懒人整合包修复
修复的问题:
- 把分卷压缩改为一整个压缩包
- 修复离线不可用,默认环境不可用
- 设置所有工作流都默认在懒人包,不需要再次手动添加节点等其他操作
本次懒人包没有新的功能点,只是对之前的一些问题修复处理
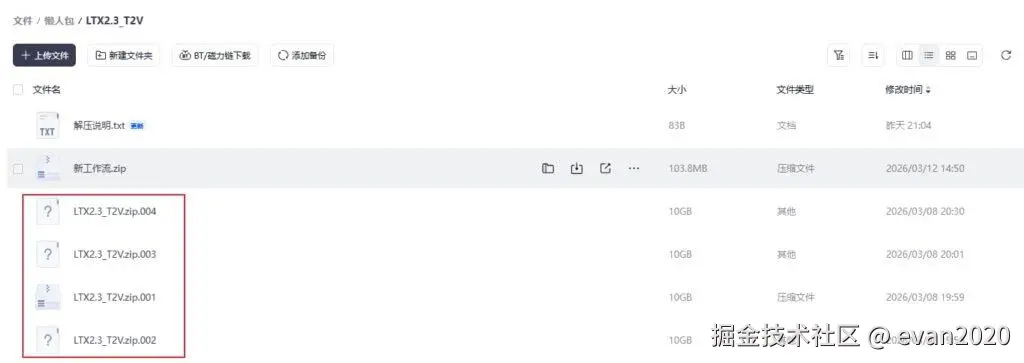
分卷压缩
分卷压缩的文件,需要把所有的压缩包下载下来
然后全部同时间选中,然后右键解压缩,才能获取一个完整的文件
分卷压缩的好处是,可以按单个文件下载,比如c盘只有50GB剩余空间,D盘剩余80GB,但是一个压缩包要90GB,那么无论c盘还是d盘都无法一次性下载
分卷压缩就是可以把90GB拆分为9个10GB文件,C盘下载一部分,D盘下载一部分,最后找个空间充足的地方一并解压
现在我已经把分卷改为单个压缩包,本文大约40GB压缩文件
离线可用
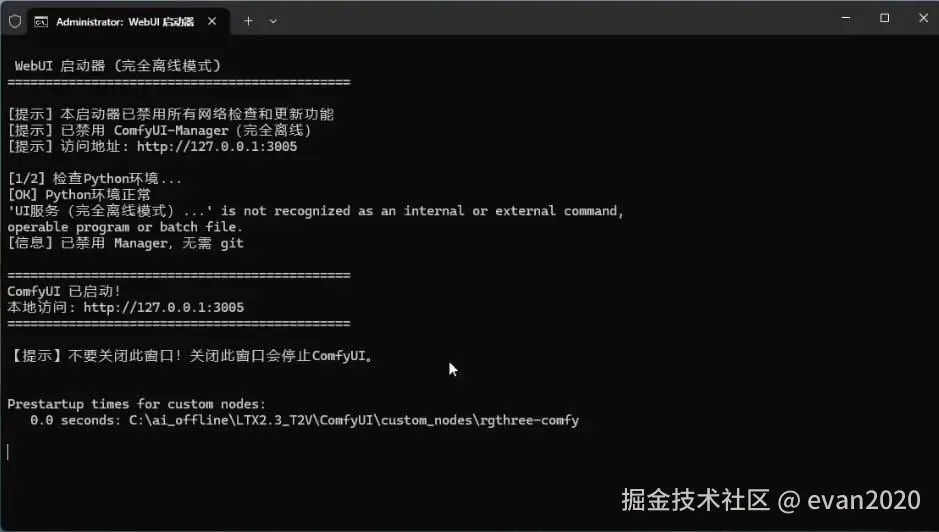
前期的懒人包,没有环境自测
在虚拟机win只能测试cpu离线场景,还经常卡顿,无法测试gpu场景
后面改为U盘随身系统win,可以用纯净版win测试cpu+gpu+离线+无程序环境
这个懒人包重新复测了一遍,已修改为离线懒人整合包,无需联网,没有python等环境和模型也可以使用
需要注意的是cuda版本需要12.8及以上
工作流
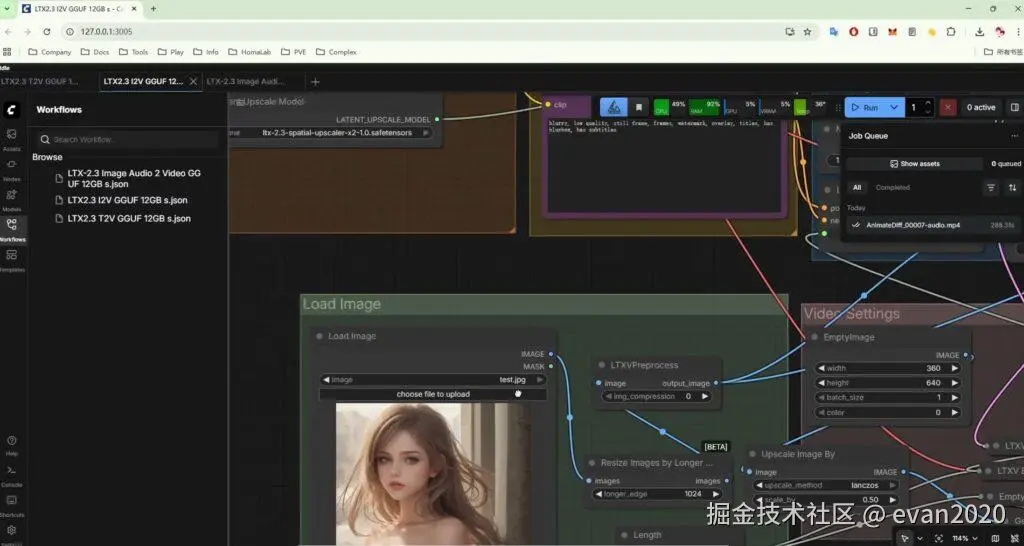
前期文生视频单独打包懒人包,后期补充100M的图生视频和数字人工作流,需要用户自己复制文件夹和节点
现在统一预设到懒人包,打开就可以直接使用
使用说明
LTX2.3 T2V GGUF 12GB s
T2V是文生视频 text to video,根据你的文字描述来生成视频,带有背景音乐(提供的文字最好是有分镜,画面,声音等描述,不会的可以交给ai生成)
LTX2.3 I2V GGUF 12GB s
I2V是图片生成视频,image to video ,视频主要参考图片来生成,也会同时参考文字内容(如果有的话),适合固定人物
LTX-2.3 Image Audio 2 Video GGUF 12GB s
图片+音频生成视频,也就是音频驱动人像,生成数字人
让图片里的人物按照音频说话,有对应的口型和适当的动作,主要是口播之类的数字人场景
目前本文就这三种玩法,其他更多内容未测试,也不打算深入
Tips
懒人包还是原来的地址和网盘
点击此处 网盘下载
百度网盘已更新,夸克网盘需要今晚或者明早
已知显存占用约10GB左右,建议显存12GB可以尝试,如果显存为8GB,可能有爆显存的问题
启动需要3-10分钟,需要耐心等待,会自动打开浏览器网页才算成功
还有问题,在评论区留言或者私信即可