失函数(仅交叉熵) ==========
def compute_loss(student_logits, labels, attention_mask):
"""
student_logits: [batch, seq_len, vocab]
labels: [batch, seq_len],其中 -100 忽略位置
attention_mask: [batch, seq_len] 用于过滤填充(可选,但 labels 已用 -100)
"""
# 使用 huggingface 内置的交叉熵损失(自动忽略 -100)
loss_fct = torch.nn.CrossEntropyLoss(ignore_index=-100)
# 将 logits 和 labels 展平
shift_logits = student_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
loss = loss_fct(
shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1)
)
return loss
# ========== 训练流程 ==========
def train():
# 初始化 tokenizer 和 学生模型
tokenizer = AutoTokenizer.from_pretrained(config.student_model_name)
student = load_student()
student.to(config.device)
# 初始化教师 API
teacher = DeepSeekTeacher(client)
# 数据集(会调用 API 生成教师输出)
dataset = DistillationDataset(tokenizer, teacher, cache_file=config.cache_file)
dataloader = DataLoader(dataset, batch_size=config.batch_size, shuffle=True)
# 优化器
optimizer = AdamW(student.parameters(), lr=config.learning_rate, weight_decay=0.01)
step_count = 0
for epoch in range(config.num_epochs):
for batch_idx, batch in enumerate(dataloader):
inputs = {k: v.to(config.device) for k, v in batch.items()}
labels = inputs.pop("labels") # 移除标签,不作为模型输入
# 学生模型前向
outputs = student(**inputs)
student_logits = outputs.logits
# 计算损失
loss = compute_loss(student_logits, labels, inputs["attention_mask"])
# 检查损失
if torch.isnan(loss):
print("NaN loss detected, skipping")
optimizer.zero_grad()
continue
# 反向传播(梯度累积)
(loss / config.grad_accum_steps).backward()
if (batch_idx + 1) % config.grad_accum_steps == 0:
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(student.parameters(), 1.0)
optimizer.step()
optimizer.zero_grad()
step_count += 1
# 学习率预热(可选)
warmup_steps = 500
if step_count < warmup_steps:
lr = config.learning_rate * step_count / warmup_steps
else:
lr = config.learning_rate * (warmup_steps ** 0.5) / (step_count ** 0.5)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# 打印信息
if step_count % 10 == 0:
print(f"Epoch {epoch+1} | Step {step_count} | Loss: {loss.item():.4f} | LR: {lr:.2e}")
# 保存模型
student.save_pretrained("./distilled_student")
tokenizer.save_pretrained("./distilled_student")
print("训练完成,模型已保存。")
if __name__ == "__main__":
train()