什么是CSRF(跨站请求伪造)
CSRF (Cross-Site Request Forgery),也被称为"One-Click Attack"或"Session Riding"。简单来说,它是一种借刀杀人的攻击手法。
攻击者诱导受害者访问一个被精心构建好的恶意网页,利用受害者在其浏览器中已经等了的凭证,向目标网站发送恶意请求。因为请求是从受害者浏览器发出,且带有合法凭证,那么目标服务器就会误以为是受害者本人意图,从而执行这个请求。
CSRF的危害
它的危害取决于受害者在目标网站的权限级别和存在漏洞业务接口,常见的危害形式包括:
普通用户被强制修改绑定的邮箱、密码、密保等,未授权的资金转账、商品购买、虚拟货币消耗,以受害者名义发送推文、发送邮件等。如果是管理级别则会有进一步的危害,通畅就是攻击者可以执行目标身份在目标网站上的功能,可以执行修改、上传等等恶意操作。
CSRF产生的核心因素
如果目标网站会产生CSRF漏洞,那么一般会满足一下三点:
- 存在敏感操作:服务端内会提供一些可以改变状态的接口(比如修改密码、转账等操作),并且这个接口是允许被外部请求触发。
- 基于Cookie的会话管理:应用部分完全依赖浏览器的Cookie来识别身份,因为攻击的前提就是让受害者发送请求时,让目标可以验证其身份不产生额外操作,而Cookie就是其中的主要形式,因为当浏览器发送请求时,会自然携带本域名下的所有Cookie。
- 请求参数是可被预测的:攻击者必须要提前猜出或者指定所需请求的所有参数,如果请求中包含类似验证码、动态Token,那么往往CSRF就会失效,因为无法伪造就会导致请求被拒绝。
文艺复兴,CSRF最简单表现形式
本文先只去介绍CSRF最简单表现形式,博物馆级别,因为CSRF的实现思路是依照服务端的形式展开的,服务端是如何开展认证,如何防CSRF,那么就会针对形式对防守出现纰漏的目标实现绕过,而传统的CSRF的表现方式,早已不适用现代Web。
环境取自portswigger的免费Lab
Lab: CSRF vulnerability with no defenses
这是存在CSRF并且没有任何应对的一个Lab,你可以直观的看到CSRF是如何产生,危害又是什么:
执行过程:
首先这个Lab的目的是,将受害者的更新成一个我们想要的值,进入环境,登录账户就可以发现这个改变邮箱这个功能,我们可以尝试提交一个值,在Burp的历史记录里看具体的请求方式:
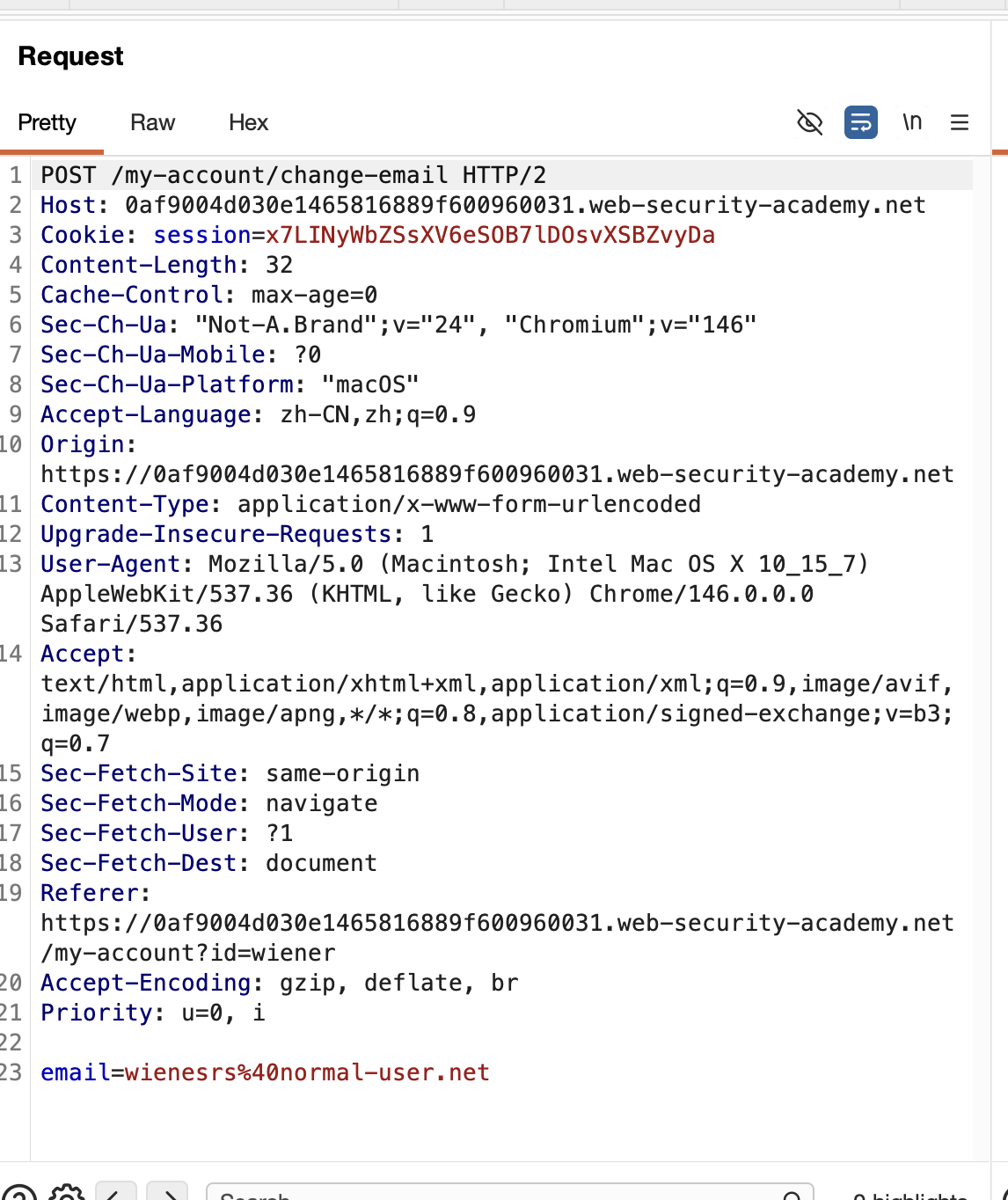
可以看到这个POST的方式的改变邮件的/my-account/change-email,只有两个有价值参数,第一是Cookie,第二是email值了,除此之外再无其他,若没有什么特殊的地方,那么这里就会出现CSRF,原因就是服务器仅仅通过cookie来验证用户身份,没有做其他任何二次验证和防护,如果我们构建一个恶意网页,比如:
javascript
<form method="POST" action="https://xxxxx/my-account/change-email">
<input type="hidden" name="email" value="anything%40123.net">
</form>
<script>
document.forms[0].submit();
</script>当任何一个登录过程原域名的访客,触发这个恶意网页,将自动去请求这个修改邮箱的,并且参数值是攻击者设定的,因为访客登录过原网站,只要cookie不过期,那么服务端就会认可这个请求,直接将访客的邮箱改为
anything%40123.net,实现CSRF,这个Lab没有任何防护,你可以很直观的看到是如何产生CSRF的。
Lab: CSRF where token validation depends on request method
这是第二个Lab,它使用最基本的的应对CSRF的方法,也就是使用CSRF_TOKEN,它的工作方式是,每当用户需要提交表单前,在用户请求提交表单的页面上,悄悄返回一个CSRF_TOKEN,它往往是唯一对应认证凭证(比如Cookie)且有时效不可预测的,当用户提交这份表单时,服务端会验证这个参数是否对应用户的凭证,如果对应则接收请求,否则就返回错误,这是最基本的CSRF的防护。
那么这个Lab的存在这样的防护,但是却出现了纰漏,当执行POST的请求时,服务端会检查csrf参数,但切换为GET请求后,就不会检查了,属于是同一个控制器的的两个Method中的GET功能没有做验证却直接调用了业务函数。
执行过程: 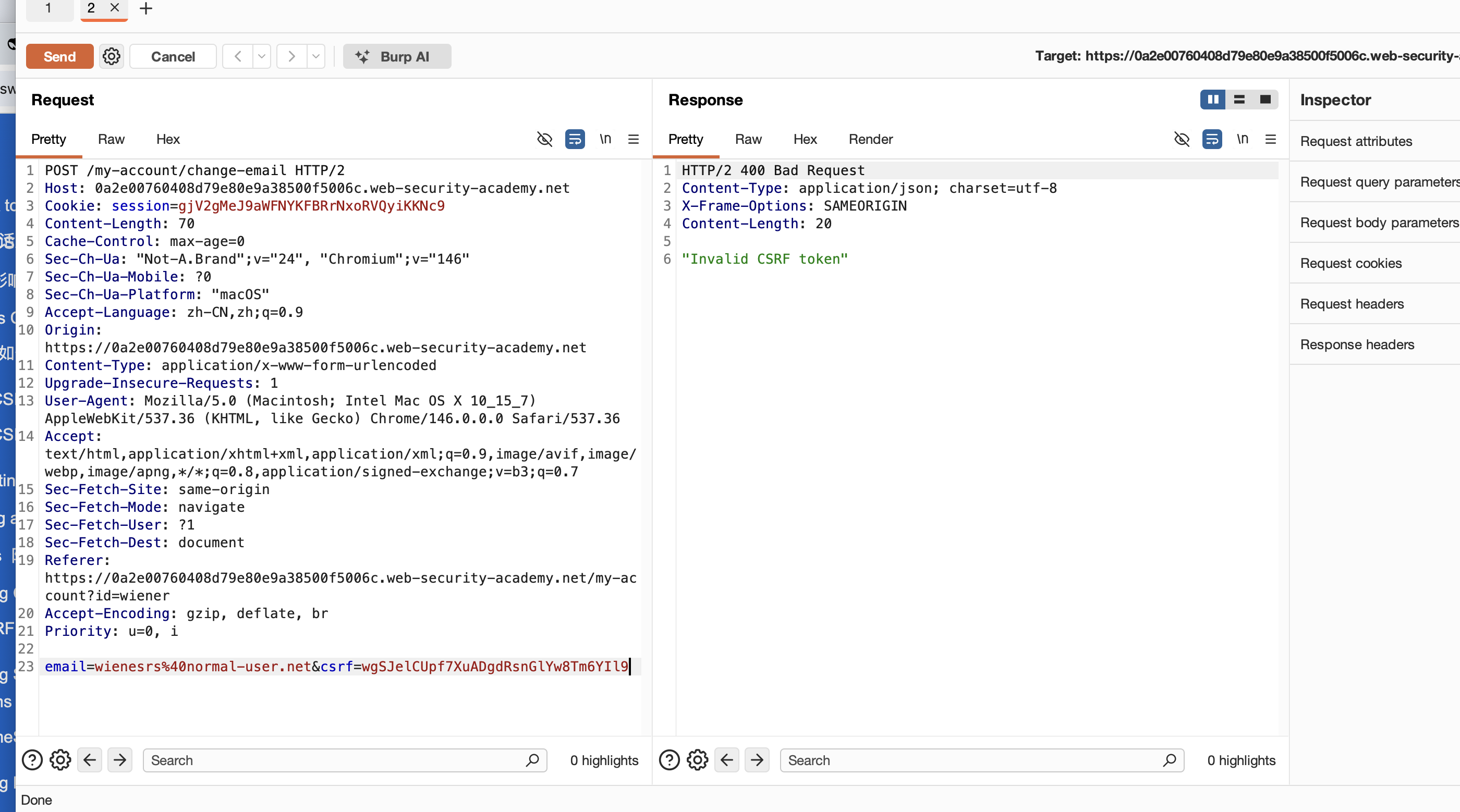
首先,当我请求这个修改时,随机填入一个csrf 参数,对方会返回CSRF token无效的字段
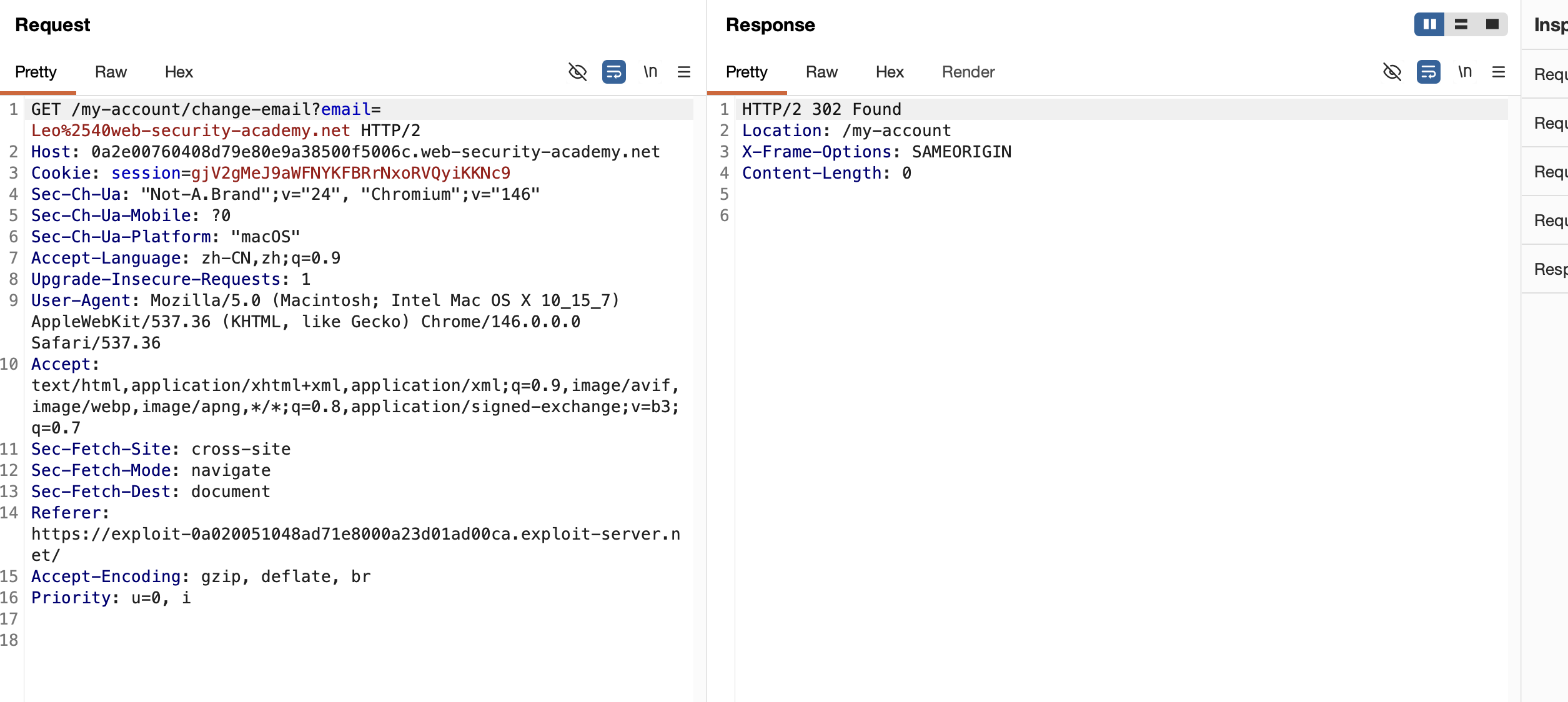
当我把请求方式改为GET方式时,直接请求就会发现绕过CSRF
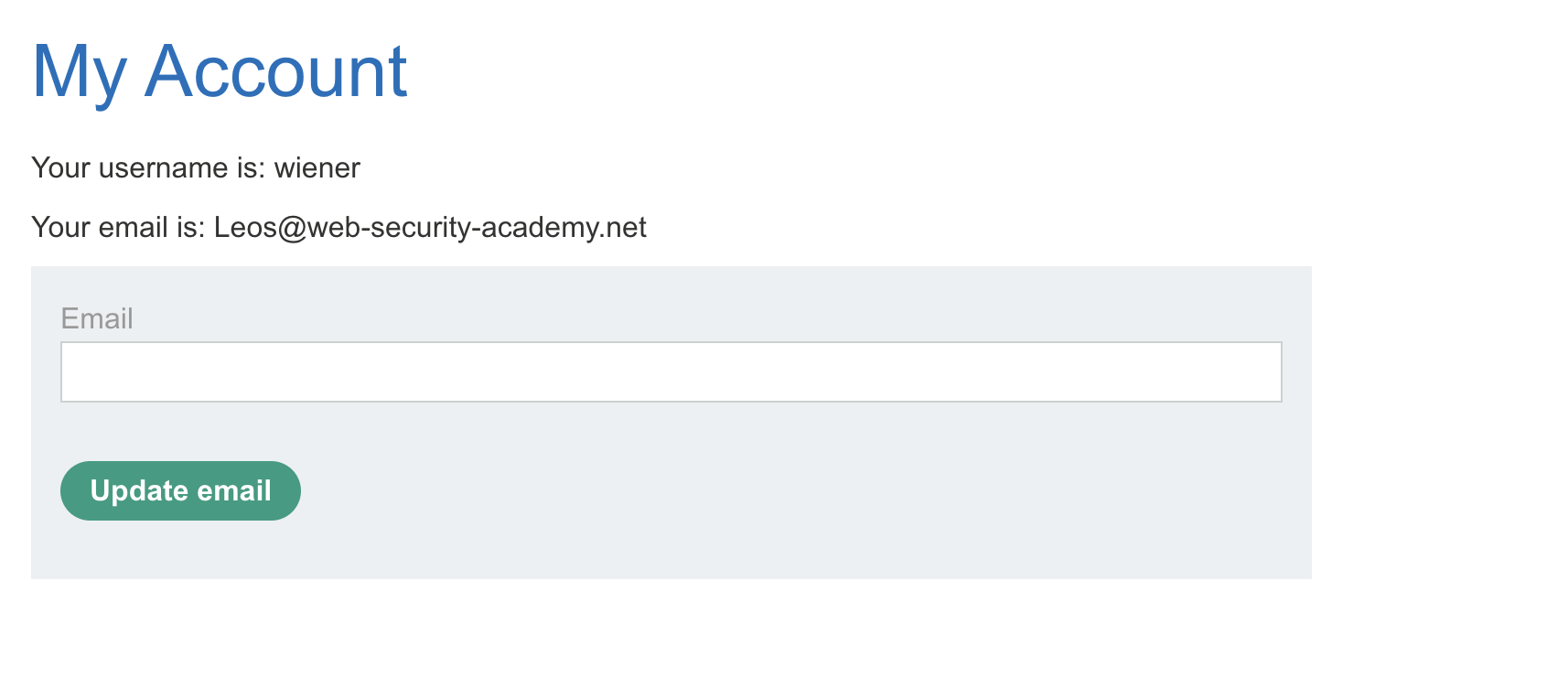
直接完成了修改邮箱的请求。

而通过编写上述这样一个恶意页面,诱导受害者访问就可以完成CSRF,我们可以将method设置为GET,并且随便给一个csrf值(这个值取决于目标检查参数的位置,如果要到验证逻辑时,那么就可以不用加,因为GET方式存在漏洞就是说明GET压根没有token的检查)
Lab: CSRF where token is not tied to user session
这个Lab呢,与上述情况类似,同样适用CSRF_TOKEN的方式来应对CSRF,但是它却没有绑定用户凭证,也就是说csrfToken是不依靠Cookie等字段生成的,并且目标服务器也仅仅只会检查Token是否合法,所以我们只需要正常获取一份csrf,就可以通过它直接构建恶意页面诱导访客访问,其实这里引出一些事情,就是传统的CSRF_Token其实是可以有效应对的,但是由于在以往的Web形式中,防CSRF是一种类认证体系,它往往脱离于整个Web认证体系外的,但是却依靠这其中的凭证或者用户的参数值等,这样就会导致未经过全面测试前,会出现很多纰漏,比如这个Lab的用户凭证不绑定CSRF_Token,任何一个合法值都会绕过这个防守,其次还有些情况依赖存在CSRF_Token就验证,如果不提交token就不验证的问题,这都体现着防CSRF是后期打的补丁,且十分不牢靠。当然现代Web框架提出了更加严谨更加合理的方式,我们通过这几个简单Lab主要认识CSRF即可,我们会在后续继续介绍更多的CSRF的表现形式和策略。
现代CSRF应对方式
伴随Web发展和转型,CSRF的应对早成体系,涵盖从浏览器底层机制到业务逻辑的多个层面。
-
现代浏览器的底线:SameSite Cookie 属性(最核心的防御)
这是目前防御 CSRF 最有效的手段之一。通过在服务端设置 Set-Cookie 时添加 SameSite 属性,直接告诉浏览器:"跨站请求时,不许带上这个 Cookie"。
- SameSite=Strict:绝对禁止跨站发送 Cookie。即便你从外部网页点击链接跳转过来,哪怕是 GET 请求也不带 Cookie(安全性最高,但可能影响用户体验)。
- SameSite=Lax:现代浏览器的默认行为。仅允许在顶级导航(如点击普通 < a> 链接跳转)且为 GET 请求时携带 Cookie。对于跨站的 POST 请求、或者通过 < img>、< script> 发起的 AJAX 请求,一律不带 Cookie。
- SameSite=None:允许所有跨站请求携带 Cookie,但必须配合 Secure 属性(仅在 HTTPS 下生效)。
-
后端防御中流砥柱:Anti-CSRF Token(同步器令牌模式)
- 原理: 用户登录后,服务端生成一个强随机的、不可预测的 Token,存储在用户的 Session 中(或与 Session 绑定),并将其下发给前端(通常隐藏在 Form 表单中或放在 meta 标签里)。
- 验证: 当用户发起 POST/PUT/DELETE 请求时,必须携带这个 Token。服务端比对请求中的 Token 和 Session 中存储的 Token 是否一致。因为攻击者无法跨域读取受害者的页面内容(受同源策略 SOP 限制),所以猜不到这个 Token,伪造的请求自然会失败。
-
前后端分离架构首选:双重提交 Cookie (Double Submit Cookie)
如果后端是无状态的(比如不使用 Session),往往会采用这种模式。
- 原理: 服务端不保存 Token。而是在用户访问时,把一个随机 Token 写到 Cookie 里,同时也写到页面的 DOM 里。前端发请求时,既要让浏览器自动带上那个 Cookie,又要通过请求体(或 Header)把 DOM 里的 Token 再传一次。
- 验证: 服务端只比对 Cookie 里的 Token 和请求参数里的 Token 是否一致。
-
API 时代的防御:自定义 HTTP Header
在使用 AJAX(如 Axios/Fetch)和 RESTful API 的现代应用中,很多时候会要求客户端附加一个自定义请求头,比如 X-Requested-With: XMLHttpRequest 或 X-CSRF-Token。
- 原理: 浏览器的同源策略(SOP)和跨域资源共享(CORS)机制规定,跨域发送自定义 Header 必须先发送 OPTIONS 预检请求。如果目标服务器没有配置允许该恶意站点的跨域请求,浏览器会直接拦截请求,从而天然防御了 CSRF。
-
辅助防御:验证 Origin 和 Referer 头
- 原理: HTTP 请求头中的 Origin 和 Referer 字段会记录请求是从哪个域名发出的。服务端可以通过检查这两个字段是否为受信任的域名(通常是本站域名)来拦截跨站请求。
- 局限性: 只能作为纵深防御的一部分,因为某些情况下出于隐私保护,浏览器可能不发送 Referer 头,且有时这些头部存在被伪造或绕过的风险。