云南省各城市天气数据预处理
- 摘要
- 一、引言
- 二、相关理论与技术
-
- [1. Pandas 库](#1. Pandas 库)
- [2. NumPy 库](#2. NumPy 库)
- [3. PyMySQL与SQLAlchemy 库](#3. PyMySQL与SQLAlchemy 库)
- [4. Pathlib 库](#4. Pathlib 库)
- 三、云南省各城市天气数据预处理
-
- [1. 数据加载模块](#1. 数据加载模块)
- [2. 数据探查模块](#2. 数据探查模块)
- [3. 重复值处理模块](#3. 重复值处理模块)
- [4. 日期特征处理模块](#4. 日期特征处理模块)
- [5. 天气类型与风力等级标准化](#5. 天气类型与风力等级标准化)
- [6. 温度数据清洗与缺失值填充](#6. 温度数据清洗与缺失值填充)
- [7. 数据持久化模块](#7. 数据持久化模块)
- 四、完整代码
摘要
天气数据作为气象分析、气候研究及区域环境评估的核心数据源,其数据质量直接影响后续分析结果的可靠性。针对云南省各城市天气数据存在的格式不统一、缺失值、重复值、特征维度冗余等问题,本文设计并实现了一套系统化的天气数据预处理脚本。该脚本基于Python语言,整合Pandas、NumPy等数据处理库,涵盖数据加载、数据探查、重复值处理、日期特征工程、天气类型与风力等级标准化、温度数据清洗、缺失值填充及数据持久化等核心功能。经实际数据验证,该脚本可有效提升云南省天气数据的规范性和可用性,为后续的气象数据分析、可视化及建模工作奠定坚实基础。
关键词:云南省天气数据;数据预处理;数据清洗
一、引言
云南省地处低纬度高原地区,地形复杂,气候类型多样,其天气数据具有多维度、多格式、易缺失等特点。在气象数据应用过程中,原始采集的天气数据往往存在诸多问题:日期格式非标准化、温度数据包含冗余单位符号、天气类型与风力等级表述不统一、部分记录存在缺失或重复等。这些问题会导致后续数据分析无法有效开展,甚至产生错误的分析结论。
数据预处理是数据挖掘与分析流程中的关键环节,其核心目标是将原始、杂乱的数据转换为干净、规范、可用的结构化数据。目前,针对区域化天气数据的预处理多采用人工清洗或零散脚本处理的方式,效率低且可复用性差。为此,本文基于Python生态工具链,构建一套针对云南省各城市天气数据的自动化预处理脚本,实现数据从加载到清洗、再到持久化的全流程自动化,提升数据预处理的效率和标准化程度。
二、相关理论与技术
1. Pandas 库
Pandas 是基于 Python 语言的开源数据处理与分析工具库,是本次天气数据预处理脚本的核心支撑。Pandas 提供了 DataFrame 二维数据结构,能够高效加载、清洗、转换、统计结构化表格数据,支持数据去重、缺失值处理、格式转换、特征提取等常用预处理操作,可快速完成天气数据的批量处理。在本脚本中,Pandas 主要用于读取原始天气数据、执行数据清洗、日期格式转换、温度数值处理、特征标准化及结果保存,是实现天气数据规范化处理的核心工具。
2. NumPy 库
NumPy 是 Python 科学计算的基础库,提供高性能的数组对象与数值计算函数。在数据预处理中,NumPy 常与 Pandas 配合使用,用于处理数值型数据、缺失值标记、数据类型转换等任务。本脚本通过 NumPy 实现温度数据的异常值标记、空值统一化、数值格式标准化,提升数值计算效率,保证天气数据中气温、风力等连续型指标处理的稳定性与准确性。
3. PyMySQL与SQLAlchemy 库
PyMySQL 是 Python 连接 MySQL 数据库的驱动库,支持数据库的连接、查询、写入等基础操作;SQLAlchemy 是主流的数据库 ORM 框架,可屏蔽不同数据库语法差异,提供统一的数据读写接口。二者结合能够实现天气数据与 MySQL 数据库的无缝交互。在本预处理脚本中,PyMySQL 与 SQLAlchemy 主要用于从数据库读取原始天气数据,并将预处理后的高质量数据写入数据库,实现数据持久化存储与管理。
4. Pathlib 库
Pathlib 是 Python 内置的面向对象文件路径处理库,能够以简洁、直观的方式实现文件路径拼接、目录创建、文件存在性判断等功能,相比传统字符串路径处理更稳定、更易读。在本脚本中,Pathlib 用于统一管理数据文件读取路径、预处理结果保存路径,自动识别并创建存储目录,提升文件操作的跨平台兼容性与代码可读性,避免因路径格式错误导致脚本运行失败。
三、云南省各城市天气数据预处理
本脚本采用模块化设计思想,将数据预处理流程拆解为多个功能独立的函数,各函数职责清晰、可复用性强,整体流程为:数据加载 → 数据探查 → 重复值处理 → 日期特征工程 → 天气/风力特征标准化 → 温度数据清洗 → 缺失值填充 → 数据持久化。核心模块包括数据加载模块、数据探查模块、数据清洗模块、特征工程模块及数据持久化模块,各模块通过主函数串联,形成完整的预处理流程。
1. 数据加载模块
数据加载模块为整个预处理脚本提供数据输入支持,兼顾本地文件与数据库两种主流存储场景,设计本地CSV加载 与MySQL数据库加载 双接口,确保脚本在不同数据环境下均可稳定运行。模块通过try-except异常捕获机制,对文件不存在、数据库连接失败、数据表缺失、读取格式异常等常见错误进行精准拦截与提示,有效提升脚本的鲁棒性与容错性。CSV加载依托Pandas的read_csv方法实现本地数据快速读取,数据库加载通过SQLAlchemy构建数据库连接引擎,结合PyMySQL驱动完成MySQL数据读取,两种方式均在加载完成后输出数据行列信息,统一返回DataFrame格式结果,保证后续数据处理流程的输入格式一致,实现数据源灵活切换与稳定接入。
python
# 数据加载与初步检查
def load_data(file_path):
"""加载数据并进行初步验证"""
try:
df = pd.read_csv(file_path)
print(f"成功加载数据,共 {df.shape[0]} 行,{df.shape[1]} 列")
return df
except FileNotFoundError:
raise FileNotFoundError(f"数据文件不存在: {file_path}")
except Exception as e:
raise Exception(f"加载数据出错: {str(e)}")
def load_data_from_mysql(table_name: str):
"""从 MySQL 加载数据并进行初步验证"""
try:
# 创建数据库连接引擎
engine = create_engine(
f"mysql+pymysql://{MYSQL_CONFIG['user']}:{MYSQL_CONFIG['password']}@{MYSQL_CONFIG['host']}:{MYSQL_CONFIG['port']}/{MYSQL_CONFIG['database']}?charset=utf8mb4"
)
# 从 MySQL 读取全表数据
df = pd.read_sql_table(table_name, con=engine)
# 保持和原代码一样的打印输出
print(f"成功加载数据,共 {df.shape[0]} 行,{df.shape[1]} 列")
return df
except Exception as e:
# 表不存在 / 连接失败 统一抛出异常
if "Table" in str(e) and "doesn't exist" in str(e):
raise FileNotFoundError(f"数据表不存在: {table_name}")
else:
raise Exception(f"从 MySQL 加载数据出错: {str(e)}")2. 数据探查模块
数据探查是开展数据预处理工作的前提,用于全面掌握原始数据的结构、字段类型与数据质量,为后续清洗与标准化提供依据。本模块主要实现两项核心功能,一是通过df.info()输出字段名称、数据类型、非空数量等基础信息,快速识别缺失值与格式问题;二是对城市、昼夜天气状况、风向、风力等离散特征进行唯一值统计,明确各类文本特征的取值范围与分布情况,为后续开展标准化处理提供参考。模块在执行过程中会自动校验字段是否存在,对缺失列进行提示,提升脚本在不同数据版本下的兼容性。
python
# 检查数据基本信息
def inspect_data(df):
"""检查数据基本信息"""
print("\n=== 数据基本信息 ===")
df.info()
print("\n=== 离散特征唯一值统计 ===")
lisan_columns = [
'city', 'type_day', 'type_night',
'direction_day', 'wind_force_day', 'direction_night', 'wind_force_night'
]
for column in lisan_columns:
if column in df.columns:
unique_vals = df[column].unique()
print(f"{column}的唯一值有:{unique_vals},数量:{df[column].nunique()}")
else:
print(f"警告:列 {column} 不存在于数据中")数据探查结果如下图所示,从数据探查结果可见,本次成功加载云南省16个州市共64528条天气数据,包含城市、日期、昼夜天气类型、最高/最低气温、昼夜风向及风力共10个字段,所有字段均为object类型,其中最高气温存在2条缺失记录。离散特征统计显示,日间天气类型共33种、夜间天气类型共28种,表述繁杂且不统一;风向取值为13类,风力等级取值为15-16类,存在"微风""≤3级""1-2级"等多种同义表述,不利于后续分析。整体来看,原始数据结构完整但存在格式不规范、特征冗余、缺失值等问题,需通过后续预处理步骤完成数据清洗与标准化。

3. 重复值处理模块
重复数据会对后续的统计分析、模型构建等工作造成干扰,导致结果出现偏差,因此重复值处理是数据预处理的必要环节。本模块通过duplicated()方法统计数据集中的重复记录数量,若存在重复值,则使用drop_duplicates()方法对数据进行去重操作,保留唯一记录。模块在处理前后分别输出重复值数量,清晰展示处理效果,确保最终数据具备唯一性与准确性,为后续高质量数据分析奠定基础。
python
# 重复值处理
def handle_duplicates(df):
"""处理重复数据"""
duplicate_count = df.duplicated().sum()
print(f"\n重复值数量(处理前):{duplicate_count}")
if duplicate_count > 0:
df = df.drop_duplicates()
print(f"重复值数量(处理后):{df.duplicated().sum()}")
return df重复值处理结果如下图所示,重复值处理结果显示,在对云南省天气原始数据集进行去重处理前,数据中共存在347条重复记录。通过调用Pandas的drop_duplicates()方法完成去重操作后,所有重复记录均被成功删除,最终重复值数量降至0条。处理结果表明,原始采集数据中存在部分完全重复的无效条目,若直接用于分析将导致统计结果出现偏差。本模块有效识别并清除了冗余数据,保证了数据集中每条记录的唯一性,显著提升了数据质量,为后续的特征工程与统计分析奠定了干净、可靠的数据基础。

4. 日期特征处理模块
原始数据中的日期以中文格式的字符串形式存储,无法直接用于时间序列分析,因此需要开展日期特征工程。本模块首先通过pd.to_datetime方法将中文日期格式转换为标准的datetime类型,并对转换失败的无效日期进行统计与提示,保证数据有效性。在此基础上,从日期字段中提取年、月、日、星期、周数、年内天数等关键时间特征,丰富数据维度。同时,根据月份数值划分并生成季节特征,将气象分析中常用的季节维度加入数据集,使后续的气象规律分析、周期性研究更加便捷,提升数据的实用性与分析价值。
python
# 处理日期相关特征
def process_dates(df):
"""处理日期相关特征"""
# 日期转换
df['date'] = pd.to_datetime(df['date'], format='%Y年%m月%d日', errors='coerce')
# 检查日期转换错误
invalid_dates = df['date'].isna().sum()
if invalid_dates > 0:
print(f"警告:有 {invalid_dates} 条日期格式不正确")
# 提取日期特征
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df['weekday'] = df['date'].dt.weekday # 0-6
df['week'] = df['date'].dt.isocalendar().week
df['dayofyear'] = df['date'].dt.dayofyear
# 季节特征
def get_season(month):
if pd.isna(month):
return '未知'
if month in [3, 4, 5]:
return '春季'
elif month in [6, 7, 8]:
return '夏季'
elif month in [9, 10, 11]:
return '秋季'
else:
return '冬季'
df['season'] = df['month'].apply(get_season)
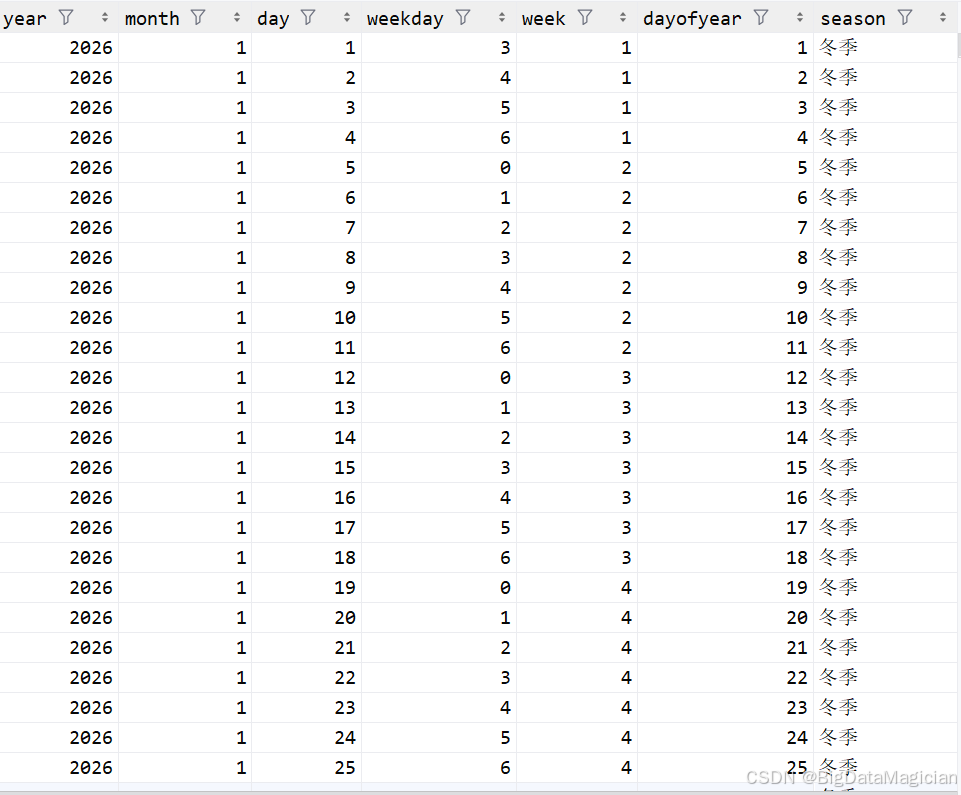
return df日期特征处理结果如下图所示,日期特征工程处理后,原始中文格式的日期字符串被成功转换为标准datetime类型,并在此基础上衍生出丰富的时间维度特征。从结果可见,数据集新增了year(年份)、month(月份)、day(日期)、weekday(星期,0-6)、week(周数)、dayofyear(年内天数)及season(季节)等字段,实现了日期数据的结构化与维度扩展。以2026年1月数据为例,1月被自动归类为冬季,星期、周数等特征清晰可辨,为后续开展时间序列分析、季节气候规律研究等提供了完备的特征支撑,显著提升了数据的分析价值与可用性。
5. 天气类型与风力等级标准化
原始采集的天气数据中,天气类型与风力等级存在表述不统一、分类过于细致的问题,不利于后续统计分析。本模块针对上述问题开展标准化处理:一方面通过构建集合存储各类天气描述,将繁杂的天气类型统一归类为晴天、多云、阴天、雨天、雪天、雾天、未知七大类,采用矢量化函数实现高效转换;另一方面通过建立风力等级映射字典,将多种不规则的风力描述统一规范为1-3级、3-4级、4-5级、5-6级、6-7级、未知六类,利用映射匹配方式完成快速替换。经过处理后,数据特征更加简洁规范、分布更加清晰,有效提升了天气数据的可用性与分析效率。
python
# 简化天气类型
def simplify_weather_types(df):
"""简化天气类型"""
# 使用集合提高查询效率
rain_set = {'毛毛雨', '细雨', '小雨', '阵雨', '雨夹雪', '雷雨', '雷阵雨', '中雨', '大雨', '冻雨', '零散阵雨',
'小到中雨', '中到大雨', '大到暴雨', '暴雨', '暴雨到大暴雨', '大暴雨', '小雨-中雨', '零散雷雨',
'大到暴雨', '小雨-中雨', '中雨-大雨', '雷阵雨伴有冰雹'}
snow_set = {'小雪', '中雪', '阵雪', '小到中雪', '中到大雪', '零散阵雪'}
# 表示完全被云覆盖,阳光很少或没有的状态
overcast_set = {'阴', '阴天'}
# 表示有较多云层,但阳光仍可见的状态
cloudy_set = {'多云', '局部多云'}
sunny_set = {'晴', '少云'}
fog_set = {'雾'}
def simple_weather_type(weather_type):
if pd.isna(weather_type):
return '未知'
elif weather_type in rain_set:
return '雨天'
elif weather_type in snow_set:
return '雪天'
elif weather_type in overcast_set:
return '阴天'
elif weather_type in cloudy_set:
return '多云'
elif weather_type in sunny_set:
return '晴天'
elif weather_type in fog_set:
return '雾天'
else:
return '其他'
# 使用矢量化操作提高效率
df['type_day'] = df['type_day'].apply(simple_weather_type)
df['type_night'] = df['type_night'].apply(simple_weather_type)
return df
# 简化风力等级
def simplify_wind_force(df):
"""简化风力等级"""
force_map = {
'1-2级': '1-3级',
'2': '1-3级',
'微风': '1-3级',
'微风级': '1-3级',
'≤3级': '1-3级',
'<3级': '1-3级',
'1-3级': '1-3级',
'3': '3-4级',
'4': '3-4级',
'3-4级级': '3-4级',
'3~4级': '3-4级',
'3-4级': '3-4级',
'4~5级': '4-5级',
'4-5级': '4-5级',
'5': '5-6级',
'5-6级': '5-6级',
'6-7级': '6-7级'
}
# 使用map方法更高效
df['wind_force_day'] = df['wind_force_day'].map(force_map).fillna('未知')
df['wind_force_night'] = df['wind_force_night'].map(force_map).fillna('未知')
return df6. 温度数据清洗与缺失值填充
温度是气象分析中的核心数值指标,原始数据存在单位符号、格式不统一及缺失值等问题,需进行专项清洗处理。本模块分为两步实现:首先通过格式清洗函数移除温度中的"℃"符号,将字符串类型的温度值转换为标准整型数值,对无法转换的异常数据统一标记为缺失值,保证数据类型规范;其次采用按城市分组的均值填充策略,充分考虑云南省不同城市气候差异较大的特点,避免全局均值填充带来的误差,同时在填充前后输出缺失值统计信息,直观展示数据修复效果,确保温度数据完整、准确、可用。
python
# 清洗温度数据格式
def clean_temperature_format(df):
"""
第一步:清洗温度数据格式
去掉℃符号,统一转为整数类型,不处理缺失值
"""
def clean_unit(temperature):
if pd.isna(temperature):
return np.nan
try:
return int(str(temperature).replace('℃', ''))
except (ValueError, TypeError):
return np.nan
# 清洗最高温、最低温格式
df['max_temperature'] = df['max_temperature'].apply(clean_unit)
df['min_temperature'] = df['min_temperature'].apply(clean_unit)
return df
# 处理缺失值
def handle_missing_values(df):
"""
第二步:用【同一城市】的平均温度填充缺失值
先打印缺失情况 → 填充 → 再打印结果
"""
# 查看处理前缺失值
print("\n缺失值情况(填充前):")
print(df.isnull().sum())
# 核心:按【城市】分组,用每组的平均值填充缺失值
df['max_temperature'] = df.groupby('city')['max_temperature'].transform(lambda x: x.fillna(x.mean())).astype(int)
# df['min_temperature'] = df.groupby('city')['min_temperature'].transform(lambda x: x.fillna(x.mean()))
# 查看处理后缺失值
print("温度缺失值情况(填充后):")
print(df.isnull().sum())
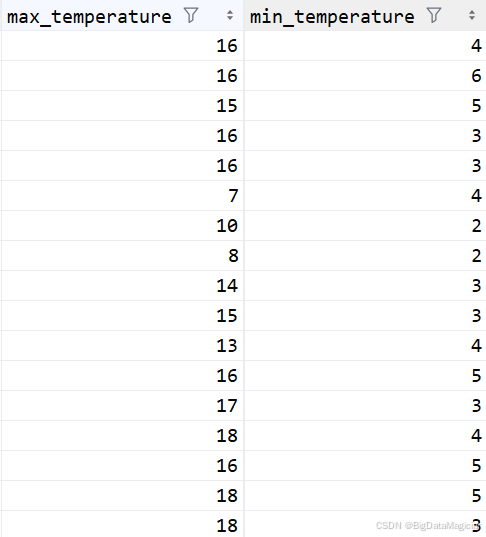
return df温度数据清洗结果如下图所示,经温度数据清洗与缺失值填充后,原始带"℃"单位的字符串温度被成功转换为纯整数数值类型,缺失的最高气温记录也通过按城市分组均值的方式完成填充。从处理结果可见,max_temperature与min_temperature字段均为规范的整型数值,无单位符号、格式混乱或缺失值问题,数据格式统一、数值清晰,可直接用于后续气温统计分析、趋势建模等工作,有效提升了温度数据的可用性与分析效率。
7. 数据持久化模块
数据持久化是数据预处理流程的最终环节,用于将清洗完成后的高质量数据进行稳定存储,便于后续分析与调用。本模块支持本地CSV文件与MySQL数据库两种保存方式,能够满足不同场景下的数据管理需求。在本地保存时,通过Pathlib库规范文件路径,采用UTF-8-SIG编码确保中文正常显示,避免索引列冗余输出;在数据库存储时,先自动检测并创建目标数据库,保证存储环境有效,再通过SQLAlchemy引擎将数据批量写入MySQL,使用replace模式避免数据重复,配合分块写入机制提升大批量数据的存储效率,最终实现预处理后天气数据的安全、规范、高效保存。
python
# 保存数据到CSV
def save_to_csv(data: DataFrame, save_dir: str, filename: str) -> None:
"""保存数据到CSV文件"""
save_path = Path(save_dir) / filename
data.to_csv(save_path, index=False, encoding='utf-8-sig')
print(f"\n清洗后的数据已保存至:{save_path}")
# 如果数据库不存在就创建
def create_database_if_not_exists() -> None:
"""如果数据库不存在,则创建数据库"""
config = MYSQL_CONFIG
# 先不指定库,连接 MySQL server
conn = pymysql.connect(
host=config["host"],
port=config["port"],
user=config["user"],
password=config["password"],
charset="utf8mb4"
)
try:
with conn.cursor() as cursor:
# 创建数据库,不存在则创建
cursor.execute(f"CREATE DATABASE IF NOT EXISTS {config['database']} DEFAULT CHARACTER SET utf8mb4")
conn.commit()
finally:
conn.close()
def save_to_mysql(data: DataFrame, table: str) -> None:
# 创建 MySQL 连接引擎
engine = create_engine(
f"mysql+pymysql://{MYSQL_CONFIG['user']}:{MYSQL_CONFIG['password']}@{MYSQL_CONFIG['host']}:{MYSQL_CONFIG['port']}/{MYSQL_CONFIG['database']}?charset=utf8mb4"
)
# 写入 MySQ
data.to_sql(name=table, con=engine, if_exists="replace", index=False, chunksize=1000)
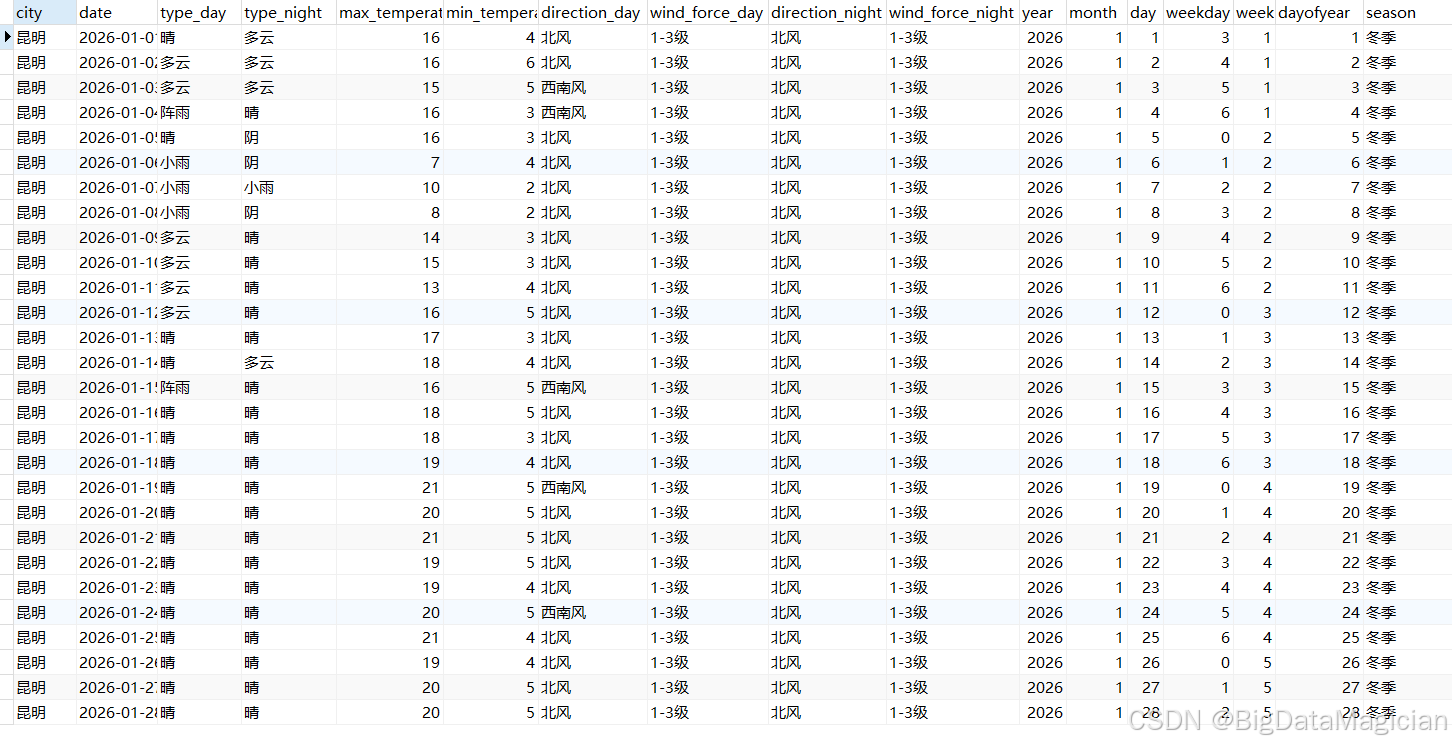
print(f"\n清洗后的数据已保存至:{MYSQL_CONFIG['database']}.{table} 表")持久化保存后的数据如下图所示,经完整预处理流程后,云南省各城市天气数据已实现规范化与结构化。从持久化保存的结果表可见,数据包含原始天气特征与新增时间维度特征共17个字段,其中城市、日期、标准化后的昼夜天气类型与风力等级、清洗后的温度数据格式统一、无缺失与冗余;新增的年、月、日、星期、周数、年内天数及季节等时间特征,为后续气象时序分析、季节气候规律挖掘提供了丰富维度。整体数据干净规范、结构完整,可直接用于可视化、建模分析等后续工作,充分体现了预处理脚本的有效性与实用价值。
四、完整代码
python
from pathlib import Path
import numpy as np
import pandas as pd
import pymysql
from matplotlib import pyplot as plt
from pandas import DataFrame
from sqlalchemy import create_engine
# 配置 MySQL 连接信息
MYSQL_CONFIG = {
"host": "127.0.0.1",
"port": 3306,
"user": "root",
"password": "zxcvbq",
"database": "weather"
}
# Pandas环境配置
def setup_environment():
"""配置绘图和Pandas环境"""
# 设置中文正常显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'WenQuanYi Micro Hei', 'Heiti TC']
plt.rcParams['axes.unicode_minus'] = False
# 设置Pandas全局选项
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 50)
pd.set_option('display.expand_frame_repr', False)
# 数据加载与初步检查
def load_data(file_path):
"""加载数据并进行初步验证"""
try:
df = pd.read_csv(file_path)
print(f"成功加载数据,共 {df.shape[0]} 行,{df.shape[1]} 列")
return df
except FileNotFoundError:
raise FileNotFoundError(f"数据文件不存在: {file_path}")
except Exception as e:
raise Exception(f"加载数据出错: {str(e)}")
def load_data_from_mysql(table_name: str):
"""从 MySQL 加载数据并进行初步验证"""
try:
# 创建数据库连接引擎
engine = create_engine(
f"mysql+pymysql://{MYSQL_CONFIG['user']}:{MYSQL_CONFIG['password']}@{MYSQL_CONFIG['host']}:{MYSQL_CONFIG['port']}/{MYSQL_CONFIG['database']}?charset=utf8mb4"
)
# 从 MySQL 读取全表数据
df = pd.read_sql_table(table_name, con=engine)
# 保持和原代码一样的打印输出
print(f"成功加载数据,共 {df.shape[0]} 行,{df.shape[1]} 列")
return df
except Exception as e:
# 表不存在 / 连接失败 统一抛出异常
if "Table" in str(e) and "doesn't exist" in str(e):
raise FileNotFoundError(f"数据表不存在: {table_name}")
else:
raise Exception(f"从 MySQL 加载数据出错: {str(e)}")
# 检查数据基本信息
def inspect_data(df):
"""检查数据基本信息"""
print("\n=== 数据基本信息 ===")
df.info()
print("\n=== 离散特征唯一值统计 ===")
lisan_columns = [
'city', 'type_day', 'type_night',
'direction_day', 'wind_force_day', 'direction_night', 'wind_force_night'
]
for column in lisan_columns:
if column in df.columns:
unique_vals = df[column].unique()
print(f"{column}的唯一值有:{unique_vals},数量:{df[column].nunique()}")
else:
print(f"警告:列 {column} 不存在于数据中")
# 重复值处理
def handle_duplicates(df):
"""处理重复数据"""
duplicate_count = df.duplicated().sum()
print(f"\n重复值数量(处理前):{duplicate_count}")
if duplicate_count > 0:
df = df.drop_duplicates()
print(f"重复值数量(处理后):{df.duplicated().sum()}")
return df
# 处理日期相关特征
def process_dates(df):
"""处理日期相关特征"""
# 日期转换
df['date'] = pd.to_datetime(df['date'], format='%Y年%m月%d日', errors='coerce')
# 检查日期转换错误
invalid_dates = df['date'].isna().sum()
if invalid_dates > 0:
print(f"警告:有 {invalid_dates} 条日期格式不正确")
# 提取日期特征
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df['weekday'] = df['date'].dt.weekday # 0-6
df['week'] = df['date'].dt.isocalendar().week
df['dayofyear'] = df['date'].dt.dayofyear
# 季节特征
def get_season(month):
if pd.isna(month):
return '未知'
if month in [3, 4, 5]:
return '春季'
elif month in [6, 7, 8]:
return '夏季'
elif month in [9, 10, 11]:
return '秋季'
else:
return '冬季'
df['season'] = df['month'].apply(get_season)
return df
# 简化天气类型
def simplify_weather_types(df):
"""简化天气类型"""
# 使用集合提高查询效率
rain_set = {'毛毛雨', '细雨', '小雨', '阵雨', '雨夹雪', '雷雨', '雷阵雨', '中雨', '大雨', '冻雨', '零散阵雨',
'小到中雨', '中到大雨', '大到暴雨', '暴雨', '暴雨到大暴雨', '大暴雨', '小雨-中雨', '零散雷雨',
'大到暴雨', '小雨-中雨', '中雨-大雨', '雷阵雨伴有冰雹'}
snow_set = {'小雪', '中雪', '阵雪', '小到中雪', '中到大雪', '零散阵雪'}
# 表示完全被云覆盖,阳光很少或没有的状态
overcast_set = {'阴', '阴天'}
# 表示有较多云层,但阳光仍可见的状态
cloudy_set = {'多云', '局部多云'}
sunny_set = {'晴', '少云'}
fog_set = {'雾'}
def simple_weather_type(weather_type):
if pd.isna(weather_type):
return '未知'
elif weather_type in rain_set:
return '雨天'
elif weather_type in snow_set:
return '雪天'
elif weather_type in overcast_set:
return '阴天'
elif weather_type in cloudy_set:
return '多云'
elif weather_type in sunny_set:
return '晴天'
elif weather_type in fog_set:
return '雾天'
else:
return '其他'
# 使用矢量化操作提高效率
df['type_day'] = df['type_day'].apply(simple_weather_type)
df['type_night'] = df['type_night'].apply(simple_weather_type)
return df
# 简化风力等级
def simplify_wind_force(df):
"""简化风力等级"""
force_map = {
'1-2级': '1-3级',
'2': '1-3级',
'微风': '1-3级',
'微风级': '1-3级',
'≤3级': '1-3级',
'<3级': '1-3级',
'1-3级': '1-3级',
'3': '3-4级',
'4': '3-4级',
'3-4级级': '3-4级',
'3~4级': '3-4级',
'3-4级': '3-4级',
'4~5级': '4-5级',
'4-5级': '4-5级',
'5': '5-6级',
'5-6级': '5-6级',
'6-7级': '6-7级'
}
# 使用map方法更高效
df['wind_force_day'] = df['wind_force_day'].map(force_map).fillna('未知')
df['wind_force_night'] = df['wind_force_night'].map(force_map).fillna('未知')
return df
# 清洗温度数据格式
def clean_temperature_format(df):
"""
第一步:清洗温度数据格式
去掉℃符号,统一转为整数类型,不处理缺失值
"""
def clean_unit(temperature):
if pd.isna(temperature):
return np.nan
try:
return int(str(temperature).replace('℃', ''))
except (ValueError, TypeError):
return np.nan
# 清洗最高温、最低温格式
df['max_temperature'] = df['max_temperature'].apply(clean_unit)
df['min_temperature'] = df['min_temperature'].apply(clean_unit)
return df
# 处理缺失值
def handle_missing_values(df):
"""
第二步:用【同一城市】的平均温度填充缺失值
先打印缺失情况 → 填充 → 再打印结果
"""
# 查看处理前缺失值
print("\n缺失值情况(填充前):")
print(df.isnull().sum())
# 核心:按【城市】分组,用每组的平均值填充缺失值
df['max_temperature'] = df.groupby('city')['max_temperature'].transform(lambda x: x.fillna(x.mean())).astype(int)
# df['min_temperature'] = df.groupby('city')['min_temperature'].transform(lambda x: x.fillna(x.mean()))
# 查看处理后缺失值
print("温度缺失值情况(填充后):")
print(df.isnull().sum())
return df
# 保存数据到CSV
def save_to_csv(data: DataFrame, save_dir: str, filename: str) -> None:
"""保存数据到CSV文件"""
save_path = Path(save_dir) / filename
data.to_csv(save_path, index=False, encoding='utf-8-sig')
print(f"\n清洗后的数据已保存至:{save_path}")
# 如果数据库不存在就创建
def create_database_if_not_exists() -> None:
"""如果数据库不存在,则创建数据库"""
config = MYSQL_CONFIG
# 先不指定库,连接 MySQL server
conn = pymysql.connect(
host=config["host"],
port=config["port"],
user=config["user"],
password=config["password"],
charset="utf8mb4"
)
try:
with conn.cursor() as cursor:
# 创建数据库,不存在则创建
cursor.execute(f"CREATE DATABASE IF NOT EXISTS {config['database']} DEFAULT CHARACTER SET utf8mb4")
conn.commit()
finally:
conn.close()
def save_to_mysql(data: DataFrame, table: str) -> None:
# 创建 MySQL 连接引擎
engine = create_engine(
f"mysql+pymysql://{MYSQL_CONFIG['user']}:{MYSQL_CONFIG['password']}@{MYSQL_CONFIG['host']}:{MYSQL_CONFIG['port']}/{MYSQL_CONFIG['database']}?charset=utf8mb4"
)
# 写入 MySQ
data.to_sql(name=table, con=engine, if_exists="replace", index=False, chunksize=1000)
print(f"\n清洗后的数据已保存至:{MYSQL_CONFIG['database']}.{table} 表")
# 主函数
def main():
# 环境设置
setup_environment()
# 加载数据
df = load_data('./data/云南天气数据.csv')
# df = load_data_from_mysql('yunnan_weather')
# 数据检查
inspect_data(df)
# 数据清洗流程
df = handle_duplicates(df)
df = process_dates(df)
# df = simplify_weather_types(df)
# df = simplify_wind_force(df)
df = clean_temperature_format(df)
df = handle_missing_values(df)
# 保存清洗后的数据
save_to_csv(df, './data', '云南天气数据_清洗后.csv')
# save_to_mysql(df, 'yunnan_weather_cleaned')
if __name__ == "__main__":
main()