4.4.1 A Naive ATPG Algorithm(一种非常简单的ATPG算法)
这种算法如下,有fanout结构的组合逻辑电路可以用这种算法:

从这个算法中可以看出来,这个ATPG的计算复杂度是指数级的,因为它要试过所有的向量。除非这个可用的向量在中间试出来了被找出来了,或者证明这个故障是不可测的。
但需要注意第2步,这个挑选向量的方式可以被优化,而不是一直无脑一个一个去试。比如先试了一些向量,发现了一些规律,剩下的向量就可以直接排除掉一些,这样就能提高效率。这里提到了一个概念decision tree。
下图展示了一个decision tree的例子:
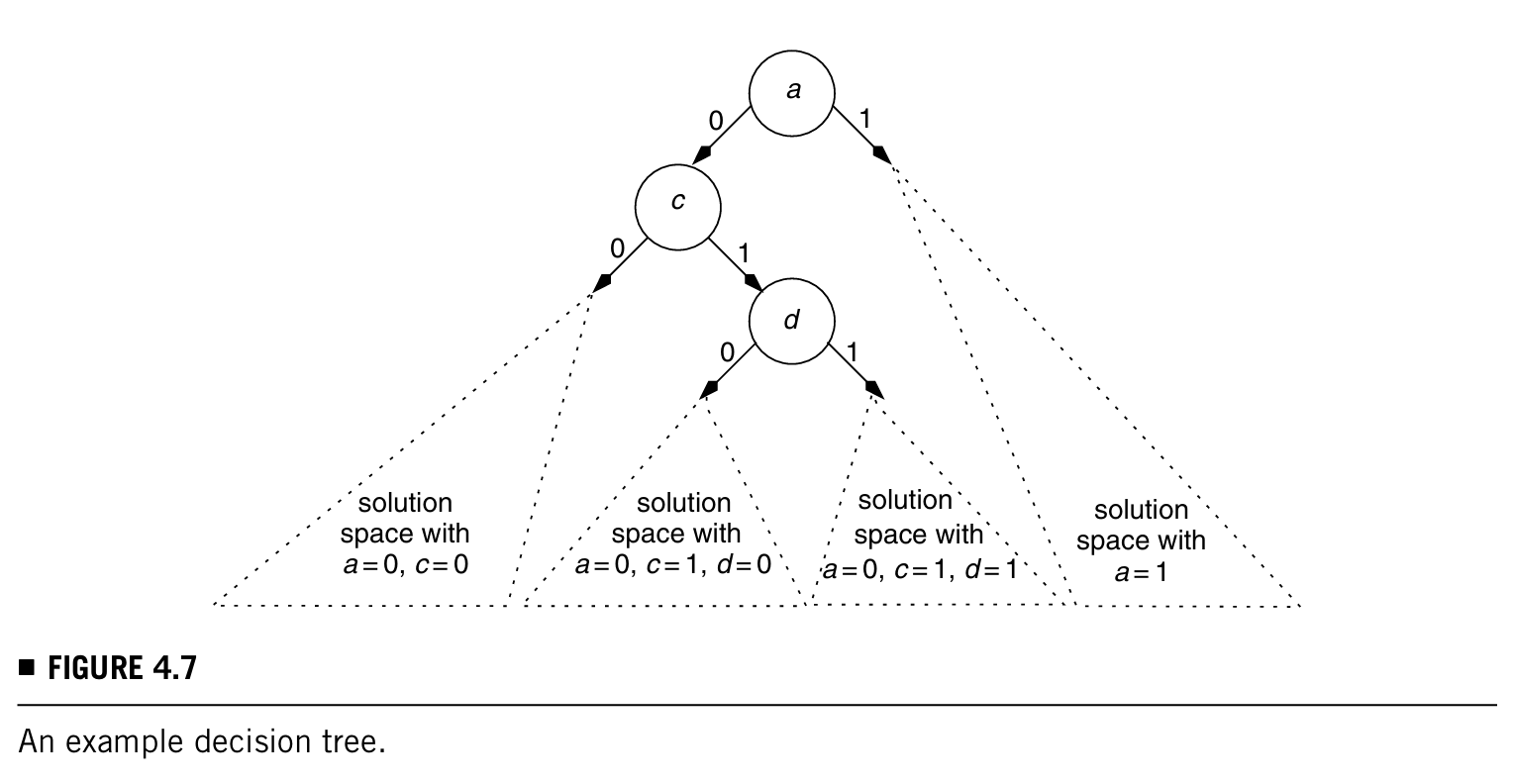
可以理解到,每个输入都分两个岔,那么solution space就有2^n个,也就是2^n个向量。(可以注意到a = 1的分支被隐藏了,通常decision tree是可以这样画的,隐藏一些不重要的分支)
4.4.1.1 Backtracking(回溯法)
用一个例子讲明白回溯法,非常简单,如下图例:
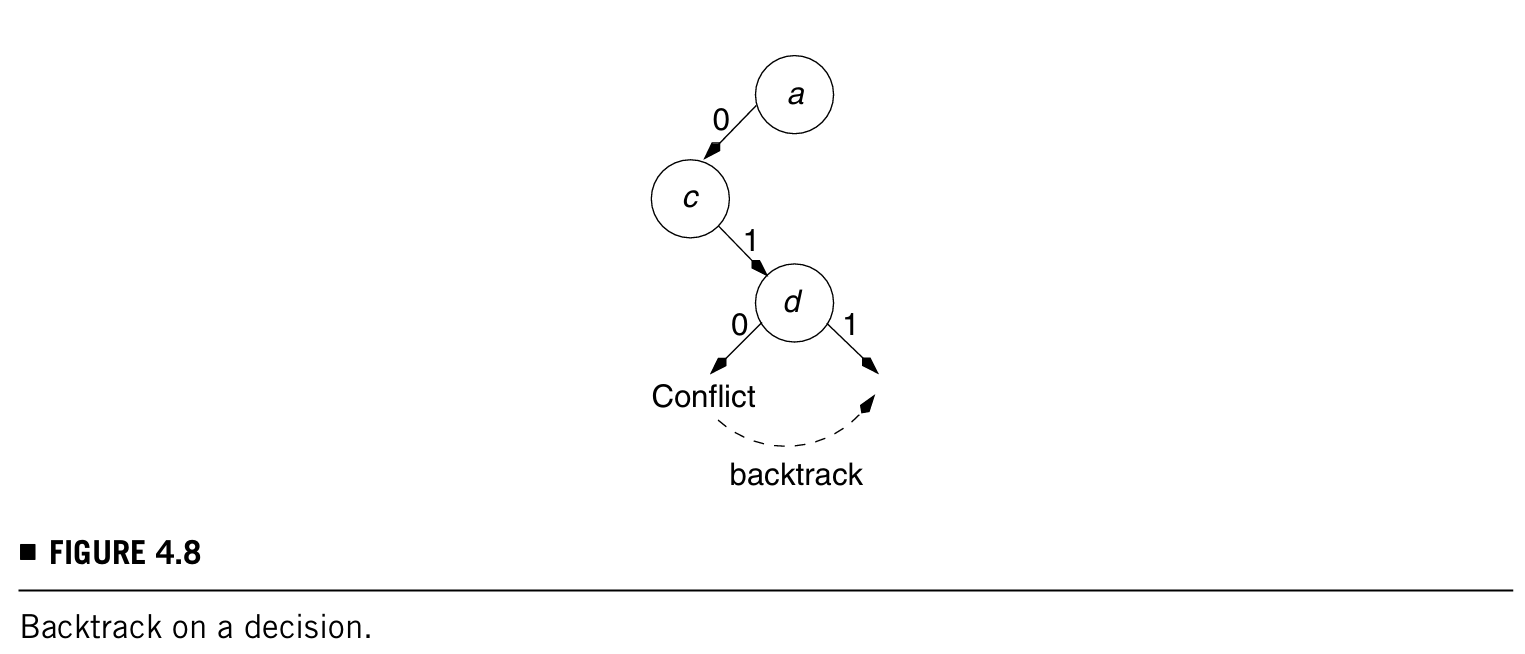
a = 0, c = 1, d = 0:如果这个向量造成了conflict,那么就将d = 0翻转成d = 1;
a = 0, c = 1, d = 1:如果这也造成了conflict,那么就再往前推,把c做翻转,d可以don't care;
a = 0, c = 0:依次推......就是这么个回溯的意思
如果往前推没有任何节点的值可以翻转,那么ATPG可以得出结论这个目标故障是不可测的。
conflict analysis可以参考文献继续探究,这里没有再讲。
4.4.2 A Basic ATPG Algorithm
以下算法2适用于检测fanout-free的组合逻辑电路C中的目标故障g/v。:

其中JustifyFanoutFree()和PropagateFanoutFree()都是递归方程。
JustifyFanoutFree()的算法如下图:

用下图作为一个例子说明,目标是justify g = 1:
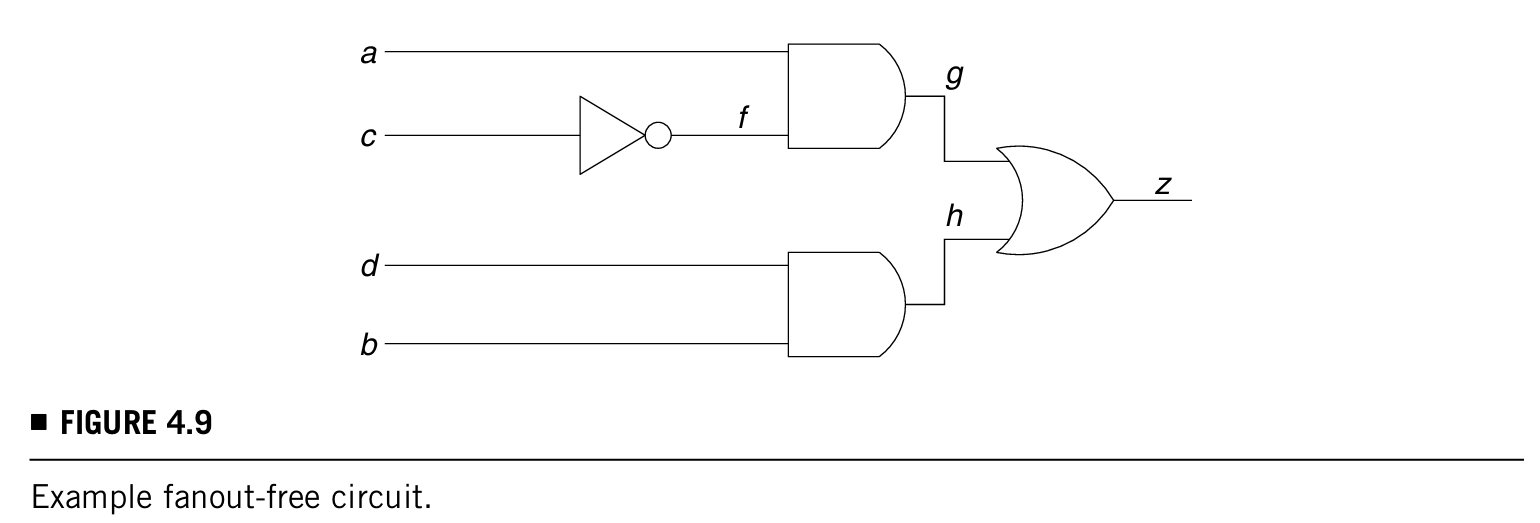
那么这个方程的动作就会有:
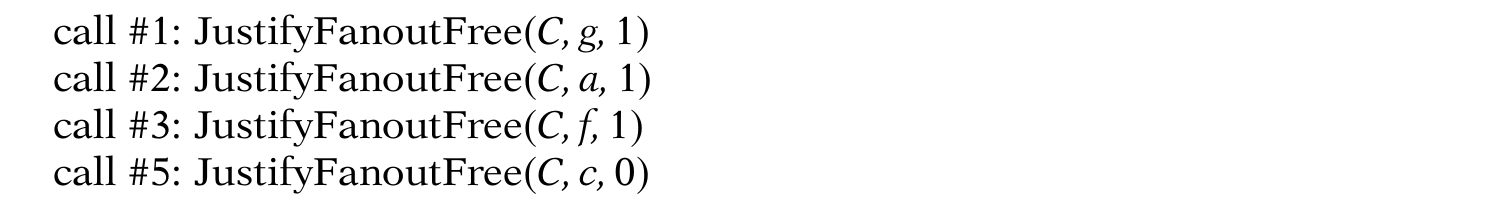
结束后abcd = 1X0X就是知道是一个可以justify g = 1的输入向量。
再举一个例子如下图(有fanout,但是也能用这个算法justify the signal g = 1):
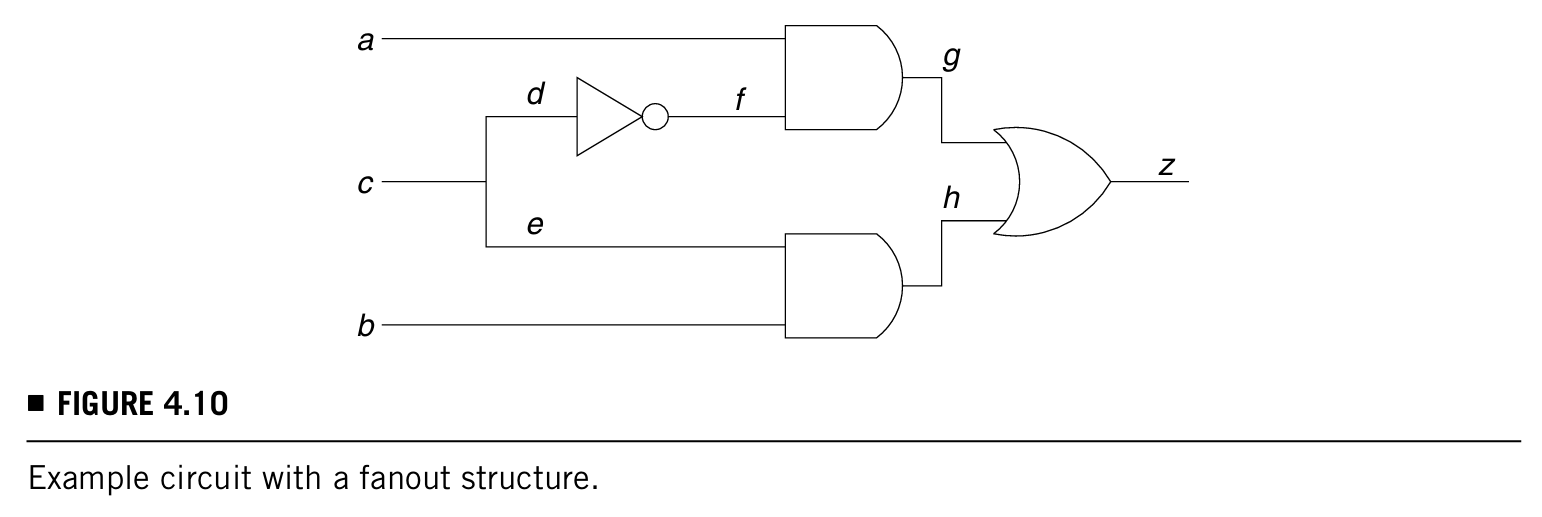
方程动作为:
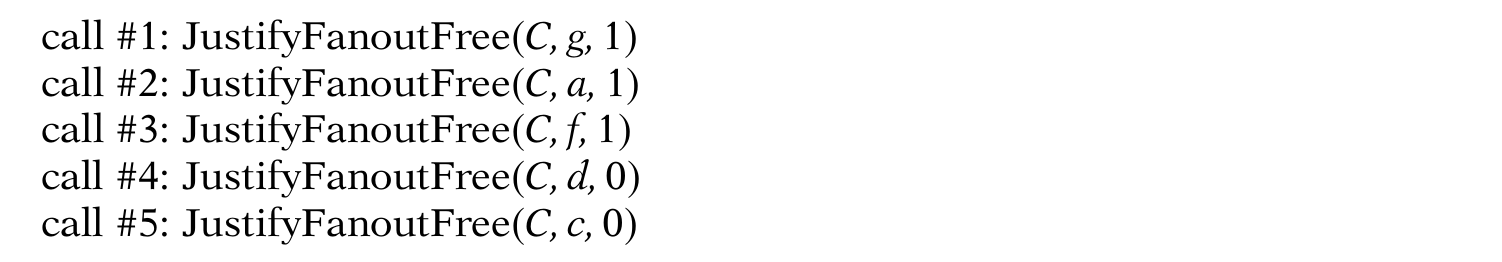
结束后abc = 1X0就是知道是一个可以justify g = 1的输入向量。
再以图4.10作为例子,又假设了一个z = 0的例子,可以自己看着玩儿。
下面的算法4是算法2中的PropagateFanoutFree()的伪随机代码:

还是假设目标故障为g/0,那么根据JustifyFanoutFree和PropagateFanoutFree两个方程,下面的动作会被执行:
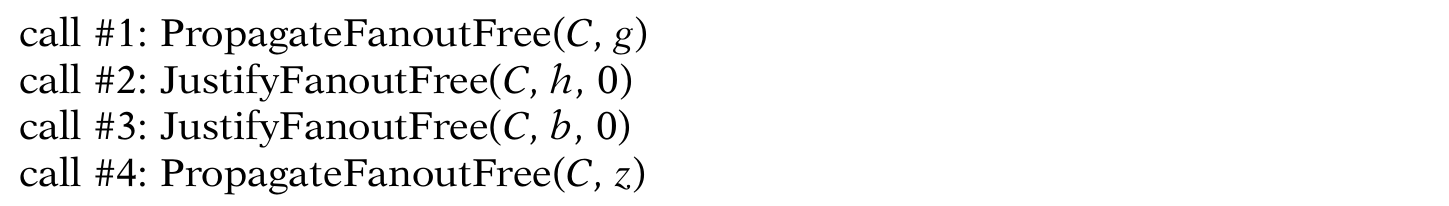
可探测出故障的向量为abc = 100。
上面的算法通常都是在fanout-free电路中比较使用,如果是有fanout的电路,这样的算法就总会遇到conflicts,为了避免遇到conflict从而能在电路中通用,有下面小节中所说的算法。
4.4.3 D Algorithm(D算法)
在讨论D算法之前,要理解两个词:
- D-frontier :由电路中所有的门组成,输出是x,受故障影响的D或者D'在一个或多个输入上。为了达成这个目标,一个或多个输入就需要是"don't care",D-frontier是故障相关的一个门,如下图两个例子:
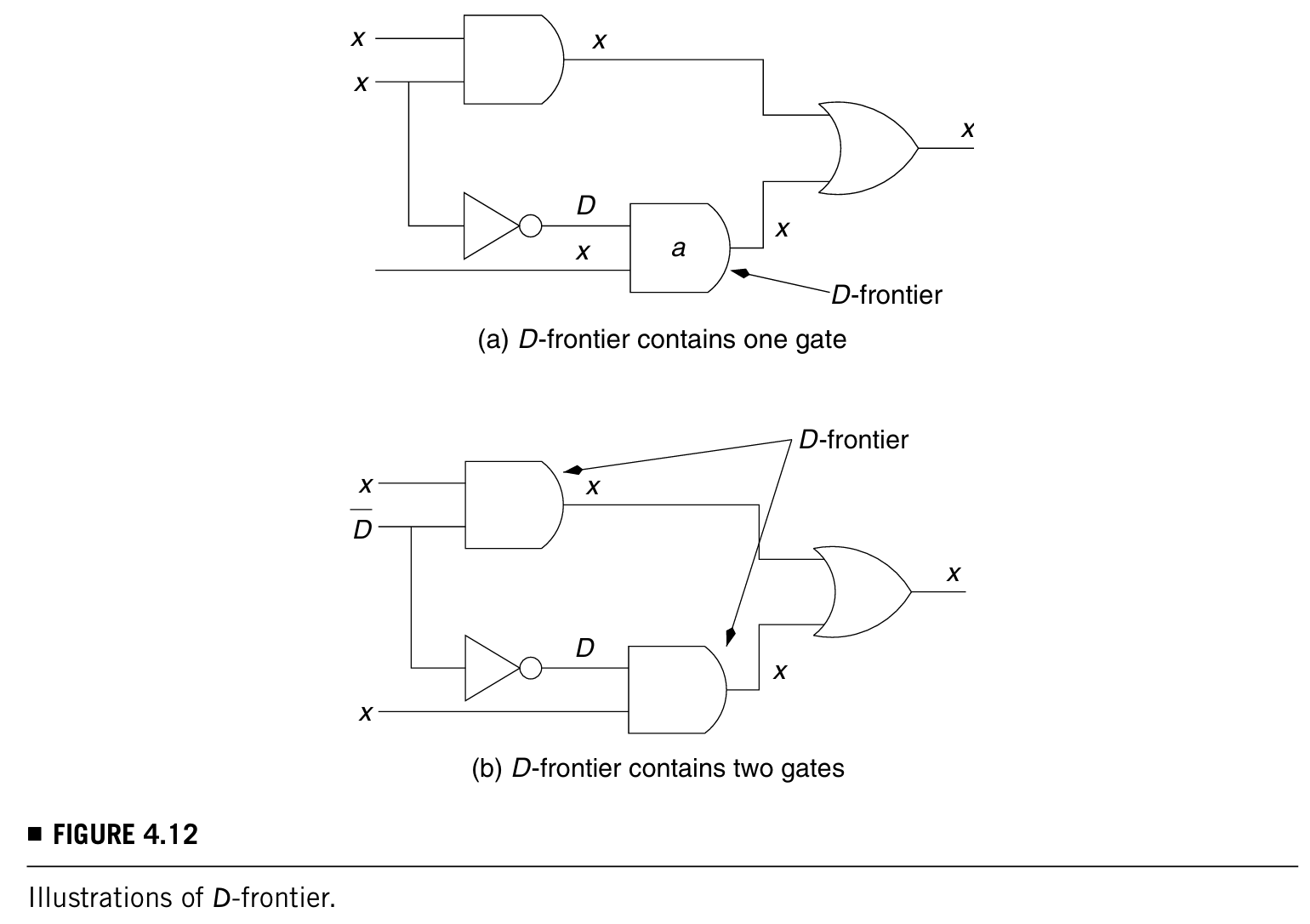 有个定律,D-frontier is empty的时候,故障就不能被检测到。D-frontier is empty的意思就是比如,图a中a门下面那个管脚被赋值0,那么这个门的输出肯定是0,D就不管用了,这就叫D-frontier is empty。
有个定律,D-frontier is empty的时候,故障就不能被检测到。D-frontier is empty的意思就是比如,图a中a门下面那个管脚被赋值0,那么这个门的输出肯定是0,D就不管用了,这就叫D-frontier is empty。 - J-frontier:由电路中所有门组成,它的输出是已知的(可以是五值逻辑中的任何一个),但不是由它的输入可判断的,如下图:
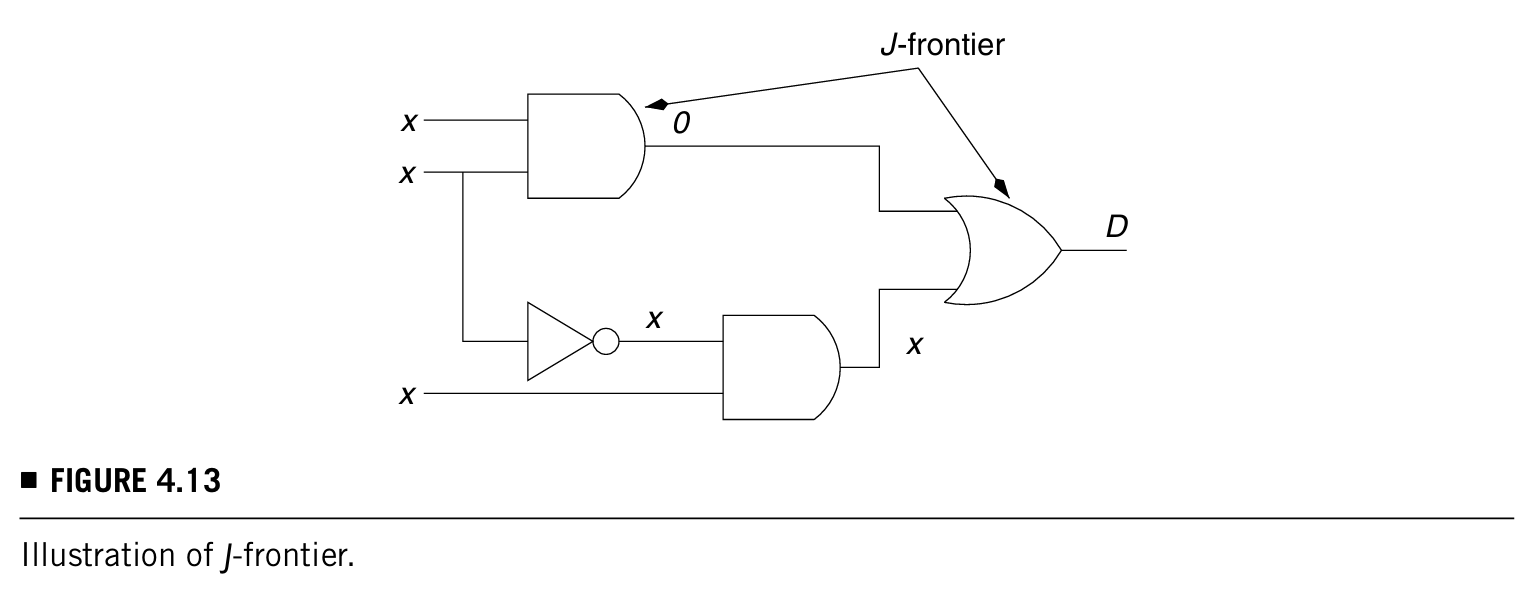 为了探测到故障,J-frontier中的所有门必须被判断。
为了探测到故障,J-frontier中的所有门必须被判断。
解释完D-frontier和J-frontier之后就可以开始讲述D算法的原理。一整个过程就是从fault site开始将D传播到primary output的过程,例子如下图:
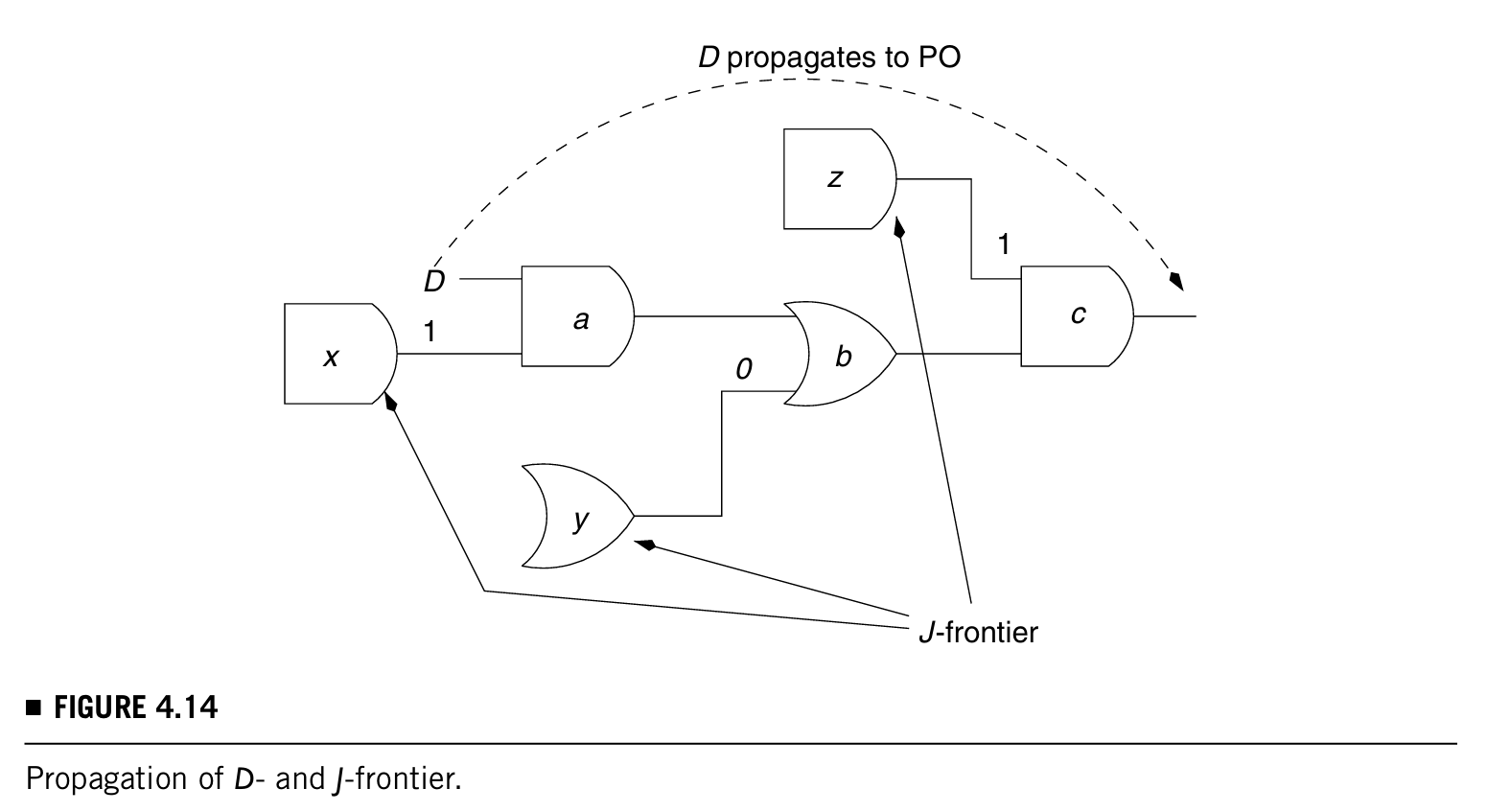
这个过程就是gates a → b → c,x、y、z组成了J-frontier,因为他们目前没有被判断,而且因为D最终会被传播到primary output,D-frontier最后就是那个output gate。
整个D算法的流程展示在如下的算法5和6中:


注意到以上算法没有一些智能的判断提高判断效率,用下面一个小例子说明什么叫智能的判断:
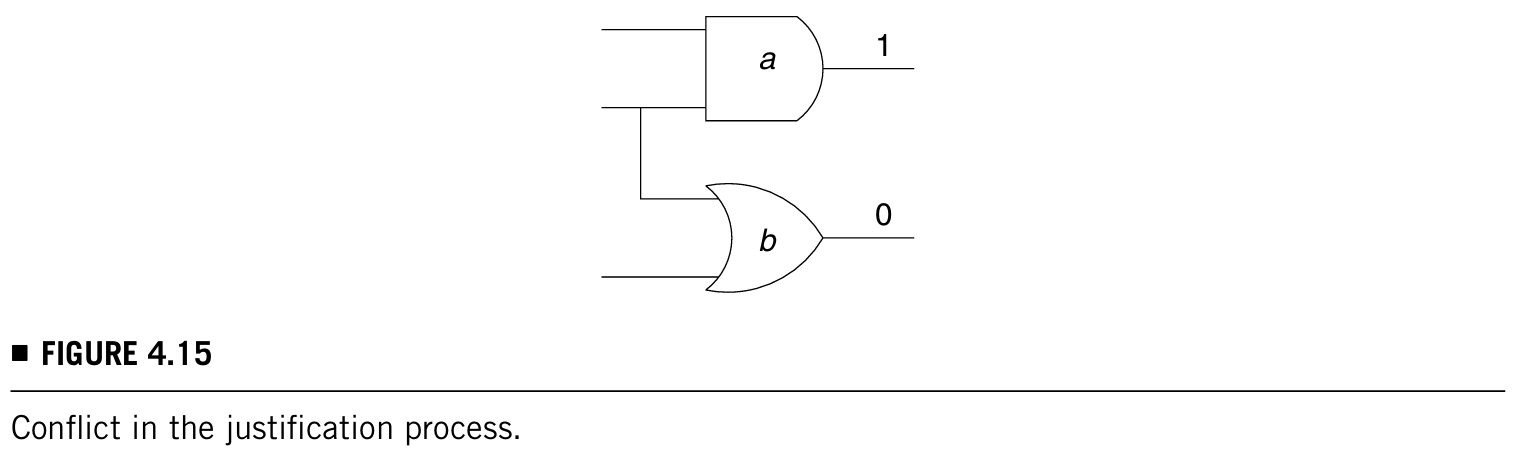
比如上图中a = 1,那么b就不可能等于0,这就叫智能的判断,如果算法里加入这种判断就可以少走很多分支,从而提高效率,然而在算法6的第一行中,就可以加入这样的智能的判断,提升D算法和其他ATPG算法的性能。(后面的章节中也会继续讨论)
再讨论一个例子,如下图:
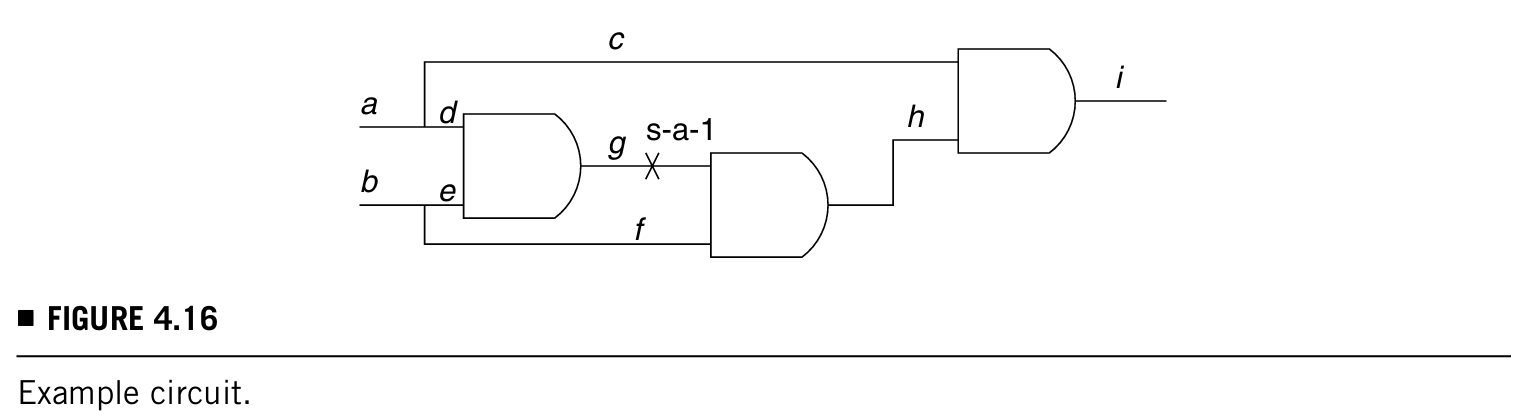
基本步骤如下:
- 目标故障为g/1。
- 电路初始化:D算法将D'放在g(为了和D相反,利于激活故障),J-frontier由g = D'组成,D-frontier由h组成
- 为了完善D-frontier,要让f = 1(可理解),f = 1就被加入了J-frontier,D-frontier现在就是i
- 为了让故障能传输到输出上,需要c = 1,那么c = 1也就被加入了J-frontier,这个时候就可以将故障传输到输出上了
- 接下来的任务就是判断J-frontier上的信号值:{g = D',f = 1,c = 1}
- 为了让g = D',有两个选择:
- a = 0:那么f = 0且b = 0是justified,c = 1是unjustified,程序就会发现a = 0而c =1是矛盾的,就会翻转上次的结论也就是选择a = 0,也会发现是conflict,就会继续backtrack把b = 1换为b = 0
- b = 0:a此时可被置为"don't care",会发现b = 0也是conflict,即便翻转b的值也不能justify所有的J-frontier,这时候b再往前做backtrack已经发现没有可以回溯的了
- 所以,目标故障g/1是untestable的故障
4.4.4 PODEM
可以发现D算法中,decision space需要遍历所有的门,但是ATPG得到的最终向量都是给primary inputs的。所以有没有可能有一种算法是只触及primary inputs而不是电路中所有门的呢?
有,就是PODEM。它的要点和步骤大概分成以下几步:
- 类似于D算法,D-frontier是保留的;但是因为decisions are made就在primary inputs,所以不存在J-frontier
- 算法的一开始首先要激活fault
- 算法的重点就是找到一条X-path可以将D-frontier的fault传到primary output。如果没有这样的通路那么就意味着所有的通路都被阻塞了,如下图的示例
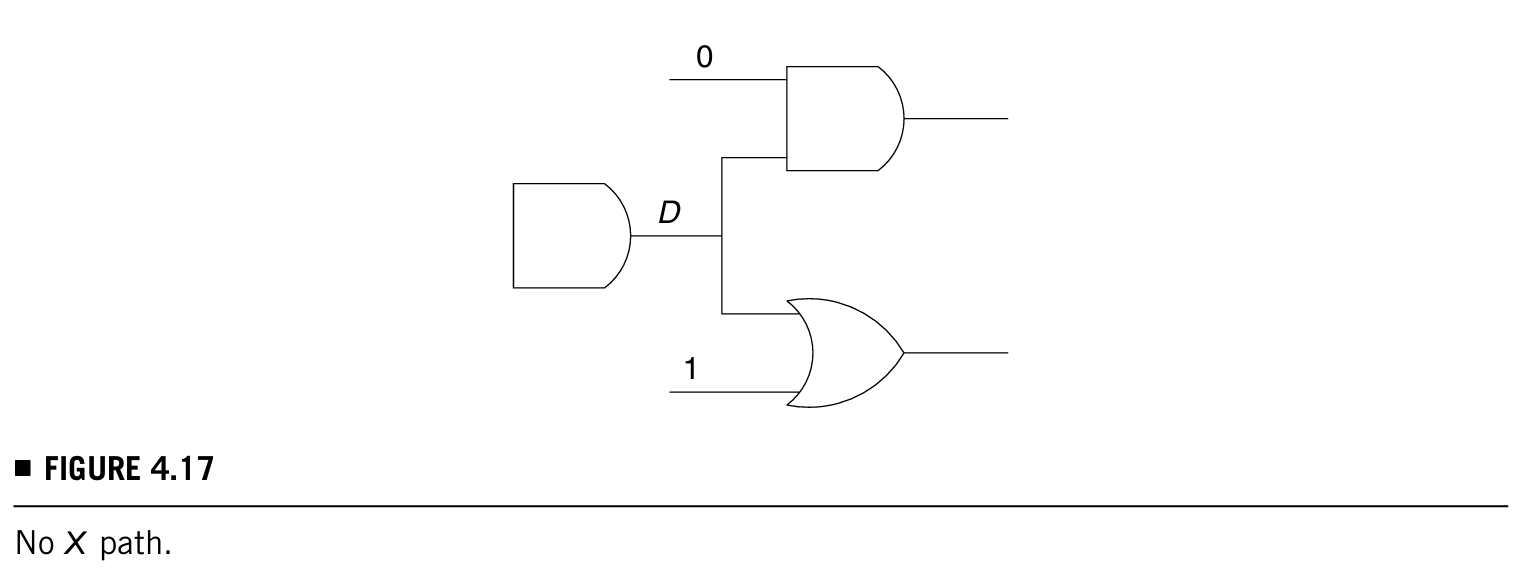
- PODEM会挑一条最好的X-path传播fault到输出
PODEM的基本算法为下面的算法7和8:

不同于D算法的是,它的decisions都是被限制在primary inputs上,所有内部节点的值都由primary inputs通过仿真得到,所以在电路内部信号中不会发生conflict,只有两种情况必须backtrack:
- the target fault is not excited
- the D-frontier becomes empty
PODEM-Recursion(),这个PODEM迭代方程中最重要的三个方程是:
- getObjective(),它的伪随机代码见下面算法9:

- back-trace(),它的伪随机代码见下面算法10:

- logicSimulate_and_imply()
文中有3个例子,有必要的时候查阅原文。