我们在基础篇讲了 pd.cut 和 pd.qcut 各自怎么用。但在实际项目里,分箱不是调一次函数就完事的。通常来说,训练集上算出来的切分点要保存下来,测试集和线上推断要复用同一套切分点,还要处理各种边界情况。
这篇聚焦分箱落地时的工程问题:怎么 fit、怎么 apply、怎么兜底、怎么验证。
准备工作:生成模拟数据
本篇所有示例共用同一份模拟数据,先跑这段:
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
np.random.seed(42)
n = 5000
df = pd.DataFrame({
'月收入': np.random.exponential(8000, n).clip(1000, 80000),
'负债率': np.random.beta(2, 5, n),
'逾期次数': np.random.poisson(0.5, n).clip(0, 10).astype(int),
'账龄': np.random.randint(1, 120, n),
'年龄': np.random.randint(20, 65, n),
})
# 模拟违约标签:收入低、负债高、逾期多 → 违约概率更高
log_odds = -3 - 0.0001*df['月收入'] + 2.0*df['负债率'] + 0.5*df['逾期次数'] - 0.005*df['账龄']
df['label'] = (np.random.rand(n) < 1/(1+np.exp(-log_odds))).astype(int)
train, test = train_test_split(df, test_size=0.2, random_state=42, stratify=df['label'])
print(f"训练集 {len(train)} 条,测试集 {len(test)} 条,坏样本率 {df['label'].mean():.2%}")输出:
bash训练集 4000 条,测试集 1000 条,坏样本率 4.38%
后续代码中出现的 train、test 均来自这里。
一、fit / apply 分离模式
分箱和模型训练一样,存在训练与推断不一致的风险。如果在测试集上重新调用 qcut,因为切分点可能会不同,这样在训练集和测试集上相同的值可能落进不同的箱,这就是数据泄漏的一种形式。
1.1 将分箱拆分为拟合和应用
通常,在实践过程中,会把分箱拆成两步:
首先,拟合切分点。fit_bins 负责在训练集上用 qcut 算出切分点,只返回 edges 数组,不返回分箱结果:
python
def fit_bins(series, n_bins=5):
"""在训练集上拟合切分点"""
_, edges = pd.qcut(series, q=n_bins, retbins=True, duplicates='drop')
return edges apply_bins 负责用已有的 edges 对任意数据分箱。注意它内部调用的是 pd.cut 而不是 qcut,因为切分点已经确定了,不需要再从数据中计算:
python
def apply_bins(series, edges):
"""用已保存的切分点对任意数据分箱"""
return pd.cut(series, bins=edges, include_lowest=True)1.2 使用
训练时调 fit_bins 拿到切分点,之后训练集、测试集、线上数据全部走 apply_bins:
python
# 训练阶段:拟合
edges = fit_bins(train['月收入'], n_bins=5)
# 训练集分箱
train['月收入_bin'] = apply_bins(train['月收入'], edges)
# 测试集 / 线上推断:复用同一套 edges
test['月收入_bin'] = apply_bins(test['月收入'], edges) 这个模式的核心是 qcut 只调用一次,后续全部用 cut 。edges 是一个 numpy 数组,可以序列化保存(pickle / JSON / 配置文件),和模型权重一起管理。
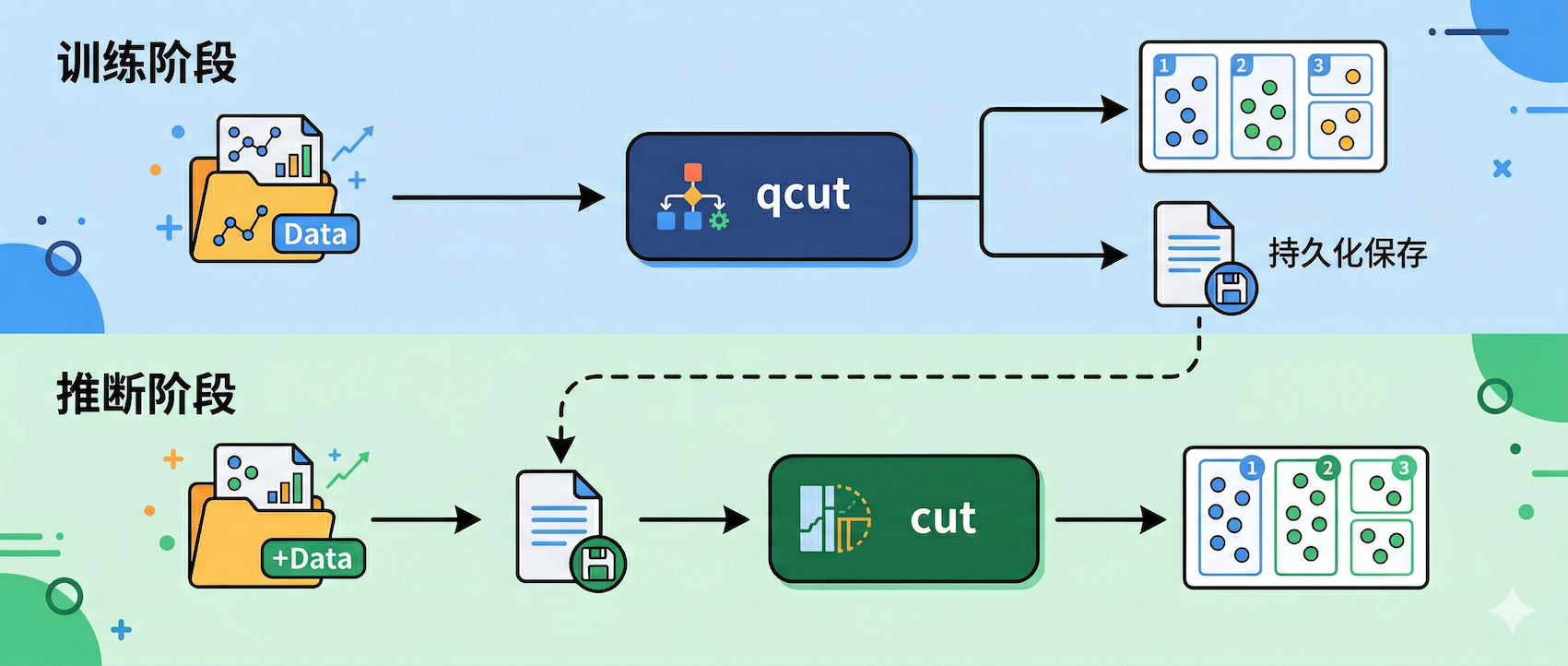
fit_bins 对应 sklearn 的 fit,apply_bins 对应 transform。分箱本质上也是一个有状态的转换器,状态就是那组 edges。
二、边界值兜底
2.1 问题:极端值变 NaN
训练集的值域是有限的。线上数据完全可能出现训练时没见过的极端值,例如收入特别高的客户、负债率为零的新用户。如果这些值落在 edges 范围之外,pd.cut 会返回 NaN,下游特征全部失效。
2.2 解法:首尾替换为无穷
只需要在 fit_bins 里加两行,把 qcut 算出的第一个和最后一个切分点替换成 ±inf,让区间向两端无限延伸:
python
def fit_bins(series, n_bins=5):
_, edges = pd.qcut(series, q=n_bins, retbins=True, duplicates='drop')
edges[0] = -np.inf
edges[-1] = np.inf
return edges 这样不管来什么值,都一定能落进某个箱里。
python
edges = fit_bins(train['月收入'], n_bins=5)
bash[ -inf 1776.89448627 4075.8209369 7400.24411354 12748.68735451 inf]
对于月收入,我们设置的分箱数为5, 得到了6个边界点。
验证一下效果,故意传入一个远低于训练集最小值的 500 和一个远高于最大值的 200000:
python
test_series = pd.Series([500, 200000])
test_bins_res = apply_bins(test_series, edges)
test_bins_df = pd.DataFrame({"data": test_series, "bins": test_bins_res})
print(f"test bins = {test_bins_df}")
test bins = data bins 0 500 (-inf, 1776.894] 1 200000 (12748.687, inf]
可以看到极小值进第一个箱,极大值进最后一个箱。不会再有 NaN出现。
2.3 注意事项
有一个细节值得注意:替换 ±inf 后,第一个箱和最后一个箱变成了兜底箱,它们的样本量在线上可能和训练时不一样。如果业务上对极端值的处理有特殊要求(比如超高收入客户需要单独审批流程),应该在分箱之前就做截断或特殊标记,而不是依赖兜底箱。
三、重复边界的处理策略
基础篇中提到过 duplicates='drop' 能绕过重复切分点的报错。但"绕过"不等于"解决",箱数会减少,等频的约束被打破。实际遇到这个问题时,有几种处理方式。
3.1 先看分布再决定
遇到 duplicates 报错时,第一反应不是加 duplicates='drop',而是先看看数据长什么样:
python
s = pd.Series([0, 0, 0, 0, 0, 1, 2, 3, 5, 10])
sorted_res = s.value_counts().sort_index()
print(sorted_res)
bash
0 5
1 1
2 1
3 1
5 1
10 1 10 个值里 5 个是 0,等频分 5 箱需要找 20%、40%、60%、80% 四个分位数作为切分点,其中 20% 分位和 40% 分位都落在 0 上,产生重复的切分点,qcut 直接报 ValueError。看清分布之后,再选下面某种策略。
3.2 策略一:drop + 接受更少的箱
最省事的方式,就是让 pandas 自动合并重复的切分点,实际箱数会少于你请求的数量:
python
_, edges = pd.qcut(s, q=5, retbins=True, duplicates='drop')
# 实际只得到 2~3 个箱 适合探索阶段快速看个大概,不适合直接用于建模。
3.3 策略二:把高频值单独成箱
思路是把导致重复的那个值拎出来给它一个专属箱,剩下的值再正常分箱。
-
单独拎出来0所在的信息,剩下的再分箱
pythonmask_zero = (s == 0) _, edges_rest = pd.qcut(s[~mask_zero], q=3, retbins=True) print("====剩下的边界====") print(edges_rest)bash====剩下的边界==== [ 1. 2.33333333 4.33333333 10. ] -
手工拼接:在 edges_rest 前面插入
-inf和0,让 0 独占(-inf, 0]这个箱。pythonedges = np.concatenate([[-np.inf, 0], edges_rest[1:]]) edges[-1] = np.inf print("=====拼接边界=======") print(edges)python=====拼接边界======= [ -inf 0. 2.33333333 4.33333333 inf]
注意最终箱数是 1(0 的专属箱)+ 3(剩余值的等频箱)= 4 个,不是 q=3 指定的 3 个。q 控制的只是"去掉高频值之后"那部分数据的分箱数,加上手工拆出来的专属箱,总箱数会多出来。
风控场景常见,比如"逾期次数 = 0"本身就是一个强特征,值得单独成箱。
3.4 策略三:换用等距或自定义分箱
如果等频分箱在这个特征上表现不好,换用 pd.cut 或业务自定义切分点可能更合适。不必执着于一种分箱方式。
四、自定义分箱点
等频和等距都是数据驱动的自动方案。实际业务中,分箱点经常来自领域知识。
4.1 按业务含义切分
年龄是最典型的例子,每个年龄段在风控中的含义不同,切分点来自业务经验而非数据分布:
python
age_bins = [0, 18, 25, 35, 45, 55, 65, np.inf]
age_labels = ['未成年', '18-25', '26-35', '36-45', '46-55', '56-65', '65+']
df['年龄段'] = pd.cut(df['年龄'], bins=age_bins, labels=age_labels,
right=False, include_lowest=True) 负债率也类似,风控经验上 20%、40% 等是常见的风险分水岭:
python
debt_bins = [-np.inf, 0.2, 0.4, 0.6, 0.8, np.inf]
df['负债率段'] = pd.cut(df['负债率'], bins=debt_bins, include_lowest=True) 自定义分箱的好处是可解释性强,业务人员能直接理解"负债率 40%~60%"是什么意思,不需要解释"第 3 分位到第 4 分位"。缺点是需要领域经验,切分点选不好会导致某些箱样本量太少。
4.2 折中:自动探索 + 手工微调
一种折中做法是:先用 qcut 自动分箱看分布,再根据业务含义手工微调切分点。
五、分箱结果的验证
分箱完成后,需要验证结果的合理性,避免把有问题的分箱带入下游建模。以下三项检查覆盖了最常见的问题。
5.1 各箱样本量
最基本的检查,看每个箱里有多少样本:
python
df['月收入_bin'].value_counts().sort_index()(-inf, 3200.0] 812
(3200.0, 5800.0] 798
(5800.0, 9500.0] 803
(9500.0, 16000.0] 791
(16000.0, inf] 796 等频分箱的各箱应该大致均匀。如果某个箱样本量特别少(比如不到总量的 5 % 5\% 5%),考虑合并相邻箱。
5.2 是否存在空箱
训练集和测试集的分布可能有差异,某个箱在测试集里可能一个样本都没有:
python
# 检查测试集是否有箱为空
test_counts = test['月收入_bin'].value_counts()
if (test_counts == 0).any():
print("警告:测试集存在空箱") 测试集某个箱为空不一定是问题(可能只是样本量小),但如果训练集某个箱为空就需要处理了,空箱算不出 WOE,会在下游引发错误。
5.3 可视化验证
数字看完看图。最有信息量的图是柱线混合图,柱子表示各箱样本量,折线表示坏样本率:
python
import matplotlib.pyplot as plt
bin_stats = (
train.groupby('月收入_bin', observed=True)['label']
.agg(['mean', 'count'])
.rename(columns={'mean': 'bad_rate', 'count': 'n'})
) groupby 按分箱聚合,mean 就是坏样本率(因为 label 是 0/1),count 是样本量。
bash
月收入_bin bad_rate n
(-inf, 1776.894] 0.06875 800
(1776.894, 4075.821] 0.05250 800
(4075.821, 7400.244] 0.05375 800
(7400.244, 12748.687] 0.03250 800
(12748.687, inf] 0.01125 800 画图用双 Y 轴:左轴画柱子表示样本量,右轴画折线表示坏样本率。两个指标量纲差异大,共享一个 Y 轴会导致其中一个被压扁看不清:
python
fig, ax1 = plt.subplots(figsize=(10, 5))
ax1.bar(range(len(bin_stats)), bin_stats['n'], alpha=0.3, label='样本量')
ax2 = ax1.twinx() # 创建共享 X 轴的第二个 Y 轴
ax2.plot(range(len(bin_stats)), bin_stats['bad_rate'], 'ro-', label='坏样本率') X 轴的刻度默认是 0, 1, 2... 这样的整数索引,需要替换成分箱区间标签。标签较长,旋转 45° 避免重叠:
python
ax1.set_xticks(range(len(bin_stats)))
ax1.set_xticklabels(bin_stats.index.astype(str), rotation=45, ha='right')
plt.tight_layout()
plt.show()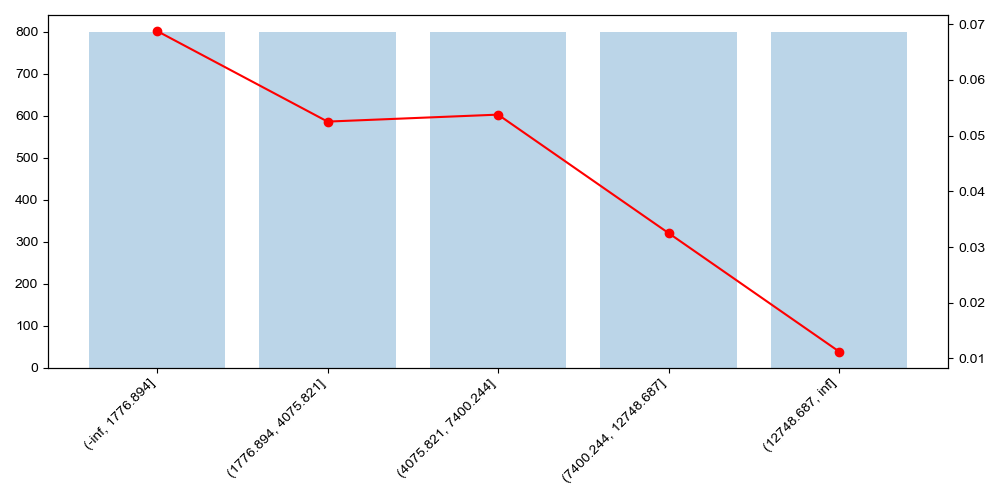
重点看折线的走势:理想情况下,坏样本率应该在各箱之间呈单调趋势(随收入增加而递减,或随逾期次数增加而递增)。如果出现非单调的拐点,通常意味着需要合并相邻箱或重新调整切分点,这就是WOE 单调性约束。另外需要说明的是,非单调拐点是一个信号,不是一个错误。它提示你这两个相邻箱的风险差异可能不够显著,合并后模型会更稳定。
六、多特征批量分箱
实际项目中特征不止一个。把前面的 fit_bins / apply_bins 包一层循环,对所有特征统一处理:
python
def fit_all_bins(df, features, n_bins=5):
"""对多个特征批量拟合分箱"""
return {feat: fit_bins(df[feat], n_bins) for feat in features}
def apply_all_bins(df, features, bin_edges):
"""对多个特征批量应用分箱"""
result = df.copy()
for feat in features:
result[f'{feat}_bin'] = apply_bins(df[feat], bin_edges[feat])
return result 用法很直观,训练时 fit 一次,之后对训练集和测试集各 apply 一次:
python
features = ['月收入', '负债率', '逾期次数', '账龄', '年龄']
bin_edges = fit_all_bins(train, features)
train_binned = apply_all_bins(train, features, bin_edges)
test_binned = apply_all_bins(test, features, bin_edges) bin_edges 是一个字典,键为特征名,值为 edges 数组。整个字典可以一次性序列化保存,部署时加载复用。
七、edges 的持久化
bin_edges 需要和模型一起保存,否则线上没法分箱。
7.1 方案一:pickle
最简单的方式,但 numpy 版本敏感:
python
import pickle
with open('bin_edges.pkl', 'wb') as f:
pickle.dump(bin_edges, f)7.2 方案二:JSON
跨语言通用(Java/Go 线上服务也能读),但有一个麻烦:JSON 规范只支持有限数值,±inf 和 NaN 都无法直接表示。Python 的 json.dumps(float('inf')) 会直接抛 ValueError。
这里需要约定一个映射规则。常见做法是把 ±inf 映射成 None(Python)→ null(JSON)。注意这三者的对应关系:
| Python | JSON | 含义 |
|---|---|---|
None |
null |
空值 |
float('inf') |
无对应,需自行约定 | 正无穷 |
float('nan') |
无对应,需自行约定 | 非数值 |
我们选择 null 来表示 ±inf,是因为 edges 数组中只有首尾两个位置可能是无穷,反序列化时根据位置(首位→-inf,末位→+inf)就能无歧义地还原。
(1) 序列化实现
python
import json
def edges_to_json(bin_edges):
result = {}
for feat, edges in bin_edges.items():
result[feat] = [
None if np.isinf(e) else float(e)
for e in edges
]
return result 序列化后的 JSON 大概长这样:{"月收入": [null, 3200.0, 5800.0, 9500.0, 16000.0, null]}。
(2) 反序列化实现
反序列化时把首尾的 null 还原成 ±inf:
python
def edges_from_json(data):
result = {}
for feat, edges in data.items():
arr = []
for i, e in enumerate(edges):
if e is None:
arr.append(-np.inf if i == 0 else np.inf)
else:
arr.append(e)
result[feat] = np.array(arr)
return result7.3 如何选择
选哪个取决于部署环境。如果线上服务也是 Python(比如用 Flask/FastAPI 包一层),pickle 最省心;如果线上是 Java 微服务,JSON 或配置中心更合适。
八、总结
这篇讲的是分箱的"工程骨架":
- fit / apply 分离 :
qcut只在训练集上调一次,后续全用cut+ 保存的 edges - ±inf 兜底:替换首尾边界,确保任何值都有箱可落
- 重复边界:先看分布,再选策略(drop / 单独成箱 / 换方式)
- 自定义分箱 :业务知识优先,
qcut做初始探索 - 验证三件事:样本量、空箱、坏样本率单调性
- 持久化:edges 和模型一起保存、一起部署