文章目录
- [🧠 JVM 内存管理与垃圾回收(GC)深度解析](#🧠 JVM 内存管理与垃圾回收(GC)深度解析)
-
- [一、JVM 运行时内存分配](#一、JVM 运行时内存分配)
- 二、类加载机制
-
- [2.1 类加载的五个阶段](#2.1 类加载的五个阶段)
- [2.2 何时会触发类加载?](#2.2 何时会触发类加载?)
- [2.3 双亲委派模型](#2.3 双亲委派模型)
- 三、垃圾回收(GC)
-
- [3.1 找出垃圾:如何判断对象已死?](#3.1 找出垃圾:如何判断对象已死?)
-
- [方案一:引用计数法(Python、PHP 采用)](#方案一:引用计数法(Python、PHP 采用))
- [方案二:可达性分析(Java 采用)](#方案二:可达性分析(Java 采用))
- [3.2 Stop The World(STW)深度解析](#3.2 Stop The World(STW)深度解析)
-
- [3.2.1 为什么必须暂停?------ 两个核心场景](#3.2.1 为什么必须暂停?—— 两个核心场景)
- [3.2.2 扫地嗑瓜子比喻](#3.2.2 扫地嗑瓜子比喻)
- [3.2.3 STW 的影响范围](#3.2.3 STW 的影响范围)
- [3.2.4 为什么 C/C++ 不引入 GC?](#3.2.4 为什么 C/C++ 不引入 GC?)
- [3.3 清理垃圾:回收算法](#3.3 清理垃圾:回收算法)
-
- [3.3.1 标记-清除算法(Mark-Sweep)](#3.3.1 标记-清除算法(Mark-Sweep))
- [3.3.2 复制算法(Copying)](#3.3.2 复制算法(Copying))
- [3.3.3 标记-整理算法(Mark-Compact)](#3.3.3 标记-整理算法(Mark-Compact))
- [3.3.4 三种算法对比总结](#3.3.4 三种算法对比总结)
- [3.4 分代回收(Generational Collection)](#3.4 分代回收(Generational Collection))
-
- 为什么分代?
- [新生代回收流程(Minor GC)](#新生代回收流程(Minor GC))
- [老年代回收流程(Major GC / Full GC)](#老年代回收流程(Major GC / Full GC))
- 大对象直接进入老年代
- 四、总结
- [五、常见 JVM 面试题(附回答要点)](#五、常见 JVM 面试题(附回答要点))
-
- [1. JVM 的内存区域有哪些?各自的作用是什么?](#1. JVM 的内存区域有哪些?各自的作用是什么?)
- [2. 类加载的过程是怎样的?双亲委派模型是什么?为什么要这样设计?](#2. 类加载的过程是怎样的?双亲委派模型是什么?为什么要这样设计?)
- [3. 垃圾回收中,如何判断一个对象是"垃圾"?有哪些 GC Roots?](#3. 垃圾回收中,如何判断一个对象是“垃圾”?有哪些 GC Roots?)
- [4. 简述垃圾回收的三种基础算法(标记-清除、复制、标记-整理)及其优缺点。](#4. 简述垃圾回收的三种基础算法(标记-清除、复制、标记-整理)及其优缺点。)
- [5. 什么是 Stop The World?为什么 GC 需要 STW?如何减少 STW 的影响?](#5. 什么是 Stop The World?为什么 GC 需要 STW?如何减少 STW 的影响?)
🧠 JVM 内存管理与垃圾回收(GC)深度解析
本文是我在学习 JVM 过程中的笔记总结,结合了《深入理解 Java 虚拟机》及实际面试经验,用大量生活中的例子帮你彻底搞懂 JVM 的内存分区、类加载机制和垃圾回收原理。
一、JVM 运行时内存分配
当我们在操作系统中启动一个 Java 程序时,JVM 会向操作系统申请一大块内存,然后按照自己的规范将这些内存划分为几个不同的区域。每个区域都有特定的职责,共同支撑程序的运行。
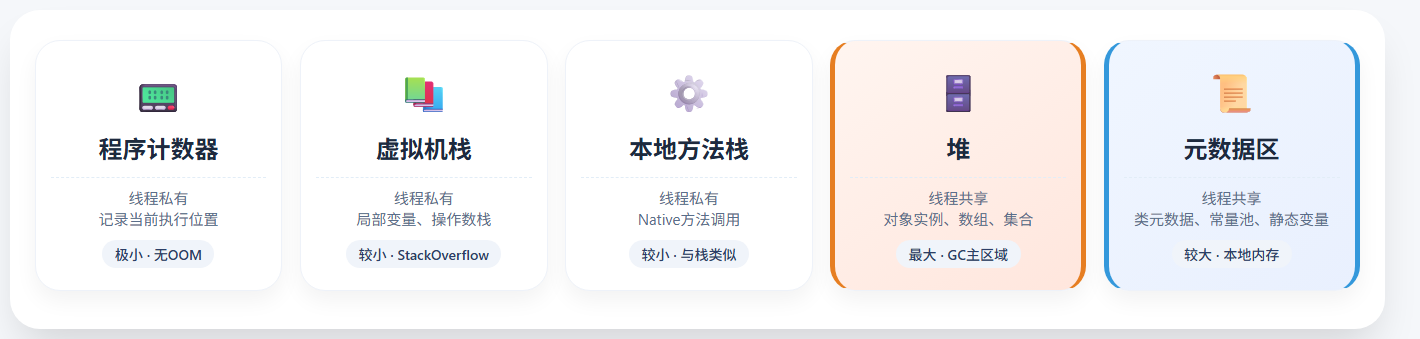
| 内存区域 | 线程共享 | 主要存储内容 | 特点 |
|---|---|---|---|
| 程序计数器 | 私有 | 当前线程执行的字节码指令地址 | 线程切换后能恢复执行位置,唯一不会 OOM 的区域 |
| 本地方法栈 | 私有 | 为 native 方法(JNI 调用)提供服务,存储本地方法调用信息 |
由底层操作系统或 C 库管理 |
| 虚拟机栈 | 私有 | 存储栈帧,每个栈帧对应一个方法调用,包含局部变量表、操作数栈、方法出口等 | 方法调用时入栈,结束时出栈;递归过深可能 StackOverflowError |
| 堆 | 共享 | 所有 new 出来的对象、数组、集合实例 |
GC 的主要区域,内存最大,可动态扩展 |
| 元数据区 | 共享 | 类的元数据(类信息、字段信息、方法信息、常量池、静态变量等) | Java 8 后用本地内存实现,避免 PermGen 内存溢出 |
💡 提示 :程序计数器、虚拟机栈、本地方法栈都是线程私有 的,而堆和元数据区是线程共享的。
二、类加载机制
2.1 类加载的五个阶段
当 Java 程序第一次使用某个类时,JVM 会触发类加载,将 .class 文件中的二进制数据读入内存,并经过以下五个阶段:
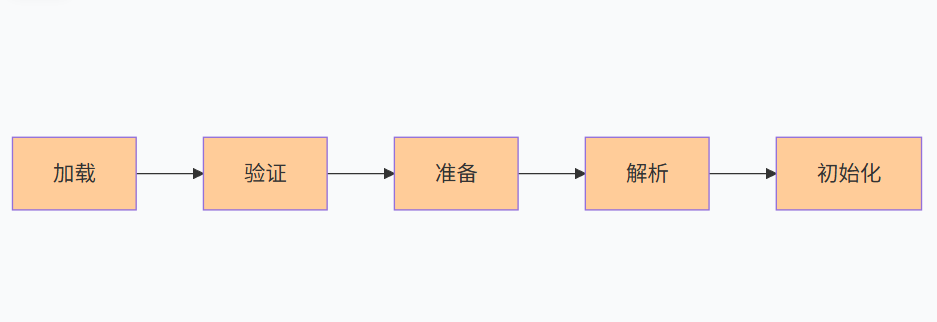
-
加载
根据类的全限定名(如
java.lang.String)查找并读取字节码文件(.class)。加载过程中,类加载器会先委托父类加载器去加载,只有父类加载器找不到时,才由自己加载------这就是"双亲委派模型"。
-
验证
检查字节码文件是否符合 JVM 规范,防止恶意代码或格式错误。包括文件格式、元数据、字节码、符号引用等验证。
-
准备
为 静态成员变量 分配内存(在元数据区/方法区),并赋予默认零值(如
int→0,boolean→false,引用 →null)。
注意:此时还没有执行静态变量的显式赋值。 -
解析
将常量池中的 符号引用 (如类名、方法名、字段名、字符串常量)替换为 直接引用(内存地址或偏移量)。这一步使后续的方法调用可以直接通过地址执行。
-
初始化
按照代码编写的顺序,从上到下执行 静态变量 的显式赋值和 静态代码块。这是类加载的最后一步,之后类就可以被正常使用了。
2.2 何时会触发类加载?
类加载遵循"懒加载 "原则,只有在 首次主动使用 一个类时才会触发:
new创建对象- 调用静态方法
- 访问静态字段(不是
final编译时常量) - 初始化子类时会先初始化父类
- 反射调用(
Class.forName) - 作为启动类(
main方法所在类)
2.3 双亲委派模型
双亲委派模型出现在类加载的 加载 阶段,它规定了类加载器的优先级和协作方式。
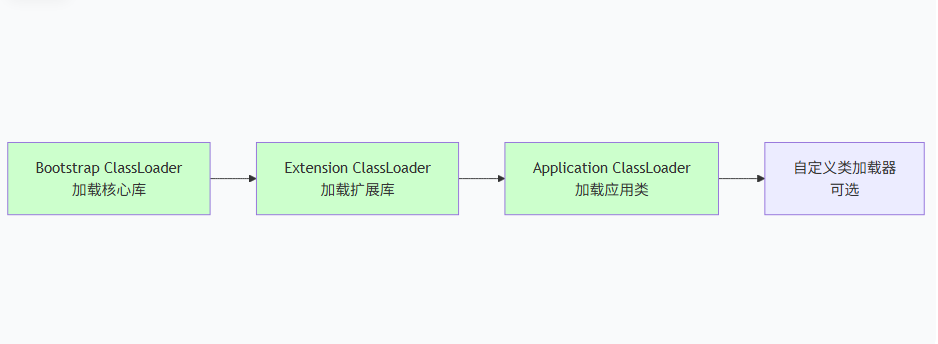
工作流程 :
当一个类加载器收到加载请求时,它首先将请求委派给父加载器,父加载器再继续向上委派,直到最顶层的 Bootstrap 加载器。如果父加载器无法加载(在它的搜索路径中找不到该类),才由当前加载器自己尝试加载。
为什么要这样设计?
- 保证核心类库的唯一性 :像
java.lang.String必须由启动类加载器加载,防止用户自定义的同名类被误加载,从而破坏 Java 标准库的安全。 举个例子:如果先从自己找,你可以在项目里写一个java.lang.String类,然后系统就可能误加载你这个假的String,导致程序运行异常甚至出现安全漏洞。双亲委派先向上找,确保核心类永远由最顶层的启动类加载器加载。 - 避免重复加载:同一个类如果被不同加载器加载,在 JVM 中会被视为两个不同的类型,会导致类型转换异常。双亲委派确保每个类尽量由上层加载器加载,避免重复。
- 沙箱安全:用户自定义的恶意类无法冒充核心类,因为父加载器会优先加载真正的核心类。
📌 一句话总结 :双亲委派 先向上委托,再自己加载 ,是为了保护 Java 标准库的权威性和唯一性。
如果两个类有同一个父类,父类只需要被加载一次,子类加载时不会重新加载父类,这也是双亲委派带来的好处。
三、垃圾回收(GC)
Java 的自动内存管理(GC)主要针对 堆内存 。与 C/C++ 需要手动 malloc/free 不同,Java 通过后台线程定期"打扫"不再使用的对象,极大地减少了程序员的内存管理负担。
下面我们从"如何找出垃圾"和"如何清理垃圾"两个角度来深入理解 GC。
3.1 找出垃圾:如何判断对象已死?
方案一:引用计数法(Python、PHP 采用)
给每个对象附加一个计数器,记录指向它的引用个数。当新引用指向对象时,计数+1;当引用失效时,计数-1;当计数为 0 时,对象即可回收。
缺点:
-
额外内存开销:每个对象需要额外空间存储计数器。假设一个对象本身只有 2 个字节,加上 2 字节的计数器,内存占用翻倍,浪费严重。虽然大对象多 2 字节无所谓,但小对象数量众多,累积开销可观。
-
循环引用问题:看下面这段代码:
javaclass Test { Test t; } Test a = new Test(); Test b = new Test(); a.t = b; b.t = a; a = null; b = null;虽然
a和b都置为 null,但它们内部互相引用,各自引用计数都不为 0,导致这两个对象永远无法被回收,造成内存泄漏。虽然 Python 和 PHP 通过额外引入"环路检测"机制解决了这个问题,但增加了复杂度。
正是因为这两个缺陷,Java 没有采用引用计数法。
方案二:可达性分析(Java 采用)
核心思想 :以一组称为 GC Roots 的根对象为起点,通过引用链向下遍历对象图。能够被遍历到的对象为 存活 ,否则即为 垃圾,可被回收。
图中绿色为存活对象(从 GC Roots 可达),红色为垃圾(不可达)。
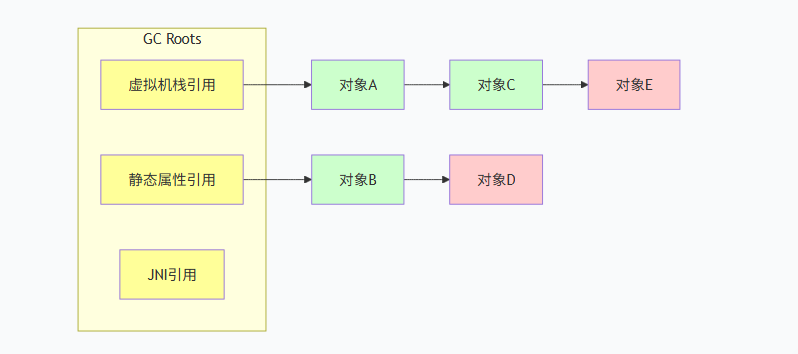
GC Roots 包括哪些对象?
- 虚拟机栈(栈帧中的局部变量)中引用的对象
- 元数据区 中静态属性引用的对象(
static字段) - 元数据区 中常量池引用的对象(如字符串常量、
final static静态常量) - 本地方法栈中 JNI 引用的对象
- 活动线程(Thread)对象本身
记忆口诀:栈上在用的、静态的、常量的,都是 GC 根节点 。
注: 一个进程有多个栈,一个栈有多个栈帧,一个栈帧里有多个局部变量
优点:
- 彻底解决了循环引用问题(即使对象互相引用,只要没有外部 GC Roots 引用,仍会被回收)
- 不需要为每个对象额外分配计数器
缺点:
- 需要遍历整个对象图,耗时较长
- 分析过程中必须 停止所有用户线程(Stop The World,STW),否则业务线程的修改会干扰标记结果。
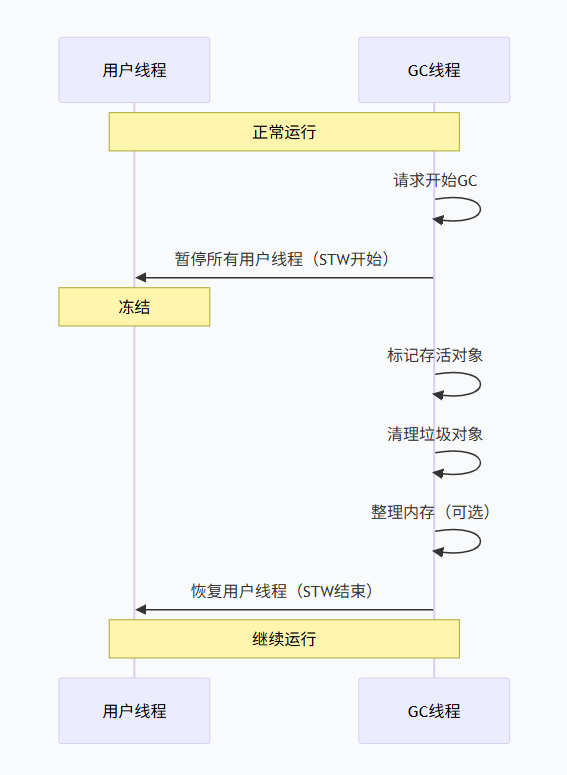
3.2 Stop The World(STW)深度解析
STW 是指 GC 过程中 暂停所有用户线程,仅允许 GC 线程运行的机制。为什么必须暂停?因为可达性分析需要对象引用关系在一瞬间静止,否则就像一边扫地一边有人扔瓜子壳,永远扫不干净。
3.2.1 为什么必须暂停?------ 两个核心场景
假设 GC 线程正在做可达性分析,从 GC Roots 开始标记存活对象。如果没有暂停用户线程,就会出现两种典型问题:
场景一:引用被修改 → 产生"浮动垃圾"
标记过程中,一个对象原本被栈上的变量引用(可达),但业务线程突然将这个引用改成了 null,使该对象变为不可达。然而 GC 线程可能在此之前已经标记它为"存活",于是这个对象虽然已经是垃圾,却不会被本次 GC 回收,只能等到下一次 GC 才能清理。这种对象称为"浮动垃圾"。
后果:不会导致程序错误,只是内存暂未释放,影响不大。
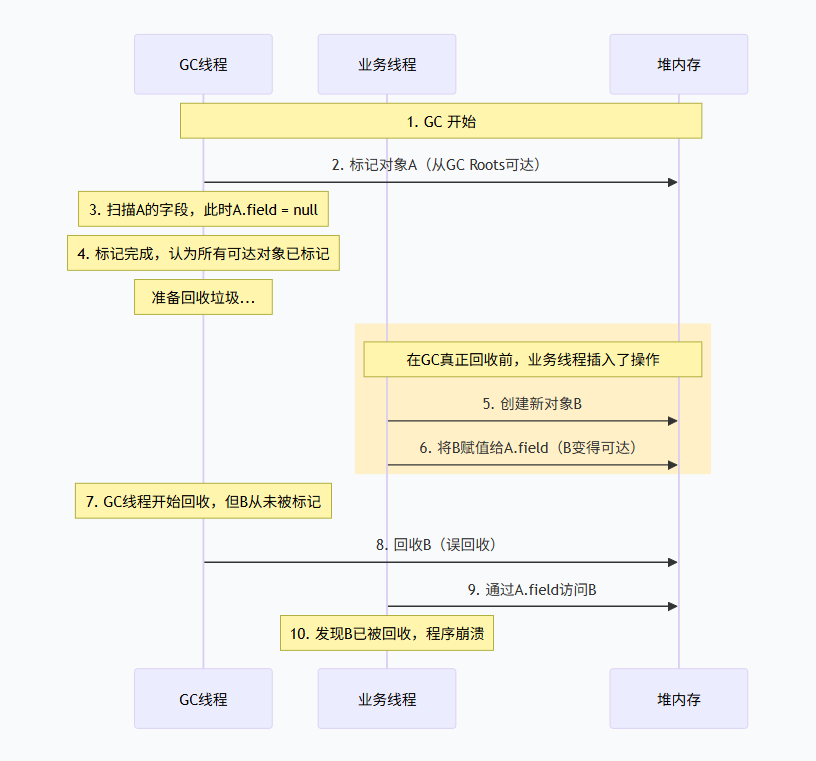
场景二:新对象被创建 → 误回收(致命错误)
在 GC 线程进行可达性分析的过程中,业务线程创建了一个新对象,并将其赋值给某个已经标记过的对象的字段(使新对象变得可达)。然而,由于 GC 线程可能尚未遍历该对象的字段(或者已经完成该字段的扫描),这个新对象就不会被标记,从而被误判为垃圾,并在后续清理阶段被回收。
后果
当业务线程随后通过该字段访问这个新对象时,会发现对象已被回收,导致程序崩溃(如空指针异常)或数据错乱。这是一个致命的系统错误,可能引发线上故障。
3.2.2 扫地嗑瓜子比喻
你正在打扫房间(GC 线程),有一个朋友在嗑瓜子(业务线程),瓜子壳不停地掉在地上。如果你一边扫,他一边扔,你永远无法彻底清理干净。
STW 的做法 :
你让朋友先停下来,你把房间彻底打扫干净,包括之前掉落的和现在存在的所有垃圾,然后再让他继续嗑瓜子。虽然会耽误他一会儿,但房间干净了。
如果不暂停 :
你一边扫,他一边扔,你永远不知道哪些是旧垃圾,哪些是新垃圾。最终可能导致漏扫(垃圾残留)或者误扫(把朋友还没吃完的瓜子也扫走了,相当于误杀了正在使用的对象)。
3.2.3 STW 的影响范围
很多人以为 STW 只发生在"标记"阶段,实际上 从 GC 开始,到标记、清理、内存整理全部结束,用户线程才恢复。整个过程业务线程都处于阻塞状态。
- 标记阶段:需要暂停,保证引用关系不变。
- 清理阶段:如果使用标记-清除算法,清理时也需要暂停,避免业务线程同时访问被回收的内存。
- 内存整理阶段:如果使用标记-整理算法,移动对象时需要更新所有引用,也必须暂停,否则引用指向错误地址。
所以,STW 的时间 = 标记时间 + 清理时间 + 整理时间。这个时间直接影响程序的"卡顿"程度。
3.2.4 为什么 C/C++ 不引入 GC?
- GC 需要周期性地遍历对象图,占用 CPU 资源,带来性能损耗。
- STW 会导致程序停顿,不适用于对实时性要求高的场景(如高频交易、游戏引擎)。
- C/C++ 追求极致性能和对底层资源的绝对控制,开发者愿意自己管理内存,以换取更高的运行效率。
3.3 清理垃圾:回收算法
找到垃圾后,就需要将其占用的内存释放出来。常用的三种基础算法各有优劣,Java 并没有单一使用某一种,而是结合了 分代回收 的思想,根据不同区域的特性采用不同的策略。
3.3.1 标记-清除算法(Mark-Sweep)
工作原理:
- 标记阶段:从 GC Roots 出发,遍历所有可达对象,并打上标记(mark)。
- 清除阶段:遍历堆内存,回收所有未被标记的对象,释放其占用的空间。

优点:
- 实现简单,不需要移动对象。
- 适用于存活对象较多的场景(如老年代)。
缺点:
- 内存碎片:清除后内存空间不连续,形成大量碎片。当需要分配一个大对象时,即使总空闲内存足够,也可能因为没有连续空间而触发另一次 GC。
3.3.2 复制算法(Copying)
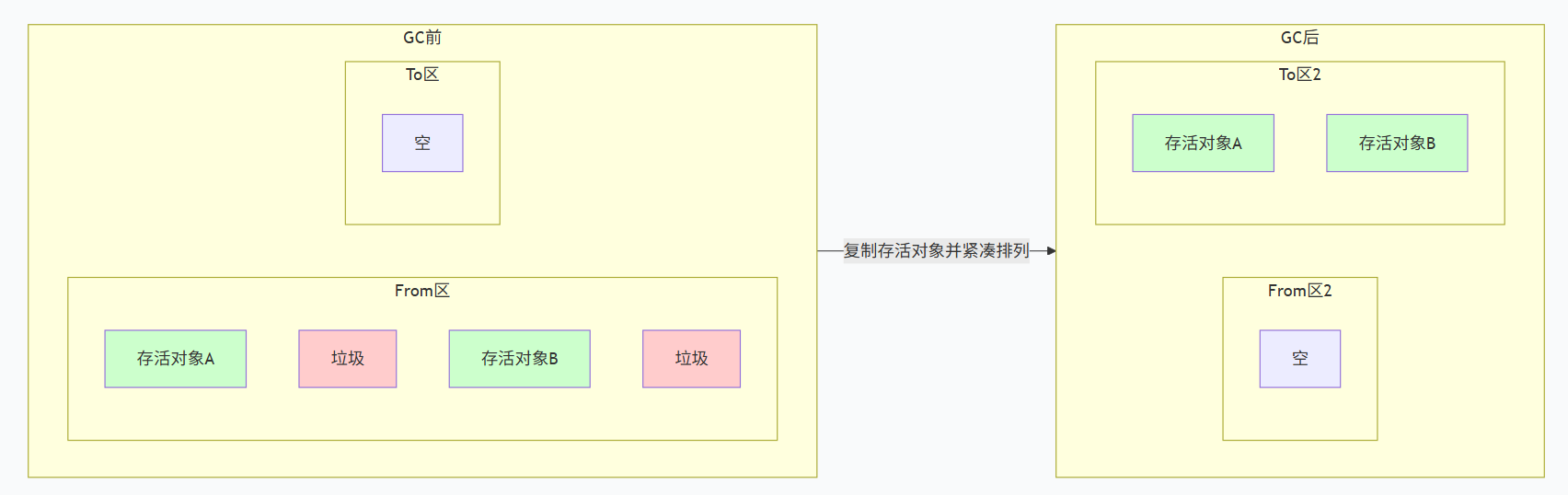
工作原理:
- 将内存划分为大小相等的两块(如 From 区和 To 区),每次只使用其中一块(From 区)。
- GC 时,将 From 区中存活的对象复制到 To 区,并按照内存地址顺序排列。
- 复制完成后,清空整个 From 区,然后交换两块区域的角色(原来的 To 区变成新的 From 区)。
优点:
- 无碎片:存活对象被紧凑排列,内存利用率高,分配速度快(只需移动指针)。
- 效率高:只处理存活对象,对于存活率低的场景非常高效。
缺点:
- 空间浪费:始终有一半内存处于闲置状态(To 区在 GC 期间为空)。
- 复制成本:当存活对象较多时,复制开销大。
适用场景:新生代。因为新生代对象朝生暮死,每次 GC 存活的对象很少,复制成本低,且空间浪费在可接受范围内(新生代占比小)。
3.3.3 标记-整理算法(Mark-Compact)
工作原理:
- 标记阶段:与标记-清除相同,从 GC Roots 出发标记所有存活对象。
- 整理阶段:将所有存活对象向一端移动,使它们紧凑排列,然后清理掉边界以外的内存。

优点:
- 无碎片:解决了标记-清除算法的碎片问题,内存利用率高。
- 适合老年代:老年代对象存活率高,移动成本虽然高,但 GC 频率低,整体可接受。
缺点:
- 性能开销大:整理阶段需要移动大量存活对象,并更新所有引用地址,耗时较长。
适用场景:老年代。因为老年代 GC 频率低,且需要避免碎片化(否则可能导致大对象无法分配)。
3.3.4 三种算法对比总结
| 算法 | 内存碎片 | 空间利用率 | 效率 | 适用场景 |
|---|---|---|---|---|
| 标记-清除 | 有碎片 | 高 | 中 | 老年代(配合 CMS) |
| 复制 | 无碎片 | 低(浪费一半) | 高(存活率低时) | 新生代 |
| 标记-整理 | 无碎片 | 高 | 低(移动成本高) | 老年代 |
这三种算法都不完美,所以 Java 并没有单一使用某种算法,而是结合了 分代回收 的思想,针对新生代和老年代的不同特点采用最合适的策略,从而实现整体效率的最大化。接下来将详细介绍分代回收的具体实现。
3.4 分代回收(Generational Collection)
为什么分代?
大多数对象的生命周期都很短(例如方法内局部对象),而少数对象生命周期很长(如缓存、单例)。将堆划分为不同区域,可以针对不同特点采用最合适的回收算法,从而提高整体效率。
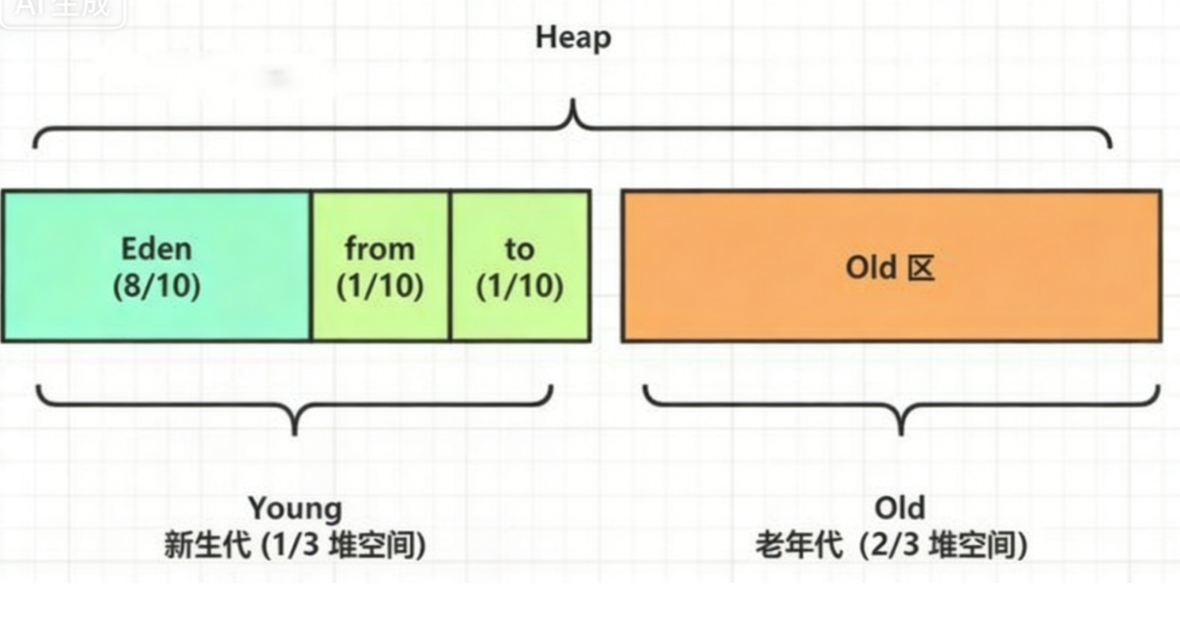
| 区域 | 占比 | 特点 | 回收算法 |
|---|---|---|---|
| 新生代 | 堆的 1/3 ~ 1/2 | 存放新创建的对象,大部分朝生暮死 | 复制算法 |
| 伊甸区(Eden) | 新生代的 80% | 新对象优先分配到这里 | - |
| 幸存区(Survivor) | 两个,各占新生代的 10% | 存放从 Eden 区存活下来的对象 | - |
| 老年代 | 堆的 2/3 ~ 1/2 | 存放长期存活的对象 | 标记-整理(或标记-清除,配合 CMS) |
名字由来:伊甸区和幸存区名称源自《圣经》故事------上帝造了亚当和夏娃,让他们在伊甸园生活,后来因偷吃禁果被逐出,洪水惩罚时幸存者进入诺亚方舟。新生代中的对象就像伊甸园中的生命,经历 GC(洪水)后幸存下来的进入幸存区(方舟),多次幸存后进入老年代(新世界)。
新生代回收流程(Minor GC)
- 新对象优先分配在 伊甸区。
- 当伊甸区满时,触发 Minor GC 。使用 复制算法:将伊甸区和一个幸存区(如 From)中的存活对象复制到另一个幸存区(To),然后清空伊甸区和 From 区,并交换两个幸存区的角色(保证 To 区始终为空)。
- 每个对象在幸存区每经历一次 Minor GC 且存活,年龄就 +1。当年龄达到阈值(默认 15),对象就晋升到 老年代。
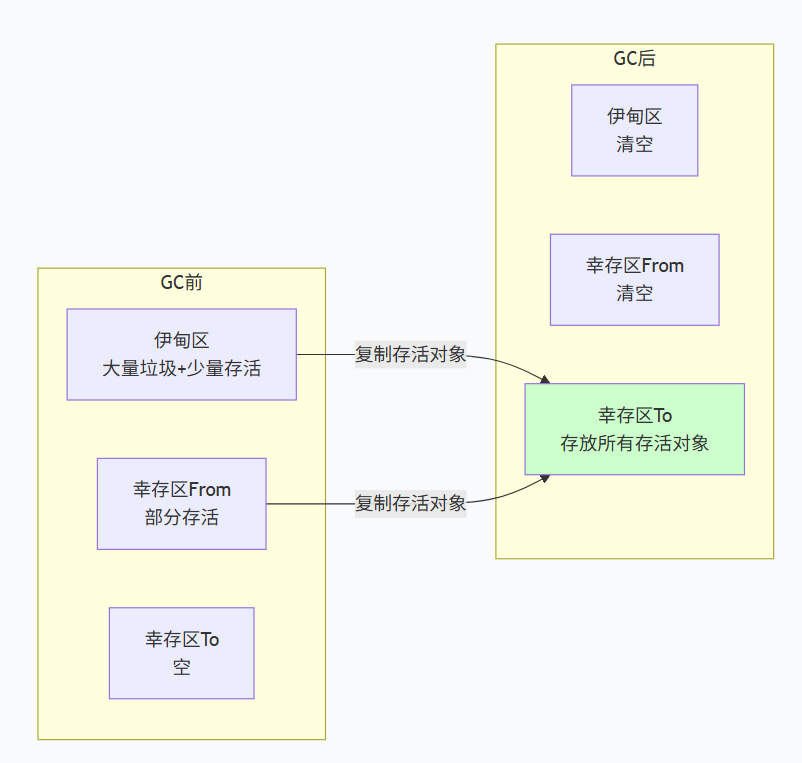
为什么复制算法适合新生代?
因为新生代每次回收后存活的对象很少(比如只有 10%),复制成本低,且没有内存碎片,分配速度快。虽然复制算法会浪费一半空间(始终有一个幸存区为空),但新生代本身空间占比小,这种浪费可以接受。
老年代回收流程(Major GC / Full GC)
老年代的对象存活率高,且空间大,不适合复制算法。通常采用 标记-整理 或 标记-清除(配合 CMS 等并发收集器)。虽然标记-整理需要移动对象,但老年代 GC 频率远低于新生代,所以总体开销可以接受。
大对象直接进入老年代
如果一个对象占用的空间很大(比如很长的数组),会直接分配到老年代,避免在新生代频繁复制。
类比:有的人拼了命(多次 GC)才进入老年代,而有的人(大对象)靠"关系"直接进入老年代。
四、总结
JVM 的内存管理与垃圾回收是一个精妙的系统工程。从内存区域的划分,到类加载的双亲委派,再到 GC 的标记和回收算法,每一步都体现了"在性能和安全性之间取得平衡"的设计思想。
- 类加载 用双亲委派保证了核心类库的权威性,防止用户篡改。
- GC 的标记 通过可达性分析,解决了循环引用问题,用 STW 换取准确性。
- GC 的回收 采用分代思想,针对新生代和老年代的不同特点选择最优算法,实现效率最大化。
五、常见 JVM 面试题(附回答要点)
1. JVM 的内存区域有哪些?各自的作用是什么?
考察点:JVM 内存布局(堆、栈、元数据区等),以及线程私有与共享的区别。
回答要点:
- 程序计数器:线程私有,记录当前线程执行的字节码行号,用于线程切换后恢复执行。唯一不会 OOM 的区域。
- 虚拟机栈 :线程私有,每个方法执行时创建栈帧,存储局部变量表、操作数栈、动态链接、方法出口等。递归过深导致
StackOverflowError。 - 本地方法栈 :线程私有,为
native方法服务,类似虚拟机栈,但服务于 JNI 调用。 - 堆:线程共享,存放所有对象实例和数组,是 GC 的主要区域。可分为新生代(Eden、Survivor)和老年代。
- 元数据区(Java 8+):线程共享,存储类的元数据、常量池、静态变量等。用本地内存,避免 PermGen 内存溢出。
进阶追问 :Java 8 为什么用元空间替代永久代?
→ 避免永久代内存上限限制,减少 OOM 风险。
2. 类加载的过程是怎样的?双亲委派模型是什么?为什么要这样设计?
考察点:类加载的五个阶段,双亲委派机制及其作用。
回答要点:
- 类加载分为:加载 → 验证 → 准备 → 解析 → 初始化。
- 加载:查找并读取字节码,生成 Class 对象。此阶段使用双亲委派:先委托父加载器加载,父加载器加载失败才自己加载。
- 验证:确保字节码符合 JVM 规范,防止恶意代码。
- 准备:为静态变量分配内存并设默认零值。
- 解析:将常量池中的符号引用替换为直接引用。
- 初始化 :执行静态变量赋值和静态代码块(
<clinit>)。
双亲委派的好处 :保证核心类库的唯一性(如 java.lang.String 由 Bootstrap 加载器加载),避免重复加载,防止用户篡改核心类,实现沙箱安全。
进阶追问 :如何打破双亲委派?
→ 自定义类加载器,重写 loadClass() 方法,不先委托父加载器。
3. 垃圾回收中,如何判断一个对象是"垃圾"?有哪些 GC Roots?
考察点:可达性分析、GC Roots 的组成。
回答要点:
- Java 采用可达性分析,而非引用计数法(引用计数有循环引用问题且占用额外内存)。
- 从 GC Roots 出发,通过引用链遍历对象,无法到达的对象即为垃圾。
- GC Roots 包括 :
- 虚拟机栈(栈帧中的局部变量)引用的对象
- 元数据区中静态属性引用的对象
- 元数据区中常量池引用的对象(如字符串常量)
- 本地方法栈中 JNI 引用的对象
- 活动线程(Thread)对象本身
进阶追问 :引用计数法为什么不行?
→ 循环引用无法回收,且每个对象需额外计数器。
4. 简述垃圾回收的三种基础算法(标记-清除、复制、标记-整理)及其优缺点。
考察点:GC 算法的原理、适用场景、内存碎片问题。
回答要点:
- 标记-清除:先标记存活对象,再清除未标记的。简单,但产生内存碎片,可能无法分配大对象。
- 复制算法:将内存分为两块,每次使用一块,存活对象复制到另一块,清空原块。无碎片,但空间利用率低(最多 50%)。适用于新生代(存活率低)。
- 标记-整理:标记存活对象后,将所有存活对象向一端移动,再清理边界外内存。无碎片,但移动对象开销大。适用于老年代(存活率高)。
进阶追问 :为什么新生代不用标记-整理?
→ 因为新生代存活率低,复制成本低,且整理移动对象开销大。
5. 什么是 Stop The World?为什么 GC 需要 STW?如何减少 STW 的影响?
考察点:STW 的概念、必要性、并发收集器的优化手段。
回答要点:
- STW:垃圾回收期间暂停所有用户线程,仅让 GC 线程执行。
- 为什么需要 STW:可达性分析需要对象引用关系在一瞬间静止,否则业务线程修改引用会导致标记结果错误,可能误回收正在使用的对象(致命错误)。
- 减少 STW 的影响 :
- 使用并发收集器(如 CMS、G1、ZGC),在标记阶段大部分工作与用户线程并发,只在初始标记和重新标记时短暂 STW。
- G1 通过"停顿预测模型"控制停顿时间。
- ZGC 将停顿时间控制在毫秒级。
- STW 的代价:程序卡顿,对实时性要求高的场景(如高频交易)不友好。
进阶追问 :CMS 和 G1 的优缺点?
→ CMS 易产生碎片,G1 可控停顿且内存利用率高。