PaddleOCR-VL-1.5
github地址:https://github.com/PaddlePaddle/PaddleOCR
PaddleOCR-VL-1.5:0.9B VLM,专为真实世界文档解析和文本识别而 设计,是一款资源高效且达到最先进水平的模型。它在文档解析任务中,涵盖六大主要场景:正常、倾斜、变形、扫描、多光照和屏幕拍摄,均展现出全面领先优势。该模型引入了领先的文本识别和印章识别功能,增强了对复杂元素(如文本、表格、公式和图表)的解析能力,并将语言支持扩展至111种语言------所有这些都保持了极低的资源消耗
核心特性:
- 文档解析任务的SOTA性能: PaddleOCR-VL-1.5 在 OmniDocBench v1.5 基准上实现了 94.5% 的高精度,超越了全球顶尖的通用大模型和文档解析专用模型。
- 现实5大场景文档解析的SOTA性能: 引入了一种创新的文档解析方法,业界首个支持不规则文档版面定位。在扫描、弯曲、倾斜、屏摄和光照变化这五个现实场景的文档解析任务评估集上,表现全面优于主流的开源和闭源模型。
- 基于0.9B紧凑模型的能力扩展: 基于 0.9B 的参数量,PaddleOCR-VL-1.5 扩展了文本检测识别和印章识别任务,进一步提升了其能力范围,各任务相关指标均创下了 SOTA 结果。
- 强化多元素识别能力: 增强了特定场景和多语言识别方面的能力。针对特殊符号、古籍、多语言表格、下划线和复选框的识别性能得到提升。语言覆盖范围扩展,新增支持中国藏文和孟加拉语识别。
- 长文档跨页解析: 模型支持跨页表格自动合并和跨页段落标题识别,有效缓解了长文档解析中的内容碎片化问题。

使用说明
双击start_gpu.bat,等待终端启动
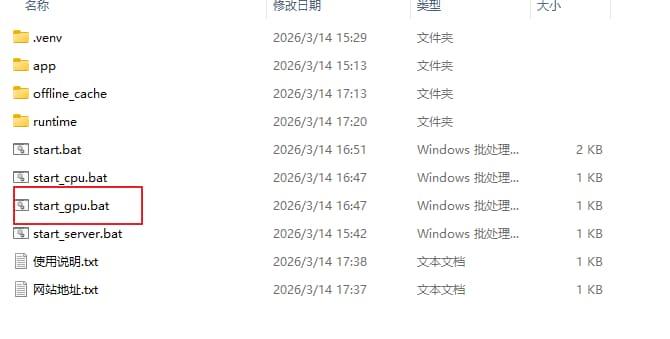
启动成功后,确认终端没有错误
正常加载对应的模型和网址
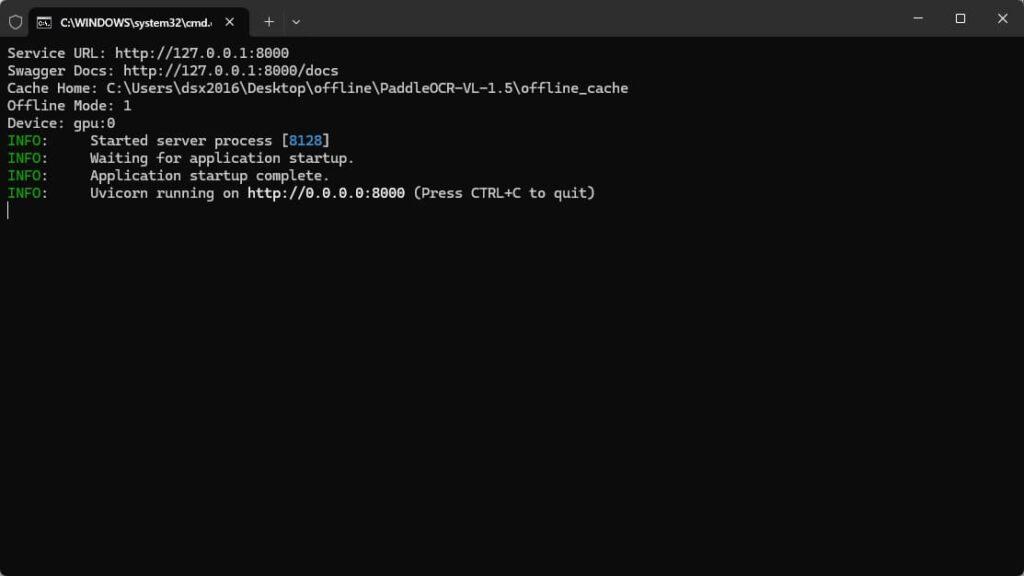
打开网页http://127.0.0.1:8000/docs
选择/parse,点击try it
选择要解析的PDF文件,设置返回的类型为md,设置返回的结果为文件file
点击Execute执行
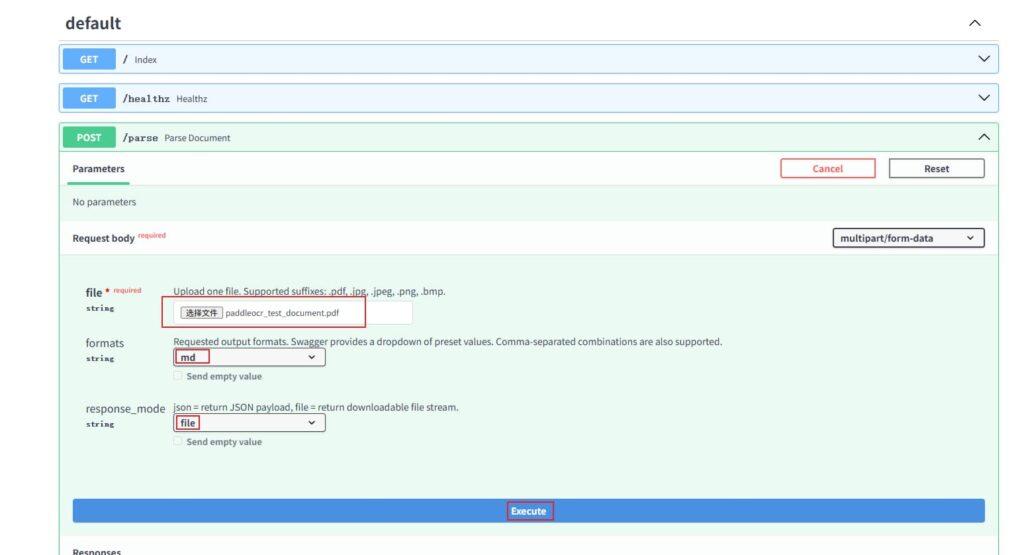
点击download file,会下载一个zip压缩包
解压缩会得到对应的md文件和图片
建议使用marktext来打开md文件,对md公式,图表,表格支持比较友好
Tips
点击此处 网盘下载
本文是PaddleOcr系列的第三篇,第一篇是cpu支持,第二篇是gpu支持,且添加pdf转md
第三篇是处理模型不同
一个是PaddleOCR 3.x 系列的传统 pipeline,具体是 PP-OCRv5 + PP-StructureV3 的组合(高精度传统 OCR + 结构化解析(PP-OCRv5 文字识别 + PP-StructureV3 布局/表格/公式/图表/印章等))
一个是PaddleOCR-VL(0.9B/1.5 等视觉语言模型版本)(极致最全"(特别是无边框复杂表单、图表语义、手写混合、端到端理解))
经过实际测试
PaddleOCR-VL-1.5的pdf转md的效果要好于PP-StructureV3
PP-StructureV3的解析会出现少文字,以及段落换行,图表转换数据等问题
同样的pdf使用PaddleOCR-VL-1.5,没有明显的错误,表面上解析度为100%,md的格式正确且完整
PaddleOCR-VL-1.5实际测试,占用显存8.2GB左右