4.6 UNTESTABLE FAULT IDENTIFICATION
不可测故障具有两个特点:
- 不能激发故障
- 不能将故障传播到primary output
所以一个故障不可测会有如下三个原因:
- 激发故障的条件是不可能的
- 将故障传播到primary output的条件是不可能的
- 故障激发和传播不能同时满足
不可测故障识别有几个好处:
- 可以提升ATPG的性能,因为如果事先不知道故障故障不可测,ATPG就会使劲去测这个不可测的故障,直到发现这个故障不可测,浪费精力
- 如果不识别,不可测故障以冗余的形式存在于电路中增加了芯片面积;而且还会增加功耗和传播延迟
- 如果不识别,不可测故障可能会干扰其他故障的探测
- 如果不识别,不可测故障会导致scan-based testing发生没必要的良率损失。因为芯片工作是整个运作,包括了这个不可测故障,在scan-based testing的时候就会因为这个不可测故障reject这颗芯片
综上,识别不可测故障是很值得努力去探索的。
过去的不可测故障识别技术有三种:
- fault-oriented methods based on deterministic ATPG
- fault-independent methods:基于conflict analysis(FIRE 就是其中一种方法,但它是基于single-line conflicts的方法)
- hybrid methods
下面介绍FIRE方法的例子。对于电路中的每个门,都有下面两种sets:
- S0 ---Set of faults not detectable when signal g = 0.
- S1 ---Set of faults not detectable when signal g = 1.
对于所有故障,每个set的Si都需要g = i',这个故障才能被探测到,所以像上面这种S0和S1的情况就不可测。例子如下图:
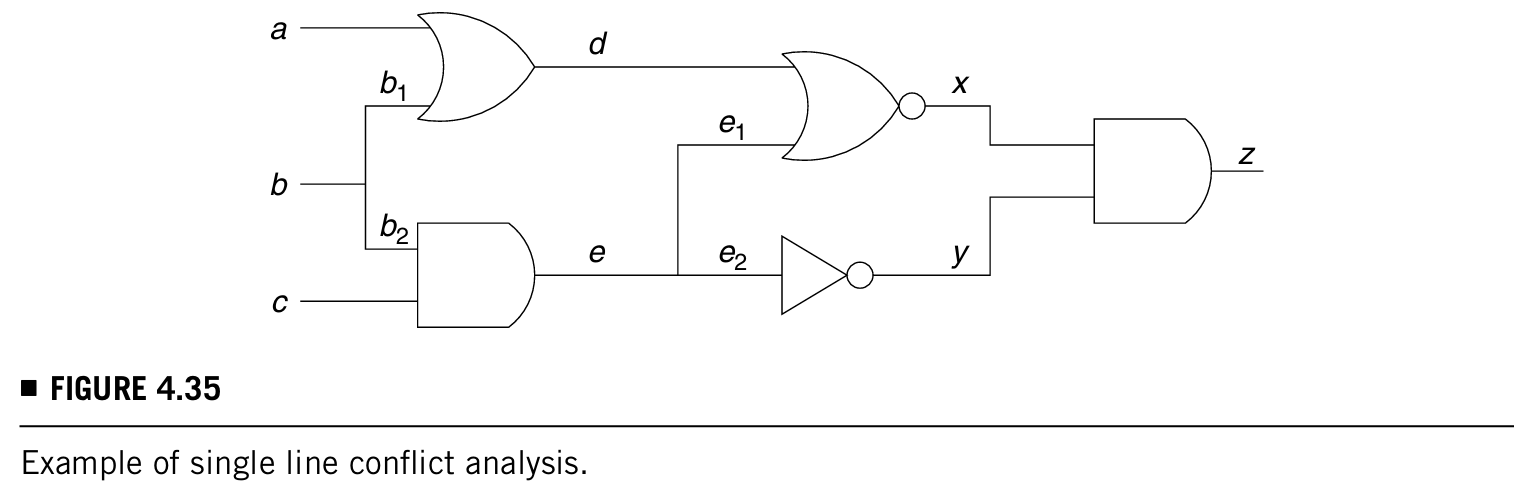
在前面所讲的静态逻辑仿真中,可以推导每一个门的状态,比如说:Implb,1,0 = {(b,1,0),(b1,1 0),(b2,1,0),(d,1,0),(x,0,0),(z,0,0)}。
分成几种情况讲解:
- Faults unexcitable due to b = 1(故障不可激发) :当b = 1的时候,d就不能为0,因为{b = 1}推出{d = 1},所以当b = 1的时候,故障d/1是不能被激发的(因为d本来就是1,只有需要b = 0的时候才能发现这里有故障)。所以归纳出一条定律:if k,v,t ∈ ImplN,w,then fault k/v would be unexcitable in time frame t with N = w in the reference time frame 0。所以同理,故障b/1,b1/1,b2/1,d/1,x/0,z/0在b = 1时是不可被激发的。
- Faults unobservable due to b = 1(故障不可观测) :因为{b = 1}能推出{x = 0},所以y的那根线就被block了,所以故障y/0和y/1需要b = 0才能被探测,同样的a,e1,e2也都是因为b = 1而不能被探测到。这个不可测的信号可以往回推,直到找到一个fanout stem,可能这里就不再是不可观测了,看这个fanout stem是否不可观测,是看从它出发的分支是否可以block别的信号(很好理解吧,举个例子就明白了)。还是看上图,如果a = 1且c = 0,两个分支b1和b2都是不可观测的,他们的fanout stem b在两条分叉上都不能block别的信号(b1要block住a的话,a需要为1;b2要block住c的话,c需要为0),所以fanout stem b还是不可观测的。因为b = 1造成的不能被传播的故障有:
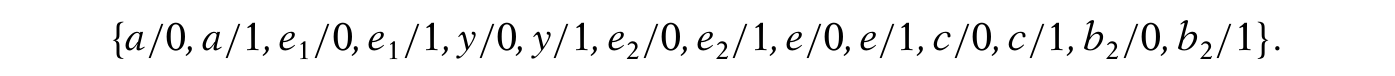
因此,综上S1的集合是上面两种情况的并集:
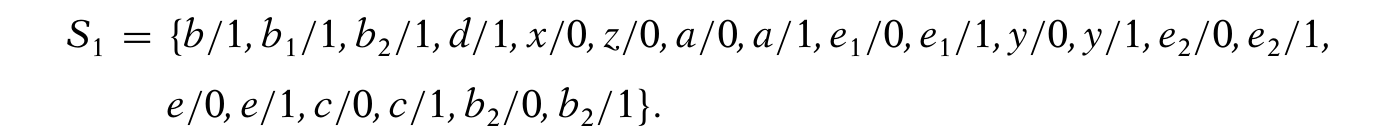
同样的,接下来讨论b = 0的情况,有:
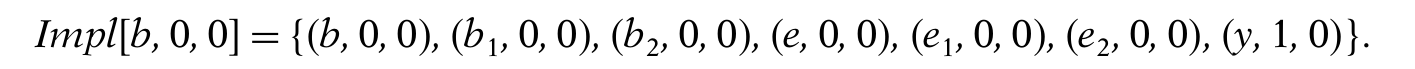
用和上面一样的方法推导得到S0:
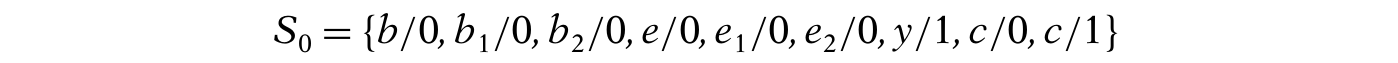
现在S1和S2都计算完成了,那么不可测故障就是两者的交集:S0S1 = {b2/0,e/0,e1/0,e2/0,y/1,c/0,c/1}。
4.6.1 Multiple-Line Conflict Analysis
与上面的single-line conflicts的例子不同,这一节到next level:Multiple-Line Conflict。
有两段都是multiple-line conflict的解释,太难读了,不如直接看最下面一段例子,用一个与门举例,下图是门电路图和推论图:
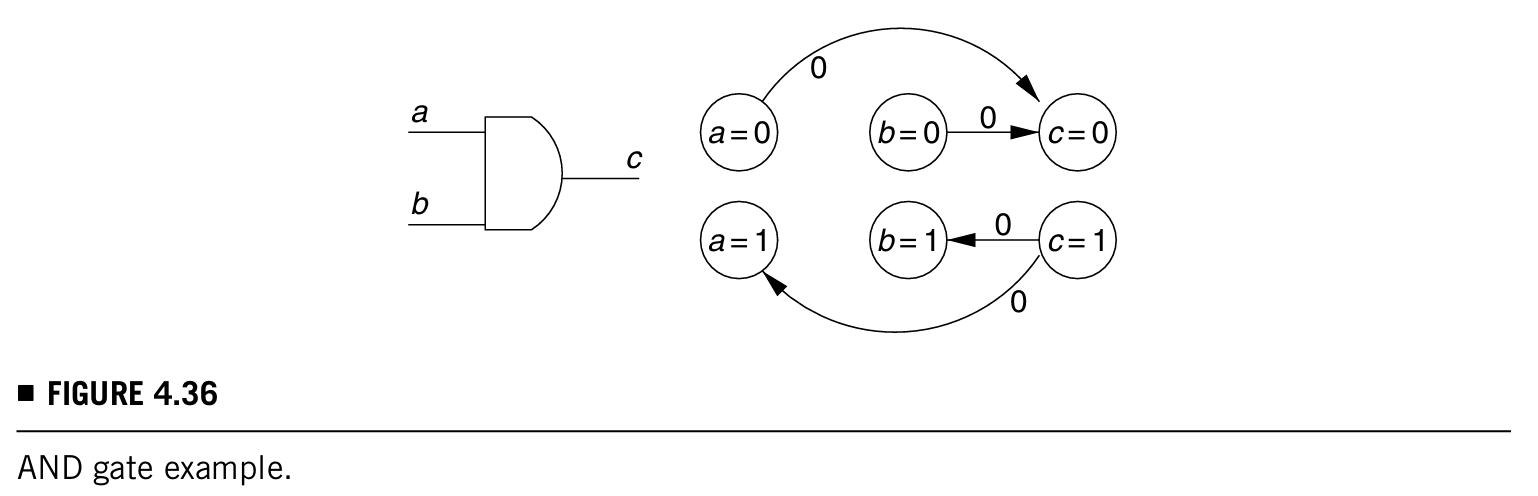
讨论两种方法:
- single-line-conflict algorithm:对于与门有三种情况{a = 0,a = 1},{b = 0,b = 1}和{c = 0,c = 1},(回想一下之前的例子中说的当a = 0的时候识别不可测故障a/0需要impla = 1),按照推论图,不可能值的组合有:
- 针对{a = 0,a = 1}:{a = 0,a = 1,c = 0}
- 针对{b = 0,b = 1}:{b = 0,b = 1,c = 0}
- 针对{c = 0,c = 1}:{c = 0,c = 1,a = 1,b = 1}
- 用到multiple-line conflict的话,会发现,有一种情况single-line-conflict没有考虑进去,那就是{a = 1,b = 1,c = 0}(这个可以被证明,有用的话参考原文),那么不可测故障就可以被下面几个集合识别出来:
- S0---Set of faults not detectable when signal a = 0.
- S1---Set of faults not detectable when signal b = 0.
- S2---Set of faults not detectable when signal c = 1.
所以为了识别像上面这样不明显的conflict值,一种新的maximizing local impossibilities的方法被加到FIRE方法的顶部,如下图算法11(这个算法在每个门上执行一次,所以计算复杂度和电路的规模成正比):

后面图中的例子,和下面好几个定理,和最后算法12,太抽象了/(ㄒoㄒ)/~~有需要的时候细看。
4.7 DESIGNING A SIMULATION-BASED ATPG(设计一个基于仿真的ATPG)
这一节讨论用仿真的方法而不是确定性算法(deterministic algorithms)如何进行测试向量生成。内容:
- 总览仿真如何指导测试生成
- 讨论在不同特定的框架(遗传算法genetic algorithms, 状态划分state partitioning, 图谱spectrum, etc)下如何进行测试生成
4.7.1 Overview
在这一章靠前的部分已经讲过,random test generator是最早的一种基于仿真的ATPG算法,任意一个可以检查出来新故障的向量都会被加到test set里面,但是这样的概念不太全面,面向复杂故障的时候random ATPG就没法产生向量了,导致这种方法的应用受限。
simulation-based ATPGs:
- 优点:减少测试生成的时间
- 缺点:
- 生成的test sets普遍比deterministic test generators长的多
- 在时序逻辑电路中,difficult-to-test faults常常被终止
- simulation-based ATPG由于其本质而无法检测不可测故障。所以不可测故障还是需要用到deterministic algorithms
4.7.2 Genetic-Algorithm-Based ATPG
原理和关键词:
- genetic algorithm (GA):简单的遗传算法(GA)可用于为组合电路以及时序电路生成单个测试向量。
- population of individuals:在典型的遗传算法中,定义了一个个体(或染色体)群体,其中每个个体都是针对当前问题的候选解决方案。
- 由于个体代表组合电路测试生成的测试向量,因此个体中的每个字符都映射到一个主要输入。如果使用二进制编码,则个体仅仅表示一个测试向量。
- fitness:每个个体都与一个适应度相关联,该适应度衡量了此个体解决该问题的质量。在测试生成的过程中,此适应度衡量了候选个体检测故障的优劣程度。适应度评估可以通过逻辑或故障仿真简单计算得出。
- selection , crossover , and mutation:基于评估的适应度,通过选择、交叉和变异的进化过程从现有群体中生成新的群体。这个过程会一直重复,直到最佳个体的适应度无法再提高或达到令人满意的程度为止。
遗传算法用于测试生成最简单的应用就是在每一次跑GA时候选出最好的测试向量。GA架构的简易图如下:
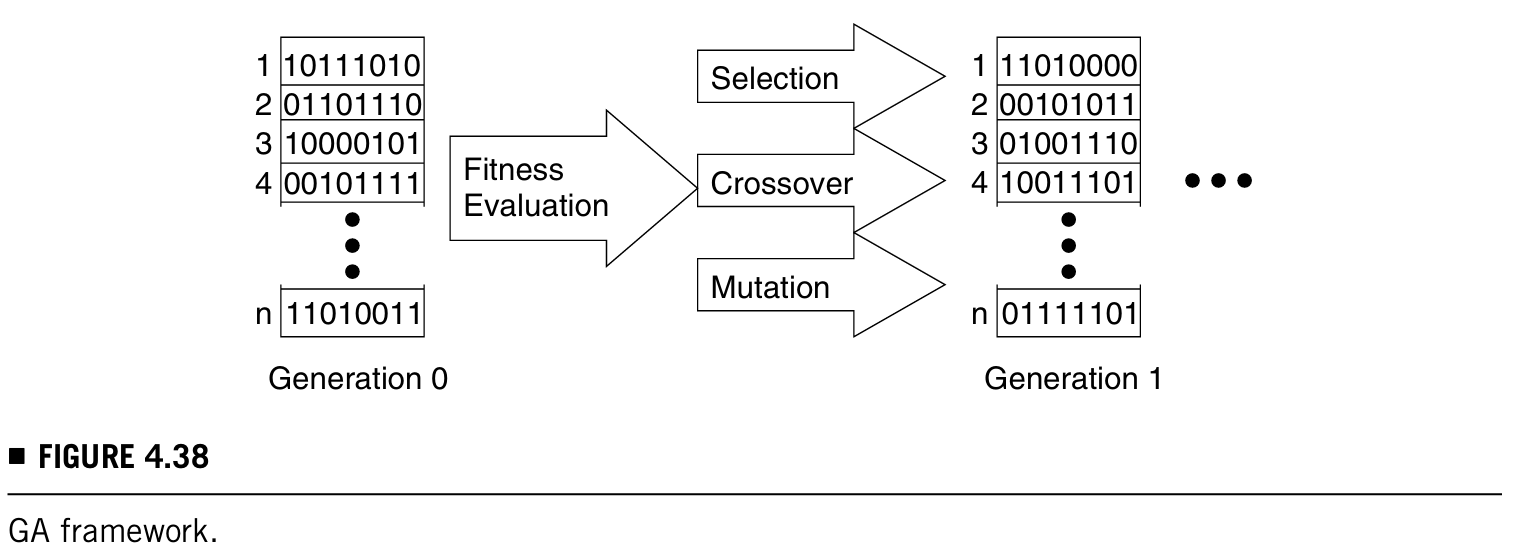
算法运行步骤如下:
- 由n个individuals组成一个随机的群体
- 故障仿真器用于计算每个个体的fitness
- 最优向量会被选中并加入test set中
- 加入的向量也会使fault set中减去能检测到的故障从而更新
- GA的就这样重复这个步骤,直到没有更多故障被检测到
当种群最初没有以合适的个体组合开始时,遗传算法过程可能无法产生有效的测试向量。当这种情况发生时,应重新初始化遗传算法,使用新的随机种群,并继续进行新的遗传算法尝试。整个过程如算法 13 所示:

在上述这个流程中,有三种GA operators,分别是对应selection、crossover和mutation,它们在每一次迭代中都能用到,对于每一种,下面都几种讨论它们最经典的method:
**第一种, for the selection operator。**有两种经常用到的流行架构:
- binary tournament selection(二进制锦标赛型选择):首先在population中随机选取2个individuals,有更高的fitness值的选为parent individual,重复这个步骤选择第二个parent。
- roulette wheel selection(轮盘赌选择):n individuals被分布在一个n slots的wheel上,每个slot有一个对应的fitness,这个轮盘如下图所示:
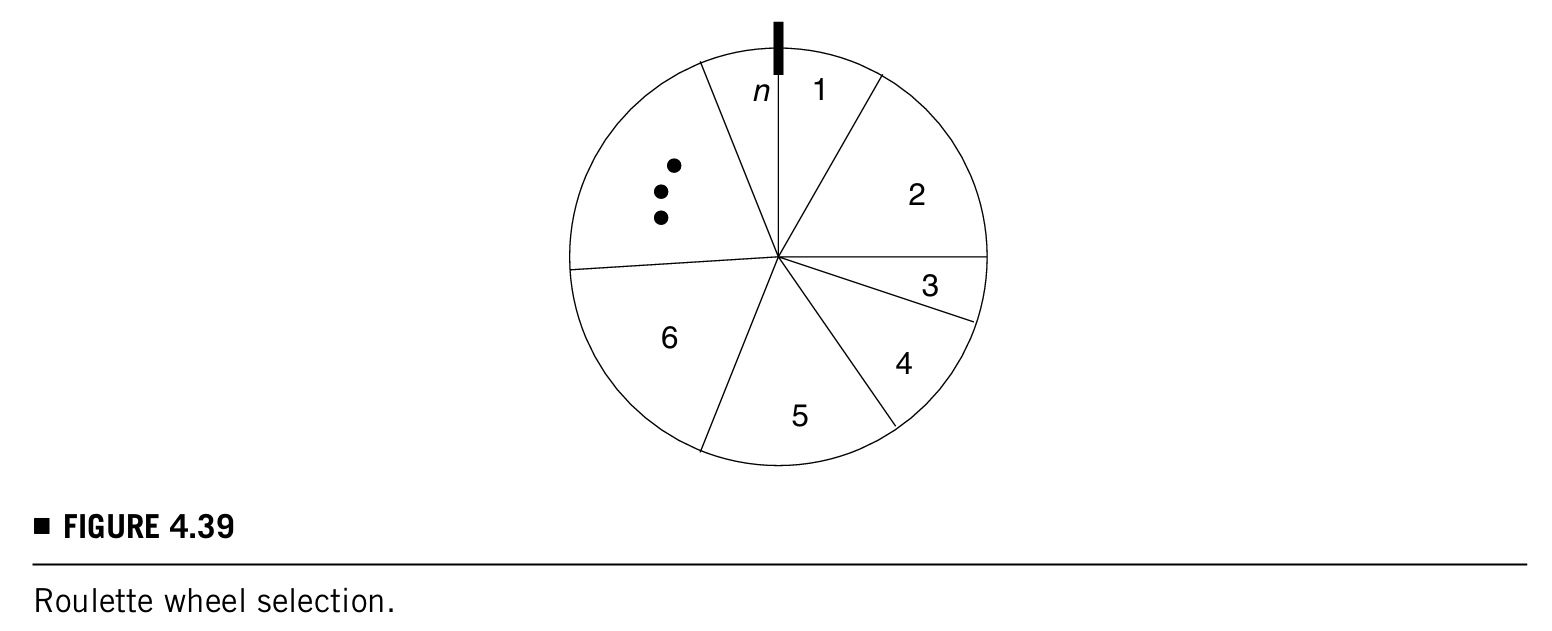 当轮盘转动之后,marker所指的位置就是选中的individual。
当轮盘转动之后,marker所指的位置就是选中的individual。
比较这两种架构,需要知道一个词叫selection pressure,好抽象,看不懂这一段在讲啥......
**第二种,for the crossover operator。**本质上来说,两个parent individuals一旦被选择,crossover就会被施加在两个parent individuals上从而产生两个children individuals,每个child都会继承每个parent的一部分染色体,而且more fit parents能传递给下一代的更多,有个偏向性,而且产生的个体会更加fit,因为他们继承了更多的more fit parent的特点。
接下来是几种crossover的解读:
- one-point crossover :个体的长度为
,两个parents会在一个随机的位置交叉,比如说r,在1和
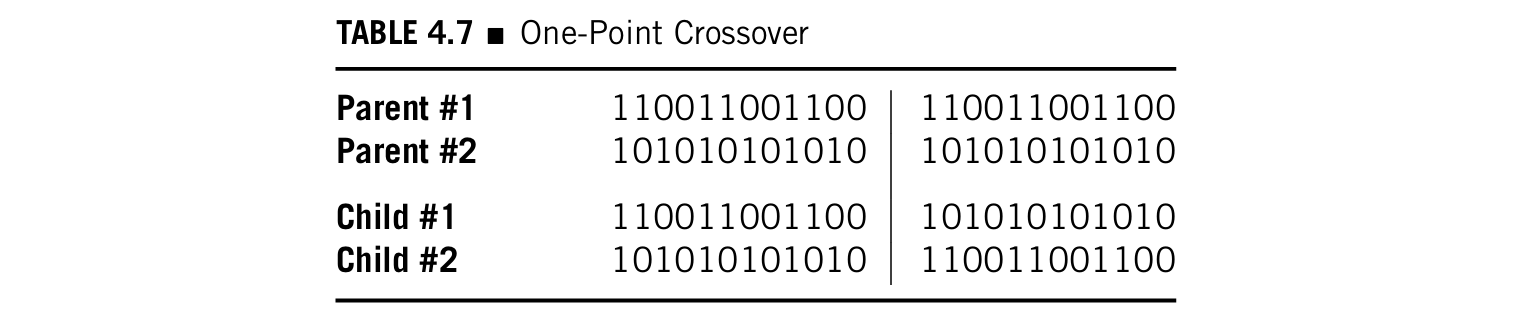
- two-point crossover :和one-point相似,只不过有两个crossover的点,交换的是两点中间的比特,如下图,一看就明白:
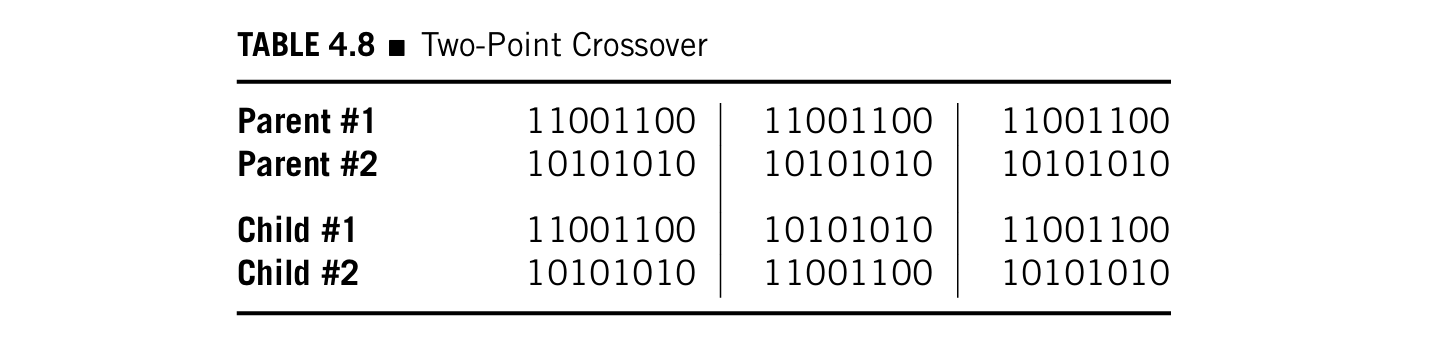
- uniform crossover :有一个crossover mask,就是这一串数字中为1的比特位置,两个parents互换,如下图,一看也明白:

第三种,for the mutation operator。会让crossover之后的child individual再次发生轻微的变化,所以叫做变异,比如下图例中的第三比特:

还需要知道一个参数叫做变异概率,如果这个值太小,那么就没什么变异,如果这个值太大,那么就会发生太多随机扰动,可能传几代之后相似性就消失了(跟生物似的,所以是遗传算法)。
4.7.2.1 Issues Concerning the GA Population
population size可以是individual length的函数,比如说时序逻辑电路的individual length就是primary inputs的个数乘测试序列的长度,population size就会不时的增加,提高individual的多样性,帮助扩大search space。
几个要点:
- 个体的编码方式:可以是二进制的(就是向量本身),也可以是非二进制的
- 测试集需要足够紧凑:可以使fault simulation时fitnesses的计算花销不会太大。两种方式:
- 故障采样
- 使用重叠population
总之,选取population的数量不能太小,保证个体的多样性,但又不能太大让花费不可控,还得权衡。
4.7.2.2 Issues Concerning GA Parameters
需要考虑的三个参数:
- the number of generations:生成的代数
- crossover probability:比如1,就是两个parents总是能交叉产生新的个体
- mutation probability:前面详细讲过
4.7.2.3 Issues Concerning the Fitness Function
fitness values如何计算是一个非常重要的问题。
在ATPG流程中,可以将整个流程分为两个大的部分,第一部分先检测好检测的fault,第二部分再检测难检测到的fault。
所以在一个典型的two-stage ATPG process中:
- first stage:尽可能的多检测到故障,这里fitness function可能非常简单,比如就是检测到的故障数量,进一步优化为:
 检测好检测的故障是一个过程,每一次被检测到的故障都会被从故障列表里面去掉,所以随着越来越多容易被检测到的故障减少,从剩下的故障中挑选fitness值比较好也就是好检测到的故障难度就会加大,那么这个时候就会准备进入第二个阶段,检测难检测的故障
检测好检测的故障是一个过程,每一次被检测到的故障都会被从故障列表里面去掉,所以随着越来越多容易被检测到的故障减少,从剩下的故障中挑选fitness值比较好也就是好检测到的故障难度就会加大,那么这个时候就会准备进入第二个阶段,检测难检测的故障 - second stage:基因算法的进程集中于一个特定的故障,fitness的算法计算两个值:
- how close the individual is to exciting the fault:要check有多少必要的逻辑值需要被赋予,如图例:假设故障为h/0,图中case2的把与门输入都设置为0显然不如1更能发现故障
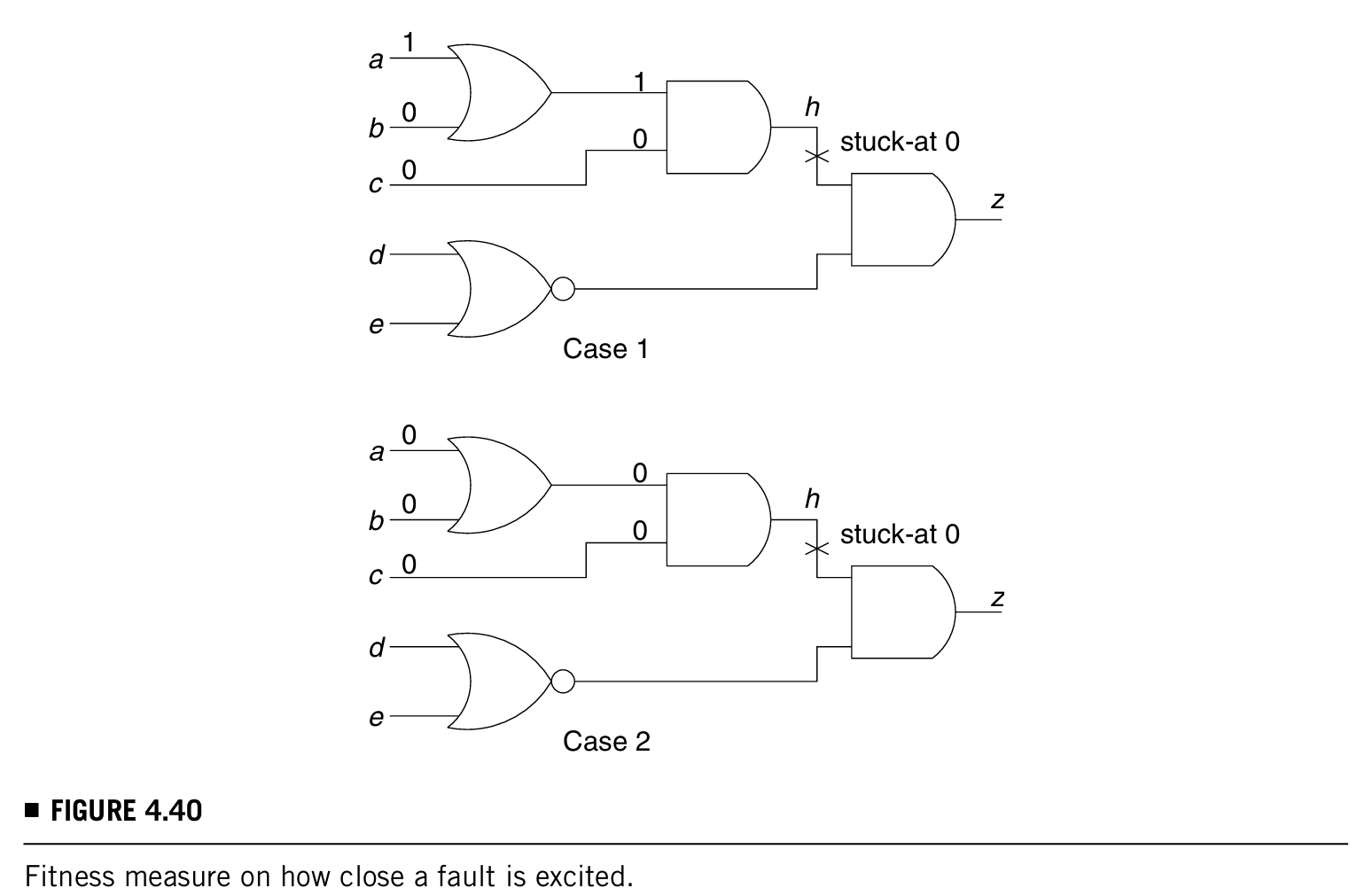
- how close it is to propagating the fault-effect to a primary output:需要结合D或者D'和observability value来定
- how close the individual is to exciting the fault:要check有多少必要的逻辑值需要被赋予,如图例:假设故障为h/0,图中case2的把与门输入都设置为0显然不如1更能发现故障
还简单讲了一下时序逻辑电路的fitness怎么算。
fitness的计算成本占了GA计算成本的大头,所以fitness function要非常小心地制定。