最近有空入坑了cs336,在做大作业之前,汇总一下能薅算力的地方吧,后面三张图是获取GPU的方式~
1. kaggle
https://www.kaggle.com/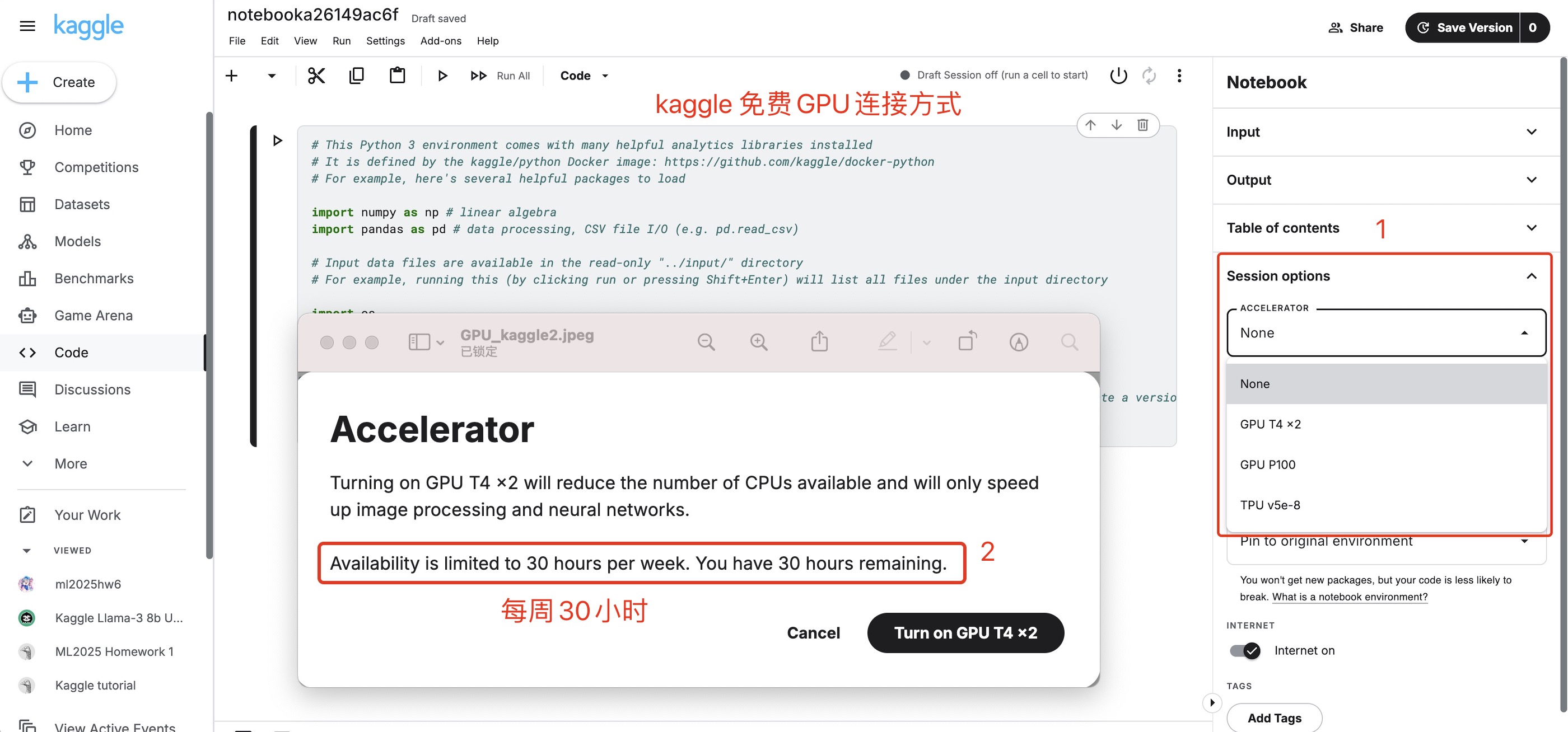 kaggle每周30个小时的算力,GPU是两块T4或者一块P100,比较稳定。缺点是需要🪜,以及我去年做李宏毅作业的时候,Kaggle的环境配置很耗费时间,或许是我去年打开方式不太正确。
kaggle每周30个小时的算力,GPU是两块T4或者一块P100,比较稳定。缺点是需要🪜,以及我去年做李宏毅作业的时候,Kaggle的环境配置很耗费时间,或许是我去年打开方式不太正确。
2.Google colab
https://colab.research.google.com/
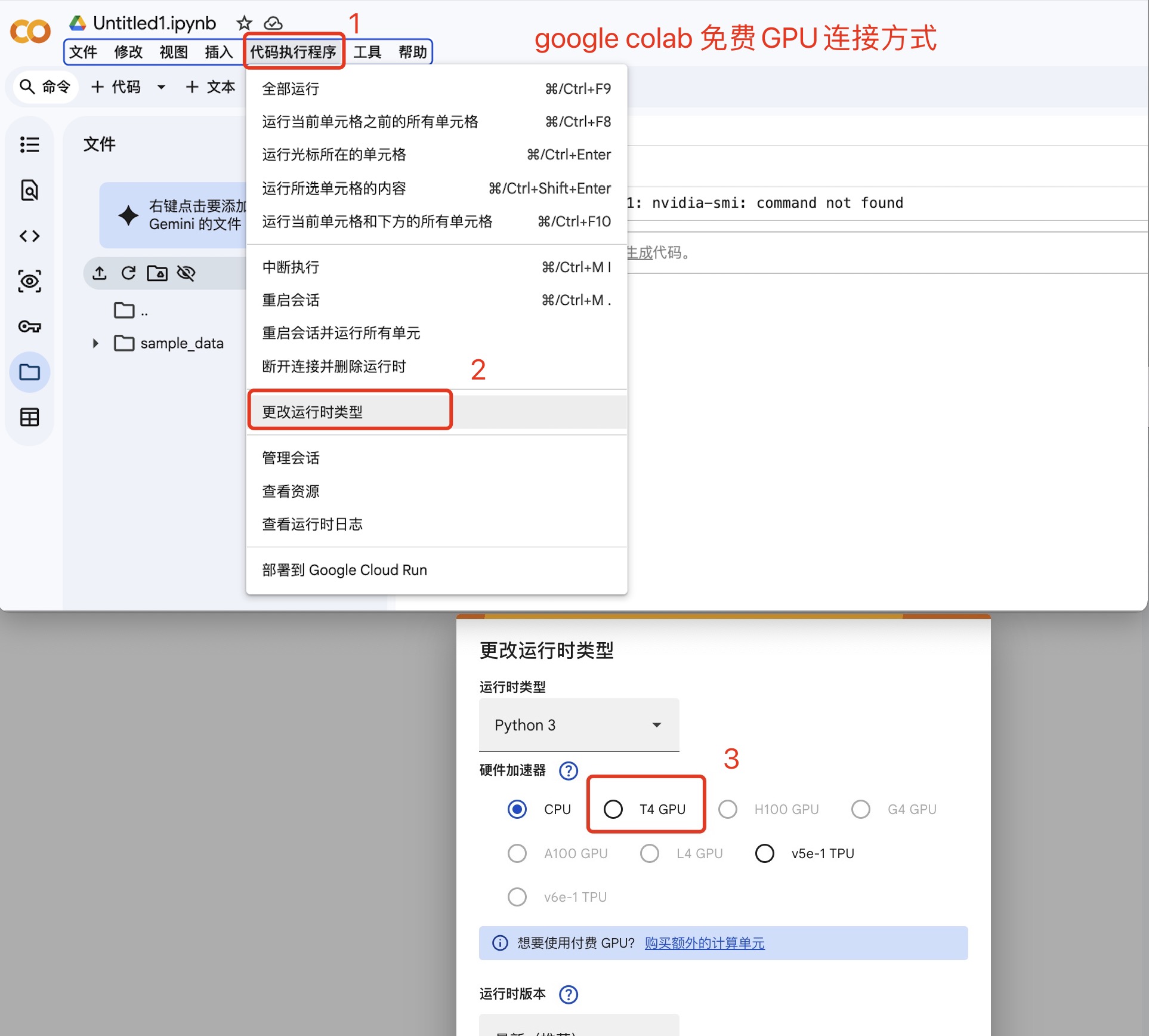
每次12小时的免费GPU算力,一块T4,其实不到12小时就会用完,用完之后可能几天或者几周才能重新获得。优点是深度学习、LLM常用库都装好了,而且非常方便跟Gemini交互。缺点是,需要🪜,且比较容易断连(不要息屏)。
3. 看图
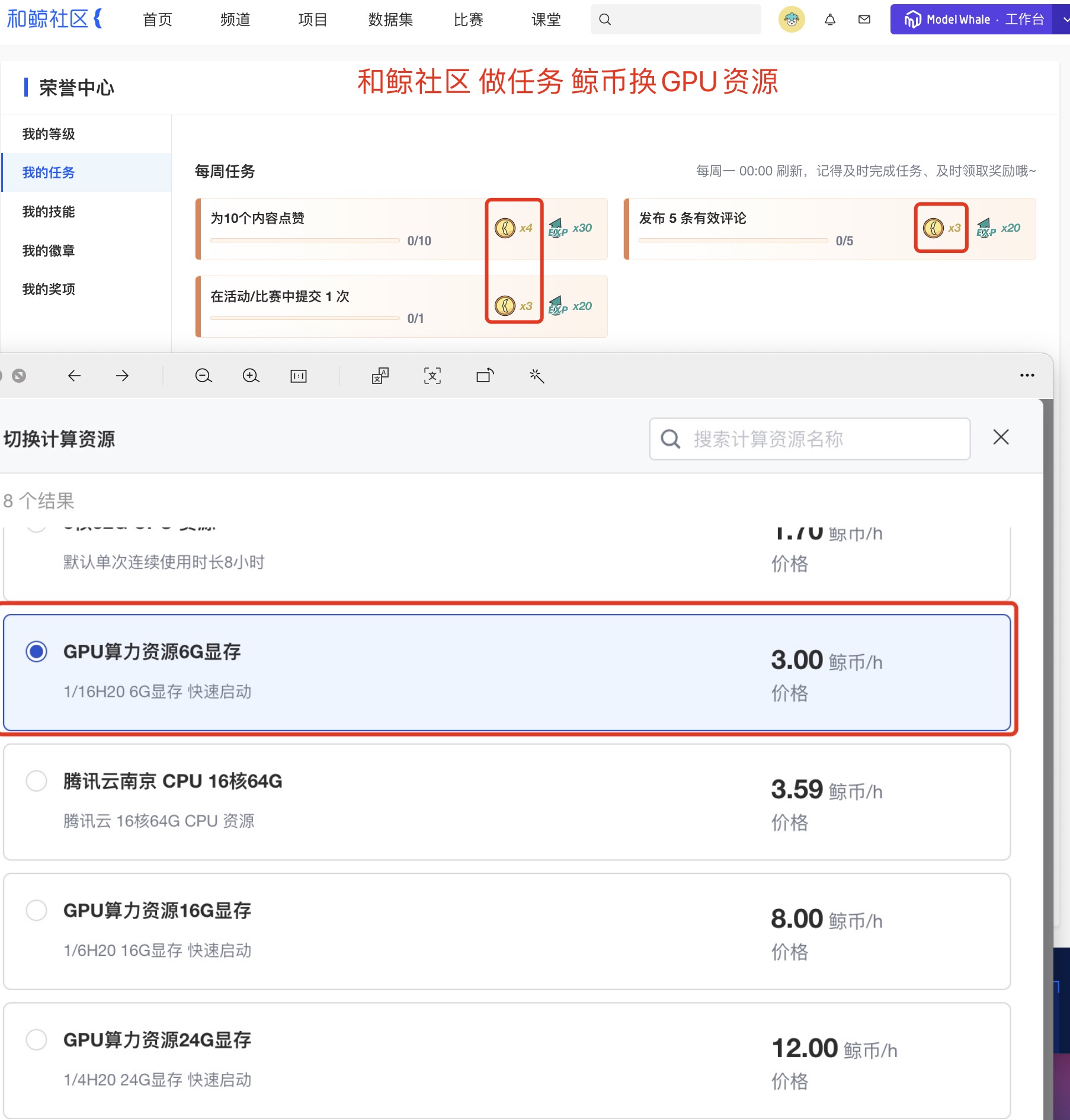
最后,最方便的还是,直接云服务器租一个带GPU的(这种问题充钱就能解决.jpg) 哈哈哈