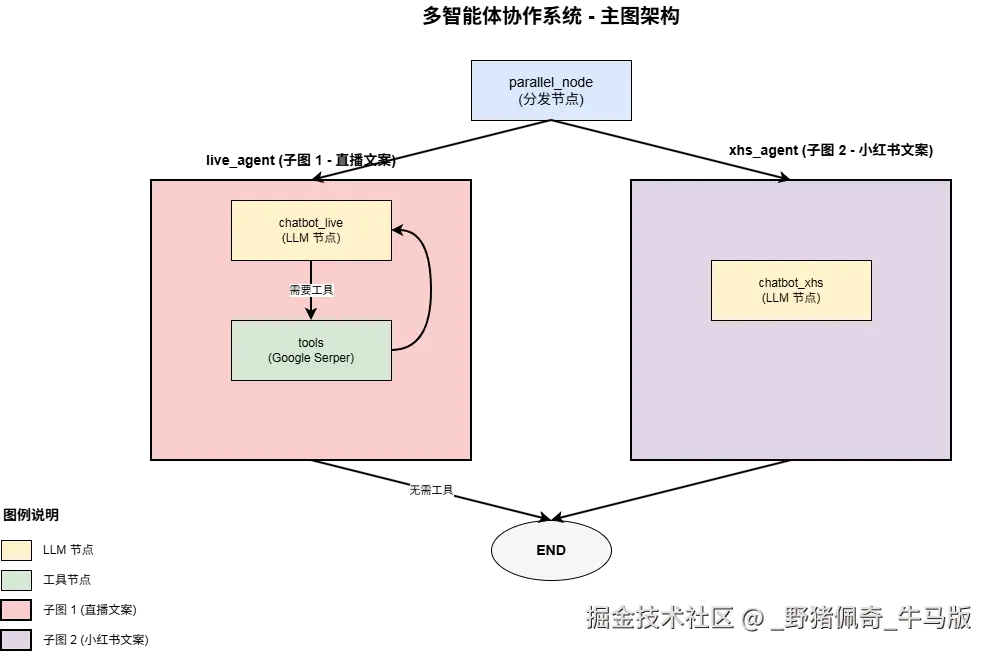
多智能体协作系统 - 使用 LangGraph 子图实现 功能:并行执行两个智能体(直播文案 + 小红书文案)
python
import os
from typing import TypedDict, Any, Annotated
import dotenv
from langchain_community.tools import GoogleSerperRun
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableConfig
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, add_messages
from langgraph.prebuilt import ToolNode, tools_condition
from pydantic.v1 import Field, BaseModel
dotenv.load_dotenv()
# ==================== 初始化 LLM ====================
llm = ChatOpenAI(
model="qwen3-max-2026-01-23",
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_API_BASE_URL")
)
# ==================== 工具定义 ====================
class GoogleSerperArgsSchema(BaseModel):
query: str = Field(description="执行谷歌搜索的查询语句")
google_serper = GoogleSerperRun(
api_wrapper=GoogleSerperAPIWrapper(),
args_schema=GoogleSerperArgsSchema,
)
# ==================== 状态归约函数 ====================
def reduce_str(left: str | None, right: str | None) -> str:
"""
字符串归约函数:用于合并状态字段
逻辑:如果新值存在且非空则使用新值,否则保留旧值
!! 如果为空 传递给llm 会造成无限循环
"""
if right is not None and right != "":
return right
return left
# ==================== 状态定义 ====================
class AgentState(TypedDict):
"""主图状态 - 包含所有共享数据"""
query: Annotated[str, reduce_str] # 原始问题/商品名
live_content: Annotated[str, reduce_str] # 直播文案
xhs_content: Annotated[str, reduce_str] # 小红书文案
messages: Annotated[list, add_messages] # 对话历史(自动追加消息)
class LiveAgentState(TypedDict):
"""直播智能体状态 - 继承主图所有字段 + messages"""
query: Annotated[str, reduce_str]
live_content: Annotated[str, reduce_str]
xhs_content: Annotated[str, reduce_str]
messages: Annotated[list, add_messages]
class XHSAgentState(TypedDict):
"""小红书智能体状态 - 继承主图所有字段 + messages"""
query: Annotated[str, reduce_str]
live_content: Annotated[str, reduce_str]
xhs_content: Annotated[str, reduce_str]
messages: Annotated[list, add_messages]
# ==================== 子图 1: 直播文案智能体 ====================
def chatbot_live(state: LiveAgentState, config: RunnableConfig) -> Any:
"""
直播文案生成节点
功能:根据商品名生成直播带货脚本文案,支持调用搜索工具
"""
# 创建提示模板 + 绑定工具
prompt = ChatPromptTemplate.from_messages([
(
"system",
"你是一个拥有 10 年经验的直播文案专家,请根据用户提供的产品整理一篇直播带货脚本文案,如果在你的知识库内找不到关于该产品的信息,可以使用搜索工具。"
),
("human", "{query}"),
("placeholder", "{chat_history}"),
])
chain = prompt | llm.bind_tools([google_serper])
# 调用链生成回复
ai_message = chain.invoke({"query": state["query"], "chat_history": state["messages"]})
# 返回更新的状态
return {
"messages": [ai_message], # 追加到消息历史
"live_content": ai_message.content, # 更新直播文案
}
# 创建子图 1 结构
live_agent_graph = StateGraph(LiveAgentState)
# 添加节点
live_agent_graph.add_node("chatbot_live", chatbot_live) # LLM 聊天节点
live_agent_graph.add_node("tools", ToolNode([google_serper])) # 工具执行节点
# 添加边(控制流)
live_agent_graph.set_entry_point("chatbot_live") # 入口点
live_agent_graph.add_conditional_edges(
"chatbot_live",
tools_condition # 动态路由:如果 LLM 决定调用工具 → tools 节点,否则 → 结束
)
live_agent_graph.add_edge("tools", "chatbot_live") # 工具执行后返回 LLM
"""
子图 1 流程:
┌─────────┐
│ START │
└────┬────┘
│
▼
┌─────────────┐
│ chatbot_live│ ←───┐
└──────┬──────┘ │
│ │
├─[需要工具]─→│ tools │
│ └──────┘
│
└─[无需工具]─→ END
"""
# ==================== 子图 2: 小红书文案智能体 ====================
def chatbot_xhs(state: XHSAgentState, config: RunnableConfig) -> Any:
"""
小红书文案生成节点
功能:根据商品名生成小红书笔记文案(风格活泼,带 emoji)
"""
# 创建提示模板 + 解析器
prompt = ChatPromptTemplate.from_messages([
("system",
"你是一个小红书文案大师,请根据用户传递的商品名,生成一篇关于该商品的小红书笔记文案,注意风格活泼,多使用 emoji 表情。"),
("human", "{query}"),
])
chain = prompt | llm | StrOutputParser()
# 调用链生成文案
return {"xhs_content": chain.invoke({"query": state["query"]})}
# 创建子图 2 结构
xhs_agent_graph = StateGraph(XHSAgentState)
# 添加节点
xhs_agent_graph.add_node("chatbot_xhs", chatbot_xhs)
# 添加边
xhs_agent_graph.set_entry_point("chatbot_xhs") # 入口
xhs_agent_graph.set_finish_point("chatbot_xhs") # 出口
子图 2 流程:
┌─────────┐
│ START │
└────┬────┘
│
▼
┌────────────┐
│ chatbot_xhs│
└──────┬─────┘
│
▼
END
# ==================== 主图:编排两个子图 ====================
def parallel_node(state: AgentState, config: RunnableConfig) -> Any:
"""
并行分发节点
功能:透传状态,将请求分发给两个子智能体
"""
return state
# 创建主图结构
agent_graph = StateGraph(AgentState)
# 添加节点(关键:添加的是编译后的子图)
agent_graph.add_node("parallel_node", parallel_node) # 分发节点
agent_graph.add_node("live_agent", live_agent_graph.compile()) # 直播智能体(子图)
agent_graph.add_node("xhs_agent", xhs_agent_graph.compile()) # 小红书智能体(子图)
# 添加边(控制流)
agent_graph.set_entry_point("parallel_node") # 从分发节点开始
agent_graph.add_edge("parallel_node", "live_agent") # 并行执行直播智能体
agent_graph.add_edge("parallel_node", "xhs_agent") # 并行执行小红书智能体
# 设置结束点(两个子图都完成后结束)
agent_graph.set_finish_point("live_agent")
agent_graph.set_finish_point("xhs_agent")
# 编译主图
agent = agent_graph.compile()
# 打印图的 ASCII 结构
print(agent.get_graph().print_ascii())
# 执行并获取结果
print("\n=== 执行结果 ===")
result = agent.invoke({"query": "潮汕牛肉丸"})
print(f"商品:{result['query']}")
print(f"\n直播文案:\n{result['live_content']}")
print(f"\n小红书文案:\n{result['xhs_content']}")