一套开源的可私有化部署的AI客服系统(AI-CS)
最近一段时间,我一直在做一件看起来不复杂、但真正落地会踩很多坑的事:把官网右下角那个"客服小窗",从一个能聊天的窗口,做成一套可用、可运营、可排障的智能客服系统 。
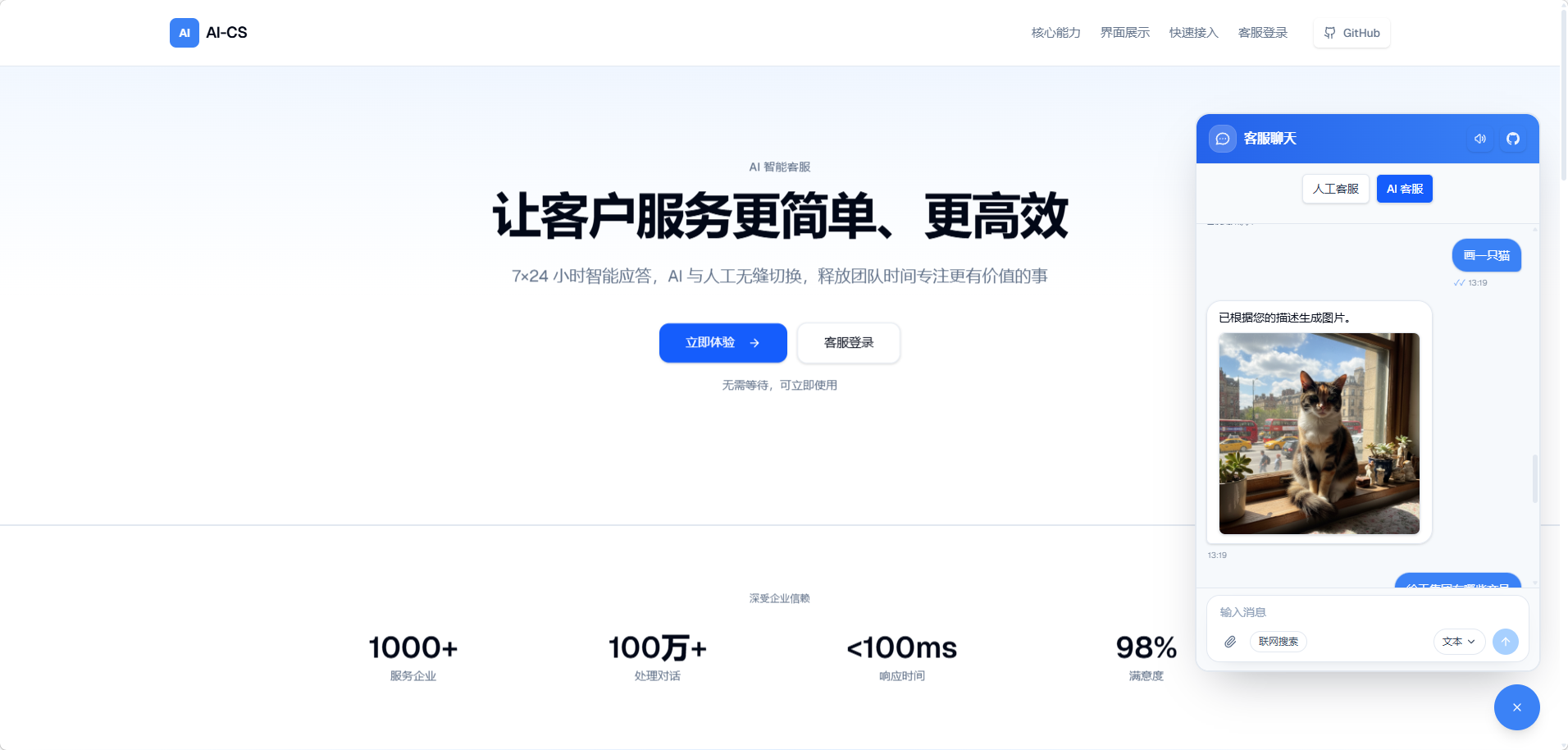
我把它整理成了一个开源项目:AI-CS 智能客服系统。
- GitHub(主仓库) :
https://github.com/2930134478/AI-CS - Gitee(国内镜像) :
https://gitee.com/gong-huijing/AI-CS - 在线演示(官网首页) :
https://demo.cscorp.top - 在线演示(访客聊天) :
https://demo.cscorp.top/chat - 在线演示(客服登录) :
https://demo.cscorp.top/agent/login
这篇文章我想用更"复盘"的方式写:为什么要做、做成了什么、怎么跑起来、踩过哪些坑、以及我打算怎么继续迭代。如果你也在做官网获客、售前咨询、内部支持,应该会有共鸣。
为什么我要自己做一套,而不是直接买一个?
很现实的几个原因:
- 数据归属:对话里会出现真实客户信息、订单信息,甚至内部流程。我更倾向于把这些数据留在自己的环境里。
- AI 和人工要一体:很多方案要么偏机器人,要么偏人工工单。真实业务往往是"AI 先顶住常见问题,关键时候人工接管",两者要无缝切换。
- 知识库必须可控:我希望能随时开关 RAG,甚至向量库挂了也别把整个系统拖死。
- 排障与可观测:上线后最怕"看起来能用,但偶发问题没法定位"。所以我从一开始就把结构化日志、查询筛选、trace 线索当作核心能力来做。
AI-CS 现在做成了什么样?
我把系统分成三块:访客侧、客服侧、官网与 SEO。这样更贴近实际使用场景:访客体验、客服工作流、以及能不能被发现。
1) 访客侧:可嵌入任意网站的小窗(iframe)
- 右下角聊天小窗,可通过 iframe 嵌入任意网站
- 支持 AI 模式 / 人工模式 切换
- 支持消息提示音、文件上传
- 支持"本回合联网搜索"开关(是否展示给访客、是否启用由后台控制)
我比较在意的一点是:它应该像一个真正能上线的 widget,而不是 demo 页面。除了能对话,还得考虑嵌入方式、尺寸、移动端体验、遮挡与层级等细节。
2) 客服侧:工作台(会话 + 实时消息 + 配置 + 知识库 + 排障 + 报表)
客服侧是我投入最多的一块,因为这决定了它到底能不能"落地用起来"。
- 会话列表、实时消息(WebSocket)、未读角标
- 多模型管理(文本/绘画等)与对话配置
- Prompt 管理
- 知识库管理 + RAG(向量检索可按需启用)
- 日志中心:结构化日志落库,可按级别/分类/事件/trace_id/关键字筛选
- 数据报表:访客打开小窗、会话与消息量、AI 回复与失败率、知识库命中率、转人工等指标
我做报表不是为了"看起来很全",而是因为真实运营会问:AI 到底帮我省了多少人工?转人工发生在哪些问题上?知识库命中真的有效吗? 没数据就只能凭感觉调参数。
3) 官网与 SEO:让系统"可被发现"
很多开源项目只做到"能跑",但我希望它还能"可展示、可被搜索引擎收录、可分享"。所以也做了官网页面,以及 Open Graph、JSON-LD、sitemap、robots 这些配套。
如果你要自己部署到域名上,建议把 .env 里的:
NEXT_PUBLIC_SITE_URL=https://你的域名
配好,否则分享卡片和 sitemap 这类能力很容易出现域名不对的问题。
技术栈与整体结构(我怎么把它拼起来的)
- 前端:Next.js(Node.js 20.9.0+)
- 后端:Go(1.24+)
- 数据库:MySQL 8.0+
- 向量库(可选):Milvus
- 配置:只维护根目录
/.env(我刻意把它作为单一配置真源)
这里有个设计取舍我挺满意:向量库是"可选能力",而不是"强依赖"。你可以先不装 Milvus,把 AI + 人工 + 工作台跑起来;等准备好了再开 RAG。
5 分钟跑起来:我建议的上手路径
如果你只是想最快看效果,我建议直接用 Docker 的"预构建镜像部署"(省掉构建环境与依赖问题):
1)拉取代码并初始化配置
bash
git clone https://github.com/2930134478/AI-CS.git
cd AI-CS
cp .env.example .env至少要改(必填):
- 数据库:
MYSQL_ROOT_PASSWORD、DB_PASSWORD - 管理员:
ADMIN_PASSWORD - 安全密钥:
ENCRYPTION_KEY(64 位 hex)
生成 ENCRYPTION_KEY:
bash
# Linux/Mac
openssl rand -hex 32
# Windows PowerShell
-join ((48..57) + (97..102) | Get-Random -Count 64 | ForEach-Object {[char]$_})2)启动
bash
docker-compose -f docker-compose.prod.yml up -d3)访问
- 官网首页:
http://localhost:3000 - 访客聊天:
http://localhost:3000/chat - 客服登录:
http://localhost:3000/agent/login
我踩过的坑(写出来给你省时间)
1) "向量库连不上,服务就启动不了"这种体验很糟
所以我把"是否依赖 Milvus"做成显式开关:
- 暂时不想用知识库:
MILVUS_DISABLED=true(或VECTOR_STORE_DISABLED=true)
应用仍可启动,AI 对话与人工客服不受影响 - 生产上强依赖知识库:
MILVUS_REQUIRED=true
Milvus 不可用时,服务会落库错误日志后退出,避免"半残服务上线"
2) 提示音在部分浏览器"突然不响"
这往往不是 bug,而是浏览器策略:很多浏览器需要用户先进行一次交互才能播放音频。遇到"提示音没声音",先点一下页面任意按钮再测通常就能定位是不是策略问题。
3) 部署时最容易翻车的是"域名与环境变量"
尤其是 SEO、分享卡片、sitemap 这类能力,对 NEXT_PUBLIC_SITE_URL 很敏感。我现在的习惯是把域名相关变量列为上线 checklist,不然上线后你会遇到"页面能打开,但分享出去看起来不对"的尴尬问题。
我希望它最终变成什么
我不想把 AI-CS 做成"只有我能用"的玩具项目。更理想的状态是:
- 你能用它快速把客服能力嵌到任何业务里
- 你能按需开启 RAG / 联网搜索,而不是被某个组件绑架
- 你能通过日志与报表,把"AI 到底有没有用"从争论变成数据
- 你能把它当作底座,去二次开发自己的业务流程
如果你正好也在做类似系统,或者准备把客服小窗从"能聊"升级到"能运营、能排障、能迭代",可以看看项目仓库:
- GitHub:
https://github.com/2930134478/AI-CS - Gitee:
https://gitee.com/gong-huijing/AI-CS
我也会持续把一些真实的上线踩坑、迭代取舍、以及功能演进写出来------这类细节,往往比"功能列表"更能帮到准备落地的人。