市面上 PDF 转文本的工具一大把,但转出来的 Markdown 标题丢了层级、表格变成碎片、段落断得乱七八糟?本系列文章将介绍如果用福昕SDK实现完美的 PDF 转 Markdown 工具,真正保留文档结构,标题,表格。。。。。。
在线体验: 点击立即体验 PDF 转 Markdown
发文前更新了合并单元格用html格式的选项,下文的截图就不更新了
一、PDF 转 Markdown,文本转换容易,完美可用不易
相信做过文档处理的同学都遇到过这个场景:手头有一份 PDF 报告,想喂给 AI 做摘要、翻译或问答。直觉上把 PDF 转成文本就行了------然而用 PyMuPDF、pdfplumber 试了一圈后发现,其实也不是那么简单,主要问题:
- 标题变成普通文本------例如:三级标题"3.2.1 系统架构设计"变成了和正文一样的纯文字
- 表格完全丢失------一个 6 行 3 列的表格变成了散碎的文字片段
- 段落碎片化------PDF 里一行文字在 PDF 排版引擎中被拆成了多个文本对象,转出来每行独立成段
- 页眉页脚混入正文------每隔一段就出现一行"第 X 页"或公司名称
- 单元格合并的表格获取困难------每隔一段就出现一行"第 X 页"或公司名称
这种"有文字但没结构"的结果,给 LLM 用几乎是灾难------AI 无法区分标题和正文,无法读懂表格数据,段落语义被随机截断。
我们需要的不是一个"文本提取器",而是一个"文档结构还原器"。
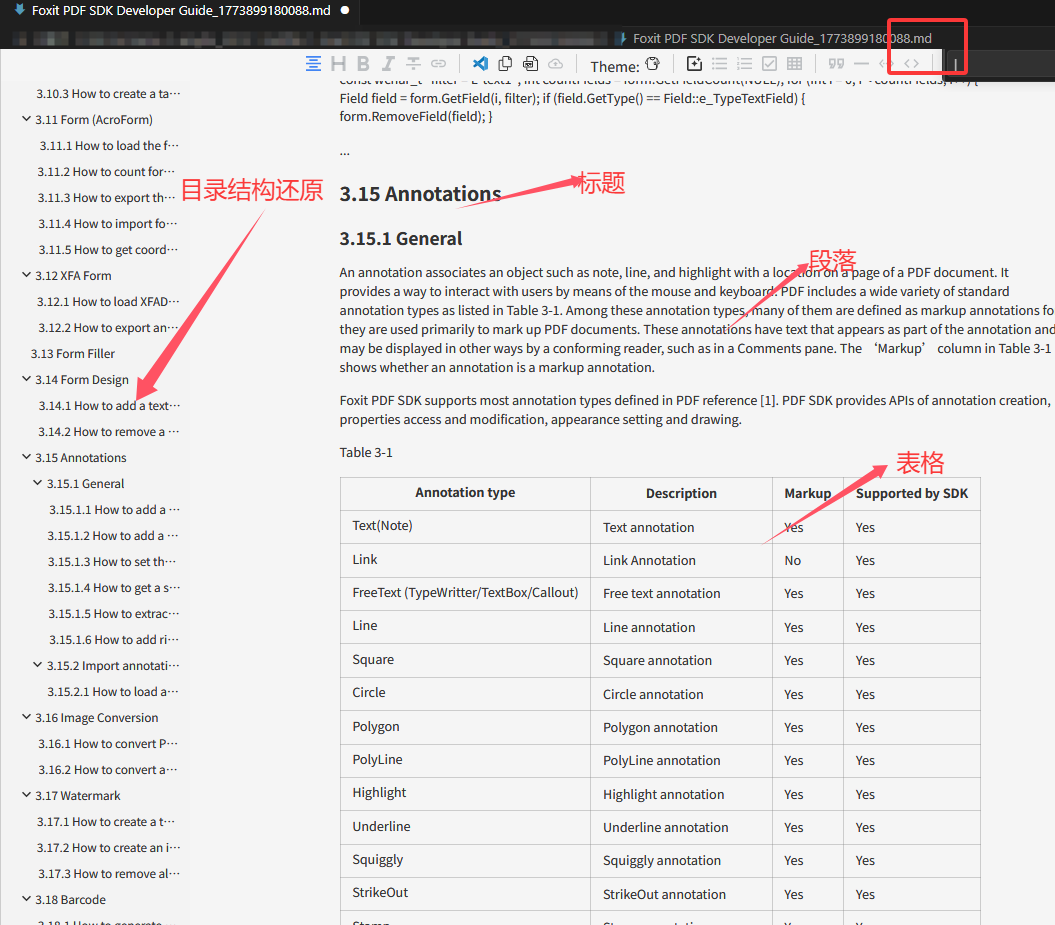
先看看本开源工具的实现效果:标题,表格,段落精准还原。
二、我们需要的是高保真的转换
感谢AI加持,目前已经实现了把 PDF 高保真地还原为结构化 Markdown ------标题有层级(# / ## / ###)、表格有管道对齐(| ... | ... |)、段落连续不碎、图片自动提取、页眉页脚自动过滤。
2.1 标题层级自动还原
工具会自动识别 PDF 中的标题,并还原正确的层级关系:
markdown
# *****项目计划
## 第一章 项目基本情况
### 1.1 团队情况
#### 1.1.1 成员组成
...标题识别不靠猜------目前综合利用了四种信号源:
- PDF 书签(优先级最高,也最准)
- 字号排名(比正文大 20% 以上的字号自动升级为标题)
- 利用Foxit SDK 版面分析模块确认(Layout Recognition 模块检测到的 Heading 元素)
- 编号模式匹配("第X章"、"3.2"、"(一)"等中文学术编号)
实现上,本文利用了上述四路信号级联融合,覆盖率非常高。
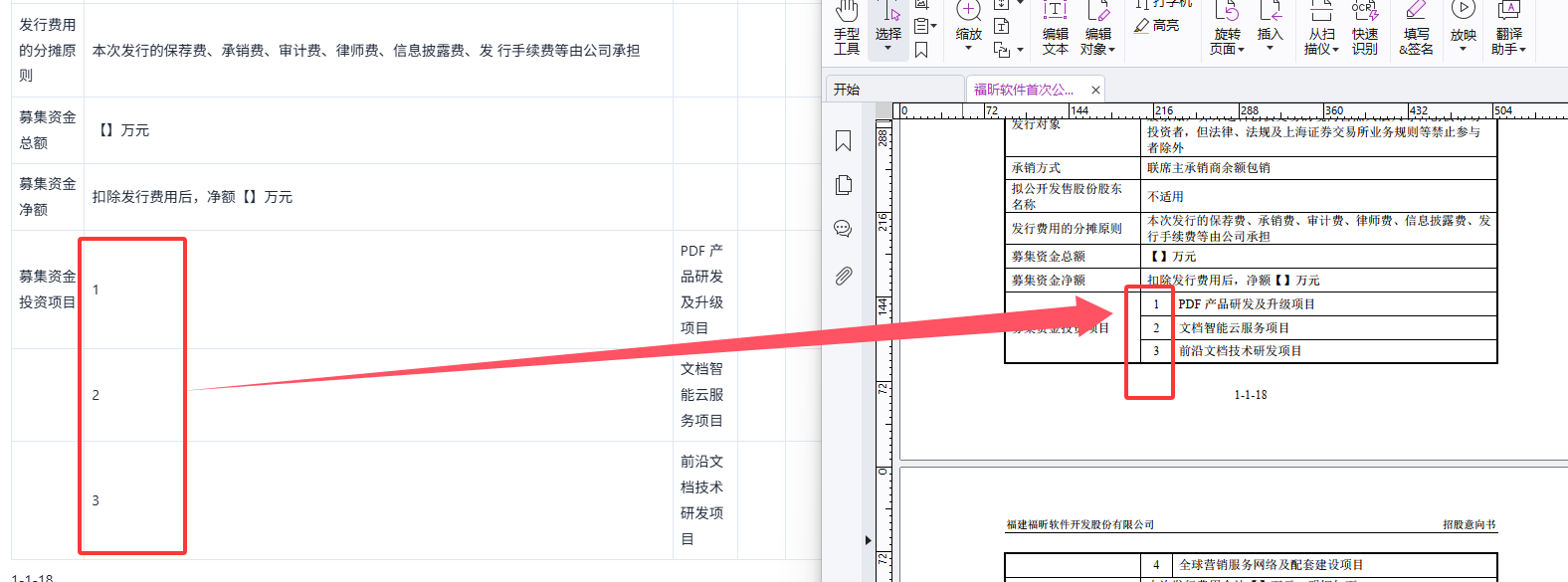
下图为转换后的MD文件的标题还原效果,基本一致。
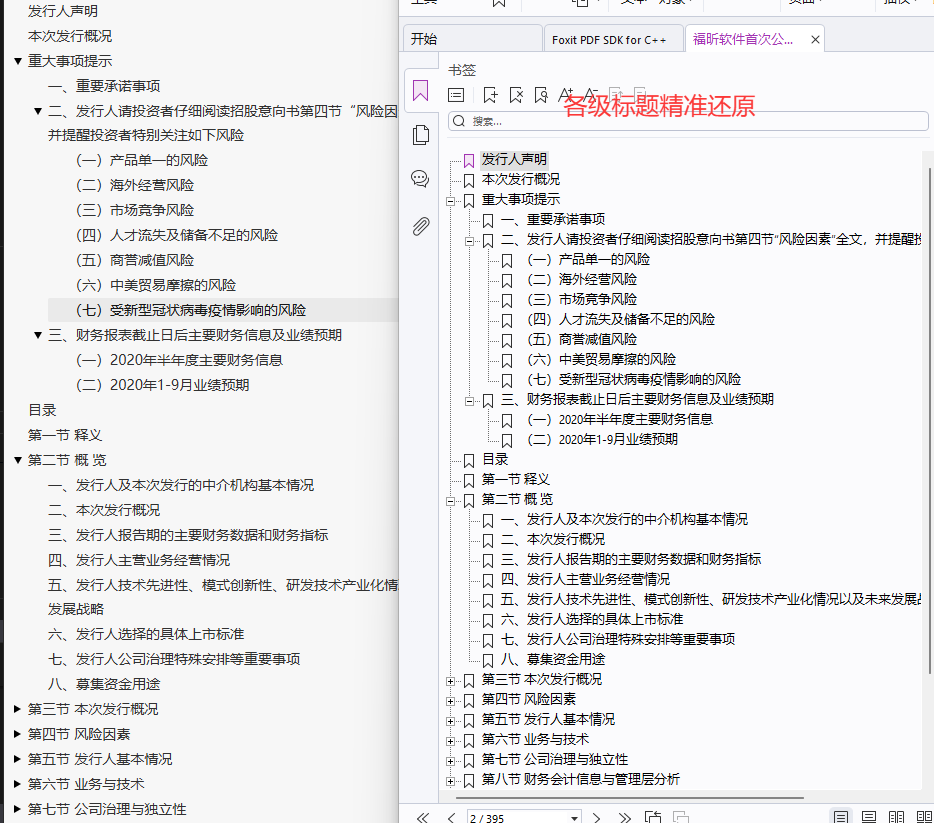
2.2 表格完整提取
PDF 中的表格通过 Foxit SDK 的 Layout Recognition(LR)模块自动检测和提取,输出为标准的 Markdown 管道表格,支持合并单元格:
更重要的是------工具还能自动纠正"伪表格" 。有些 PDF 中,一个很长的章节标题因为换行被 LR 误判为两列的表格,工具会自动检测这种情况并将其还原为标题。
合并单元格情况的准确逻辑还原:
错误对齐:
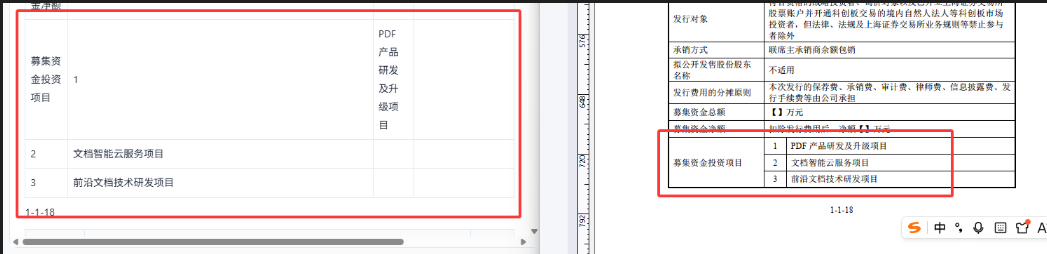
改进版的正确对齐:
2.3 段落智能合并
PDF 内部的文字存储方式和我们看到的段落完全是两回事------一个段落可能被 PDF 排版引擎拆成十几个独立的文本对象,每个对象就是一行。简单提取的话,输出会变成逐行碎片。
本工具通过多层合并策略解决这个问题:
- LR 段落分组:SDK 版面分析模块识别的段落边界框内的文本自动合并
- 几何间距启发式:根据行间距判断是否属于同一段落
- 续行检测:检测左边距对齐、行宽占满等信号判断续行
- 后处理清理:全局扫描移除中文场景下的假空行
效果就是输出的 Markdown 段落连续流畅,和原文阅读体验一致。
2.4 图片自动提取
PDF 中的嵌入图片会被自动识别、提取并保存为 PNG 文件,在 Markdown 中以图片引用的形式插入:
markdown
工具会自动过滤掉小于 20×20 像素的装饰性小图标(分隔线、logo 碎片等),只保留有实际内容的图片。
下载时如果 PDF 中包含图片,工具会自动打包为 ZIP 文件(Markdown + images 目录),下载后可以直接在本地渲染查看。
图片准确抽取,并支持过滤图片
图片的排版效果:
2.5 页眉页脚自动过滤
PDF 的每一页可能重复出现页眉(公司名称、文档标题)和页脚(页码)。工具通过频率统计自动检测:
- 同一文本在 3 页以上重复出现 → 判定为页眉/页脚,自动过滤
- 页码虽然每页都变,但位置固定 → 按位置分桶检测,同样自动过滤
转换后的 Markdown 干净清爽,不会每隔几段就蹦出一行"第 X 页"。
2.6 超链接保留
PDF 中的 URL 会被自动识别并转换为 Markdown 链接:
markdown
更多信息请参阅 [Foxit Developer Guide](https://developers.foxit.com/developer-hub/)三、Web UI:所见即所得
在线体验(已部署)
项目现已提供线上体验地址:
读者无需本地安装环境,打开网页即可上传 PDF 并查看转换结果。
工具提供了一个简洁美观的 Web 界面,整个使用流程如下:
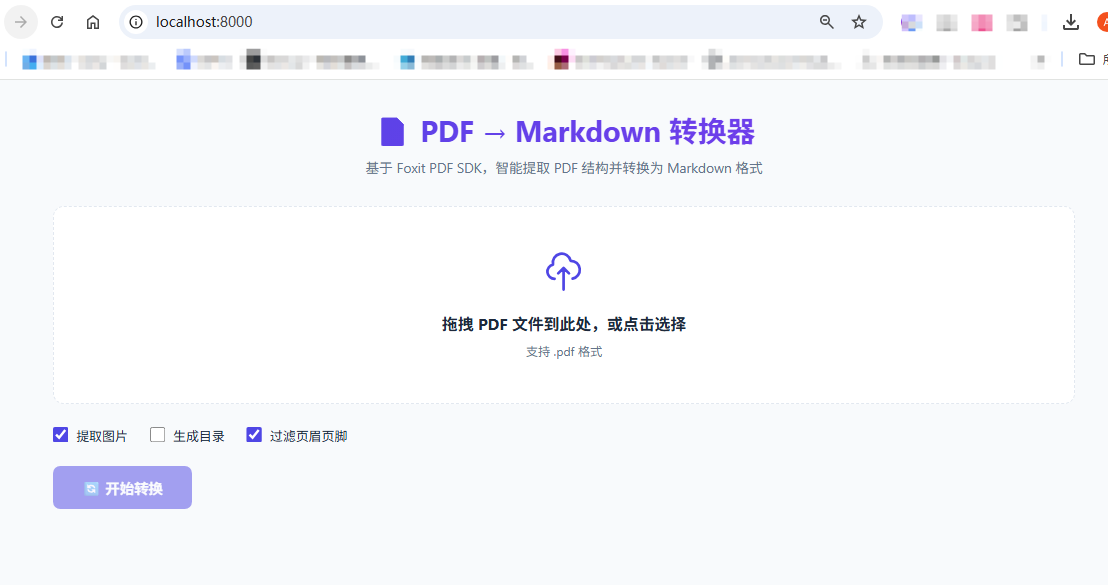
第 1 步:拖拽上传
打开浏览器访问 http://localhost:8000,直接把 PDF 文件拖进来,或者点击选择文件。
打开浏览器访问线上地址 https://pdf2md.doc-tool.qihangsoftware.cn/,直接把 PDF 文件拖进来,或者点击选择文件。
如需本地开发调试,再使用 http://localhost:8000 启动本地服务。
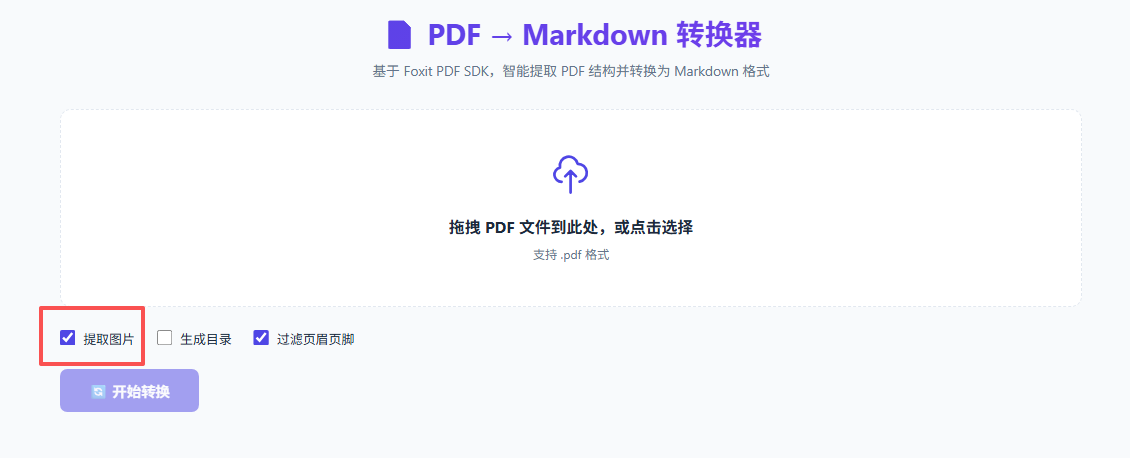
第 2 步:选择转换选项
上传后可以勾选三个选项:
| 选项 | 说明 |
|---|---|
| ✅ 提取图片 | 自动提取 PDF 中的嵌入图片 |
| ☐ 生成目录 | 从 PDF 书签生成 Markdown 目录 |
| ✅ 过滤页眉页脚 | 自动检测并跳过重复的页眉页脚 |
第 3 步:查看转换结果
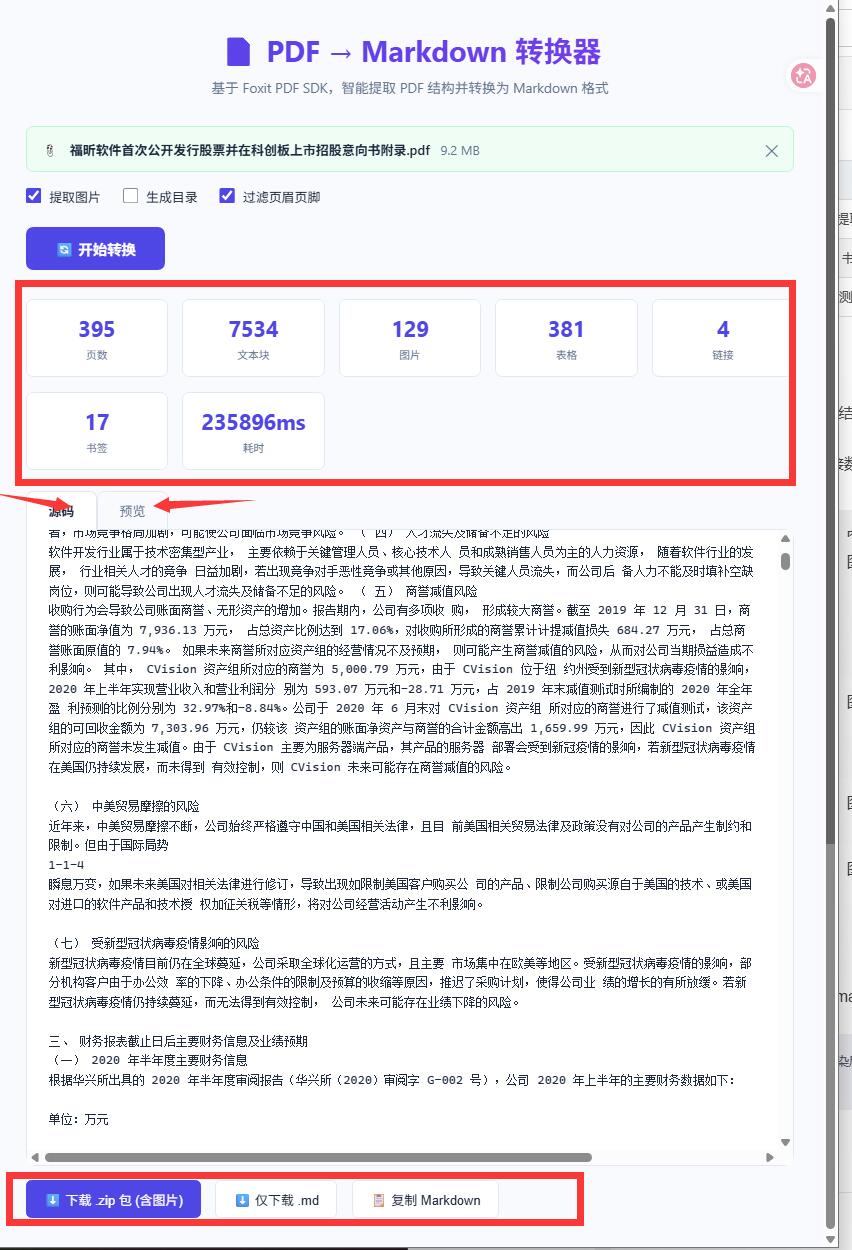
点击"开始转换"后,几秒内完成(170 页的报告约 3-5 秒)。结果区域提供:
- 统计卡片:页数、文本块数、提取图片数、表格数、链接数、书签数、耗时
- 源码标签:直接查看 Markdown 源码
- 预览标签:实时渲染 Markdown 效果(标题层级、表格、图片全可见)
第 4 步:下载结果
- 无图片时:直接下载
.md文件 - 有图片时:自动打包为
.zip(包含 Markdown 文件 + images/ 目录),下载后本地可直接渲染
四、多场景效果
本工具主要适用以下场景
4.1 中文学术论文
输入:一份 60+ 页的硕士学位论文,包含封面页、摘要、多级章节标题、表格、参考文献。
转换效果:
- 封面页信息完整提取(大学名称、论文标题、作者、指导教师)
- 章节标题层级还原正确(第一章 →
##、1.1 →###、(一) →####) - 论文中的研究方法表格完整保留
- 参考文献列表连续不碎
4.2 用户手册,说明书
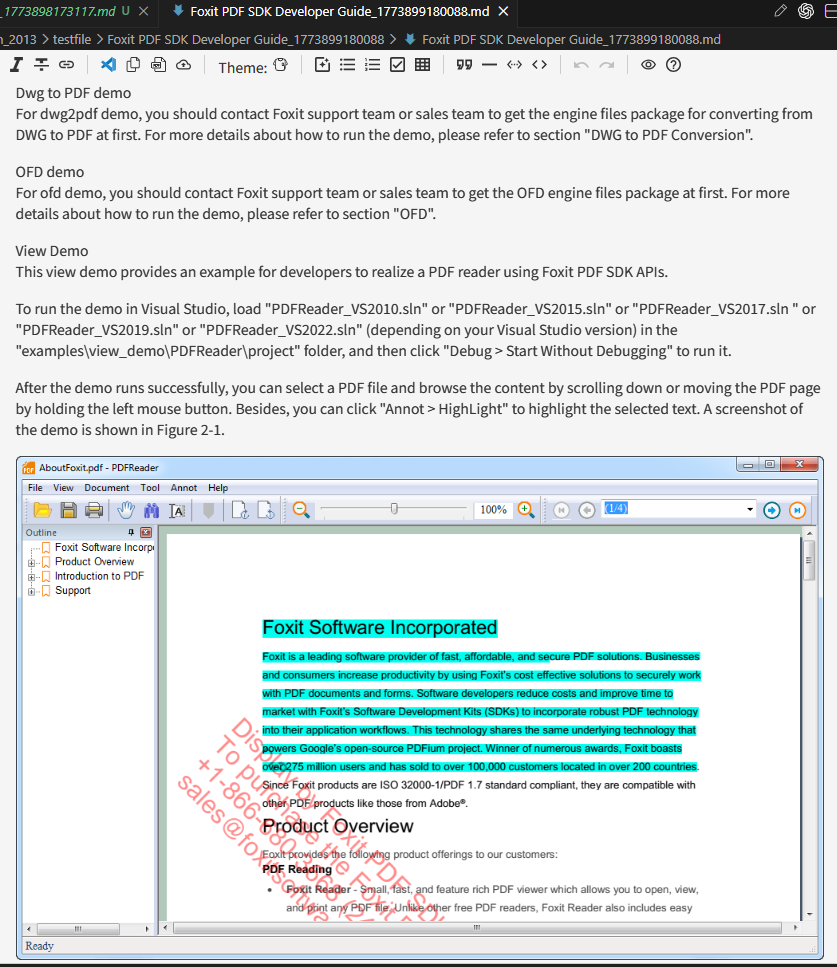
输入:Foxit PDF SDK Developer Guide,英文文档,包含目录、代码示例、嵌入图片。
转换效果:
- 英文目录页完整带点引线
- 代码示例保留为预格式化文本
- SDK 架构图片正确提取
五、技术栈与架构一览
整个工具采用两阶段流水线设计:
PDF 文件 ──→ pdf_parser.py (解析) ──→ 结构化数据 ──→ md_converter.py (转换) ──→ Markdown
│ │
│ Foxit SDK: │ 四级标题检测
│ · 逐字符文本提取 │ 段落智能合并
│ · LR 版面分析 │ 表格渲染
│ · 图片/表格/书签/链接 │ 页眉页脚过滤
▼ ▼
PDFContent 数据模型 Markdown 字符串| 组件 | 技术 | 功能 |
|---|---|---|
| PDF 解析引擎 | Foxit PDF SDK (Python) | 逐字符文本提取(带字体信息)、LR 版面分析、图片/书签/链接提取 |
| Markdown 转换器 | 纯 Python | 标题检测、段落合并、表格渲染、页眉页脚过滤 |
| Web 服务 | FastAPI + Jinja2 | REST API + 拖拽上传 Web UI |
| 结果打包 | Python zipfile | 含图片时自动打包 ZIP 下载 |
项目文件结构简洁清晰:
pdf2md_pyweb/
├── app/
│ ├── config.py # SDK License 和目录配置
│ ├── pdf_parser.py # PDF 解析核心(~1200 行)
│ ├── md_converter.py # Markdown 转换引擎(~900 行)
│ └── main.py # FastAPI 路由
├── templates/index.html # Web UI
├── uploads/ # PDF 上传暂存
├── output/ # 转换结果 + images/
├── requirements.txt
└── run.py # 启动入口六、快速上手
环境要求
| 项目 | 要求 |
|---|---|
| Python | 3.8 --- 3.12 |
| Foxit PDF SDK | pip install FoxitPDFSDKPython3 |
| 操作系统 | Windows 10/11 或 Linux |
| 内存 | ≥ 4 GB |
三步启动
bash
# 1. 安装依赖
pip install -r requirements.txt
# 2. 启动服务
python run.py
# 3. 打开浏览器访问
# http://localhost:8000也可以直接调用 REST API:
bash
curl -X POST http://localhost:8000/api/convert \
-F "file=@your_document.pdf" \
-F "include_images=true" \
-F "skip_header_footer=true"返回 JSON,其中 markdown 字段就是转换后的完整 Markdown 文本。
七、下一篇预告
这篇展示了工具的功能和效果。如果你好奇这些能力背后是怎么实现的------
- 四级标题检测的级联策略是怎么工作的?
- 段落碎片化是怎么被智能合并的?
- 遇到 LR 漏检表格和伪表格,怎么做后验校正?
**下一篇文章《PDF 转 Markdown 技术拆解:两阶段流水线、四级标题检测与段落智能合并》**将完整拆解架构设计和核心算法。敬请关注!
本项目开源,已经放到github,系列文章写完提供链接,如果有兴趣,也可以私信我提前获取源码!
技术栈:Python 3.10 + Foxit PDF SDK 11.x + FastAPI + Jinja2