MySQL篇 索引失效
距离上次学习数据库已经是上次,觉得老是有点混乱,所以借博客之名好好整理一下。
索引是怎么存的?
InnoDB默认使用B+树作为索引结构,它是一种平衡多路查找树,和二叉树、红黑树相比,更适合磁盘存储的场景,能大幅减少磁盘IO次数。我们重点关注两个核心索引类型和B+树的核心特性:
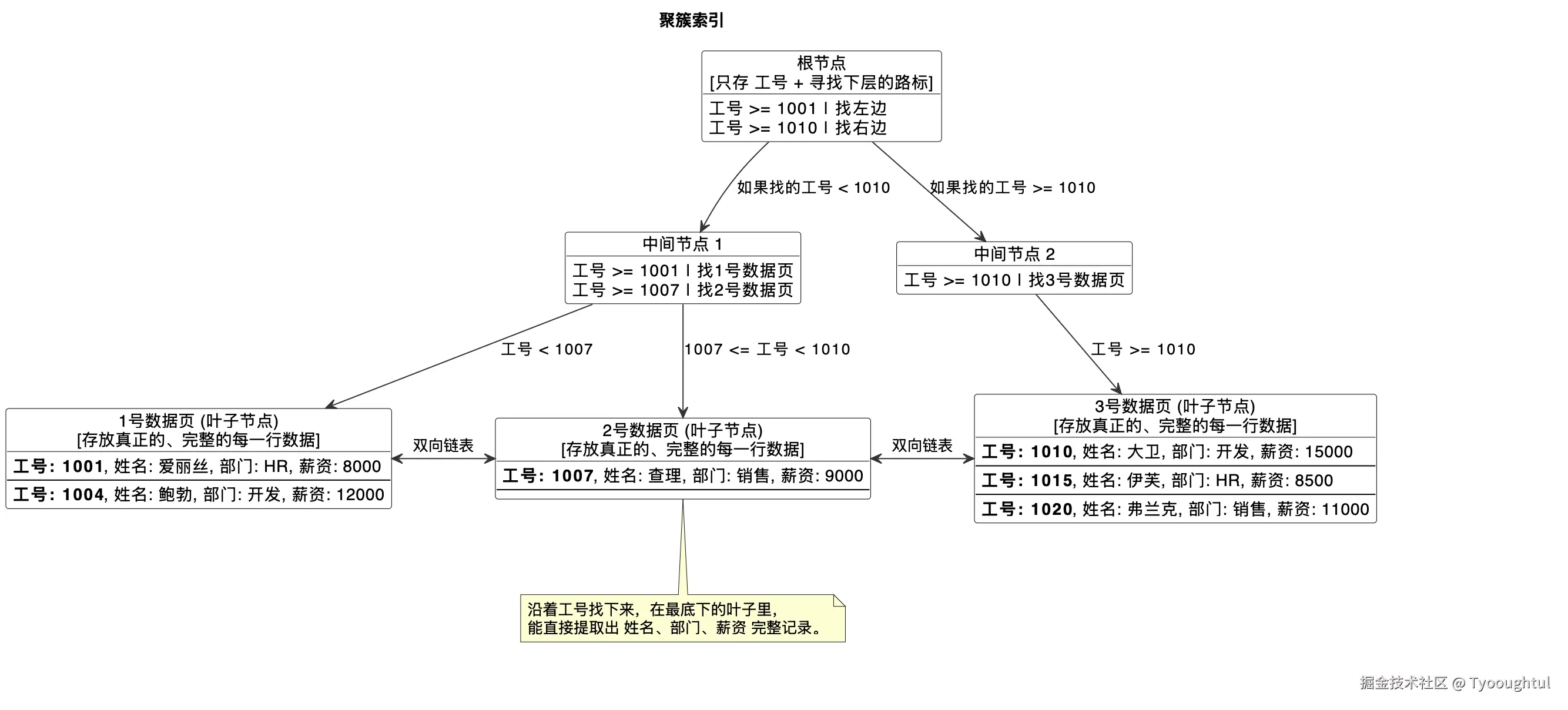
聚簇索引(也叫主键索引)
- 聚簇索引的B+树,叶子节点存储的是整行数据,非叶子节点只存储主键值和指向子节点的指针。
- 整张表的数据,会按照主键的大小,有序地组织在聚簇索引的叶子节点上,数据页之间通过双向链表连接,数据页内的记录通过单向链表连接。
- 一张表只能有一个聚簇索引,默认就是主键索引;没有定义主键时,InnoDB会自动选择唯一非空索引替代;都没有的话,会生成隐藏的ROWID作为聚簇索引。
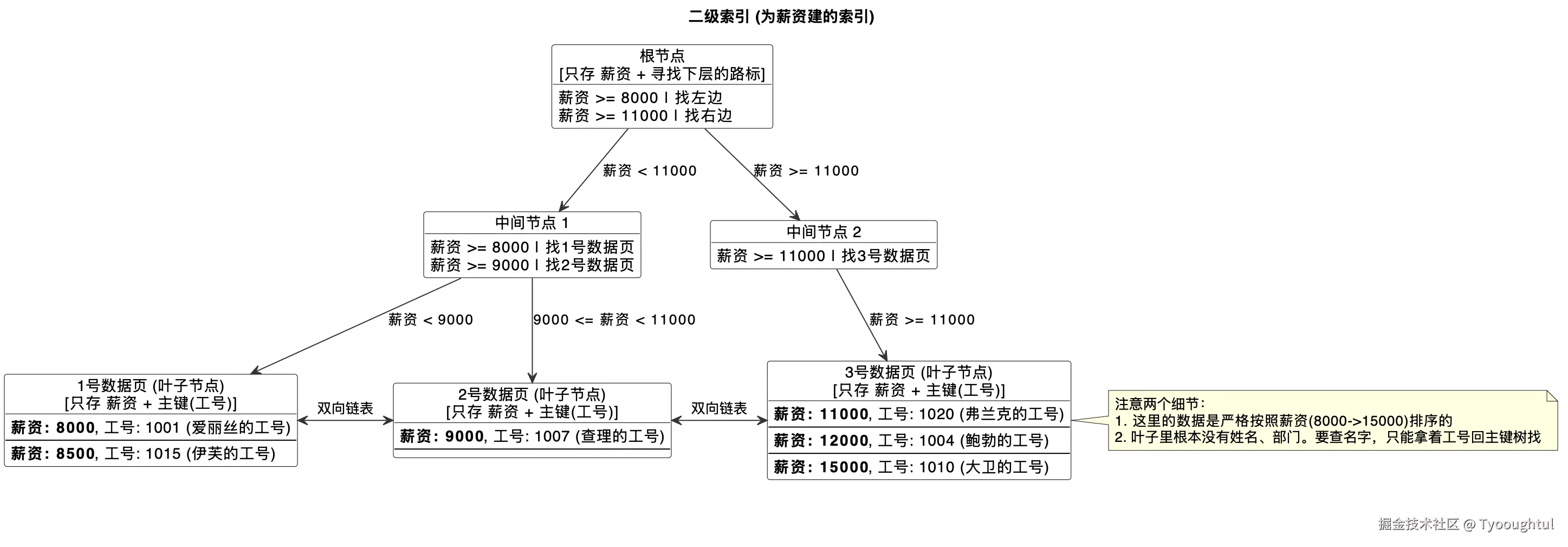
二级索引(非主键索引/辅助索引)
- 二级索引的B+树,叶子节点只存储索引列的值和对应的主键值,非叶子节点只存储索引列的值和子节点指针。
- 二级索引的所有记录,严格按照索引列的原始值进行排序;如果是联合索引,则先按第一列排序,第一列值相同时,再按第二列排序,以此类推。
- 通过二级索引查询完整行数据时,需要先在二级索引B+树中找到对应的主键值,再拿着主键去聚簇索引中查找整行数据,这个过程叫做回表。
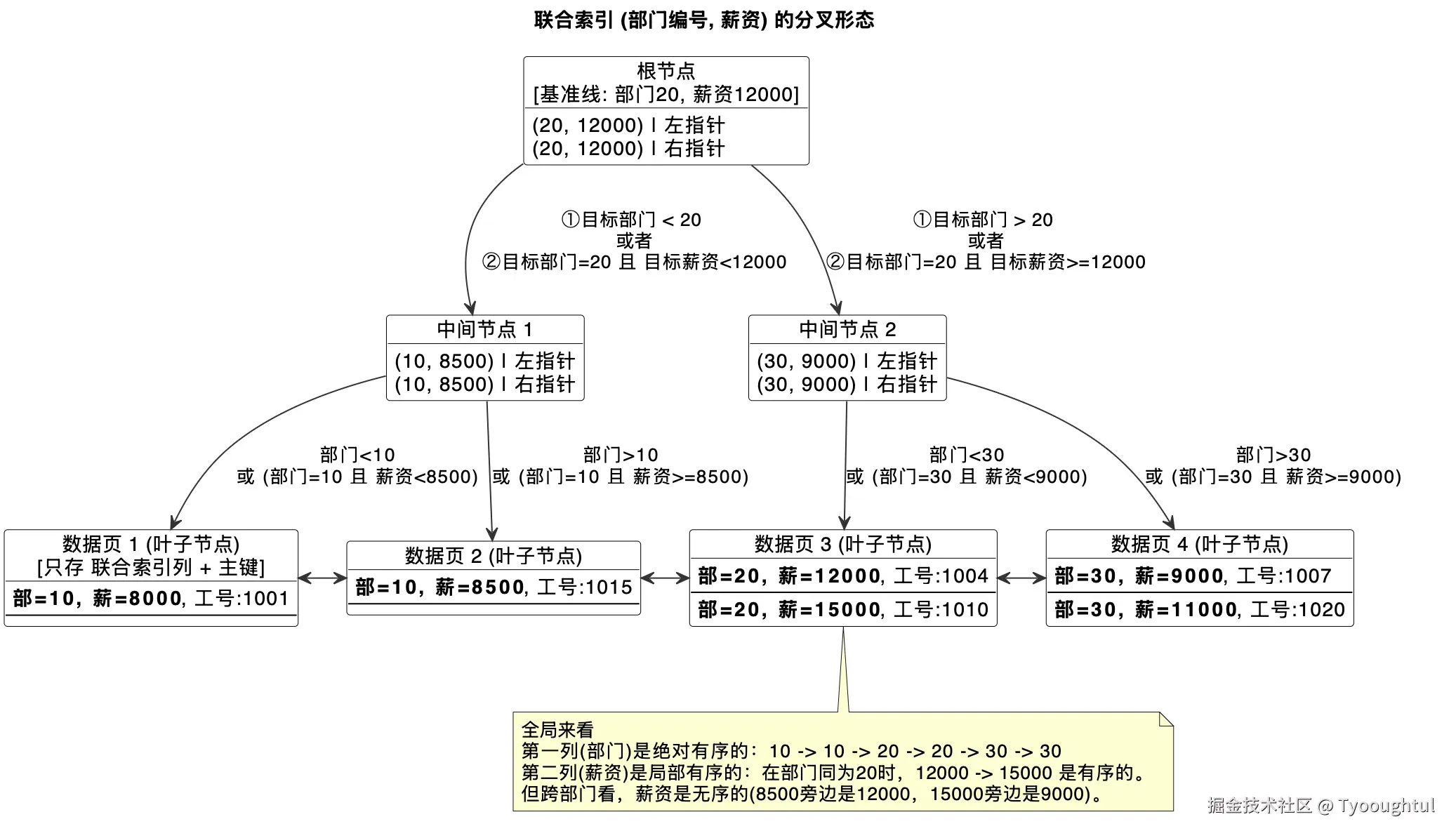
1张表有且仅有1棵聚簇索引的B+树,每额外新建1个索引(单列索引/联合索引,都算1个独立索引),就会新增1棵完全独立的二级索引B+树。联合索引的话可以参照这个图:
索引能生效的原因
索引能被优化器选中并正常使用,核心是优化器可以利用B+树的有序性,通过二分查找快速定位到符合条件的记录的起止位置,实现精准的范围扫描或等值查询,一旦SQL的查询条件无法利用B+树的有序性,或者优化器计算后认为走索引的成本比全表扫描更高,就会放弃索引,也就是我们说的索引失效。
从B+树来看,为什么失效?
对索引列使用函数运算/表达式计算
失效示例:
sql
-- 对索引列做left函数运算
SELECT * FROM user WHERE LEFT(name,3) = '张三';
-- 对索引列做表达式计算
SELECT * FROM user WHERE id + 1 = 100;
-- 对索引列做日期函数处理
SELECT * FROM user WHERE DATE(create_time) = '2026-03-01';失效原因 : B+树的排序规则,是基于索引列的原始值构建的,而非函数运算后的结果。当你对索引列施加函数/表达式后,得到的是一个全新的值,这个值和原B+树的排序规则完全不匹配。
比如LEFT(name,3),原索引中name列是按完整字符串的字典序排序的,截取前3位后,新值的排序和原排序完全脱节,MySQL无法通过二分查找在原B+树中定位到起止位置,只能遍历二级索引的所有叶子节点,甚至直接走全表扫描,索引完全失效。
正确写法:避免对索引列做任何处理,将运算移到常量一侧:
sql
SELECT * FROM user WHERE name LIKE '张三%';
SELECT * FROM user WHERE id = 99;
SELECT * FROM user WHERE create_time >= '2026-03-01' AND create_time < '2026-03-02';索引列发生隐式类型转换
失效示例:
sql
-- phone列是varchar(11)类型,查询条件用了数字类型
SELECT * FROM user WHERE phone = 13800138000;
-- age列是int类型,查询条件用了字符串类型(不会失效,注意区分)
SELECT * FROM user WHERE age = '18';失效原因 : 隐式类型转换的本质,是MySQL优化器自动对索引列施加了CAST函数,和场景1的函数运算完全一致,直接破坏了B+树的有序性。
这里有一个区分规则:当索引列的类型和查询常量的类型不一致时,MySQL会按照类型优先级进行转换。如果转换的对象是索引列,索引就会失效,如果转换的对象是常量,索引不会失效。
比如varchar类型的phone和数字常量对比,数字的优先级更高,MySQL会把phone列的所有字符串值转为数字,再和常量对比。原B+树是按字符串字典序排序的,转为数字后排序规则完全改变(比如字符串'10'排在'2'前面,转为数字后2排在10前面),无法利用有序性,索引失效。
而int类型的age和字符串常量'18'对比,MySQL会把常量'18'转为数字18,索引列本身没有任何修改,B+树的有序性完全保留,所以索引正常生效。
note: 除了数据类型隐式转换,还有一种容易被忽略的场景,字符集不一致。
失效示例:
sql
-- user表的name列是utf8字符集,order表的user_name列是utf8mb4字符集
-- 关联查询时,MySQL会自动把utf8的name转成utf8mb4,导致user表的name索引失效
SELECT * FROM user u JOIN `order` o ON u.name = o.user_name;字符集也有优先级,utf8mb4 > utf8。MySQL会把低优先级的列转成高优先级,相当于对索引列施加了 CONVERT(name USING utf8mb4),破坏了B+树的有序性。所以应该确保关联字段的字符集完全一致。建表时就要规划好,不要混用字符集。
模糊查询以通配符%开头
失效示例:
sql
-- 前缀%,索引失效
SELECT * FROM user WHERE name LIKE '%张三';
-- 前后都有%,索引失效
SELECT * FROM user WHERE name LIKE '%张三%';
-- 后缀%,前缀匹配,索引正常生效
SELECT * FROM user WHERE name LIKE '张三%';失效原因 : 字符串类型的索引B+树,是按照字符串的前缀字符字典序 排序的。比如name列的索引,会先按第一个字符排序,第一个字符相同再按第二个,以此类推。
当使用%张三这种后缀匹配时,前缀是完全不确定的,MySQL无法在有序的B+树中定位到查询的起始位置,只能遍历所有叶子节点逐行判断,索引完全失效。
而张三%这种前缀匹配,能精准定位到第一个字符是张、第二个是三的记录区间,完全可以利用B+树的有序性做二分查找,所以索引正常生效。
解决方案 :如果必须使用后缀模糊查询,MySQL8.0以上可以使用函数索引,MySQL5.7可以用反转列存储:
sql
-- MySQL8.0 函数索引
CREATE INDEX idx_name_reverse ON user(REVERSE(name));
SELECT * FROM user WHERE REVERSE(name) LIKE REVERSE('%张三');
-- MySQL5.7 新增反转列,建索引
ALTER TABLE user ADD COLUMN name_reverse VARCHAR(32) GENERATED ALWAYS AS (REVERSE(name)) STORED;
CREATE INDEX idx_name_reverse ON user(name_reverse);联合索引违背最左前缀原则
失效示例 : 我们给user表创建联合索引idx_name_phone_age (name,phone,age),以下SQL会出现索引部分失效或完全失效:
sql
-- 完全跳过第一列,索引完全失效
SELECT * FROM user WHERE phone = '13800138000' AND age = 18;
-- 中间列断档,仅第一列name生效,phone和age失效
SELECT * FROM user WHERE name = '张三' AND age = 18;
-- 范围查询之后的列,索引失效
SELECT * FROM user WHERE name = '张三' AND phone > '13800000000' AND age = 18;失效原因 : 联合索引的B+树,排序规则是严格的层级有序 :先按第一列name排序,只有name值相同的记录,才会按第二列phone排序;只有name和phone都相同的记录,才会按第三列age排序。
最左前缀原则的本质,就是只有保证前面的列是等值查询,才能利用后面列的有序性。我们逐个拆解示例:
- 跳过第一列
name:整个B+树的最外层排序都无法利用,完全找不到定位区间,索引完全失效。 - 中间
phone列断档:name是等值查询,可以定位到name='张三'的区间,但这个区间内phone是无序的,更别说age了,所以只能在name='张三'的范围内全扫描,后面的列索引失效。 phone列用了范围查询:name='张三'且phone>'13800000000'的区间内,phone是递增的,而age只有在phone值相同的时候才有序,phone不同的情况下age是完全乱序的,无法利用二分查找,所以age列索引失效。
note:
如果范围查询是联合索引的最后一列,前面所有列都能用到索引
sql
-- 范围查询在最后一列age,name、phone、age都能用到索引
SELECT * FROM user WHERE name = '张三' AND phone = '13800138000' AND age > 18;原因很简单,前面列都是等值查询,定位到一个小区间后,最后一列在这个区间内是有序的,范围查询可以正常利用。
使用不等于、not in、is not null等反向查询
失效示例:
sql
-- 不等于查询,大概率索引失效
SELECT * FROM user WHERE id != 100;
SELECT * FROM user WHERE age <> 18;
-- not in查询,索引失效
SELECT * FROM user WHERE age NOT IN (18,20,22);
-- is not null查询,索引失效
SELECT * FROM user WHERE name IS NOT NULL;失效原因 : 这类反向查询的本质,是排除一个或少数几个值,需要查询B+树中除了排除值之外的绝大部分数据。
B+树的优势是精准定位小范围的区间,而反向查询的结果集通常覆盖了索引的大部分节点,此时优化器会做成本判断:如果走二级索引,需要遍历几乎整个二级索引B+树,还要做大量的回表随机IO;而全表扫描是聚簇索引的顺序IO,成本反而更低。最终优化器会放弃索引,走全表扫描。
note:
-
如果是主键的反向查询,且结果集很小,比如
id not in (1,2,3),表有100万行数据,此时索引会正常生效。 -
is null是可以走索引的,因为B+树中null值会集中存储,能精准定位到null的区间,而is not null是排除null,覆盖绝大部分数据,所以失效。 -
覆盖索引例外,如果查询的列正好是索引列本身,不需要回表,索引可以生效:
sql-- name列有索引,只查name,is not null也能走索引 SELECT name FROM user WHERE name IS NOT NULL;虽然是全索引扫描,但比全表扫描好,因为索引比表数据小得多。
OR连接的条件中包含非索引列
失效示例:
sql
-- name有索引,age无索引,OR连接后索引失效
SELECT * FROM user WHERE name = '张三' OR age = 18;失效原因 : name='张三'可以通过索引快速定位,但age=18没有索引,必须通过全表扫描才能找到所有符合条件的记录。如果只走name索引,会漏掉age=18但name!='张三'的记录,为了保证结果的准确性,MySQL只能直接走全表扫描,索引完全失效。
note:如果OR两边的列都有独立索引,MySQL可能会走index merge索引合并,分别从两个索引中找到符合条件的记录,再合并结果集,此时索引不会失效。
优化器选错索引
失效示例:
sql
-- age有索引,但表中90%的记录age都大于18,索引失效
SELECT * FROM user WHERE age > 18;失效原因 : 这是最容易被忽略的失效场景,SQL本身没有语法问题,完全符合索引规则,但优化器还是放弃了索引,原因是回表成本过高。
前面我们提到,二级索引查询需要回表。回表通常是随机IO,因为二级索引返回的主键是离散的,而全表扫描是聚簇索引的顺序IO。机械硬盘中,随机IO的性能比顺序IO低上百倍,即使是SSD,随机IO的成本也远高于顺序IO。
当查询的结果集占表总数据量的20%~30%以上时,需要回表的次数会非常多,优化器计算后会认为,全表扫描的成本比走二级索引+回表的成本更低,最终放弃索引,走全表扫描。
除此之外,索引的区分度过低也会导致优化器放弃索引,比如性别列只有男/女两个值,区分度极低,优化器会认为走索引还不如全表扫描,直接放弃索引。
解决方法:
-
使用覆盖索引避免回表:
sql-- 只查索引列,不需要回表,优化器更倾向于走索引 SELECT id, age FROM user WHERE age > 18; -- 或者把索引改成覆盖索引 ALTER TABLE user ADD INDEX idx_age_id (age, id); -
使用 FORCE INDEX 强制走索引:
sqlSELECT * FROM user FORCE INDEX(idx_age) WHERE age > 18; -
重新统计索引信息,有时候是统计信息过期导致优化器误判:
sqlANALYZE TABLE user;
索引失效的判断、排查与Debug全流程
0 用慢查询日志发现问题SQL
在排查之前,首先得知道哪些SQL有问题
开启慢查询日志:
sql
-- 查看当前配置
SHOW VARIABLES LIKE 'slow_query%';
SHOW VARIABLES LIKE 'long_query_time';
-- 开启慢查询日志
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1; -- 超过1秒的查询记录下来
SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';分析慢查询日志:
bash
# 用mysqldumpslow汇总分析
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
# 参数说明:
# -s t: 按查询时间排序
# -t 10: 显示前10条
# 其他常用参数:
# -s c: 按查询次数排序
# -s l: 按锁定时间排序
# -s r: 按返回记录数排序输出示例:
sql
Count: 50 Time=3.21s Rows=1000 SELECT * FROM user WHERE name LIKE '%张三%'
Count: 30 Time=2.50s Rows=500 SELECT * FROM orders WHERE DATE(create_time) = '2024-01-01'看到这种 LIKE '%xxx' 或者对列用函数的,基本就是索引失效了,可以拿去用 EXPLAIN 分析
1 用EXPLAIN执行计划,判断索引是否失效
EXPLAIN是MySQL自带的执行计划分析工具,是判断索引失效的核心手段,只需要在SQL前加上EXPLAIN关键字,就能看到MySQL优化器的执行计划。
sql
EXPLAIN SELECT * FROM user WHERE LEFT(name,3) = '张三';我们重点关注和索引失效相关的6个字段,优先级从高到低:
| 字段名 | 核心作用 | 索引失效的判断标准 |
|---|---|---|
| type | 表示MySQL在表中找到所需行的方式,是索引质量的核心指标 | 优先级从高到低:system > const > eq_ref > ref > range > index > ALL ALL :全表扫描,索引完全失效 index:全索引扫描,遍历整个索引树,本质也是索引失效(仅覆盖索引除外) |
| key | 显示MySQL实际决定使用的索引 | 为NULL时,表示没有使用任何索引,完全失效 |
| key_len | 显示MySQL实际使用的索引长度(字节) | 联合索引中,通过key_len可以判断用到了哪几列,比如联合索引(name,phone,age),key_len仅等于name列的长度,说明后面的列索引失效 |
| ref | 显示与索引列做等值匹配的列或常量 | 为NULL时,大概率是范围扫描或全表扫描,索引未充分利用 |
| rows | MySQL预估为了找到目标记录,需要扫描的行数 | 数值越大,性能越差,全表扫描时rows约等于表的总记录数 |
| Extra | 额外的执行信息,能精准定位失效原因 | Using where :使用了where条件,但通过全表扫描过滤数据,索引失效 Using filesort :无法利用索引完成排序,排序字段索引失效 Using temporary :使用临时表存储中间结果,group by/order by字段索引失效 Using index:使用了覆盖索引,无需回表,是最优情况 |
2 定位索引失效的具体原因
通过EXPLAIN确认索引失效后,我们可以按以下步骤精准定位原因:
- 先看key是否为NULL,type是否为ALL :
- 如果是,检查where条件中的索引列是否存在函数运算、隐式类型转换、%前缀模糊查询、完全违背最左前缀原则、OR连接非索引列等问题。
- 可以通过
SHOW WARNINGS;查看优化器改写后的SQL,执行EXPLAIN后立即执行该命令,能直接看到隐式转换、函数改写的内容,比如CAST(phone AS signed int),能定位隐式转换问题。
- key显示了索引,但key_len远小于索引总长度 :
- 说明联合索引部分失效,检查是否存在中间列断档、范围查询之后的列无法利用的问题,对照最左前缀原则调整SQL或索引。
- SQL符合规则,但优化器还是没选索引 :
- 用
SHOW INDEX FROM table_name;查看索引的Cardinality,基数越小,区分度越低,优化器越容易放弃索引。 - 用
ANALYZE TABLE table_name;重新统计表的索引统计信息,避免因为统计信息不准确,导致优化器做出错误的成本判断。
- 用
3 用optimizer_trace追踪优化器决策
当遇到优化器选错索引的疑难问题时,我们可以通过optimizer_trace追踪优化器的完整决策过程,看到优化器对每个索引的成本计算细节,探查为什么放弃了索引。
- 查看结果 SELECT * FROM information_schema.OPTIMIZER_TRACE\G
-- 关闭追踪 SET optimizer_trace = 'enabled=off';
lua
返回的是一个很大的JSON,关注如下部分:
**rows_estimation - 行数估算和成本计算**
``` json
"rows_estimation": [
{
"table": "`index_test`",
"range_analysis": {
"table_scan": {
"rows": 1, -- 全表扫描预估扫描1行
"cost": 2.45 -- 全表扫描成本 2.45
},
"potential_range_indexes": [
{
"index": "PRIMARY",
"usable": false, -- 主键索引不可用
"cause": "not_applicable" -- 原因:不适用当前查询
},
{
"index": "idx_name_phone_time",
"usable": true, -- 联合索引可用
"key_parts": [ -- 索引包含的列
"name",
"phone",
"create_time",
"id" -- 主键会自动加到二级索引末尾
]
}
]
}
}
]best_access_path - 最终选择的访问路径
json
"best_access_path": {
"considered_access_paths": [
{
"access_type": "ref", -- 访问类型:ref
"index": "idx_name_phone_time", -- 使用的索引
"rows": 1, -- 预估扫描1行
"cost": 0.35, -- 成本 0.35
"chosen": true -- 被选中
},
{
"access_type": "scan", -- 访问类型:全表扫描
"chosen": false, -- 没被选中
"cause": "covering_index_better_than_full_scan" -- 原因:覆盖索引比全表扫描更好
}
]
}- 全表扫描成本:2.45
- 走索引成本:0.35
- 优化器选了成本更低的索引方案
假设有个查询走全表扫描,我想知道为什么:
sql
SET optimizer_trace = 'enabled=on';
SELECT * FROM user WHERE age > 18;
-- 全表扫描方案的成本
SELECT JSON_EXTRACT(trace, '$**.range_analysis.table_scan') AS table_scan
FROM information_schema.OPTIMIZER_TRACE;
-- 索引范围扫描方案的成本
SELECT JSON_EXTRACT(trace, '$**.analyzing_range_alternatives.range_scan_alternatives') AS range_alternatives
FROM information_schema.OPTIMIZER_TRACE;
-- 为什么选/不选索引
SELECT JSON_EXTRACT(trace, '$**.best_access_path.considered_access_paths') AS final_decision
FROM information_schema.OPTIMIZER_TRACE;对比两个cost,就知道为什么优化器放弃索引了。