编码是机器学习流程里最容易被低估的环节之一,模型没办法直接处理文本形式的分类数据,尺寸(Small/Medium/Large)、颜色(Red/Blue/Green)、城市、支付方式等都是典型的分类特征,必须转成数值才能输入到模型中。
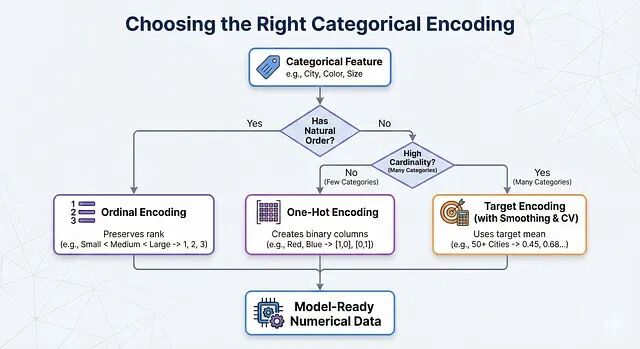
那么问题来了:为什么不直接把 Red 编成 1,Blue 编成 2?这个做法看起来简单粗暴,但其实藏着大坑。下面用一个小数据集来说明。
数据集概述
Feature | Description
-------------------|----------------------------------------------------------
customer_id | Unique customer identifier
gender | Male or Female
education_level | High School → Associate → Bachelor's → Master's → PhD
employment_status | Full-time, Part-time, Self-employed, Unemployed
city | Customer's city (50+ US cities)
product_category | Electronics, Clothing, Books, Sports, Home & Garden, Beauty, Food & Beverage
payment_method | Credit Card, Debit Card, PayPal, Cash
customer_tier | Bronze → Silver → Gold → Platinum
satisfaction_level | Dissatisfied → Neutral → Satisfied → Very Satisfied
credit_score_range | Poor → Fair → Good → Very Good → Excellent
purchase_amount | Purchase amount in USD
will_return | Yes or No (target variable)Ordinal Encoding
Ordinal Encoding 思路很简单:给每个类别分配一个数字,但是模型会把这些数字当作有序的。
假设对
payment_method做编码:Cash = 1,PayPal = 2。模型会认为 Cash < PayPal,仿佛 PayPal 比 Cash "更好" 或 "更大"。但支付方式之间根本没有这种大小关系因为它们只是不同的选项而已。
什么时候 Ordinal Encoding 才合适?当数据本身就存在真实的顺序关系时。比如
education_level:High School < Associate < Bachelor's < Master's < PhD。这是客观存在的递进关系,用数字表示完全没问题,模型的理解也是对的。
所以 Ordinal Encoding 的使用场景很明确:只用于那些排名确实有意义的特征。
from sklearn.preprocessing import OrdinalEncoder
ordEnc = OrdinalEncoder()
print(ordEnc.fit_transform(data[["education_level"]])[:5])
# Output
"""
[[1.]
[2.]
[3.]
[4.]
[2.]]
"""One-Hot Encoding
One-Hot Encoding 换了个思路:不用数字而是给每个类别创建一列。
payment_method有 4 个值,就变成 4 列,每行只有一个位置是 1,其余全是 0。
| payment_cash | payment_credit_card | payment_debit_card | payment_paypal |
|--------------|---------------------|--------------------|----------------|
| 1 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 |
| 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 1 |这样做的好处是消除了虚假的顺序关系,所有类别被平等对待和线性模型配合得也很好。
那么代价是什么?维度会膨胀。
customer_tier和
payment_method各 4 个值,合起来就是 8 列。如果遇到城市这种特征,50 多个类别直接炸成 50 多列,维度灾难就来了。
from sklearn.preprocessing import OneHotEncoder
oneEnc = OneHotEncoder()
print(oneEnc.fit_transform(data[["customer_tier", "payment_method"]]).toarray()[:5])
[#output](#output)
"""
[[0. 1. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0. 0. 1. 0.]
[0. 0. 1. 0. 0. 0. 0. 1.]
[0. 1. 0. 0. 0. 1. 0. 0.]
[1. 0. 0. 0. 1. 0. 0. 0.]]
"""Target Encoding
面对高基数特征(比如 City 有 50 多个值)One-Hot Encoding 会把特征空间撑得太大,Target Encoding 的做法是:用每个类别对应的目标变量均值来替换。也叫 Mean Encoding。
举个例子,目标变量是
will_return(Yes = 1,No = 0):
| City | will_return |
|-----------|-------------|
| Austin | 1 |
| Austin | 1 |
| New York | 1 |
| New York | 0 |
| New York | 0 |
| New York | 0 |
| New York | 1 |计算每个城市的目标均值:Austin → (1 + 1) / 2 = 1.0,New York → (1 + 0 + 0 + 0 + 1) / 5 = 0.4,这样得到的编码结果就是:
| City | Encoded Value |
|----------|----------------|
| Austin | 1.0 |
| New York | 0.4 |这里有一个坑,Austin 只出现了 2 次而且刚好都是正例,编码值直接变成 1.0。模型可能会 "学到" 一个规律:看到 Austin 就预测 will_return = Yes。
但这个 "规律" 完全是数据量不足造成的假象。样本太少均值就很不可靠。
Smoothing 的思路是把类别均值往全局均值方向 "拉" 一拉。公式:
Encoded Value = (w * Category Mean) + ((1 - w) * Global Mean)其中 Category Mean 是该类别的目标均值Global Mean 是整个数据集的目标均值,w 是一个和样本量相关的权重。样本越少w 越小,编码值就越接近全局均值;样本越多类别自己的均值就越占主导。这能有效抑制小样本带来的过拟合。
另一个问题就是 Data Leakage。如果用全量数据计算编码值再把这个编码喂给模型,模型等于直接 "看到了" 答案的统计信息。比如模型发现 City = 0.34 对应的样本大概率是 will_return = Yes,那它干脆走捷径,不从其他特征里学东西了。
所以就要引入交叉验证,以 5 折为例:把数据分成 5 份,对第 1 份的数据,用第 2 到第 5 份来计算编码;对第 2 份的数据,用第 1、3、4、5 份来计算编码;以此类推。每个样本的编码值都来自于它 "没见过" 的数据,泄露就切断了。
但是副作用是同一个城市在不同折里的编码值会略有差异:New York 在 Fold 1 里可能是 0.50,在 Fold 2 里是 0.45。但这反而是好事,这样可以让模型被迫学习更一般化的模式而不是死记某个精确数值。
Target Encoding 的优点:避免维度爆炸,适合高基数特征,还能把目标变量的统计信息编进去。
但用的时候得小心:必须加 Smoothing 防止小样本过拟合,必须用交叉验证防止数据泄露。
from sklearn.preprocessing import TargetEncoder
data["will_return_int"] = data["will_return"].map({"Yes": 1, "No": 0})
tarEnc = TargetEncoder(smooth="auto", cv=5) # Those are the default value
print(data[["city"]][:5])
print(tarEnc.fit_transform(data[["city"]], data["will_return_int"])[:5])
"""
city
0 Houston
1 Phoenix
2 Chicago
3 Phoenix
4 Phoenix
[[0.85364466]
[0.69074308]
[0.65024828]
[0.74928653]
[0.81359495]]
"""总结
三种编码方法各有适用场景,选择取决于特征本身的性质。
实际操作中可以这样判断:特征有天然顺序就用 Ordinal Encoding;没有顺序、类别数量也不多就用 One-Hot Encoding;类别太多就上 Target Encoding,记得配合 Smoothing 和交叉验证。
真实项目里,一个数据集往往会同时用到这三种方法。
https://avoid.overfit.cn/post/eeabb03fba684a88a6ccce132f4852b0
作者: adham ayman