做知识库检索的人几乎都踩过这种坑:切片里只剩一句「收入增长 3%」,却说不清哪家公司、哪一季 ------传统切块很容易把文档级语境 弄丢,后面无论是向量召回还是 BM25,都在「半句话」上打转。Contextual Retrieval 的思路很直白:在做向量嵌入和 BM25 之前,先给每个 chunk 补一小段「它在全文里站什么位置」的说明,再建索引。具体数字与是否值得上生产,仍以原文和你自己的 eval 为准。1
先看主线
- 主线:为什么裸 chunk 会失语境 → Anthropic 这套补什么 → 混合检索 + rerank 怎么叠 → 什么时候别硬上 RAG。
- 跳读位 :文内
### 深度解析与「继承关系与未公开细节」。
一、背景:传统 RAG 为什么常「断章取义」
模型要在业务里好用,往往要接外部知识库;常见套路是 RAG :从库里捞片段拼进 prompt。问题出在编码片段 这一步:chunk 单独看像「公司收入增长 3%」,脱离原文后指代不清,检索命中了也可能用错------不是模型不努力,是索引对象本身缺了坐标。1
二、演进:Contextual Retrieval 在补哪一环
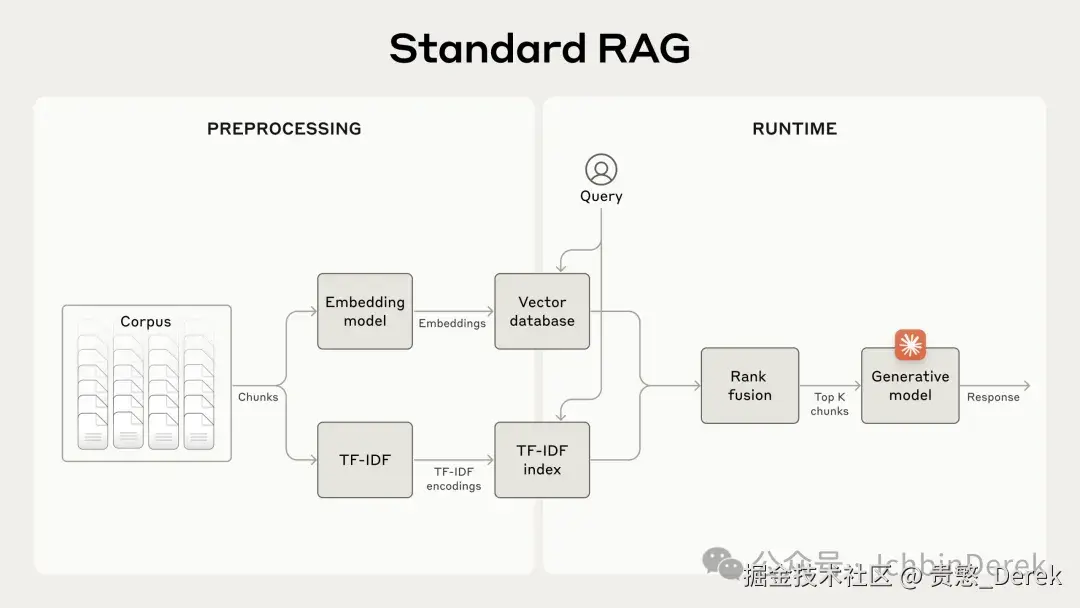
可以把它理解成两条并列子能力(命名以原文为准):1
动手实验可直接跟官方 Contextual Embeddings cookbook。12
- Contextual Embeddings :在做向量嵌入前 ,给每个 chunk 前面加一段短文,说明「这块内容在整篇文档里处在什么处境」。
- Contextual BM25 :用同一套已经情境化过的文本 去建 BM25,而不是只对裸 chunk 建词项索引。
文中给过一个概念示例(帮助建立直觉):1
ini
original_chunk = "The company's revenue grew by 3% over the previous quarter."
contextualized_chunk = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; ... The company's revenue grew by 3% over the previous quarter."三、机制:Embedding、BM25、Rerank 各自干什么
Embedding 偏语义;BM25 偏字面/词项 (比如错误码 TS-999 这种)。经典混合 RAG 往往是 BM25 + 向量 + rank fusion 再去重------情境化是在「进索引之前」多走一步,不是替代混合检索。1
3.1 情境说明从哪来:批量生成管线
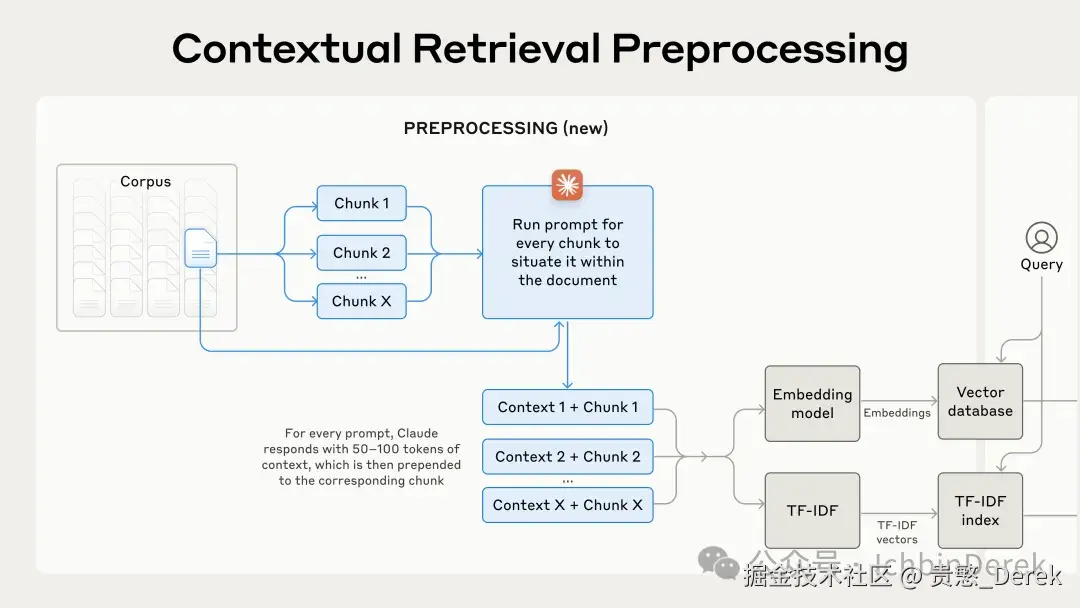
手工给百万个 chunk 写说明不现实:文内用 Claude (示例为 Claude 3 Haiku )+ 固定 prompt ,输入整篇文档 + 目标 chunk ,输出一段很短 、专门服务检索的说明(常见约 50--100 tokens),再拼回 chunk 上做嵌入与 BM25。1
3.2 成本:Prompt Caching 为什么重要
如果对每个 chunk 都重复塞整篇文档 ,账单会很难看;Prompt caching 让文档先载入缓存一次 ,后面 chunk 复用------产品说明见 Prompt caching 文档;文内给了示意性 成本估算(依赖 chunk 大小、文档长度、指令与情境 token 等假设),一次性生成情境化 chunk 的均价量级约为 每百万 document tokens 约 $1.02 (定价与假设以原文与当前官网为准)。14
深度解析:情境化会不会「写错背景」
事实:情境说明是模型生成的,再拼进 chunk。1
原文观点:能抬检索 Top-k。1
本文解读 :如果生成器把「文档类型/时间」写飘了,会污染索引 ------流水线里最好加 抽样人工抽查 或 规则校验(例如财报期和文档元数据对齐)。
四、应用边界:什么时候值得上,什么时候先别折腾
若知识库 < 约 200k tokens (文中量级),有时不必硬上 RAG ,直接把全库塞进 prompt 反而省事;配合 prompt caching 还能压延迟和费用------这条和「做大索引」是不同取舍。1
4.1 原文评测怎么读(Top-20)
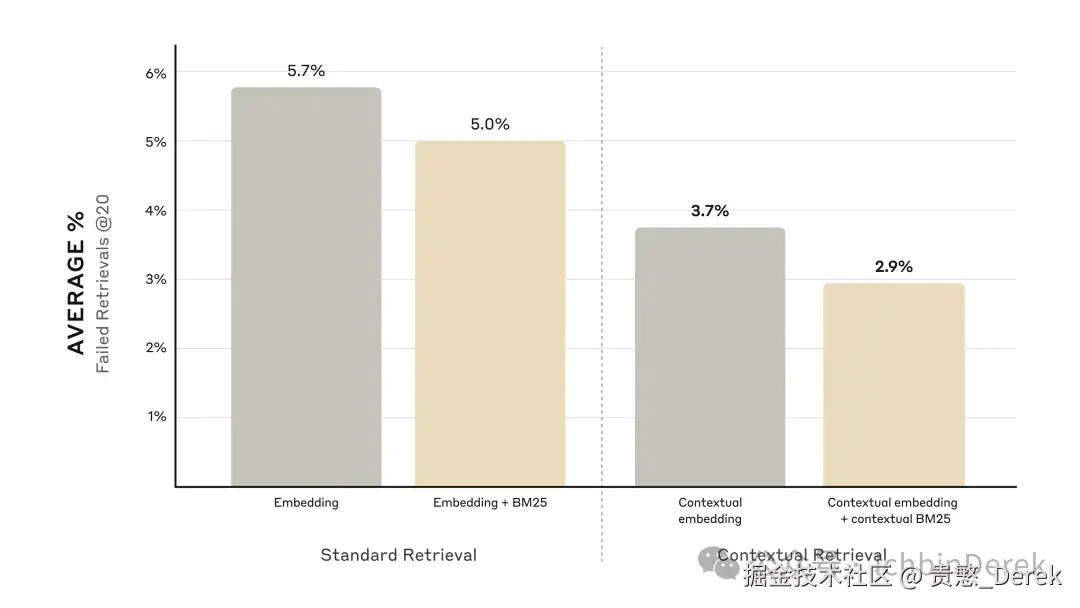
指标是 1 − recall@20 (白话讲就是 Top-20 chunk 检索失败率 ),多领域、多嵌入配置;示例问答与更细拆分见 Appendix II PDF。13
- 只上 Contextual Embeddings :Top-20 失败率 从 5.7% → 3.7% (约 −35% 相对降幅,以原文表述为准)。
- Contextual Embeddings + Contextual BM25 :5.7% → 2.9% (约 −49%)。
- 再叠 Rerank (文内用 Cohere reranker 等设定):5.7% → 1.9% (约 −67% )。流程上可以先多捞候选(如 Top-150 ),再 rerank 到 Top-20 进生成。1
4.2 落地时别忽略的变量(原文归纳)
- Chunk 怎么切:边界、重叠、粒度都会影响检索。
- 嵌入模型换不换 :情境化在多个模型上都有提升,幅度不一;文内对 Gemini / Voyage 等有实验叙述。
- 情境化 prompt :通用模板能跑,领域定制(术语表等)往往更香。
- 最终喂给生成的 chunk 数 :文内比较过 5 / 10 / 20,20 在该设定下更优(仍要按业务自评)。
- 始终做 eval;生成侧也可以区分「情境说明」和「原始 chunk」怎么展示给用户。1
Rerank 会多一笔延迟和钱,要在效果和总成本之间自己权衡。1
五、延伸(非原文结论)
合规 :财报/客户数据走情境化时,留意日志与缓存 里有没有多留一份敏感上下文。
和 Agent 侧对照读 :Effective context engineering for AI agents 偏在线任务流与窗口;本篇偏 知识库侧离线索引与检索,问题不在同一层。6
继承关系与未公开细节:工程博文 vs 直接对外承诺
事实 :文内数字来自原文实验设定与 Appendix II PDF 等附录材料,非对你业务的承诺。13
原文观点:情境化 + 混合 + rerank 可以叠。1
本文解读(推断) :Top-20 失败率 跟领域 强相关------换中文、医疗、内部工单域要 重跑 eval,别拿「−49%」当对外 SLA 念。
结论与讨论
技术坐标
Contextual Retrieval 改的是索引对象 :从「裸 chunk」变成「chunk + 一小段文档级语境」。它发生在离线索引 这一侧;和在线 context engineering 是互补关系,不是二选一。
批判性问题
- 情境化生成会不会让你更依赖底层模型------单点出问题时怎么兜底?
- Rerank 的延迟和费用,有没有被低估在总拥有成本里?
- 小库「整库进 prompt」在合规上是否允许「全量可见」?
独立判断(事实 / 原文观点 / 本文解读)
| 类型 | 内容 |
|---|---|
| 事实 | 原文 URL;Top-20 与混合检索数字为文内表述。1 |
| 原文观点 | Embeddings+BM25 + 情境化 + rerank 可叠加。1 |
| 本文解读 | 先在你自己的数据上离线复现一版 eval ,再谈上生产;成本数字会随定价变。批判性补一句 :情境化把 LLM 写进索引流水线 ------生成模型或 prompt 一变,宜规划 版本锁定与全量重建,否则「检索变差」可能来自索引侧漂移,而不是查询侧。12 |
参考文献与延伸阅读
- 1 Introducing Contextual Retrieval --- Anthropic Engineering,2024-09-19
- 2 Contextual Embeddings --- Cookbook --- 官方可运行示例入口
- 3 Contextual Retrieval --- Appendix II (PDF) --- 示例 Q&A 与更细指标拆分
- 4 Prompt caching --- 与文内成本叙事配套的官方说明
- 5 Prompt caching cookbook --- 上手示例(平台 cookbook)
- 6 Effective context engineering for AI agents --- 与本篇互补的 Agent 侧上下文工程
原文还引用 HyDE 等相关工作作对比,不等同 于本文方案;不熟 RAG 时先搞懂「切块 → 嵌入 → 检索」,再读「索引前先补坐标 」,最后打开 2 跑一版。