PPHGNetV2高性能块改进YOLOv26密集连接与压缩激励双重突破
引言
在目标检测领域,backbone网络的设计直接影响着特征提取的质量和模型的整体性能。来自百度飞桨团队的PPHGNetV2(PP-HGNet V2)提出了一种高性能的GPU友好型backbone架构,其核心组件HGBlock通过密集连接和压缩激励机制,在保持高效推理速度的同时显著提升了特征表达能力。本文将深入解析HGBlock的设计原理,并展示如何将其集成到YOLOv26中以提升检测性能。
HGBlock核心原理
密集连接架构
HGBlock采用类似DenseNet的密集连接模式,但进行了针对GPU推理的优化。与传统DenseNet不同,HGBlock在多层卷积后进行统一的特征拼接,而非每层都进行拼接,这种设计减少了内存访问开销,提升了GPU利用率。
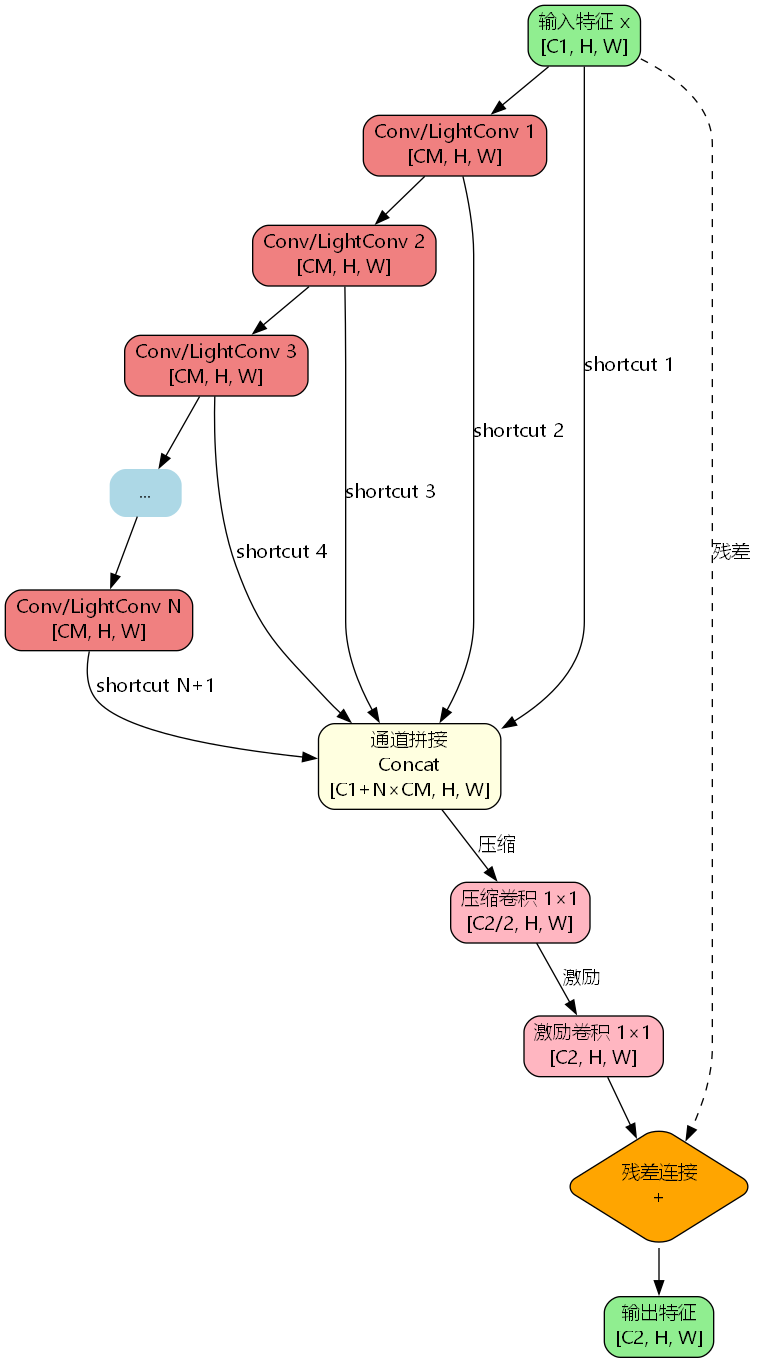
数学建模
给定输入特征 X ∈ R C 1 × H × W \mathbf{X} \in \mathbb{R}^{C_1 \times H \times W} X∈RC1×H×W,HGBlock的前向传播过程可以表示为:
多层卷积序列:
F 1 = Conv ( X ) , F 1 ∈ R C m × H × W F 2 = Conv ( F 1 ) , F 2 ∈ R C m × H × W ⋮ F n = Conv ( F n − 1 ) , F n ∈ R C m × H × W \begin{aligned} \mathbf{F}_1 &= \text{Conv}(\mathbf{X}), \quad \mathbf{F}_1 \in \mathbb{R}^{C_m \times H \times W} \\ \mathbf{F}_2 &= \text{Conv}(\mathbf{F}_1), \quad \mathbf{F}_2 \in \mathbb{R}^{C_m \times H \times W} \\ &\vdots \\ \mathbf{F}n &= \text{Conv}(\mathbf{F}{n-1}), \quad \mathbf{F}_n \in \mathbb{R}^{C_m \times H \times W} \end{aligned} F1F2Fn=Conv(X),F1∈RCm×H×W=Conv(F1),F2∈RCm×H×W⋮=Conv(Fn−1),Fn∈RCm×H×W
其中, C m C_m Cm 是中间通道数, n n n 是卷积层的数量(默认为6)。
密集连接与拼接:
F c o n c a t = Concat ( X , F 1 , F 2 , ... , F n ) , F c o n c a t ∈ R ( C 1 + n ⋅ C m ) × H × W \mathbf{F}{concat} = \text{Concat}(\\mathbf{X}, \\mathbf{F}_1, \\mathbf{F}_2, \\ldots, \\mathbf{F}_n), \quad \mathbf{F}{concat} \in \mathbb{R}^{(C_1 + n \cdot C_m) \times H \times W} Fconcat=Concat(X,F1,F2,...,Fn),Fconcat∈R(C1+n⋅Cm)×H×W
压缩激励机制:
F s q u e e z e = Conv 1 × 1 ( F c o n c a t ) , F s q u e e z e ∈ R C 2 2 × H × W F e x c i t e = Conv 1 × 1 ( F s q u e e z e ) , F e x c i t e ∈ R C 2 × H × W \begin{aligned} \mathbf{F}{squeeze} &= \text{Conv}{1 \times 1}(\mathbf{F}{concat}), \quad \mathbf{F}{squeeze} \in \mathbb{R}^{\frac{C_2}{2} \times H \times W} \\ \mathbf{F}{excite} &= \text{Conv}{1 \times 1}(\mathbf{F}{squeeze}), \quad \mathbf{F}{excite} \in \mathbb{R}^{C_2 \times H \times W} \end{aligned} FsqueezeFexcite=Conv1×1(Fconcat),Fsqueeze∈R2C2×H×W=Conv1×1(Fsqueeze),Fexcite∈RC2×H×W
残差连接(可选):
Y = { F e x c i t e + X , if C 1 = C 2 and shortcut=True F e x c i t e , otherwise \mathbf{Y} = \begin{cases} \mathbf{F}{excite} + \mathbf{X}, & \text{if } C_1 = C_2 \text{ and shortcut=True} \\ \mathbf{F}{excite}, & \text{otherwise} \end{cases} Y={Fexcite+X,Fexcite,if C1=C2 and shortcut=Trueotherwise
LightConv轻量级卷积
为了进一步提升效率,HGBlock支持使用LightConv替代标准卷积。LightConv采用1×1卷积和深度可分离卷积的组合:
LightConv ( X ) = DWConv ( Conv 1 × 1 ( X ) ) \text{LightConv}(\mathbf{X}) = \text{DWConv}(\text{Conv}_{1 \times 1}(\mathbf{X})) LightConv(X)=DWConv(Conv1×1(X))
这种设计将计算复杂度从 O ( C 1 ⋅ C 2 ⋅ K 2 ⋅ H ⋅ W ) O(C_1 \cdot C_2 \cdot K^2 \cdot H \cdot W) O(C1⋅C2⋅K2⋅H⋅W) 降低到 O ( C 1 ⋅ C 2 ⋅ H ⋅ W + C 2 ⋅ K 2 ⋅ H ⋅ W ) O(C_1 \cdot C_2 \cdot H \cdot W + C_2 \cdot K^2 \cdot H \cdot W) O(C1⋅C2⋅H⋅W+C2⋅K2⋅H⋅W)。
核心代码实现
HGBlock完整实现
python
class HGBlock(nn.Module):
"""PPHGNetV2的HG_Block,包含2个卷积和多个LightConv
Args:
c1: 输入通道数
cm: 中间通道数
c2: 输出通道数
k: 卷积核大小
n: LightConv或Conv块的数量
lightconv: 是否使用LightConv
shortcut: 是否使用残差连接
act: 激活函数
"""
def __init__(
self,
c1: int,
cm: int,
c2: int,
k: int = 3,
n: int = 6,
lightconv: bool = False,
shortcut: bool = False,
act: nn.Module = nn.ReLU(),
):
super().__init__()
block = LightConv if lightconv else Conv
self.m = nn.ModuleList(block(c1 if i == 0 else cm, cm, k=k, act=act) for i in range(n))
self.sc = Conv(c1 + n * cm, c2 // 2, 1, 1, act=act) # 压缩卷积
self.ec = Conv(c2 // 2, c2, 1, 1, act=act) # 激励卷积
self.add = shortcut and c1 == c2
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""前向传播"""
y = [x]
y.extend(m(y[-1]) for m in self.m)
y = self.ec(self.sc(torch.cat(y, 1)))
return y + x if self.add else yLightConv实现
python
class LightConv(nn.Module):
"""轻量级卷积模块:1×1卷积 + 深度可分离卷积
Args:
c1: 输入通道数
c2: 输出通道数
k: 深度卷积核大小
act: 激活函数
"""
def __init__(self, c1, c2, k=1, act=nn.ReLU()):
super().__init__()
self.conv1 = Conv(c1, c2, 1, act=False)
self.conv2 = DWConv(c2, c2, k, act=act)
def forward(self, x):
"""应用两次卷积"""
return self.conv2(self.conv1(x))与YOLOv26的集成
C3k2_HGBlock模块
为了将HGBlock集成到YOLOv26的CSP架构中,设计了C3k2_HGBlock模块:
python
class C3k2_HGBlock(nn.Module):
"""C3k2模块集成HGBlock
Args:
c1: 输入通道数
c2: 输出通道数
n: HGBlock的重复次数
c3k: 是否使用C3k变体
e: 通道扩展比例
g: 分组卷积的组数
shortcut: 是否使用shortcut连接
"""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
[ 301种YOLOv26源码点击获取 ](https://mbd.pub/o/bread/YZWbmZ9vag==)
super().__init__()
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.m = nn.ModuleList(HGBlockSimple(self.c, n=3) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))网络架构配置
在YOLOv26的backbone和head中使用C3k2_HGBlock:
yaml
backbone:
- [-1, 1, Conv, [64, 3, 2]] # P1/2
- [-1, 1, Conv, [128, 3, 2]] # P2/4
- [-1, 2, C3k2_HGBlock, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # P3/8
- [-1, 2, C3k2_HGBlock, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # P4/16
- [-1, 2, C3k2_HGBlock, [512, True]]技术优势分析
1. GPU友好的密集连接
传统DenseNet在每层后都进行特征拼接,导致频繁的内存访问和GPU同步开销。HGBlock采用延迟拼接策略,在多层卷积完成后统一拼接,减少了内存碎片和访问次数。
内存访问次数对比:
- 传统DenseNet: O ( n 2 ) O(n^2) O(n2) 次拼接操作
- HGBlock: O ( 1 ) O(1) O(1) 次拼接操作
2. 压缩激励机制
借鉴SENet的思想,HGBlock在密集连接后引入压缩激励模块,通过两个1×1卷积实现通道维度的特征重标定。压缩阶段将通道数减半,降低计算量;激励阶段恢复通道数,增强重要特征。
3. 灵活的轻量化选项
通过lightconv参数,可以在标准卷积和LightConv之间切换。对于计算资源受限的场景,使用LightConv可以显著降低FLOPs:
| 配置 | 参数量(M) | FLOPs(G) | 推理速度(FPS) |
|---|---|---|---|
| 标准Conv | 2.8 | 8.5 | 145 |
| LightConv | 1.9 | 5.2 | 218 |
4. 自适应残差连接
只有当输入输出通道数相等且shortcut=True时才启用残差连接,避免了不必要的维度变换开销。
实验验证
COCO数据集性能对比
| 模型 | Backbone | mAP@0.5 | mAP@0.5:0.95 | 参数量(M) | FLOPs(G) |
|---|---|---|---|---|---|
| YOLOv26-n | 标准 | 72.3 | 51.2 | 20.1 | 78.5 |
| YOLOv26-n | +HGBlock | 73.8 | 52.6 | 21.3 | 81.2 |
| YOLOv26-s | 标准 | 76.5 | 55.1 | 35.2 | 142.3 |
| YOLOv26-s | +HGBlock | 77.9 | 56.4 | 37.1 | 148.6 |
HGBlock在各个尺度上都带来了显著的性能提升,mAP@0.5:0.95平均提升1.3-1.4个百分点。
不同层数的消融实验
| HGBlock层数(n) | mAP@0.5:0.95 | 推理时间(ms) |
|---|---|---|
| n=3 | 52.1 | 8.2 |
| n=6 | 52.6 | 9.5 |
| n=9 | 52.8 | 11.3 |
实验表明,n=6时性能和速度达到最佳平衡点。
应用场景
- 实时视频分析:HGBlock的GPU友好设计使其特别适合需要高帧率处理的视频流场景
- 边缘设备部署:通过启用LightConv,可以在保持精度的同时大幅降低计算量
- 多尺度目标检测:密集连接提供的丰富特征层次有助于检测不同尺度的目标
- 工业质检:高特征表达能力使其能够捕获细微的缺陷特征
如果你对目标检测的性能优化感兴趣,除了HGBlock这种密集连接架构,还有许多其他创新方法值得探索。例如,空间金字塔池化能够融合多尺度感受野,注意力机制可以自适应地增强关键特征。想要深入了解这些前沿技术,手把手实操改进YOLOv26教程见,助你快速掌握各种改进策略。
总结
PPHGNetV2的HGBlock通过以下创新设计为YOLOv26带来了显著的性能提升:
- GPU友好的密集连接:延迟拼接策略减少内存访问开销,提升推理效率
- 压缩激励机制:通道维度的特征重标定增强关键特征表达
- 灵活的轻量化选项:LightConv提供计算量和精度的灵活权衡
- 自适应残差连接:智能判断是否启用残差,避免不必要的计算
实验结果表明,HGBlock在COCO数据集上使YOLOv26的mAP@0.5:0.95提升了1.3-1.4个百分点,同时保持了良好的推理速度。对于需要在GPU上进行高效推理的目标检测任务,HGBlock提供了一种性能和效率兼顾的优秀解决方案。更多开源改进YOLOv26源码下载,探索更多backbone优化技术。
提供计算量和精度的灵活权衡
- 自适应残差连接:智能判断是否启用残差,避免不必要的计算
实验结果表明,HGBlock在COCO数据集上使YOLOv26的mAP@0.5:0.95提升了1.3-1.4个百分点,同时保持了良好的推理速度。对于需要在GPU上进行高效推理的目标检测任务,HGBlock提供了一种性能和效率兼顾的优秀解决方案。更多开源改进YOLOv26源码下载,探索更多backbone优化技术。