
前言
大家好,这里是程序员阿亮,在上一篇我们讲解了RAG的Embedding,那么我的离线处理部分也就基本讲完了,但是,实际上,处理是讲完了,那么存储呢?
我们的向量的存储一般不存储在常规的传统数据库,而是会有特定的向量数据库来存储。
并且会有不同的搜索或者检索策略与算法。
接下来为大家讲解!
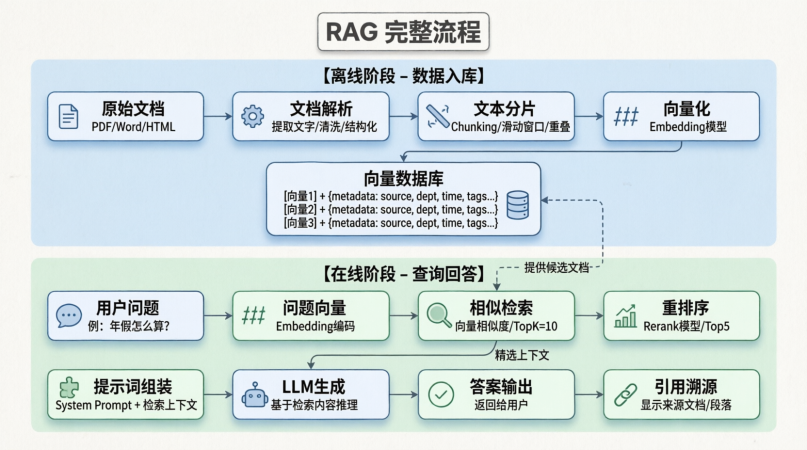
一、前置知识
1. 向量(Vector)vs. 嵌入(Embedding)
- 向量 (Vector) :数学概念。一组有序的数字列表,例如
[0.1, 0.5, -0.9]。它本身没有意义,只是数据的数值化表示。 - 嵌入 (Embedding) :工程/算法过程。将非结构化数据(文本、图片)转换 为向量的过程。
- 误区:"存的是 Embedding"。
- 正解:"存的是向量,这个向量是通过 Embedding 模型生成的"。
- 关键点 :向量数据库存储的是向量数值 ,不关心它是通过 BERT、CLIP 还是其他模型生成的,但模型的一致性至关重要(不同模型生成的向量空间不互通)。
2. 精确搜索 (KNN) vs. 近似搜索 (ANN)
- KNN (K-Nearest Neighbors) :暴力扫描 。计算查询向量与数据库中所有 向量的距离,排序后取 Top-K。
- 优点:100% 准确。
- 缺点:数据量过大时(如 >10 万),延迟不可接受(秒级甚至分钟级)。
- ANN (Approximate Nearest Neighbor) :策略性跳过 。通过索引结构,跳过 大部分不可能相似的向量,只计算一小部分候选集。
- 优点:速度极快(毫秒级),支持亿级数据。
- 缺点:牺牲少量精度(召回率可能从 100% 降到 95%~99%)。
- 核心权衡 :用可接受的精度损失,换取指数级的速度提升。
3. 召回率 (Recall) vs. 延迟 (Latency)
- 召回率:ANN 找到的结果中,有多少是真正属于"精确 Top-K"的?(例如:精确前 10 名里,ANN 找到了 9 个,召回率 90%)。
- 延迟:查询耗时。
- 关系 :通常呈反比。想要更高召回率,就需要搜索更多候选节点,延迟必然增加。企业落地的核心调优就是寻找这两者的平衡点。
二、ANN 主流算法原理
向量数据库的性能差异,本质上是索引算法的差异。以下是四大主流技术路线的原理详解。
1. 基于树的结构 (Tree-based)
- 代表算法:KD-Tree, Ball Tree。
- 原理:像二分查找一样,将空间不断切分。查询时根据距离判断走左枝还是右枝。
- 现状 :已基本淘汰。
- 原因 :维度灾难。在低维空间(<20 维)效果很好,但在高维空间(>100 维,如向量数据库常见的 768 维)下,树的剪枝能力失效,退化为准暴力搜索,性能急剧下降。
- 适用:仅适用于极低维特征检索,不推荐用于现代向量数据库。
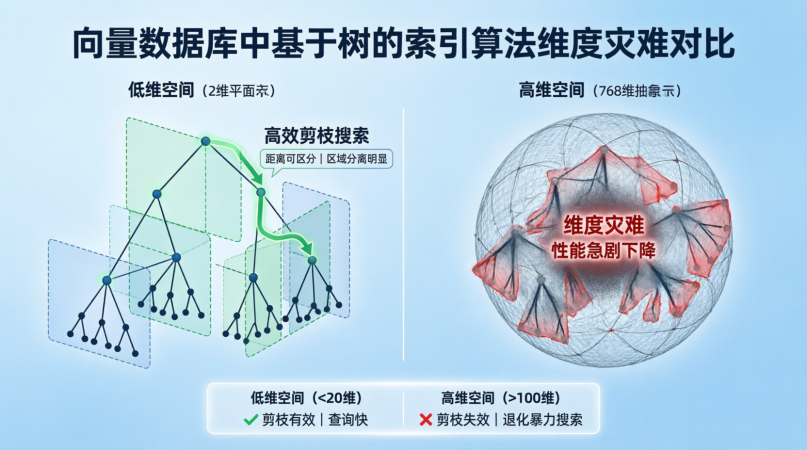
2. 基于哈希 (Hash-based)
- 代表算法:LSH (Locality Sensitive Hashing, 局部敏感哈希)。
- 原理 :设计一种哈希函数,使得相似的向量有大概率哈希到同一个桶(Bucket)里。查询时只计算同桶内的向量。
- 优点:理论上有数学保证,构建速度快,内存占用极低。
- 缺点 :召回率较低,参数敏感(哈希函数数量、桶大小难调),难以支持复杂的元数据过滤。
- 适用 :超大规模数据(十亿级)的粗筛阶段,或对精度要求不高的场景。
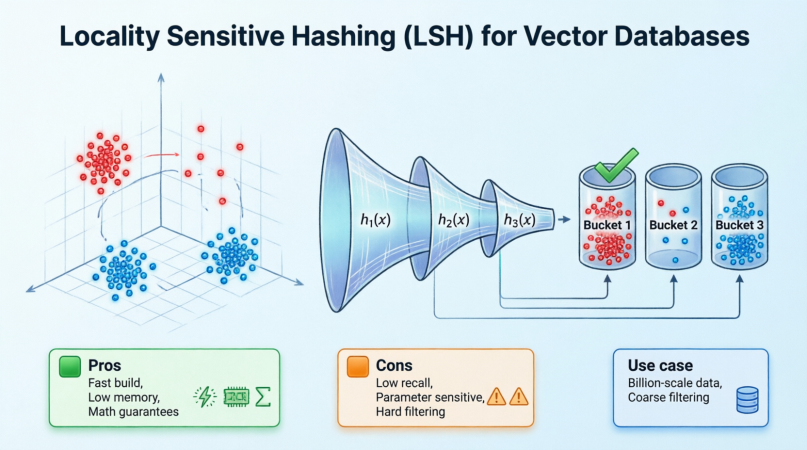
3. 基于聚类 (Clustering-based)
- 代表算法 :IVF (Inverted File Index, 倒排文件索引)。
- 原理 :
- 训练阶段 :用 K-Means 算法将所有向量聚成
N个簇(Cluster),每个簇有一个中心点。 - 查询阶段 :计算查询向量与
N个中心点的距离,只搜索最近的M个簇内的向量。
- 训练阶段 :用 K-Means 算法将所有向量聚成
- 优点 :内存占用可控,支持磁盘卸载,构建速度较快。
- 参数 :
nlist(簇数量),nprobe(搜索多少个簇)。
- 参数 :
- 缺点 :召回率依赖
nprobe大小,如果目标向量在簇的边缘,可能被漏掉。 - 适用 :内存受限 、数据量极大、对成本敏感的场景。
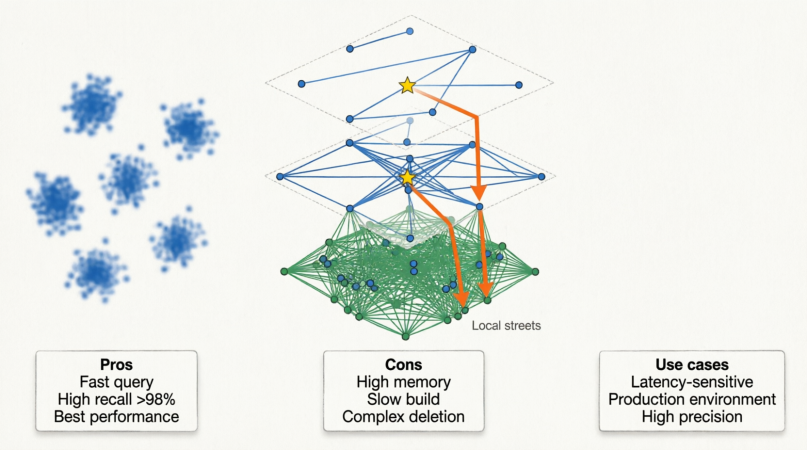
4. 基于图 (Graph-based) 当前主流
- 代表算法 :HNSW (Hierarchical Navigable Small World, 分层小世界图)。
- 原理 :
- 建图:将向量视为节点,相似向量之间连边。
- 分层:建立多层图。顶层稀疏(长距离连接,类似"高速公路"),底层稠密(短距离连接,类似"小区道路")。
- 导航:查询从顶层入口进入,快速定位到大致区域,然后逐层向下,在底层精细搜索。
- 优点 :当前综合性能最强。查询速度极快,召回率极高(通常 >98%)。
- 缺点 :内存占用大(需要存储图结构),构建索引速度慢,删除数据复杂(图结构破坏需重建)。
- 适用 :对延迟敏感 、内存充足、追求高精度的生产环境。
三、主流向量数据库选型
不同数据库选择的算法决定了其性能特征和适用场景。
| 数据库 | 核心索引算法支持 | 算法策略特点 | 典型应用场景 |
|---|---|---|---|
| pgvector | IVFFlat , HNSW | 保守稳健。早期仅支持 IVF,0.5.0+ 支持 HNSW。依赖 Postgres 内存管理。 | 中小规模数据、已有 PG 架构、强一致性要求场景。 |
| Milvus | IVF, HNSW, ANNOY, PQ, SCANN | 大而全。支持几乎所有主流算法,可针对不同 Collection 配置不同索引。 | 企业级大规模数据、多模态、需要灵活调优的场景。 |
| Qdrant | HNSW (默认), Payload Index | 极致性能 。专注 HNSW 优化,特别强化了向量 + 元数据过滤的性能(过滤后检索)。 | 实时检索、复杂过滤条件、推荐系统。 |
| Pinecone | 专有索引 (Pod 架构) | 黑盒托管。不暴露具体算法,底层基于 HNSW+ 量化优化。按 Pod 大小计费。 | 零运维需求、快速上线、预算充足的云原生场景。 |
| Elasticsearch | HNSW , Int8 Quantization | 混合检索 。8.0+ 版本引入向量,强项在于向量 + 全文检索 (BM25) 的混合能力。 | 日志分析 + 向量搜索、电商搜索(关键词 + 语义)。 |
| Weaviate | HNSW | 对象存储。将向量作为对象属性,支持 GraphQL 查询,强调语义理解。 | 知识图谱、语义搜索应用。 |
重点解析:pgvector 的算法选择
- IVFFlat(聚类) :
- 适合:数据量较大(>10 万),构建索引速度要求快,内存有限。
- 缺点 :查询速度不如 HNSW,需要调优
lists和probes。
- HNSW(图) :
- 适合:对查询延迟要求高(<10ms),内存充足。
- 缺点:构建索引慢,内存占用高(每个向量需额外存储边信息)。
- 现状 :pgvector 0.5.0 后 HNSW 成为生产环境首选,但需注意 Postgres 的
maintenance_work_mem配置,否则建索引易失败。
重点解析:Milvus 的算法选择
- 灵活性:Milvus 允许你在创建集合时指定索引类型。
- IVF_PQ:当数据量达到亿级,内存无法容纳全量 HNSW 时,Milvus 会自动推荐或用户可手动选择 IVF_PQ,通过量化压缩数据,换取磁盘存储能力。
- DiskANN:支持将索引存储在磁盘上,通过内存映射访问,解决内存瓶颈。
四、选型决策体系
选型不应只看"谁最快",而应看"谁最适合你的约束条件"。
1. 数据规模维度
- < 100 万向量 :pgvector 或 Qdrant。单机足以应付,pgvector 运维成本最低。
- 100 万 ~ 1 亿向量 :Milvus 或 Qdrant 集群。需要独立的向量服务,考虑内存成本。
- > 1 亿向量 :Milvus 分布式 或 Pinecone。必须考虑分片、量化压缩、磁盘索引。
2. 查询延迟要求
- < 10ms :HNSW 索引 (Qdrant, Milvus-HNSW, pgvector-HNSW)。必须全内存。
- 10ms ~ 100ms :IVF 索引 或 磁盘索引。可接受少量精度损失换取成本降低。
- > 100ms:批量离线分析场景,算法选择不敏感。
3. 过滤能力需求
- 强过滤 (如:向量相似 AND 时间>2023 AND 类别=IT):Qdrant 或 pgvector 。
- 原理:Qdrant 的 Payload 索引和 pgvector 的 SQL WHERE 子句能在检索前/中高效过滤。
- 避坑:Milvus 早期版本过滤性能较弱(先检索后过滤),新版已优化,但复杂 SQL 仍不如 PG 原生。
- 弱过滤:Pinecone 或 基础 Milvus。
4. 运维与成本
- 零运维/高预算 :Pinecone。按用量付费,无需关心索引参数。
- 有运维团队/控成本 :Milvus/Qdrant 自建。需承担服务器成本及人力成本。
- 复用现有基建 :pgvector。无需新组件,利用现有 PG 备份/监控体系。
五、落地考虑的关键问题
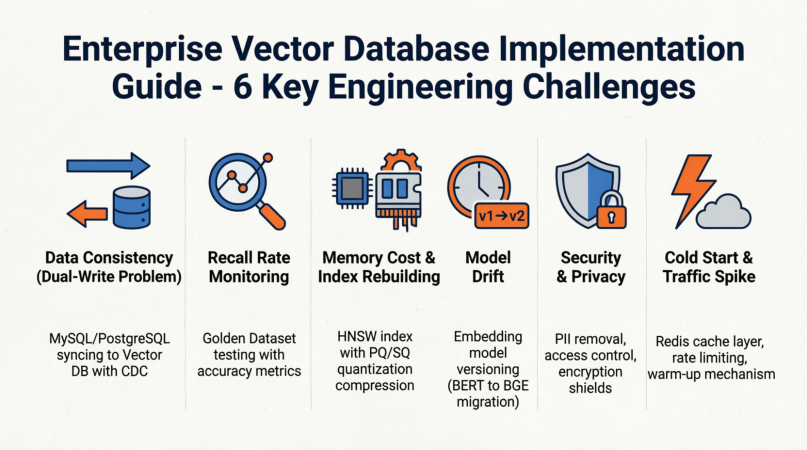
在企业生产环境落地向量数据库,技术原理只是基础,以下工程化问题往往决定项目成败。
1. 数据一致性难题(Dual-Write Problem)
- 问题:业务数据在 MySQL/PG,向量数据在向量库。当业务数据更新/删除时,如何保证向量库同步?
- 风险 :
- 数据不一致:用户删除了文档,向量库还能搜到(泄露风险)。
- 双写失败:写成功业务库,写失败向量库,导致数据丢失。
- 解决方案 :
- 方案 A(CDC 同步) :使用 Canal/Flink CDC 监听业务库 Binlog,异步同步到向量库。推荐,解耦且可靠。
- 方案 B(事务消息):本地消息表 + 定时补偿任务。
- 方案 C(pgvector 优势) :直接使用 pgvector,向量与业务数据在同一事务中,天然强一致,无同步问题。
2. 召回率监控与"黄金数据集"
- 问题:如何知道向量搜索变差了?(例如 Embedding 模型升级、索引参数误配)。
- 风险:线上无报错,但用户搜不到想要的东西,业务 silently fail。
- 解决方案 :
- 构建黄金数据集(Golden Dataset):准备 100-500 个典型查询及其期望的标准答案。
- 自动化测试:每次变更(模型升级、索引重建)前,跑一遍黄金集,计算召回率(Recall@K)。
- 阈值告警:召回率下跌超过 5% 禁止上线。
3. 内存成本与索引重建
- 问题:HNSW 索引常驻内存。数据量增长导致内存爆炸,成本不可控。
- 风险:OOM(内存溢出)导致数据库宕机。
- 解决方案 :
- 量化压缩:启用 PQ/SQ 量化,将 float32 转为 int8,内存减少 75%。
- 冷热分离:热点数据用 HNSW(内存),冷数据用 IVF(磁盘)。
- 重建策略 :向量索引删除数据性能差(尤其是 HNSW)。通常策略是标记删除(软删除),定期后台重建索引。
4. Embedding 模型漂移(Model Drift)
- 问题 :半年后,Embedding 模型升级了(如从 BERT 升级到 BGE)。新模型生成的向量与旧向量不在同一空间,无法计算距离。
- 风险:历史数据失效,需全量重刷。
- 解决方案 :
- 版本管理 :在向量表中记录
model_version字段。 - 多版本共存 :支持多列向量(
embedding_v1,embedding_v2),逐步迁移查询流量。 - 避免频繁变更:选定模型后,除非效果显著下降,否则尽量保持稳定。
- 版本管理 :在向量表中记录
5. 安全与隐私合规
- 问题:向量是否包含敏感信息?向量能否被反推还原原文?
- 风险:合规审计不通过,数据泄露。
- 解决方案 :
- 脱敏嵌入:在生成向量前,先移除 PII(个人敏感信息)。
- 权限隔离:向量数据库的权限控制需与业务系统对齐(如 pgvector 可复用 PG 的 Row Level Security)。
- 不可逆性评估:确认所选 Embedding 模型的理论不可逆性,避免存储可还原的特征向量。
6. 冷启动与流量洪峰
- 问题:服务重启后,索引需加载到内存;或突发流量导致查询队列堆积。
- 解决方案 :
- 预热机制:启动时预先加载热点索引页。
- 限流降级:在应用层对向量检索接口做 QPS 限流,避免拖垮整个数据库。
- 缓存层:对高频查询的向量结果(Query Embedding 可缓存)进行 Redis 缓存。
总结
那么今天关于向量数据库的解释就到此为止!下一集就是我们的线上的检索、增强了!
