论文总结
1、有开源代码, https://github.com/shicaiwei123/UDML
2、动态多模态融合是指根据每个模态(比如图像、声音)当前的质量,动态调整它们在融合时的权重。本文针对两个问题:
1)不确定性估计不准:现有方法在"噪声很小"或"噪声极大"时,都无法准确判断模态质量。小噪声时察觉不到变化,大噪声时仍给坏模态不小权重。
2)双重抑制问题:模型天然偏好容易学的模态(比如声音比图像好训练)。当一个难学的模态(如图像)恰好又受噪声影响时,它会被"两次压制"------先被优化过程压制,又被动态融合的权重再压一次,导致动态融合效果还不如静态融合
提出了优化策略:
1)噪声感知不确定性估计器
主动向数据中加入可控噪声,让模型学会从特征中预测噪声强度,从而在极低或极高噪声下都能准确判断模态质量。
2)模态依赖计算器
通过"删掉一个模态"看预测结果的变化,量化模型对该模态的真实依赖程度。然后用这个依赖系数去"纠正"动态权重,避免难学模态被双重压制。
3、使用了渐进优化策略,简单来说就是模型刚训练的时候,优化主要任务(如分类)并学习稳定的多模表示。在主编码器稳定后,输入引入受控扰动以训练噪声感知不确定性估计器。
摘要
传统的多模态方法通常假设静态模态性,这限制了它们在动态现实场景中的适应性。因此,提出了动力多模态方法来评估模态质量并相应调整其贡献。然而,它们通常依赖经验指标,当噪声水平极低或极高时,无法衡量模态质量。此外,现有方法通常假设每种模态的初始贡献相同,忽视了内在的模态依赖偏差。因此,难学模式将受到双重惩罚,动力学聚变的性能可能低于静态聚变。为应对这些挑战,我们提出了无偏动态多模态学习(UDML)框架。具体来说,我们引入了一种噪声感知不确定性估计器,它向模态数据添加受控噪声,并从模态特征预测噪声强度。这迫使模型学习特征损坏与噪声水平之间的清晰对应关系,从而在低噪声和高噪声条件下都能准确测量不确定性。此外,我们通过模态退出量化多模态网络中固有的模态依赖偏差,并将其纳入权重机制中。这消除了对难以学习模态的双重抑制效应。在多样化多模态基准任务中进行的大量实验验证了所提UDML的有效性、多样性和可推广性。代码可在 https://github.com/shicaiwei123/UDML 获取。
引言
多模态学习在多种视觉任务中取得了显著进展,包括分类12, 22, 39、物体检测18, 30, 52和分割3, 14, 28。大多数现有的多模态学习方法假设每种模态的质量是静态的,其中一种模态始终比其他模态更强。然而,这一假设在现实场景中常常失效。例如,RGB模态通常提供比红外模态在白天使用,但夜间可靠性大幅下降,而红外模式在低光条件下常常优于RGB20。因此,开发能够处理动态数据质量的多模态学习方法至关重要。为了应对多模态数据的动态质量,提出了多种方法来评估模态可靠性并相应调整其贡献。这些方法大致可分为两种范式:基于先验的方法9, 20和基于不确定性的方法8, 11, 16, 47。基于先验的方法利用人类知识或经验来估算模态质量。例如,激光雷达传感器在夜间优先使用,而自动驾驶中白天则优先使用摄像头。虽然直观,但这些方法通常缺乏普遍适用性,尤其是在复杂或不可预见的环境中。因此,基于不确定性的方法近年来因其更具原则性和可推广性的解决方案而受到关注。通过利用概率建模或信息论测度,这些方法动态调整模态贡献,为可靠的多模态积分提供了更稳固的基础。尽管动态多模态学习取得了进步,依然存在ING方法仍存在两个主要局限。首先,大多数现有的不确定性估计方法依赖经验指标,如能量评分47和概率嵌入8,16,当噪声水平过低或过高时,未能评估模态质量。以广泛使用的概率嵌入(PE)为例(见图1(a)),我们观察到PE无法检测低强度噪声(σ < 4),导致模态权重僵化。此外,即使在极端破坏(σ >10)下,PE仍然给予被破坏模态相当的权重,而非忽视它。其次,现有方法通常假设所有模态的初始贡献相同,忽略了模态依赖偏差。实际上,多模态模型更依赖易于学习的模态来做决策17, 27。因此,难以学习的模态将因优化偏差和高不确定性而遭受双重惩罚。因此,如图1(b)所示,动态聚变的性能可能不如稳定聚变。 为此,我们提出了一种无偏动态多模态学习(UDML),这是一个帮助多模态学习并实现动态数据质量的通用框架。UDML由两个关键组成部分:一个噪声感知不确定性估计器和一个模态依赖计算器。噪声感知不确定性估计器向模态数据添加受控噪声,并根据模态特征预测噪声强度,实现低噪声和高噪声区间的准确估计。为进一步确保对未见噪声类型的鲁棒性,我们引入了概率表示技术,将每种模态映射到一个分布中,以将噪声与语义内容解耦。具体来说,均值编码语义信息,方差反映噪声特性。估计器随后直接从方差中推导噪声强度。模态依赖计算器采用模态脱离来量化输出对每种模态的固有依赖。该依赖度随后用于重新校准模态权重,平衡其贡献并减轻双重抑制效应。值得注意的是,UDML对架构无关,所有组件仅基于模态表示,确保在不同模型和融合方法间的通用性。最后,我们引入了一种渐进优化策略,使多模表示、噪声估计和主要任务能够在标准训练计划内同步学习。对多任务和数据集的广泛实验验证了UDML持续提升多模态性能,展示了其鲁棒性和多样性。
• 我们揭示了现有基于不确定性的估计量的偏见,这些估计对轻微的退化不敏感,且对高度受损的模态赋予不可忽视的权重。这限制了动态聚变的稳健性。
• 我们揭示了现有动态多模态学习中的双重抑制效应,其中难以学习的模态因优化偏差和高不确定性而受到双重惩罚。这可能导致动态聚变表现不如静态聚变。
• 我们提出了无偏动态多模态学习(UDML),这是一种结构无关框架,明确解决动态融合中的质量估计偏差和对偶抑制偏差,共同确保稳健的动态多模态学习。
• 对多种多模态基准测试进行了大量实验,证明UDML在各种任务和场景下持续提升性能。
相关工作
动态多模态学习
研究人员提出了一系列动态多模融合算法,可分为两类:基于先验的方法9, 20和基于不确定性的方法8, 11, 16, 47。基于先验的融合方法根据人类知识分配模态权重。例如,在正常光照条件下,RGB模态通常比红外(IR)模态包含更多信息。然而,在低光环境下,这种关系可能会逆转,因为红外成像变得更加可靠。为此,Guan等人9引入了一个光照感知融合模块,能根据场景光强动态调整模态贡献。除了环境因素外,网络特征的内在特性也能指导聚变决策。例如,Li等人20利用批量归一化中的缩放因子作为特征选择指标,调整不同模态的贡献。基于不确定性的融合方法根据预测不确定性调整模态贡献,提供比先验方法更理论化的方法。常用的不确定度指标是通过分类器logits 11, 35, 36, 38计算的预测熵。然而,由于错误的预测仍可能获得高置信度分数,仅依赖分类器输出可能导致过度自信。因此,利用多元高斯分布进行特征空间建模,通过分析特征方差,更准确地捕捉模态不确定性。该方法在情感识别16, 31, 37和图像-文本分类8, 47中得到了广泛应用。尽管取得了成功,大多数现有的不确定性估计方法仍依赖实证启发式,未能在噪声水平过低或过高时评估模态质量。更重要的是,当前研究假设每种模态的初始贡献相等。这忽略了由优化偏差引起的模态依赖性失衡。因此,动态聚变的性能可能不如稳定聚变。
不平衡多模态学习
最新研究指出,即使信息量增加,大多数多模态学习方法也未能显著提升表现 6, 7, 27, 32, 43, 48。Wang 等人32观察到不同模态表现出不同的收敛速率,导致多模态模型无法超越其单模态模型。Peng 等人27进一步表明,性能优越的模态往往主导优化过程,导致较弱模态的特征学习不足。为此,开发了多种方法以增强传统多模态学习框架,大致可分为两类:梯度调制和交替优化。梯度调制7, 27, 43旨在扩大多模态学习中较弱模态的梯度,平衡不同模态编码器的优化。交替优化方法15, 40, 42, 48将传统的联合多模态学习过程转变为交替单模态学习过程,以直接最小化模态间干扰。然而,这些方法仅解决了训练阶段模态编码器的欠优化问题,并未纠正模型在推断过程中对每种模态的依赖偏差。
方法
重新分析动态多模态学习
记谱法。在一般情况下,我们考虑两个输入模态,记作m1和m2。数据集表示为 D = {xm1 i , xm2 i , yi}i=1,2,...,N,其中 y ∈ {1, 2, . . . , K} 表示类标签,K 表示类别总数。然后我们使用两个编码器φ1(θ1, ·)和φ2(θ2, ·)来提取特征,其中θ1和θ2分别代表各自编码器的参数。特征表示为 zm1 i = φ1(θ1, xm1 i ) 和 zm2 i = φ2(θ2, xm2 i)。两个编码器的表示通常通过特定的融合方法融合,这是多模态学习中的常见做法5, 13。我们将融合模记为φτ(θτ, ·),其中θτ代表该模的参数。最终分类由一个线性分类器执行,参数为W ∈RM×(d1+d2),b∈RM ,输入习的模型输出可表示如下:
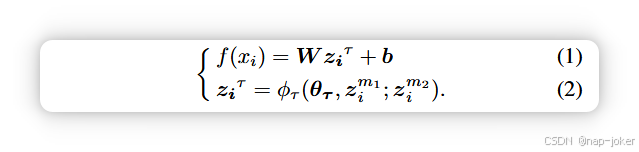
动态多模态学习(DML)。DML考虑了zm1 i和zm2 i的容量随输入样本变化的问题。因此,多模态模型应根据各模态的表示能力动态调整决策依赖性。因此,DML的融合表示可以写成:ziτ−dml = φτ(θτ, M ∗wim1 ∗zim1, M ∗wim2 ∗zim2), (3),其中wim1 + wim2 = 1;M 是模态数量,用于补偿权重对振幅的抑制。这里,wim1 wim2 与模态 m1 和 m2 的表示容量成正比,使得低容量模态的关注度较低。因此,准确衡量模态能力是DML的关键。大多数现有方法通过统计不确定性度量s(.),如能量分数47和概率嵌入29来量化模态容量,
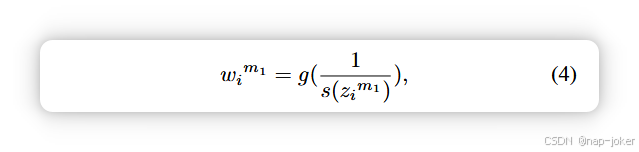
其中 g(.) 是归一化算符。不确定性降低意味着容量更大8, 47。限制分析。现有方法本质上假设s(z)与模态不确定性之间存在稳定且单调的关系。但实际上,这一假设并不成立。在低噪声下,s(z)对细微的质量差异不敏感,导致权重几乎固定。在高噪声下,表示坍塌会扭曲s(z),产生膨胀或误导性的不确定性估计。以广泛使用的概率嵌入(PE)为例(见图1(a)),PE无法检测低强度噪声(σ <4),导致模态加权僵化。更关键的是,即使在极端破坏(σ >10)下,PE仍会给予被破坏模态较大的权重,而非忽视它。此外,现有方法通常假设所有模态的初始贡献相同,忽视了内在依赖偏差。具体来说,我们记模态 m 的内在依赖性为 αm,满足 P m αm = M 。我们可以将ziτ−dml重写如下:
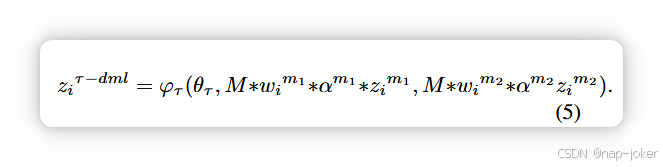
理想情况下,在平衡多模系统中,αm1 = αm² = 1。然而,多模态模型往往更多依赖易于学习的模态来做决策17, 27,导致依赖性不平衡。以视听任务为例,假设音频模态为m1,视觉模态为m2,我们可以得到以下不等式:
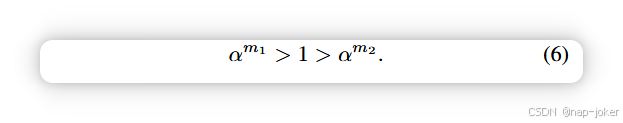
这是因为音频模态比视觉模态更容易学习17, 27。当视觉模态具有高不确定性时,这将导致双重抑制问题。难以学习的视觉模态首先被优化偏差(低 αm²)抑制,随后又被基于不确定性的重权重(低 wim²)进一步降权。因此,如图1(b)所示,动态聚变的性能可能不如静态聚变。
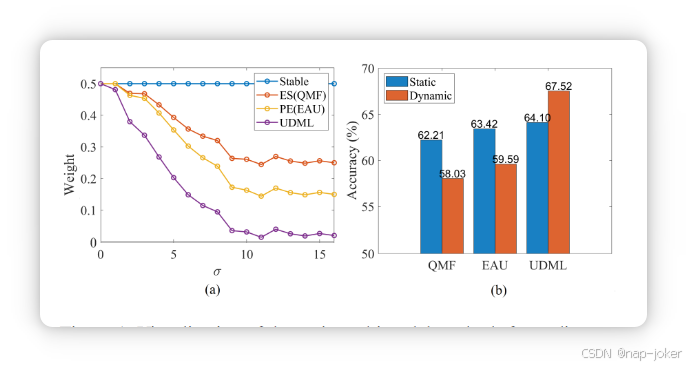
图1。在CREMA-D数据集上可视化的动态多模态视听分类方法。(a) 通过不同的不确定性估计方法获得的视觉加权系数,如能量分数(ES)47和概率嵌入(PE)8,以及拟议的UDML算法,因为不同水平的噪声(σ)被注入视觉模态。(b) 在静态和动态加权下,当噪声(σ = 5)注入视觉模态时,不同方法的表现比较。
无偏差的动态多模态学习
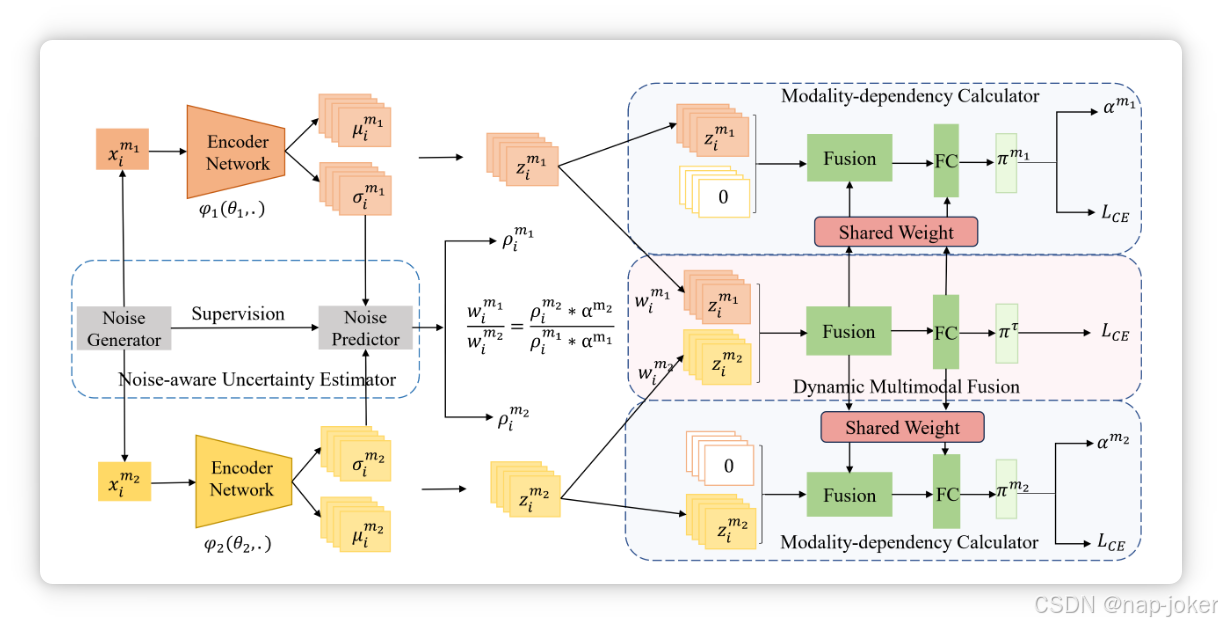
图2。无偏动态多模融合的框架。它由两部分组成:1)噪声感知不确定性估计器,用于衡量模态质量;2)模态依赖计算器,用于量化模型对每种模态的依赖性。
因此,传统的动态多模态学习存在不确定性估计和双重抑制的偏倚。为克服这些挑战,我们提出了一个无偏动态多模态学习框架。如图2所示,它由两个关键组成部分组成:一个噪声感知不确定性估计器用于量化模态不确定性(即ρim1和ρim2),以及一个模态依赖计算器用于量化模态对输出的影响(即αm1和αm2)。那么我们可以得到无偏权重wim1, wim2,具体如下:
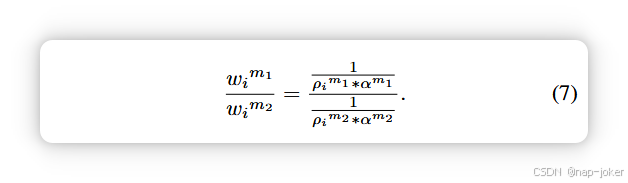
除了传统的动态多模态学习外,无偏权重还考虑了每种模态的模态依赖偏差,避免了双重抑制的问题。最后,由于多模表示、不确定性估计和依赖计算器的联合训练可能不稳定,我们设计了一种渐进优化策略以确保收敛。
噪声感知不确定性估计器
现有基于不确定性的方法常常无法评估噪声水平过低或过高的模态质量。为此,我们引入了一种噪声感知不确定性估计器,通过受控扰动学习预测每种模态的内在噪声强度。以模态m1为例,设p(σ)表示用于扰动的离散噪声水平集合。对于每个样本xim1和噪声水平σ ∼ p(σ),我们绘制ε ∼ N (0, σ2I) 的扰动,并监督估计器E(·)来预测标量强度σ。培训目标是
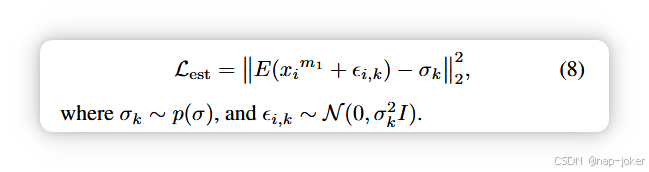
这种表述迫使模型学习特征损坏与噪声水平之间的明确对应关系,从而在低噪声和高噪声条件下都能准确测量不确定性。为避免对注入扰动的过度拟合并提高对未见噪声类型的鲁棒性,我们不直接从原始扰动输入 x + ε 估算噪声强度。相反,我们采用一种概率表示方式,将语义内容和噪声特性分开。具体来说,每个模态输入都被编码为高斯分布表示:
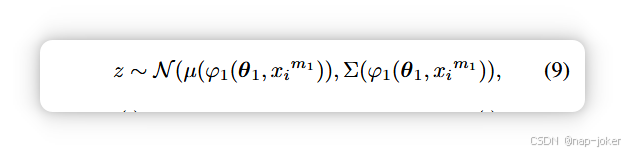
其中μ(.)捕捉语义信息,Σ(.)表示不确定性。此时,噪声估计器接收的是方差项,而非原始信号:
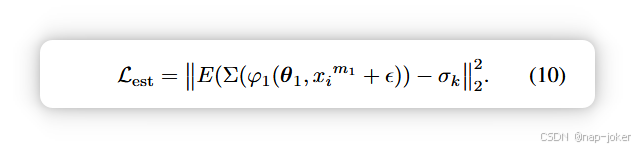
这种设计确保估计器能够从内在的分布不确定性中推断噪声强度,而非依赖低层像素畸变,从而提升对多样噪声模式的推广能力
那么推断不确定性定义如下: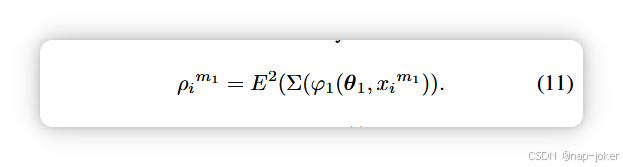
实际上,估计器E(·)作为轻量级两层MLP操作实现,其计算开销可忽略不计,同时具备强的鲁棒性和噪声级校准能力。
模态依赖计算器
为了量化每种模态对最终预测的贡献,模态依赖计算器测量模型预测对去除每个模态的敏感度。核心思想是,如果放弃某种模态导致预测变化更大,模型就更多依赖该模态。具体来说,设πτ表示所有模态的融合logit输出,πm²(πm1)是丢弃模态m1(m2)时得到的logit。量化每种模态对最终预测贡献的依赖评分dm1和dm2计算为:

其中 M=2,表示模态的数量。αm1 和 αm2 反映了每种模态的相对重要性,可用于自适应地重新加权聚变模块中的模态特征。该机制使模型能够减轻由初始依赖偏差和基于不确定性的权重引起的双重抑制效应,确保多模积分更加平衡和稳健。值得注意的是,模态脱落变体重复使用与完整多模分支相同的融合和分类模。不创建额外参数或网络副本。因此,模态依赖计算引入的开销可忽略不计。
渐进优化策略
为了有效训练UDML框架而不引发多个目标之间的梯度冲突,我们引入了一种渐进式优化策略。核心理念是逐步融入不同的学习目标,同时保持主要任务的稳定性。具体来说,训练分为两个阶段:多模态表示预训练和噪声感知训练。 第一阶段:多模态表示预训练。模型首先在干净、未受干扰的数据上训练,以优化主要任务(如分类)并学习稳定的多模表示。该阶段的损失定义如下:Ltotal = Ltask + Luni,(14),其中Ltask = LCE(f(习习),y表示当前任务的多模损失;Luni = LCE(f (xim1), y) + LCE(f (xim2), y) 表示模态依赖性计算器的单峰损失。 第二阶段:噪音感知训练。在主编码器稳定后,输入引入受控扰动以训练噪声感知不确定性估计器。该阶段的损失定义如下:Ltotal = Ltask + Luni + Lest。(15)重要的是,噪声估计损失的梯度被阻挡到模态编码器中,防止与主任务优化的冲突,避免性能下降。这一渐进方案使UDML框架能够在标准训练计划内共同学习多模表示、噪声估计和主要任务,同时确保稳定收敛和稳健的任务性能。
实验
实验配置
数据集。我们对五个多模态基准进行广泛评估,涵盖多种模态组合。具体来说,CMU-MOSI 45 和 CMU-MOSEI 46 是包含文本、视觉和音频模态的三模态情感分析数据集。MVSA-Single 25 是一个用于多模态情感分析的双峰图像-文本数据集。CREMA-D 2 和 Kinetics-Sounds (KS) 1 分别为情感识别和动作理解提供双峰视听数据。这组多样化的数据集使我们能够在异构模态配置下全面验证方法。 实施细节。对于三模态视频数据集CMU-MOSI和CMU-MOSEI,我们采用了与以往动态多模态学习相同的特征提取器8, 47:视觉用FACET,声学用COVAREP,文本用BERT。对于图像-文本数据集MVSA-Single,我们也采用了与之前相同的特征提取器8, 47,RGB图像使用ResNet-152,文本输入使用BERT。所有模型均采用Adam进行优化,初始学习率为1×10⁻⁻5,迷你批次规模为16,我们应用了"平台减少"调度器进行学习率调整。对于CREMA-D和Kinetics-Sounds数据集,我们采用ResNet18作为骨干编码器,这与之前的研究一致7, 27。对于CREMA-D数据集,从每个视频片段中选取一帧并调整大小为224×244作为视觉输入,而对应的音频则通过librosa24转换为大小为257×299的频谱图。在 Kinetics-Sounds 数据集中,从每个视频片段均匀采样三帧,并调整为 224×224 以获取视觉输入。整个音频数据被转换为一个维度为257×1,004的频谱图。训练采用与之前工作7, 27一致的配置,包括64个小批量大小、动量设为0.9的SGD优化器、学习率1e-3,权重衰减1e-4。评估指标。对于MVSA-Single、CREMA-D和Kinetics-Sounds的分类任务,我们报告准确率(Acc)和F1分数。对于CMU-MOSI和CMU-MOSEI中的回归式情感分析任务,我们遵循先前研究8, 47,报告7类准确率(Acc7)、F1分数和皮尔逊相关系数(Corr)。比较设置。我们将UDML与现有的动力多模态学习方法在包括MIB 51、HMA 23、MIM 10、GCNet 4、ConFEDE 44、DiC-MoR 34、DMD 21和QMF 47中进行比较。此外,我们还与近期的SOTA方法进行了公平比较,包括EAU 8和LDDU 16。特别地,类似于对应方法EAU 8,我们在噪声数据集上评估该方法以观察模型的稳健性。值得注意的是,尽管UDML需要两阶段优化过程,但训练纪元总数与现有方法一致,确保了公平的比较。具体来说,第一阶段持续一半的整个纪元,第二阶段持续剩余的一半。
实验结果
表1。在MVSA-Single、CREMA-D和KineticsSounds数据集上,不同方法在多模态分类任务上的性能比较。
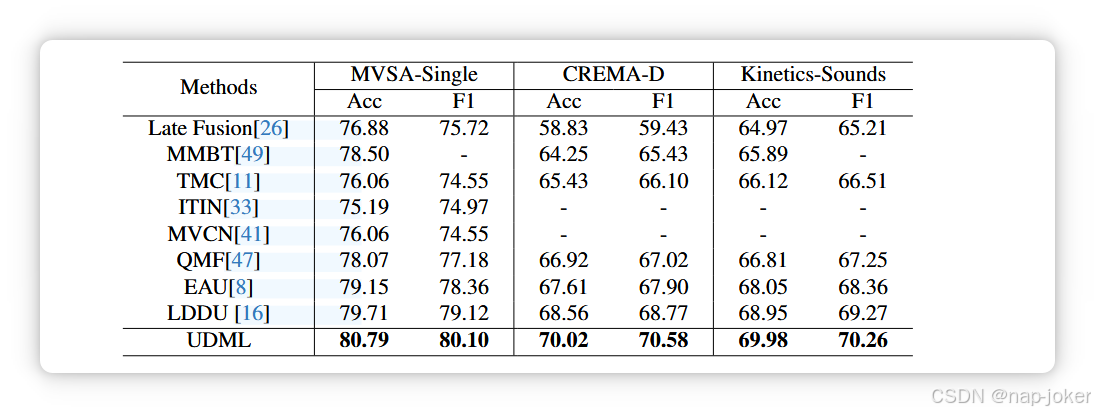
表2。CMU-MOSI 和 CMU-MOSEI 数据集上多模态回归任务不同方法的性能比较。
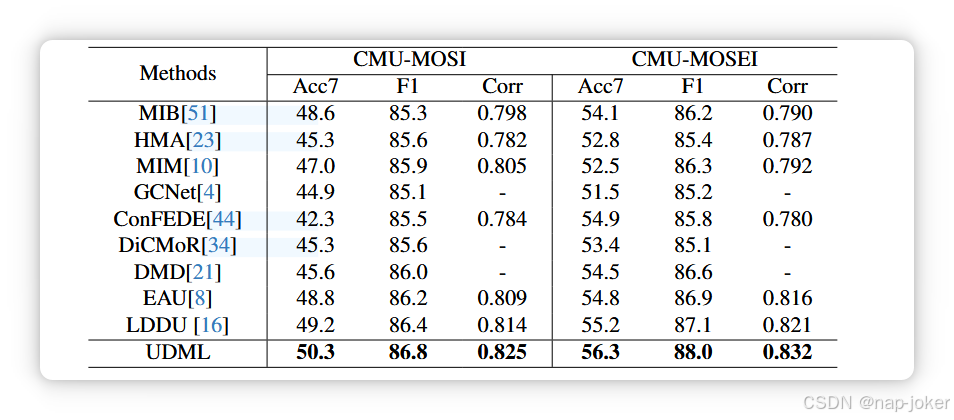
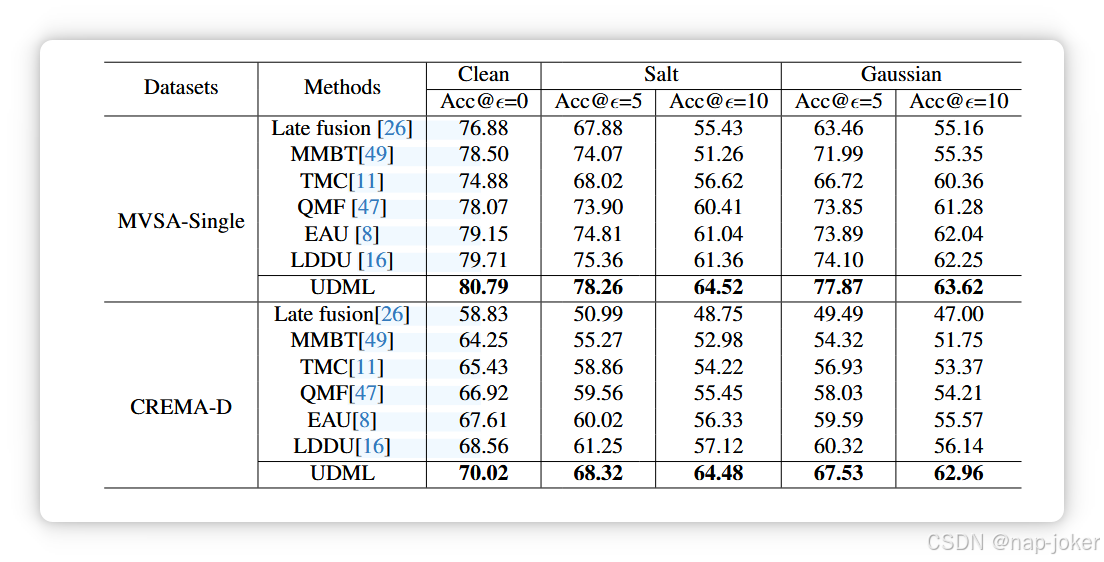
多模态分类任务的表现与比较。表1报告了我们提出的UDML方法与MVSA-Single、CREMA-D和KineticsSounds数据集上一系列基线的多模态识别结果。如图所示,UDML在所有数据集中始终保持最佳性能,优于静态融合方法和动态融合方法。特别是与最新最先进的LDDU方法相比,UDML在所有数据集上至少实现了1%的绝对改进。这些结果凸显了UDML在动态多模态融合中的有效性。 多模回归任务的性能与比较。表2展示了UDML及其竞争对手在CMU-MOSI和CMU-MOSEI数据集上的成果用于多模态回归任务。UDML在所有指标和两个数据集上都实现了最佳性能。具体来说,在CMU-MOSI上,UDML获得了50.3%的Acc7、86.8%的F1和0.825的Corr,优于以往的代表性方法如EAU和LDDU。同样,在CMUMOSEI上,UDML实现了56.3%的Acc7,88.0%的F1,0.832的Corr,显示出较现有方法持续提升。值得注意的是,UDML在小规模(MOSI)和大规模(MOSEI)数据集上均保持强劲表现,展现出多模情感回归的鲁棒性和泛化性。 噪声多模态数据集的性能与比较。为评估UDML处理数据噪声的有效性,我们遵循QMF 47,并在50%的多模样本被不同强度的盐或高斯噪声破坏时,进行更多评估。如表3所示,随着噪声强度的增加,所有方法的性能都会下降。然而,UDML在MVSA-Single和CREMA-D的所有噪声设置下始终保持最佳性能。与现有动态融合方法(如EAU、LDDU)相比,UDML在噪声强度增加时性能下降显著减少,展现出对模态破坏的强鲁棒性。这一改进得益于噪声感知不确定性估计器提供了校准且噪声无关的不确定性估计,从而实现了对严重受损模态的可靠降权。重要的是,尽管噪声估计器仅使用高斯扰动训练,UDML也能稳健地推广到盐噪声,确认估计器不会过度拟合噪声类型,而是学习一种噪声无关的污染度量。这种交叉噪声泛化能力表明所提出的基于方差的不确定性模Eling成功捕捉了不同噪声分布中共享的普遍污染线索。此外,CREMA-D的改善尤为显著。这是因为CREMA-D表现出较大的模态偏置,音频模态主导优化,且对logit输出贡献较大。传统的动态融合策略在存在噪声时进一步放大了这种偏置,导致视觉模态的双重抑制。相比之下,我们的依赖重组机制通过纠正模态贡献的偏移,明确抵消了这种不平衡,确保两种模态都能有效利用。因此,UDML在多模态协作方面实现了更稳定和卓越的表现,尤其是在模态不对称的场景下
表3。当50%的模态分别存在盐噪声和高斯噪声时,不同方法的性能比较。噪声的平均值和方差分别为0和ε。
消融实验
表4。当50%的模态存在高斯噪声(ε = 5)时,UDML方法的消融。我们报告了完整UDML结果(全全)、无噪声感知不确定性估计器UDML结果(-NUE)、无模态依赖计算器的UDML结果(-MC)以及无渐进优化策略(POS)的UDML结果。
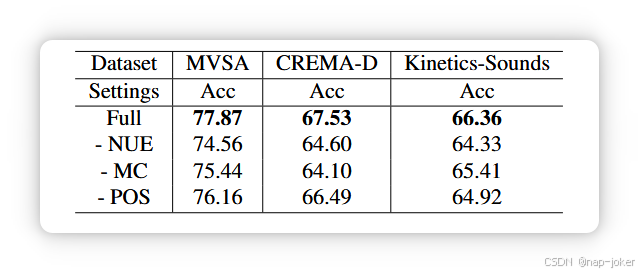
UDML的消融研究。我们开展实验,研究噪声感知不确定性估计器(NUE)、模态依赖计算器(MC)的影响,以及UDML性能上的渐进优化策略(POS)。如表4所示,移除任何组件会导致性能下降,证实了每个部件的必要性。排除噪声感知不确定性估计器(--NUE)显著降低准确率(例如MVSA-Single的77.87→74.56),表明启发式不确定性估计无法正确评估噪声水平。移除模态依赖计算器(--MC)会导致最大跌幅,验证解决模态偏倚对于避免困难模态的双重抑制至关重要。与此同时,移除渐进优化策略(--POS)也会因联合优化过程中的梯度冲突而损害性能。总体而言,完整的UDML实现了最佳性能,证明了准确的噪声估计、依赖性重对齐和稳定优化共同促进了无偏动态多模态学习。推广到不同的多模态架构。为展示UDML在多种环境中的通用性,我们将其与两种代表性的中间融合方法MMTM 19和mmFormer 50整合,并评估其在多个数据集中的表现。MMTM是一种基于卷积神经网络的架构,通过挤压和激励操作融合多模中间特征,而mmForformer是一种基于变换器的模型,采用交叉注意实现特征融合。具体来说,UDML入于融合块之前,以调节加权后的多模态表示。训练计划和数据增强策略与各自基线实施保持一致,以确保公平对比。如表5右侧所示,尽管MMTM和mmForform在未使用UDML的情况下已实现竞争性能,UDML的引入也带来了显著的性能提升。具体来说,在MVSASingle数据集上,应用UDML后MMTM的性能从78.86%提升到85.68%。这些结果证实了UDML在不同架构上的鲁棒性和多样性。可视化。为了直观理解UDML的机制,我们将在CREMA-D数据集上,在图像模态中加入不同噪声时,将每种模态的推断系数可视化。如图3(a)所示,视觉模态(红色曲线)权重平滑下降随着视觉噪声增加,最终在噪声较大时趋近于零。这表明所提出的噪声感知不确定性估计器能够准确区分低噪声和高噪声情况,克服传统不确定性估计方法的误估问题。 同时,我们可以看到模型对音频模态的内在依赖性(=1.6)比视觉模态(=0.4)更强,无论噪声水平如何。这说明了多模态模型的依赖偏差。通过整合噪声感知加权和模态依赖性,最终无偏聚变系数修正了这种依赖偏差。具体来说,UDML将视觉权重放大1.6×并抑制音频权重0.4×。例如,当噪声为0时,最终权重大约变为0.8:0.2(视觉:音频),而非0.5:0.5。这确保了聚变在尊重内在判别贡献的同时,对噪声保持鲁棒性,实现了平衡且可靠的多模态整合。
表5。在将UDML方法集成到基于CNN和Transformer的架构后进行的性能评估。†表示UDML已应用。
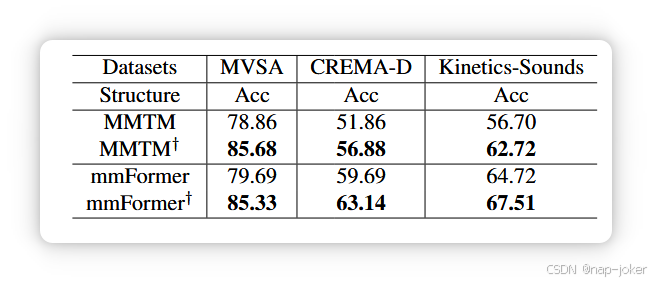
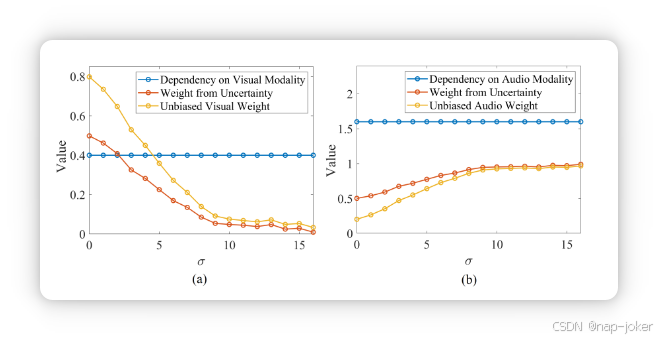
图3。在CREMA-D数据集上,将动态多模融合可视化用于视听分类,因为不同水平的噪声(σ)被注入视觉模态。
总结
本文指出多模聚变中的两个根本挑战:极端噪声下模态-不确定性估计的不可靠,以及双重抑制效应,即低贡献模态因高不确定性而进一步下注。因此,动态聚变甚至可能表现不及静态聚变。为此,我们提出了UDML这一动态多模态学习框架,结合了可靠的不确定性估计与依赖感知融合。视觉分析表明,我们的不确定性估计器能够准确追踪模态退化,并实现对受损模态的自适应抑制。与此同时,导出的依赖系数暴露了内在贡献不平衡,这一点通过我们的无偏加权策略得到了有效纠正。在多个多模态数据集上的大量实验表明,UDML比现有聚变方法更强、更稳定的聚变行为和更好的整体性能。
局限性
UDML主要关注模态层面偏倚,并未明确处理样本层面偏倚。例如,尾类样本可能存在较高的不确定性,原因是训练数据有限,而非模态噪声。在这种情况下,模型可能会过度抑制这些样本,给这些样本分配不必要的低模态权重。这表明多模态学习的不确定性不仅可能源于模态损坏,还可能源于数据失衡和样本难度。未来研究中,我们计划探讨如何解开这些不确定性来源,并将样本级偏差校正整合到动态多模聚变中。