Llamafactory是一个开源的大模型微调框架,我们不需要编写代码就能用LoRA、QLoRA等方法微调很多主流大模型。
一、环境配置
在之前的博客中也有提到,模型微调需要的环境,一般的电脑是无法支持的,所以这次我们操作的环境是网上的云服务器。
这里我们选择的是魔搭社区的云服务器。
登录魔搭社区,绑定支付宝,就有免费的额度,在notebook中选择最gpu环境选择默认的,启动之后点击查看notebook就能打开我们的云服务器了。
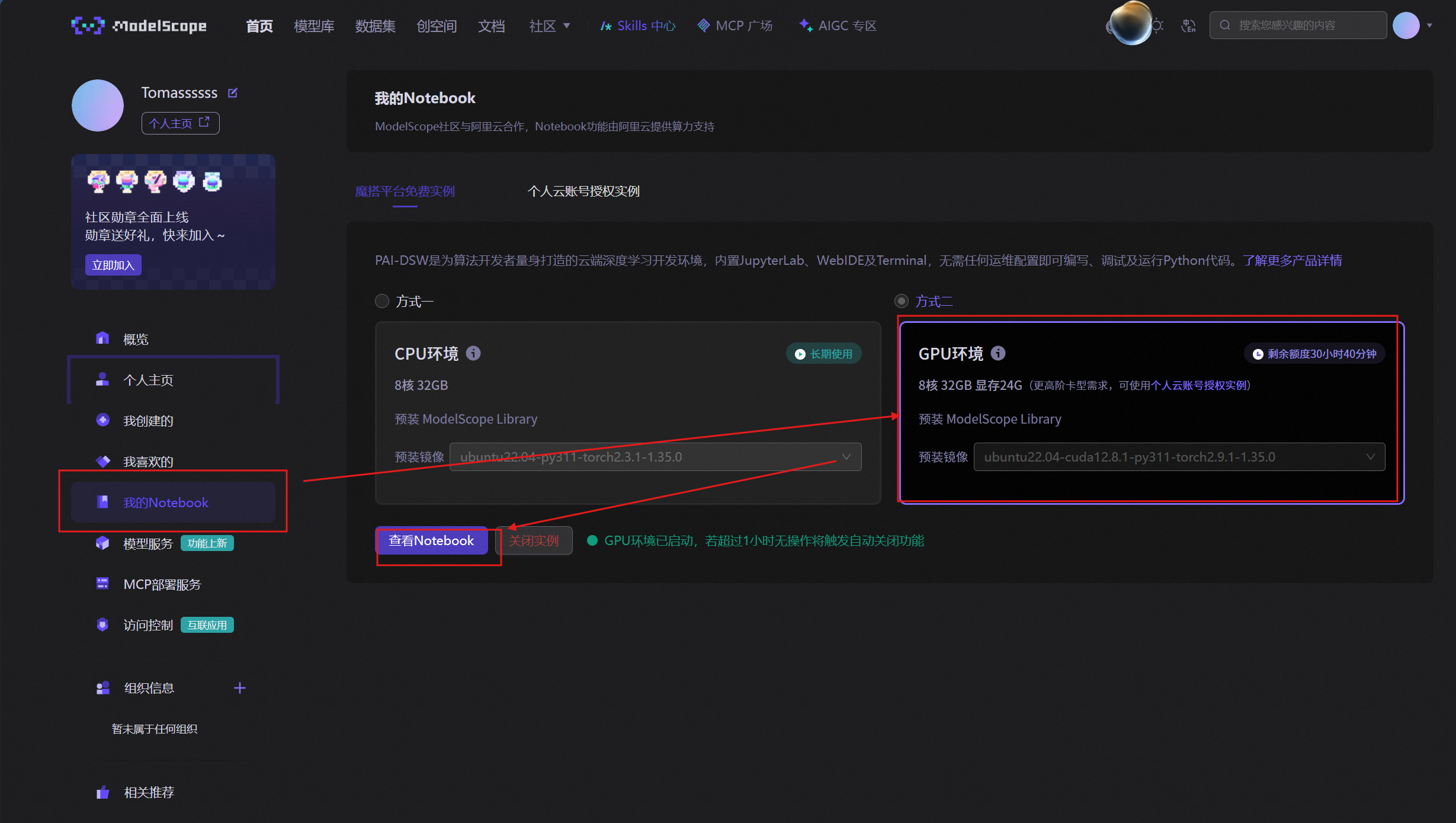
打开的界面是这样的,我们操作基本上都是在终端。
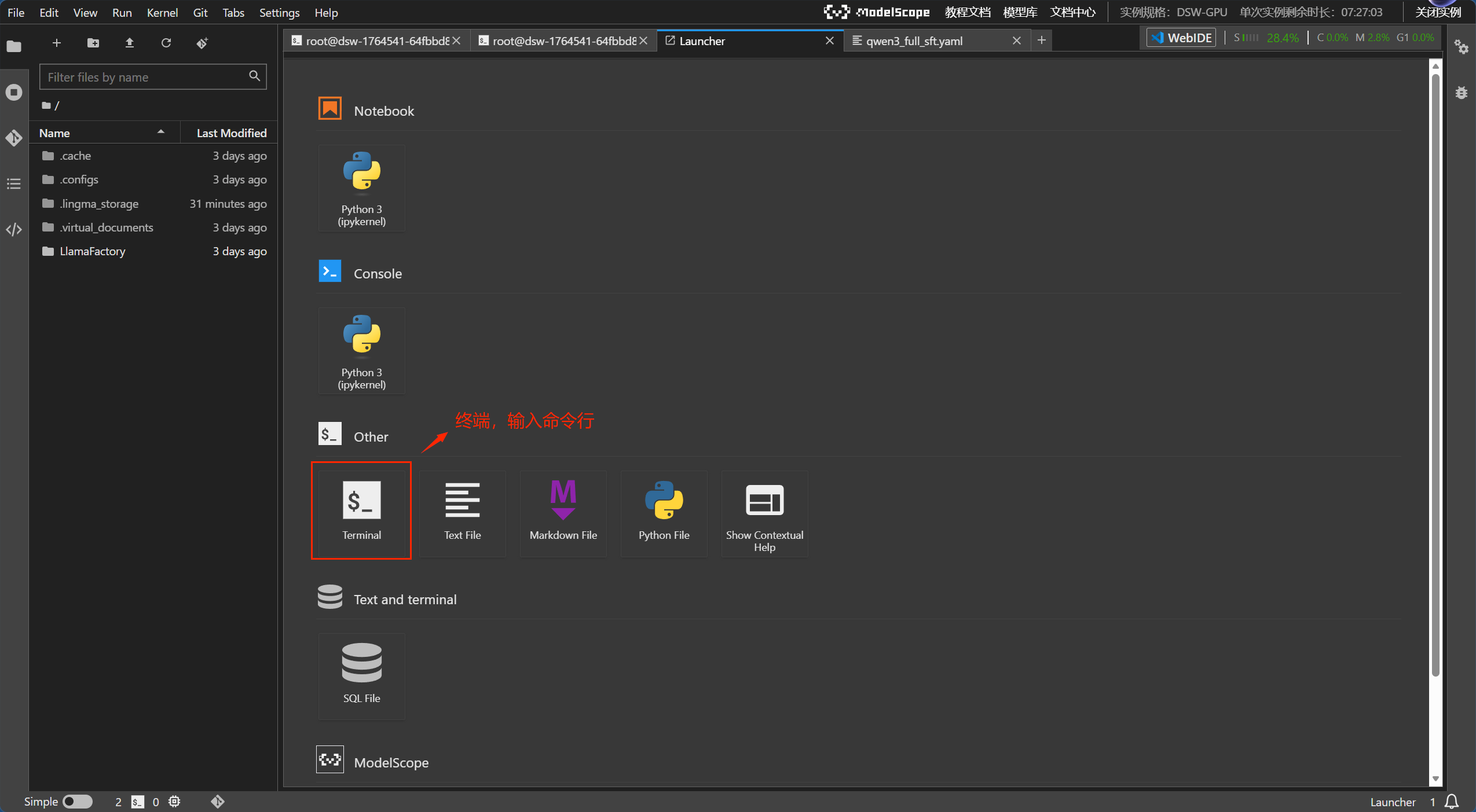
二、下载模型
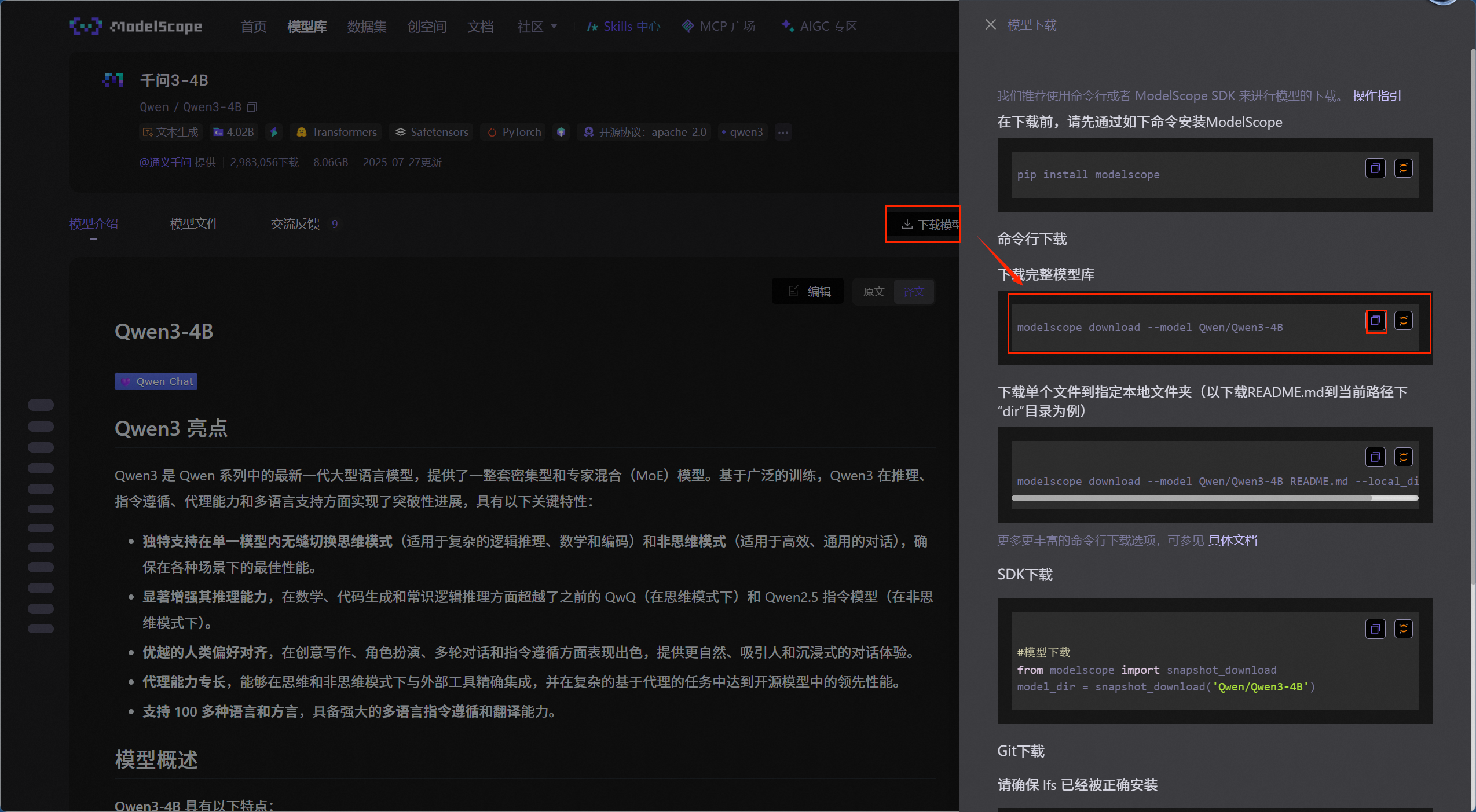
选择我们需要微调的模型,点击下载模型,选择命令行下载,复制命令在我们云服务器终端上输入回车即可,和在本机上是一样的
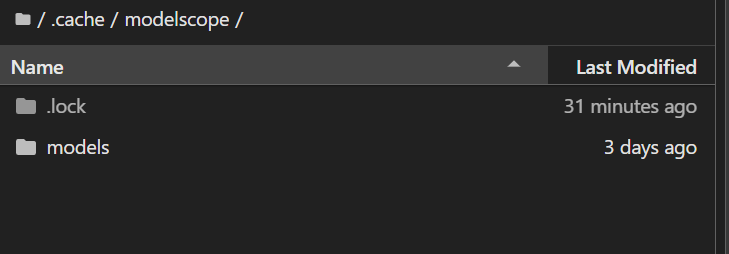
下载好模型,之后设置显示隐藏文件,方便找到我们模型的位置
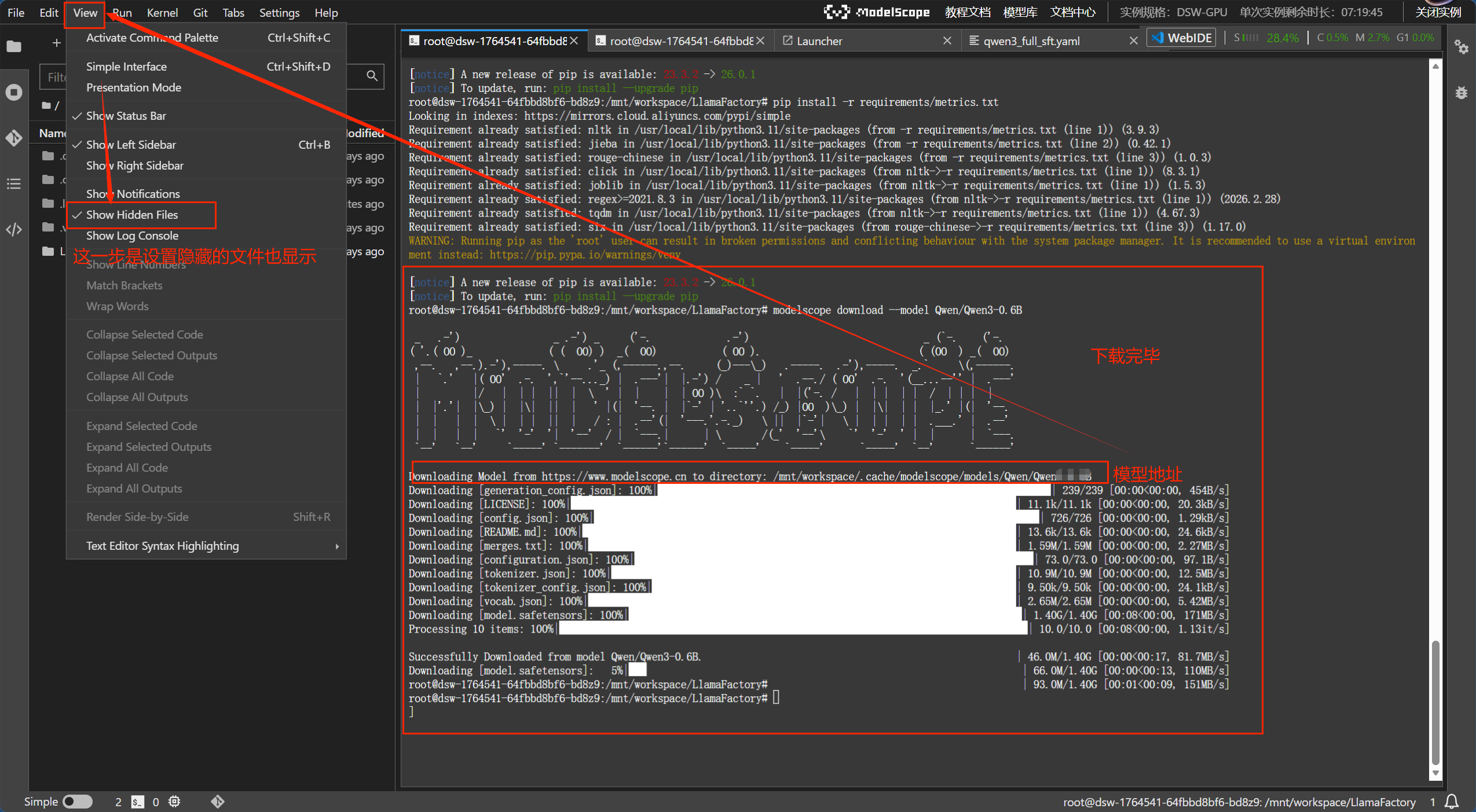
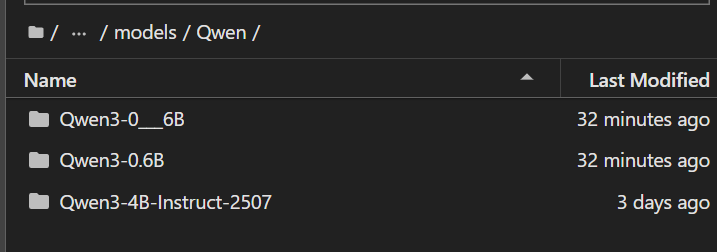
我们模型的地址就在.cache/modelsccope/models/Qwen中,有我们要下载的模型Qwen3-4B就说明模型下载成功。
三、下载Llamafactory
Llamafactory是在github上下载的。
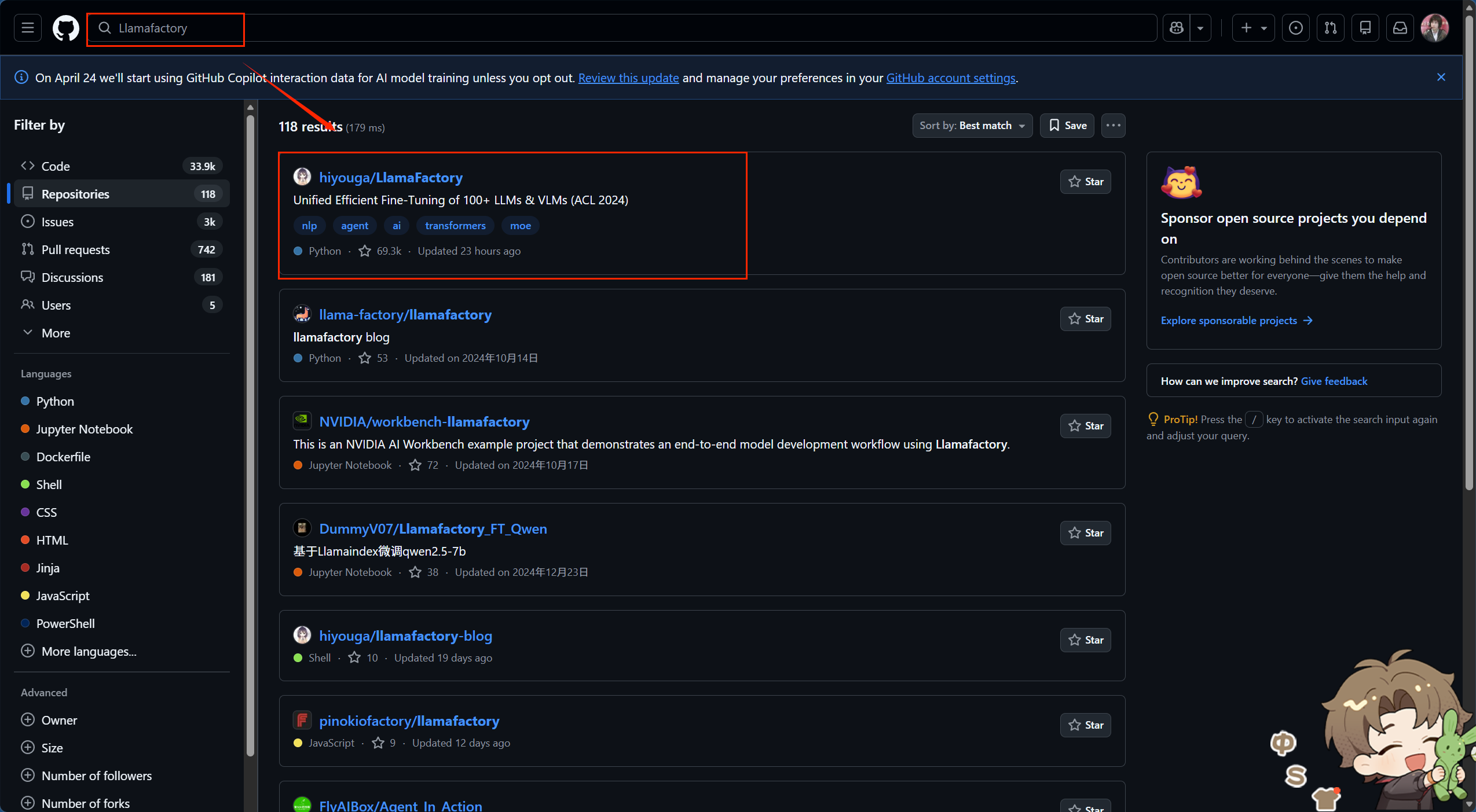
不要着急下载,先往下滑,选择中文
然后往下滑会发现如下图
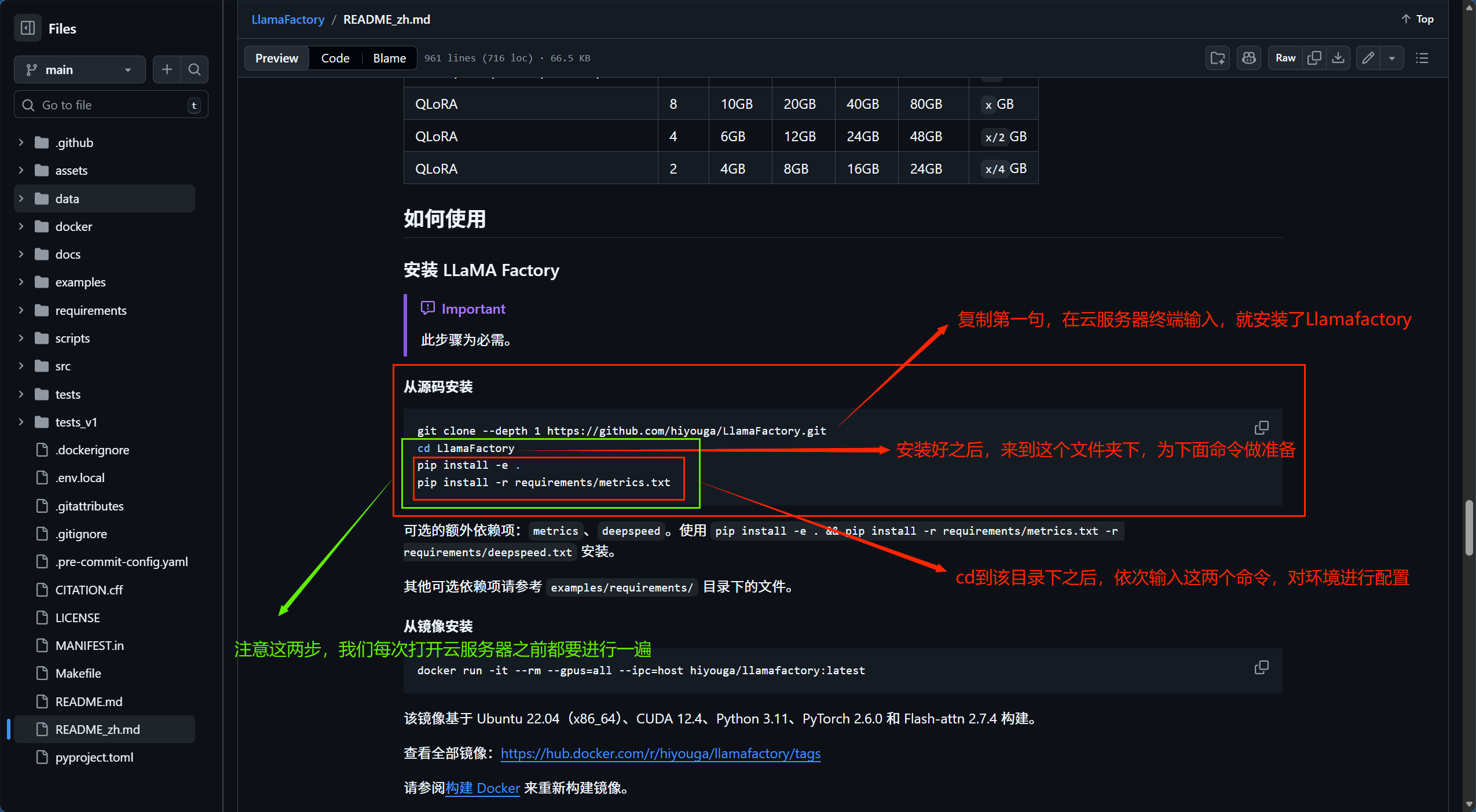
上述代码如下:(后三行是需要每次重启云服务器时都需要进行一遍的依赖)
python
git clone --depth 1 https://github.com/hiyouga/LlamaFactory.git
cd LlamaFactory
pip install -e .
pip install -r requirements/metrics.txt四、模型微调、推测、合并
因为Llamafactory是一个微调的框架,我们不需要自己去写微调的代码,就跟yolo一样,我们只需要配置一些信息就能直接使用。
所以要微调只需要修改一个配置信息即可。
当然llamafactory中有一些比较受欢迎的模型配置文件。比如说我们下载的qwen模型,框架中就有写好的模版。我们只需要修改一下路径就行。
没有模版的模型也可以进行训练,在魔搭社区能找到的模型,需要我们自己创建yaml文件,对其中一些参数进行配置就行。
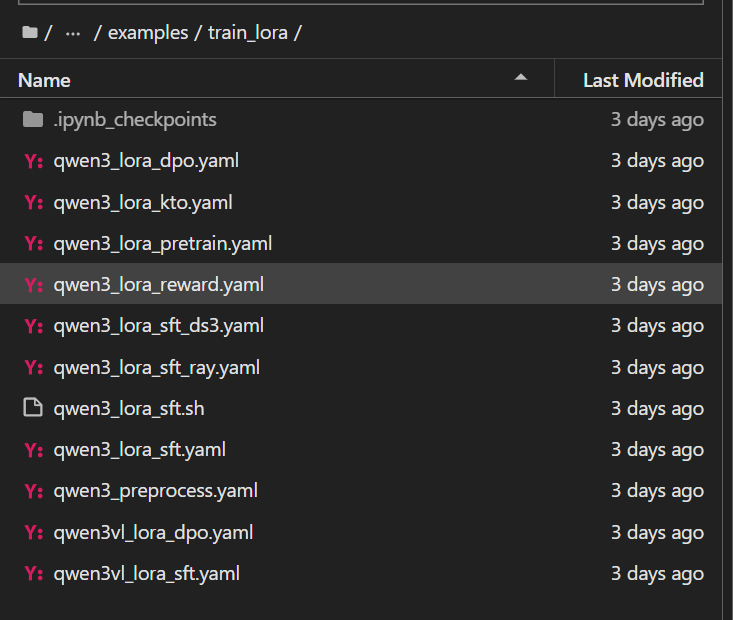
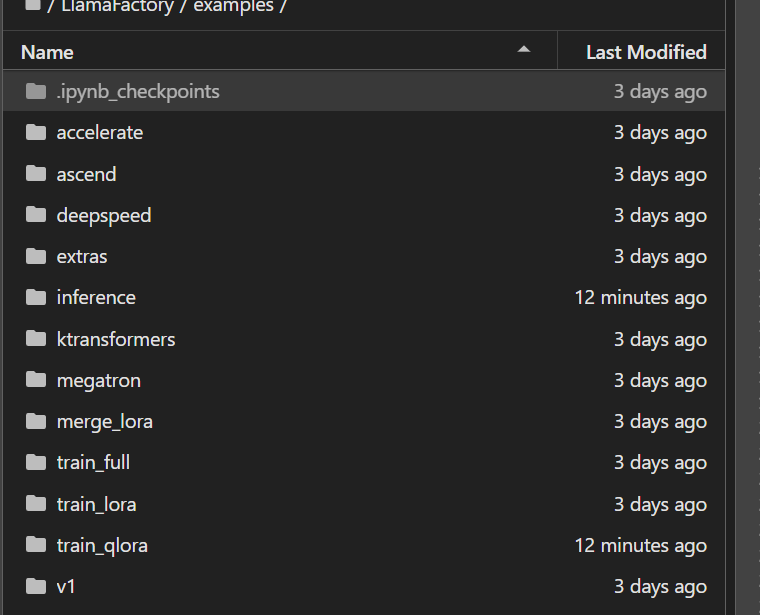
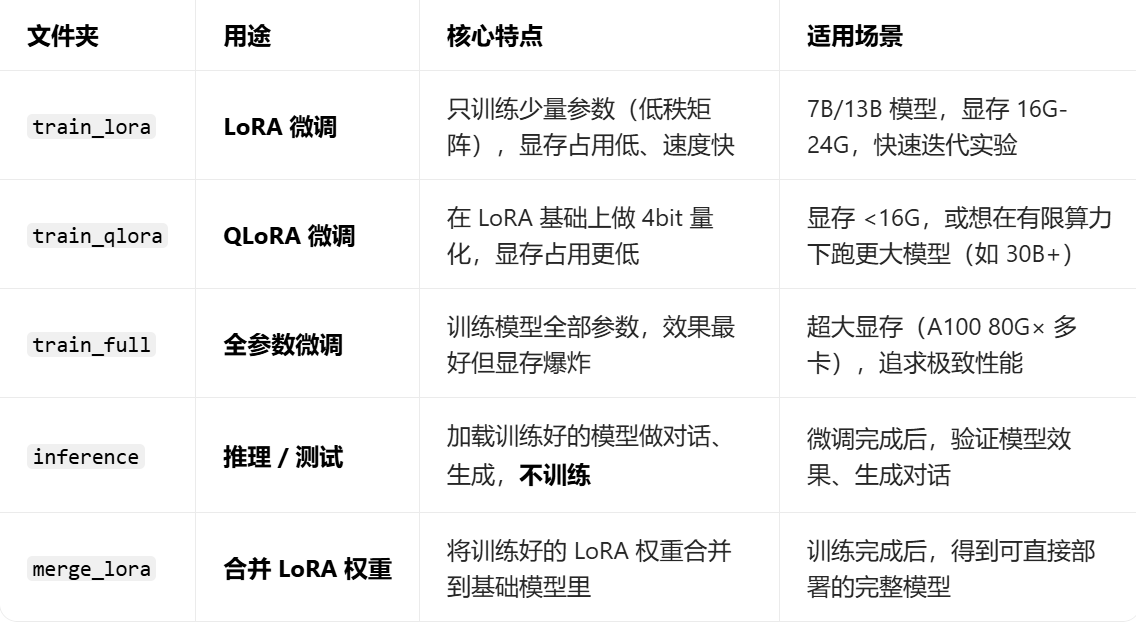
在llamafactory中的examples中会发现这些文件家里面都是yaml文件,到底用哪个,这些到底有什么不同呢?
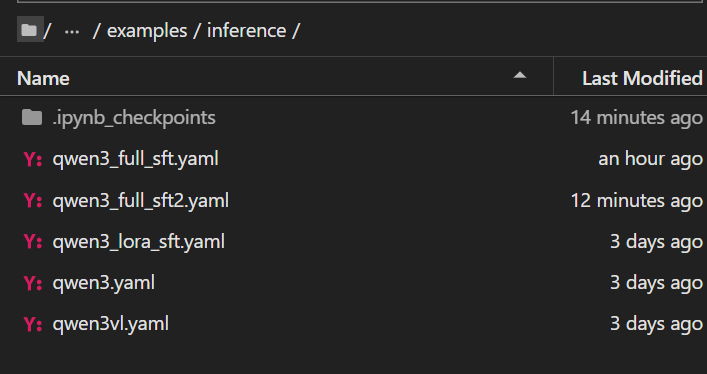
inference中都是推理配置,用来进行模型推理的。
train_lora是进行lora微调,train_qlora是进行qlora微调,train_full是进行全量微调。
merge_lora是合并模型的,也就是我们训练的模型和基础模型进行合并。
注意,其中的模型路径我们需要写完整

python
/mnt/workspace/.cache/modelscope/models/Qwen/Qwen3-4B-Instruct-2507如果我们是自己创建yaml文件
python
touch config.yaml之后需要给这个文件设置权限
python
chmod 777 config.yaml在进行写入
python
vim config.yaml就跟linux系统操作是一样的。
文件配置好之后就可以进行微调等操作了,在命令行调用对应配置文件即可
python
llamafactory-cli train examples/train_lora/qwen3_lora_sft.yaml#微调
llamafactory-cli chat examples/inference/qwen3_lora_sft.yaml#推理
llamafactory-cli export examples/merge_lora/qwen3_lora_sft.yaml#合并1.微调配置文件一些参数,微调其实就是训练,这里我们训练好的模型会有一个新的权重参数,被我们保存在output下的路径里面。
- 学什么:指定数据集(`dataset: sft_data`)和对话模板(`template: qwen3`)。
- 怎么学:设定学习率(`learning_rate`)、训练轮数(`num_train_epochs`)、批次大小(`per_device_train_batch_size`)。
- 学多少:配置 LoRA 的参数,比如秩(`lora_rank: 8`)和目标模块(`lora_target: all`)。
- 产出:运行后,你会得到一个新的文件夹(通常在 `saves/` 目录下),里面包含训练好的 **LoRA 权重文件**(`adapter_model.bin`)
python
### model
model_name_or_path: Qwen/Qwen3-4B-Instruct-2507
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset
dataset: identity,alpaca_en_demo
template: qwen3_nothink
cutoff_len: 2048
max_samples: 1000
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: saves/qwen3-4b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: null
### eval
# eval_dataset: alpaca_en_demo
# val_size: 0.1
# per_device_eval_batch_size: 1
# eval_strategy: steps
# eval_steps: 5002.推理配置文件相关参数,推理其实就是使用模型,体验模型。
python
model_name_or_path: Qwen/Qwen3-4B-Instruct-2507
adapter_name_or_path: saves/qwen3-4b/lora/sft
template: qwen3_nothink
infer_backend: huggingface # choices: [huggingface, vllm, sglang, ktransformers]
trust_remote_code: true- 加载谁:它需要同时指定基础模型(
model_name_or_path)和刚才训练出来的 LoRA 权重(adapter_name_or_path)。 - 用什么引擎:这里就是你刚才问到的
infer_backend: huggingface或vllm。 - 格式:必须保持和训练时一样的对话模板(
template: qwen3),否则模型会听不懂人话。 - 产出:一个交互式的命令行界面,你可以输入问题,模型实时回答。
3.合并模型配置文件相关参数,合并其实就是把我们训练部分和基础模型进行合并并导出,成为一个新的模型。
python
### Note: DO NOT use quantized model or quantization_bit when merging lora adapters
### model
model_name_or_path: Qwen/Qwen3-4B-Instruct-2507
adapter_name_or_path: saves/qwen3-4b/lora/sft
template: qwen3_nothink
trust_remote_code: true
### export
export_dir: saves/qwen3_sft_merged
export_size: 5
export_device: cpu # choices: [cpu, auto]
export_legacy_format: false- 源文件:指定基础模型路径和 LoRA 权重路径。
- 去向:指定合并后的模型保存路径(
export_dir)。 - 注意:这里通常要求基础模型必须是 FP16/BF16 格式,不能是量化过的(如 INT4/INT8),否则合并会失败或精度受损。
- 产出:一个全新的、独立的模型文件夹。这个文件夹里包含了所有权重,不再依赖 LoRA 插件,可以直接被任何支持该架构的工具加载。
五、监控显卡
微调过程中可以对显卡情况进行检查,两条安装命令
python
pip install nvitop#下载监控库
pip install nvidia-ml-py -U#显卡驱动接口下面三条命令都是调用,只不过显示的模式不同,依次是自动模式、紧凑模式、完整模式。
python
nvitop -m auto
nvitop -m compact
nvitop -m full