注:本文为 "JIT 与 AOT " 相关合辑。
英文引文,机翻未校。
中文引文,未整理去重。
图片清晰度受引文原图所限。
如有内容异常,请看原文。
JIT 与 AOT 区别
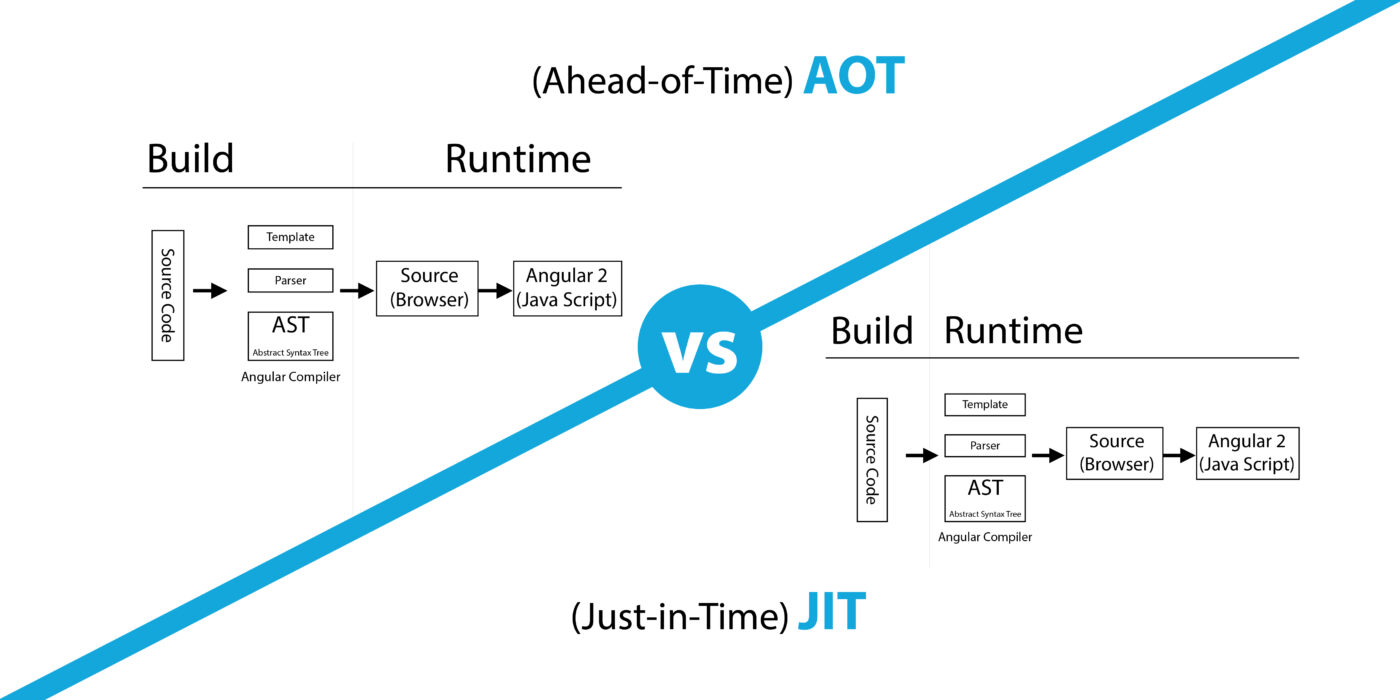
1 基本概念与典型实例
JIT (Just-In-Time) :即时编译,程序运行过程中动态完成编译。
典型实现:Android 平台的 Dalvik 虚拟机。
AOT (Ahead-Of-Time) :预先编译,程序执行前全部完成编译。
典型实现:Android 平台的 ART (Android Runtime)。
2 PGO 优化流程与实现差异
2.1 PGO 基本原理
PGO(Profile-Guided Optimizations,剖面引导优化)通过采集程序运行时的行为数据,指导编译器实施针对性优化,从而改变指令布局、提升分支预测精度、调整内联策略等,进而改变程序运行效率。
2.2 AOT 环境下的 PGO 流程
AOT 实现 PGO 通常采用多阶段编译模式:
- 仪器编译阶段:编译器在程序中插入数据采集指令,生成带采集逻辑的可执行文件。
- 剖面采集阶段:程序在测试环境或仿真环境中运行,执行典型业务流程,记录分支跳转频率、函数调用频次、循环迭代次数等运行时信息。
- 优化重编译阶段:编译器读取采集到的剖面数据,对程序进行二次编译,应用基于剖面的优化策略。
- 部署阶段:使用二次编译后的优化版本对外提供服务。
该流程需要多次编译与环境部署,整体周期较长,且依赖代表性运行数据,工程部署成本较高。
2.3 JIT 环境下的 PGO 流程
JIT 依托运行时环境天然具备剖面采集能力,流程更为简洁:
- 解释/低阶编译阶段:程序以解释模式或低优化等级编译模式运行,同时无侵入采集分支、调用、热点等运行时信息。
- 实时分析阶段:运行时环境持续统计函数调用热度、分支概率、类型分布等数据。
- 动态编译优化:当函数或代码块达到触发阈值时,JIT 编译器依据已有剖面信息实施高等级优化,生成优化后的机器码并替换原有执行逻辑。
- 持续自适应优化:程序运行过程中可持续采集新信息,对已有机器码进行重新编译与优化。
JIT 环境下 PGO 无需额外编译阶段与离线部署流程,可在程序正常运行过程中完成,适合实际生产环境使用。
3 JIT 相对 AOT 的其他优势
3.1 跨边界的 LTO 能力
传统 AOT 优化以编译单元为界限,LTO 可在链接阶段实施跨编译单元优化。动态链接库会形成优化边界,动态符号无法被内联与深度优化。
JIT 环境下,动态加载、动态生成的代码均参与统一优化,不依赖全量静态链接,可实现跨模块的全局优化。
3.2 运行时环境感知优化
JIT 在程序运行阶段执行编译,可获取目标设备的硬件配置、指令集支持情况、运行时配置等信息。这些信息可作为编译期常量参与优化,生成与当前环境匹配的机器码。
3.3 编译与运行时融合的计算能力
JIT 语言中编译阶段与运行阶段无严格分界,编译与执行可交替进行。程序可在运行时使用完整语言功能完成计算与代码生成,相关计算开销仅体现在启动阶段,对稳定运行阶段的性能表现不产生影响。
3.4 运行时热更新支持
JIT 可支持 HotSwap 类运行时函数替换能力。当函数实现发生变更时,JIT 可废弃依赖该函数的优化代码,并基于新实现重新编译与优化。AOT 环境下此类操作会破坏既有优化结构,实现条件受限。
3.5 动态类型与泛型特化优化
JIT 可根据运行时实际类型信息实施类型特化优化,对泛型代码、动态调用场景进行针对性优化,减少虚调用与类型检查开销,提升执行效率。
4 AOT 相对 JIT 的优势
4.1 程序启动耗时更短
JIT 需要在运行时完成编译与优化,程序需要经过预热阶段才能达到稳定性能。AOT 不包含运行时编译步骤,启动后可直接进入执行状态。
4.2 运行时内存占用更低
JIT 需要分配内存用于存储剖面数据、编译缓存与中间表示。AOT 运行阶段不保留编译相关数据,内存占用更低。
4.3 复杂编译优化的支持
AOT 编译为离线过程,可使用更高复杂度的分析与优化算法,通过更长编译时间换取执行效率。JIT 受限于运行时响应速度,通常简化部分优化策略。
4.4 程序逆向分析难度更高
JIT 输入多为高级中间表示,包含较多结构信息。AOT 直接编译为机器码,语言级结构保留较少,逆向分析难度更高。
5 技术演进与混合优化方案
传统 JIT 与 AOT 的性能边界并非固定,现有技术可对二者进行补偿:
- Graal 编译器在 AOT 阶段通过预训练模型推导剖面信息,模拟 PGO 效果。
- JIT 通过缓存剖面与编译结果、提前执行部分计算,缩短预热时间。
- Azul Cloud Native Compiler 将 JIT 服务部署至独立节点,共享剖面与优化结果,降低重复编译开销。
6 Java 平台 AOT 编译器实现
桌面环境下,Java 存在可替代 JIT 的 AOT 编译工具:
- GraalVM AOT 编译器:可将 Java 代码编译为平台原生机器码。
- jaotc:JDK 9 及后续版本内置的 AOT 编译器,实现基于 Graal 技术栈。
7 典型平台性能数据(以 .NET Core 为例)
- 未启用 AOT 的 ASP.NET Core 应用冷启动耗时约 150 ms,JIT 可在运行中持续优化并对高频泛型类型进行特化处理。
- 采用 ReadyToRun 混合编译模式,初始化逻辑通过 AOT 优化,启动耗时可降至约 80 ms。
- 经 CoreRT 全量 AOT 编译后,程序启动耗时可低于 10 ms,适用于 AWS Lambda 等函数计算场景。
全量 AOT 会限制表达式树动态生成 IL 等特性,在 .NET Core 生态中,除体积与启动速度需求外,AOT 相对 JIT 的优势并不明显。
8 AI 框架中的 JIT 与 AOT 应用
8.1 AOT 应用场景
AOT 适用于移动端与嵌入式深度学习部署,形式包括:
- 推理引擎:训练阶段完成模型固化,推理阶段直接加载预编译模型结构。
- 静态图生成:通过 AI 编译器将网络模型转换为统一 IR 表示,运行阶段执行预编译结果。
代表框架:TensorFlow、MLIR 相关工具链。
8.2 JIT 应用场景
JIT 实现动态编译与实时优化,适用于动态网络结构与快速迭代开发:
- PyTorch 2.X Inductor:将 Python 代码实时编译为原生机器码。
- 计图 (Jittor):基于元算子与统一计算图,通过 JIT 实现自动优化与硬件适配。
9 性能与工程性总结
- JIT:峰值吞吐表现更高,支持动态代码生成、热更新与自适应硬件优化,程序启动速度较慢,运行时存在额外资源开销。
- AOT:启动速度快,内存占用低,可执行深度离线优化,程序逆向难度更高,不支持运行时动态剖面优化,动态特性支持受限。
- 理论层面,AOT 拥有更充足的编译时间与优化空间,可生成更高效的机器码。工程实践中,JIT 生态迭代速度更快,对动态环境与运行时信息的利用更充分,综合性能表现优于传统 AOT 实现。
- 云原生与 Serverless 场景对启动速度存在要求,AOT 编译方案被广泛采用;长期运行的服务端场景更侧重峰值性能,JIT 优化方案具备更高适用性。
AOT 与 JIT 编译
部署环境决定机器学习模型由高级计算图转换为可执行机器码的时机与方式。编译时机构成即时编译与提前编译的区分条件。对该差异的分析可支撑模型在特定场景下的优化,包括边缘设备低延迟推理与云集群高吞吐量训练等场景。
编译时间线AOT 与 JIT 的差异体现在编译流程相对于应用运行阶段的执行时序。
在提前(AOT) 流程中,编译过程以离线方式完成。模型训练结束后,模型定义作为输入,经由编译工具链处理,生成独立二进制文件或库文件。该文件包含模型运行所需的优化后机器码,不包含编译组件。运行阶段,应用加载并执行该二进制文件即可完成计算。
在即时(JIT) 流程中,编译过程在程序运行阶段动态执行。PyTorch、JAX 等框架对程序执行进行监控。模型或函数首次被调用时,JIT 编译器捕获计算图,执行优化流程并生成机器码。生成的代码被缓存并参与执行。后续调用直接使用缓存内核,不再重复编译。
下图展示两类流程的结构差异。
AOT 工作流 JIT 工作流 模型定义 编译器栈(离线) 二进制产物 运行时执行 Python 脚本 首次执行 编译器栈(运行时) 快速执行 后续调用 代码缓存
AOT 与 JIT 工作流对比。AOT 模式下编译器在部署前执行一次。JIT 模式下编译器作为执行流程的组成部分。
即时(JIT)编译JIT 编译广泛应用于模型研究与训练阶段,可保留程序执行的灵活性。torch.compile、XLA 等工具可在不脱离 Python 执行环境的前提下,完成算子融合与执行优化。JIT 编译存在预热开销。数据首次进入模型时,系统执行图编译操作,延迟指标显著上升。
JIT 编译函数的执行过程包含输入张量形状分析、计算流程追踪、优化策略应用与 GPU 内核生成。若后续调用中输入形状发生变动,JIT 编译器可触发重新编译,生成适配新维度的优化内核。
JIT 的优点1. 易用性 :可与 Python 控制流协同工作。编译阶段前可使用标准 Python 调试工具。
- 动态优化:编译器在运行阶段获取张量形状与数据类型信息,可生成对应场景的专用代码。
JIT 的缺点
- 运行时开销:编译相关组件需部署于生产环境,会提升内存占用与依赖体积。
- 延迟波动:新执行路径或张量形状变化可触发重新编译,造成请求延迟波动。
提前(AOT)编译
AOT 编译将机器学习模型按照 C++ 程序的方式处理,生成依赖最小运行时的专用可执行文件,不依赖完整训练框架。该方式适用于移动设备、嵌入式系统与 FPGA 等专用加速硬件的部署场景。
AOT 流程通常要求输入静态形状,或为动态维度设定明确边界。编译器执行多阶段分析,预先确定内存需求,实现静态内存分配,降低运行阶段动态内存管理带来的开销。
AOT 的优点
- 性能稳定性:全部编译工作在部署前完成,运行阶段无额外编译行为,推理延迟保持稳定。
- 可移植性 :输出产物多为共享库(
.so或.dll),可在 C、C++、Java、Rust 环境中调用,目标环境无需配置 Python 或 PyTorch。 - 硬件执行效率:编译阶段可执行高复杂度优化策略,编译耗时不影响终端用户体验。
AOT 的缺点
- 灵活性受限:模型计算图需保持静态结构。基于张量数据的动态控制流难以直接适配,通常需要对模型结构进行修改。
- 工具链配置复杂:交叉编译环境的搭建会提升构建流程复杂度,例如在 x86 服务器上为 ARM 架构移动设备编译代码。
性能比较
通过多轮推理请求的执行时间可直观体现两类编译策略的差异。下图对标准解释器、JIT 编译器与 AOT 编译模型的延迟表现进行对比。
10 轮运行延迟对比。JIT 存在由编译开销带来的初始峰值,后续性能优于解释器。AOT 自首次运行起维持稳定低延迟。
策略选择
AOT 与 JIT 的选择不取决于单一编译速度指标,现代编译器对两类模式通常采用相同的底层优化流程。方案选择依据部署环境约束确定。
JIT 适用场景
- 研究与实验阶段
- 内存与计算资源充足的环境,如云服务器
- 模型依赖大量动态 Python 特性或输入形状存在变动
AOT 适用场景
- 资源受限的边缘设备部署场景,如移动设备、物联网终端
- 对启动延迟存在严格要求的场景
- 模型需集成至无 Python 运行时的 C++ 应用程序
两类编译流程生成的中间表示(IR)。编译器均将计算图转换为 IR 形式,以完成后续优化与代码生成工作。
计算图、中间表示及其应用
1 计算图
1.1 定义
计算图(Computational Graph) 是表示数值计算过程的有向图结构,用于描述运算、数据及其依赖关系。计算图通常表现为有向无环图(DAG, Directed Acyclic Graph)**,是机器学习框架对模型逻辑的统一抽象形式。
1.2 基本组成
- 节点(Node)
分为两类:- 数据节点:表示张量、矩阵、标量、变量、常量等数据对象。
- 运算节点:表示算子操作,如加法、乘法、矩阵乘法、卷积、归一化、激活函数等。
- 有向边(Edge)
表示数据流动方向与数据依赖关系,决定计算执行顺序。
1.3 基本特征
- 计算顺序由拓扑序确定,不存在循环依赖。
- 完整记录从输入到输出的所有计算步骤。
- 与高级语言(Python)及框架(PyTorch、TensorFlow、JAX)强相关。
2 计算图转换为 IR 形式
2.1 IR 的定义
中间表示(Intermediate Representation, IR) 是编译器内部使用的与硬件、框架无关的标准化表示形式,位于高层计算图与底层机器码之间,是编译优化的主要载体。
2.2 转换过程
计算图转换为 IR,是将高层、框架相关的计算逻辑翻译为统一、结构化、可优化的中间形式的过程,主要步骤如下:
- 计算图遍历与解析
提取算子类型、张量形状、数据类型、控制流、数据依赖等信息。 - 语义归一化
将框架特有的高层算子(如Conv2d、BatchNorm、Linear)转换为编译器可处理的基础运算集合。 - 构建 IR 结构
生成与硬件无关的中间表示,形式包括图形化 IR、三地址码 IR、基本块序列等。 - 附加元信息
补充形状信息、内存布局、数据类型、目标设备等编译所需信息。 - IR 优化
执行算子融合、死码消除、常量传播、内存复用等优化。 - 机器码生成
优化后的 IR 被进一步翻译为 CPU、GPU 或 NPU 等平台的可执行指令。
2.3 转换的作用
- 解耦高层框架与底层硬件,实现一次编译、多平台部署。
- 为 JIT 与 AOT 提供统一的优化对象。
- 屏蔽不同框架之间的接口差异。
3 计算图与数据流图的区别
3.1 数据流图(Data Flow Graph, DFG)
数据流图是一种更通用的计算模型,描述数据在处理单元之间的流动与变换,广泛用于硬件设计、数字电路、并行计算等领域。
3.2 主要区别
- 抽象层次不同
- 计算图:面向数值计算与机器学习,高层、与框架强相关。
- 数据流图:面向硬件与并行系统,底层、与计算结构强相关。
- 节点语义不同
- 计算图节点:算子、张量、变量、模型层。
- 数据流图节点:算术单元、寄存器、触发器、功能模块。
- 依赖表示不同
- 计算图:强调数学运算依赖与控制流。
- 数据流图:强调数据传输、时序与硬件资源占用。
- 应用领域不同
- 计算图:机器学习模型表示、自动微分、编译优化。
- 数据流图:处理器架构、FPGA 逻辑、数据流处理器设计。
- 优化目标不同
- 计算图:优化运算效率、内存占用、推理延迟。
- 数据流图:优化吞吐量、流水线、硬件资源利用率。
4 计算图的常见应用场景
- 神经网络前向传播表示
深度学习模型的每一层运算均被组织为计算图,形成从输入张量到输出结果的完整执行流程。 - 自动微分与梯度计算
基于计算图的依赖关系,可自动应用链式法则实现反向传播,生成梯度计算子图。 - 模型导出与序列化
ONNX、TorchScript、TF Graph 等格式均以计算图为基础,实现模型在不同框架间的迁移。 - JIT / AOT 编译输入
编译器首先将用户代码转换为计算图,再转为 IR 进行优化与代码生成。 - 静态图执行模式
TensorFlow 1.x、JAX 等系统使用静态计算图实现预调度与全局优化。 - 量化、剪枝、压缩等模型改造
以计算图为单位统一修改算子精度、移除冗余分支、合并连续运算。
5 基于计算图的模型优化方法
在计算图层面可实施多种与硬件无关的程序变换,提升执行效率:
- 算子融合(Operator Fusion)
将多个连续算子(如MatMul + Add + ReLU)合并为单一复合算子,减少内存读写次数。 - 常量折叠与传播
在图阶段预先计算常量表达式,避免运行时重复执行。 - 死代码消除
识别并移除对输出无贡献的计算分支与张量。 - 公共子表达式消除
识别重复计算结构,统一计算结果并复用。 - 内存布局优化
根据计算访存模式调整张量存储顺序,提升缓存命中率。 - 静态内存规划
预先确定所有张量的生命周期,实现内存重叠复用。 - 并行化调度
识别无依赖的子图,将其分配至不同计算单元并行执行。 - 动态形状特化
对频繁出现的张量形状生成专用计算路径,提升执行效率。 - 控制流规范化
将动态 Python 控制流转换为图级结构化控制流,便于编译器优化。
6 总结
计算图是机器学习模型的高层结构化表示,是连接用户代码与编译器的关键抽象。计算图经规范化后转换为与硬件无关的 IR,是 JIT 与 AOT 编译的基础流程。计算图与数据流图在抽象层次、节点语义与应用场景上存在明显区别。以计算图为对象可实施算子融合、内存优化、并行调度等一系列变换,从而在不改变模型数学行为的前提下提升执行效率与部署适配能力。
reference
- 对比 JIT 和 AOT,各自有什么优点与缺点? - 知乎
https://www.zhihu.com/question/23874627 - AOT 和 JIT 以及混合编译的区别、优劣 - linghu_java - 博客园
https://www.cnblogs.com/linghu-java/p/10577515.html - AOT vs JIT:性能提升300%的背后,你必须知道的文档细节差异-CSDN博客
https://blog.csdn.net/QuickDebug/article/details/155935768 - AOT 与 JIT 在生产环境的取舍 · DavidChan's Blog
https://imchenway.com/zh-CN/2020-12-jvm-aot-vs-jit-comparison/ - AOT 与 JIT 编译策略
https://apxml.com/zh/courses/intro-ml-compiler-optimization/chapter-1-ml-compilation-stack/aot-vs-jit-compilation - Just-in-Time (JiT) vs Ahead-of-Time (AoT) compilation in Angular - 2017
https://stackoverflow.com/questions/41450226/just-in-time-jit-vs-ahead-of-time-aot-compilation-in-angular