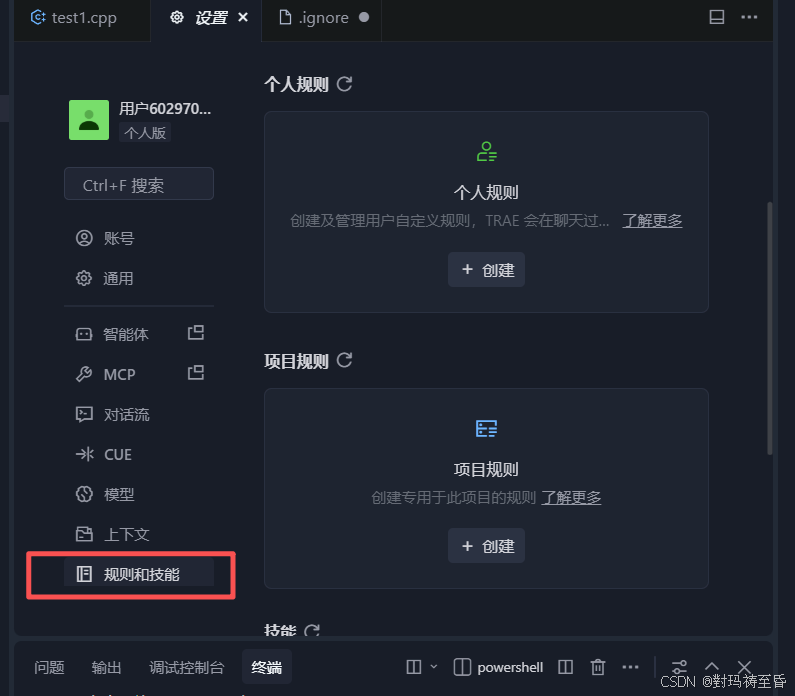
一.配置
1.Trae AI相关设置
**通用:**包括基础设置和偏好设置,比如使用什么主题,编辑器的设置,快捷键的设置等
**开发环境:**对开发的项目设置相关的环境,比如jdk、maven、node.js等
**智能体:**智能体是Trae中独立执行特定任务的"虚拟代理",核心作用是按需配置工具与协作策略
**MCP:**MCP是Trae中模型与开发环境的交互协议,核心作用是驱动AI自动执行开发任务
**对话流:**对话流是Trae中AI与用户交互的"流程化设计",核心作用是优化上下文理解与多轮交互体验
**CUE:**Cue(context understanding engine),提供多行编辑、智能改写和光标预测功能,实现更高级的代码辅助体验
**模型:**模型管理,比如管理超级模型、高级模型、也支持添加自定义模型
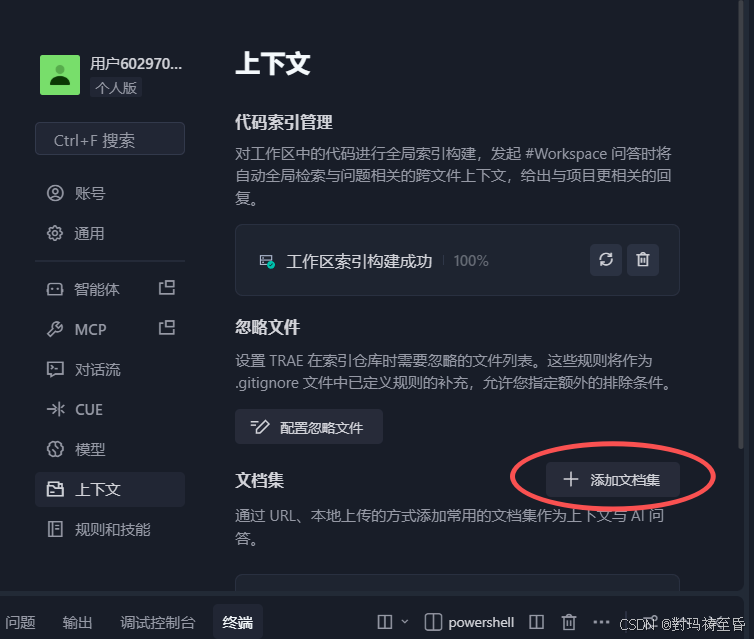
**上下文:**管理上下文,包括代码索引管理、配置忽略文件和添加文档集
**规则:**规则配置是Trae中开发流程的"自动化规范",核心作用是减少重复操作与错误,包括个人规则和项目规则。
2.Trae editor相关设置
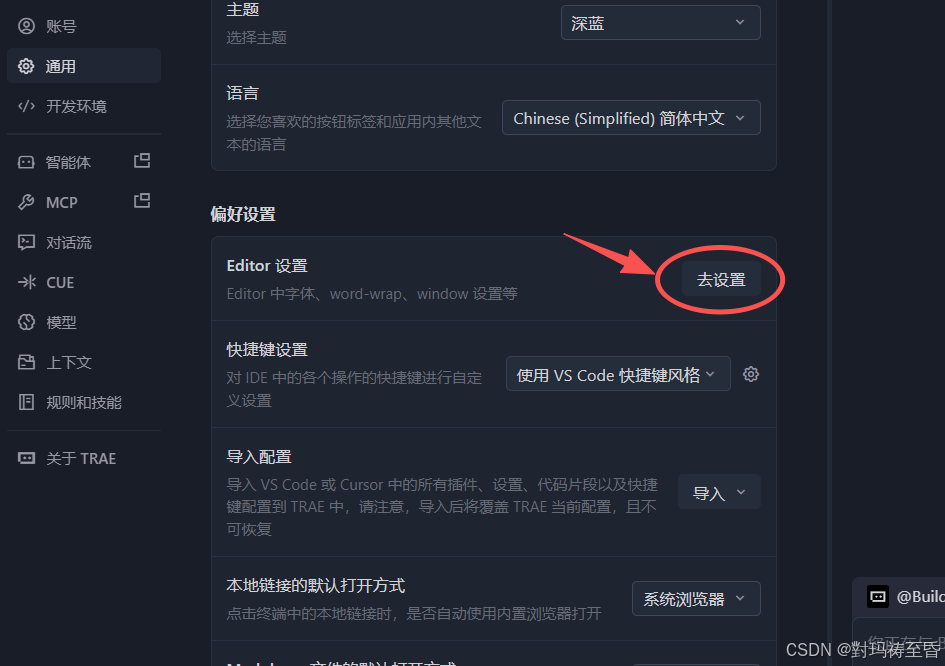
二.Trae核心三大功能
1.Tab-CUE(上下文理解引擎)
它是我们核心的交互能力。也就是通过AI驱动,它能够智能补全我们的代码,它能够明显的提升我们编码的效率。
1)代码补全
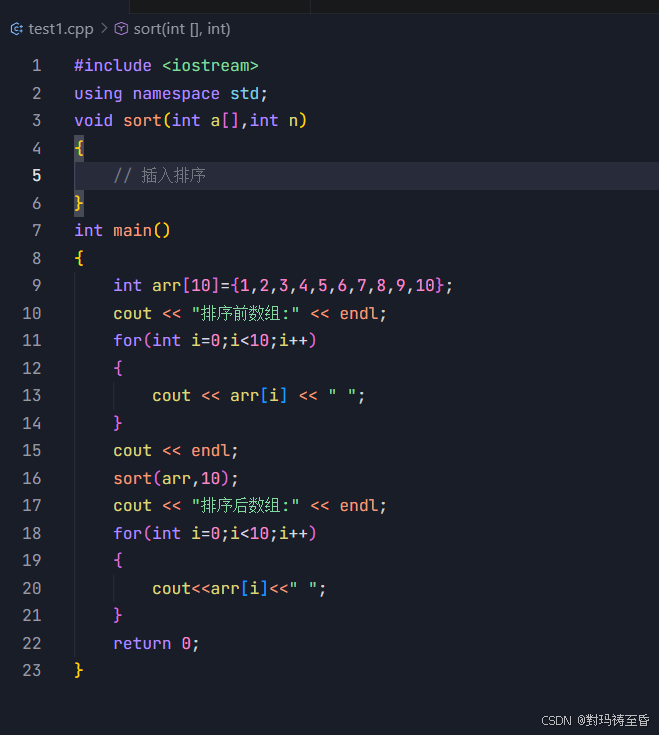
2)智能代码重写
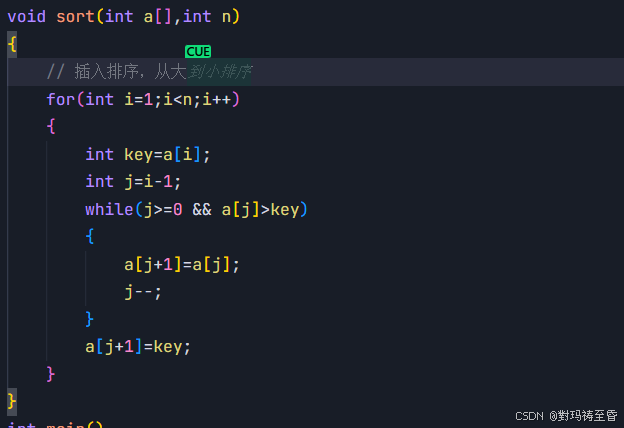
3)多行协同优化
数据联想与批量修改

4)光标位置预测
5)接收,接受部分或者是拒绝
tab:接收补全
Ctrl + RightArrow:接受部分补全
esc:拒绝补全
2.智能体聊天模式
1)chat
可以聊代码库或者编写代码,但是它不能直接生成代码文件
2)builder
适合端到端执行常规的开发任务
3)solo
有两种模式,一种就是IDE模式,还有一种就是solo模式。这两种模式它分别侧重点是不一样的。IDE模式它比较侧重于人机协作,而solo模式,更侧重于AI自主开发。
创建新的会话:ctrl + alt + N
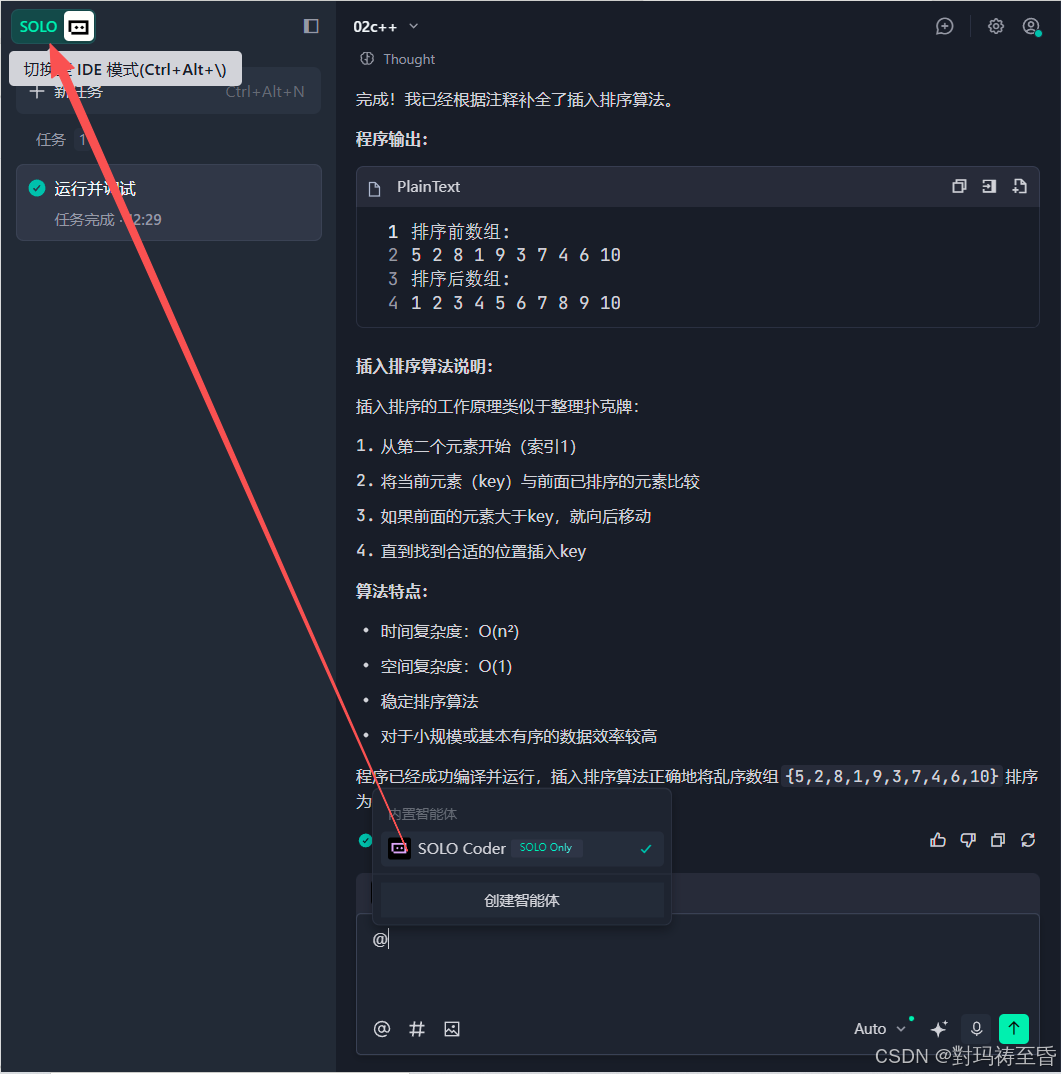
3.Editor内AI编码
三.Trae的上下文
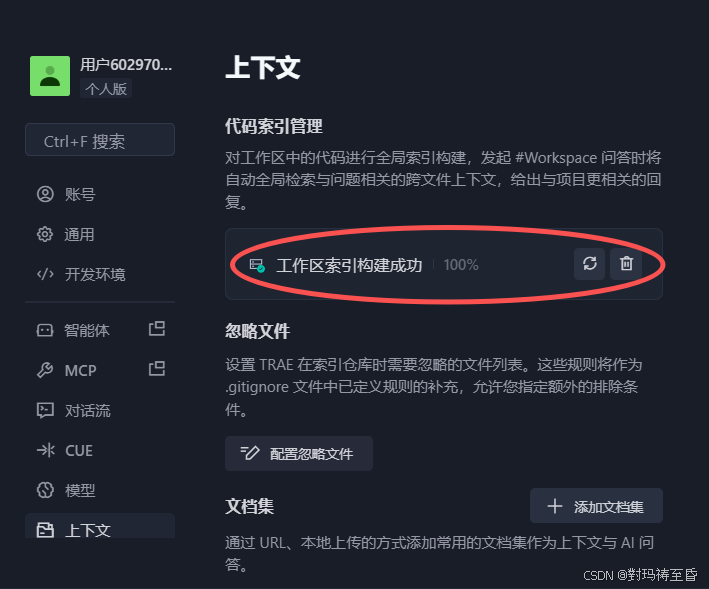
1.代码索引管理
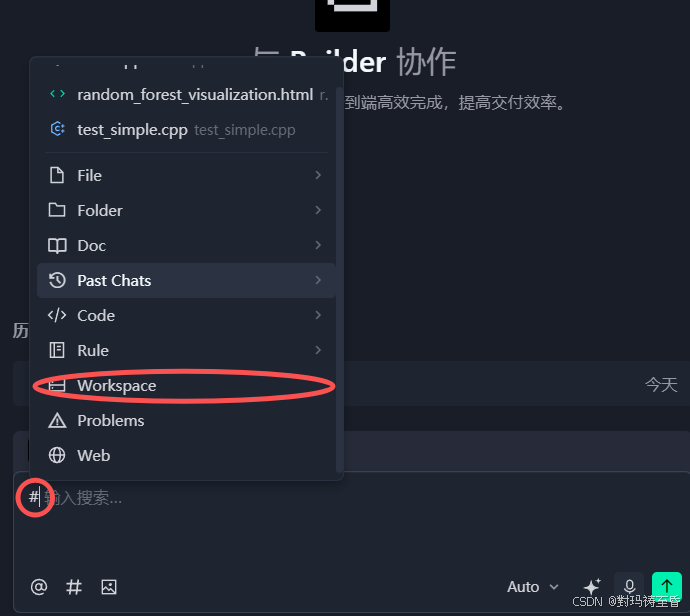
简单的讲就是对工作区中的代码进行全局的索引和构建。如果我们构建成功了,通过引用#workspace,它就会自动的进行全局的检索。
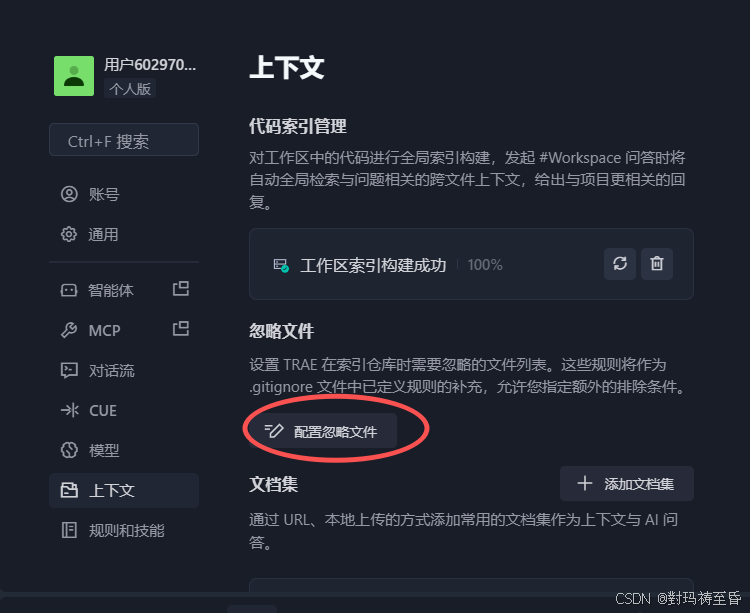
2.忽略文件
我们可以通过将".ignore"文件添加到根目录,来控制哪些文件或者哪些文件夹被忽略。
3.创建文档集
文档集的创建可以理解成创建相应的知识库。它有两种创建方式,一种就是通过URL,一种就是通过本地上传的方式。添加常用的文档集可以作为上下文与AI的一个问答。
四.Rules规则
给添加规则和限制,让生成的代码贴合我们团队的规范。第一个它可以约束代码风格,比如说去强制使用驼峰命名,或者是要求方法写注释。我们也可以去限定技术选型,也就是我们优先使用什么样的技术框架或者是库禁止使用什么组件框架或者是库。我们也可以去提前指定配置的参数,比如我们提前设置连接数据库的方式,账号或者是密码。
javaUser Rules 规则 - 我使用 Java 17 或更高版本。 - 遵循标准的 Java 命名规范:类名用 PascalCase,方法和变量用 camelCase,常量全大写加下划线。 - 所有 public 方法必须包含完整的 Javadoc 注释,包括 @param、@return 和 @throws。 - 优先使用不可变对象和 final 关键字(如 final class、final fields)。 - 避免使用 Lombok;显式编写 getter/setter 和构造函数。 - 异常处理应具体,避免捕获通用 Exception,优先抛出或记录有意义的异常。 - 使用 SLF4J 进行日志记录,而不是 System.out。 - 依赖注入使用 Spring Framework(如适用),偏好构造器注入而非字段注入。 - 单元测试使用 JUnit 5 + Mockito,每个业务类都应有对应的测试类。