大数据存储引擎
Log-Structured Merge-Tree · 从设计哲学到底层原理,掌握现代数据库存储引擎的核心数据结构
- RocksDB
- LevelDB
- HBase
- Cassandra
- TiKV
- InfluxDB
- 一、概念定义
- 二、整体架构全景图
- 三、核心子概念详解
- 四、写入与读取流程图
- [五、Compaction 策略对比](#五、Compaction 策略对比)
- 六、与其他概念的关联
- 七、进阶特性与底层原理
- 八、生产实践与调优指南
- 九、完整生命周期图
- 十、总结与学习路线
一、概念定义
LSM-Tree(Log-Structured Merge-Tree,日志结构合并树) 是一种专为高吞吐写入场景设计的存储数据结构,其核心思想是:将随机写转化为顺序写,用空间换取极致的写入性能,再通过周期性的后台合并(Compaction)来控制读放大和空间放大。
它由 Patrick O'Neil 等人于 1996 年在论文 《The Log-Structured Merge-Tree (LSM-Tree)》 中提出,是 LevelDB、RocksDB、HBase、Cassandra、TiKV 等几乎所有主流 NoSQL 和 NewSQL 存储引擎的理论基础。
📖 直观类比:图书馆的"收件箱 + 整理架"模型
想象一个繁忙的图书馆:每本新到的书先扔进"收件箱"(MemTable),当收件箱满了,就整批搬到"临时货架"(SSTable L0),定期再由馆员把多层货架的书按类目合并整理到更大的固定书架(L1、L2、L3)。查书时先翻收件箱,再翻临时货架,最后查固定书架。这种设计让"放书"(写入)极快,而"找书"(读取)需要多看几个地方。
在整个大数据存储体系中,LSM-Tree 填补了传统 B+ 树在高并发写入场景下的性能短板:B+ 树的随机 I/O 写入导致大量磁盘寻道,而 LSM-Tree 通过顺序写和内存缓冲将写入吞吐提升 10~100 倍。
二、整体架构全景图
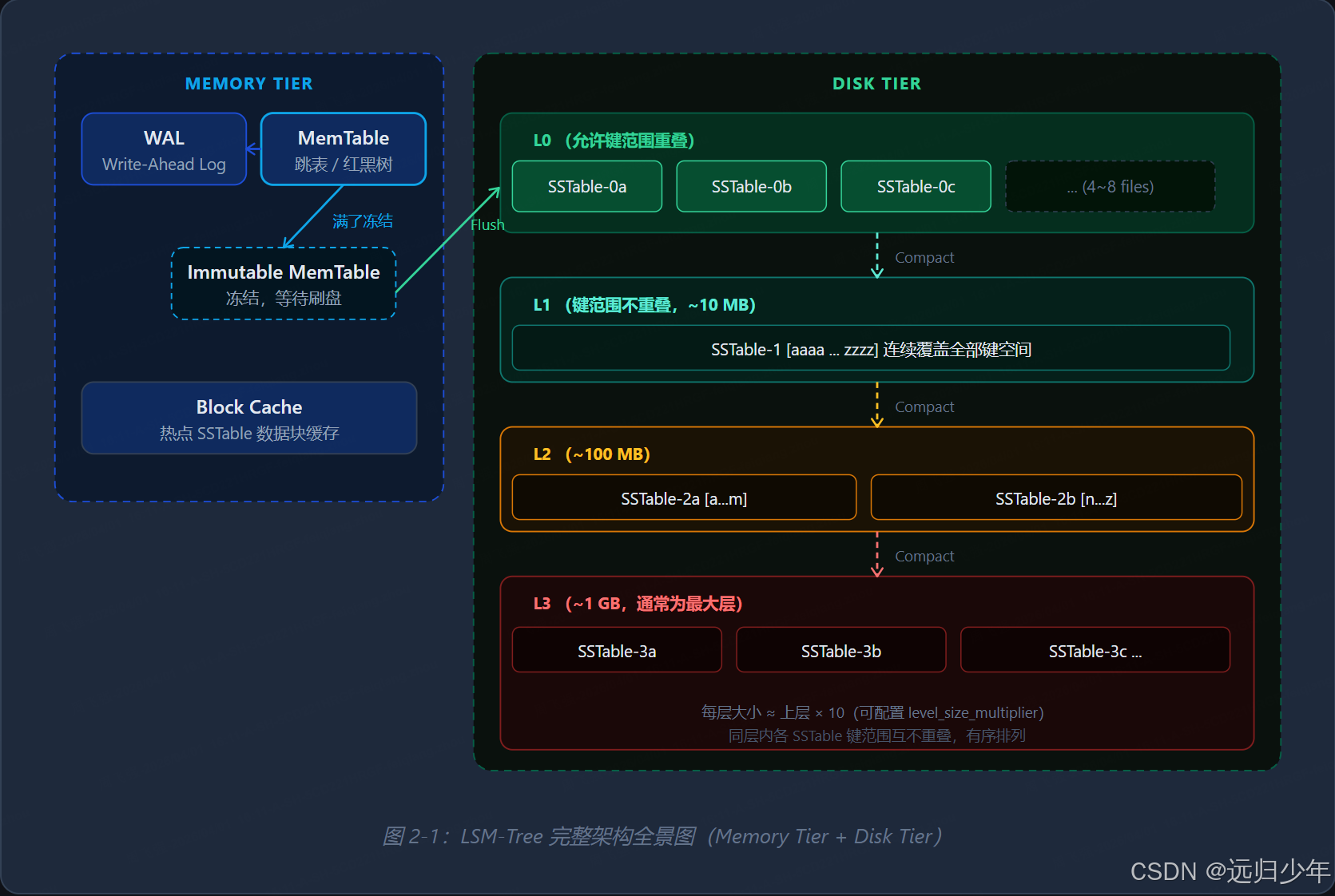
整体架构分为两层:内存层(Memory Tier) 处理实时写入,包含 WAL、MemTable、Immutable MemTable 和 Block Cache;磁盘层(Disk Tier) 以 SSTable 文件形式持久化数据,按层级(Level)组织,层级越深数据越"冷",文件越大,键范围越有序。
三、核心子概念逐一详解
3.1 WAL(Write-Ahead Log,预写日志)
WAL 是 LSM-Tree 的持久化保障机制。每次写操作先以追加方式写入 WAL 文件(顺序 I/O,极快),再写入 MemTable。系统崩溃时,通过重放 WAL 即可恢复 MemTable 中未刷盘的数据。
关键特性: 顺序追加写入(no seek)、固定格式的二进制记录(length + checksum + payload)、MemTable 刷盘成功后对应的 WAL 段可被安全删除。
cpp
// RocksDB WAL 记录结构(简化)
struct WALRecord {
uint32_t checksum; // CRC32 校验
uint16_t length; // payload 字节数
uint8_t type; // FULL / FIRST / MIDDLE / LAST
uint8_t payload[]; // 实际数据(key + value + sequence_number)
};
// WAL 文件名:{sequence_number}.log
// 每个 MemTable 对应一段 WAL,刷盘完成后 WAL 可被删除3.2 MemTable(内存表)
MemTable 是所有写操作的第一落点,通常使用跳表(Skip List)或红黑树实现,保证写入 O(log n) 时间复杂度,同时支持顺序迭代(这对 Flush 时生成有序 SSTable 至关重要)。RocksDB 默认使用跳表,也支持替换为哈希跳表或向量等结构。
go
// RocksDB MemTable 写入示意(Go 伪代码)
func Put(key, value []byte) error {
if wal.Append(key, value) != nil { return err } // 先写 WAL
memtable.Insert(key, value) // 再写内存
if memtable.Size() > threshold {
memtable.Freeze() // 冻结为 Immutable MemTable
memtable = NewMemTable() // 创建新的活跃 MemTable
go flushToDisk() // 后台异步 Flush
}
return nil
}3.3 SSTable(Sorted String Table,有序字符串表)
SSTable 是磁盘上的核心数据结构,文件内键值对按 key 有序排列 ,一经写入不可修改(Immutable)。这一设计让顺序 I/O 成为可能,同时大幅简化了并发控制。

3.4 Bloom Filter(布隆过滤器)
布隆过滤器是每个 SSTable 内置的概率性数据结构,用于在 O(1) 时间内以极低内存判断某个 key 一定不存在于该 SSTable 中。它允许误判(假阳性 false positive),但绝不漏报(无假阴性),误判率通常配置为 1%,每个 key 约消耗 10 bits 内存。这让大多数点查询可以跳过大量不相关的 SSTable,从根本上解决 LSM-Tree 读放大问题。
3.5 Compaction(合并压缩)
Compaction 是 LSM-Tree 的后台"整理"进程,负责将多个 SSTable 文件合并为更少的、更大的有序文件,同时:清除重复 key 的旧版本、删除标记为 Tombstone 的 key、将数据从高层推向低层。Compaction 的策略直接影响写放大(Write Amplification)、读放大(Read Amplification)和空间放大(Space Amplification)之间的权衡,被称为 RAS Tradeoff。
四、工作原理:写入与读取流程
WRITE 写入路径
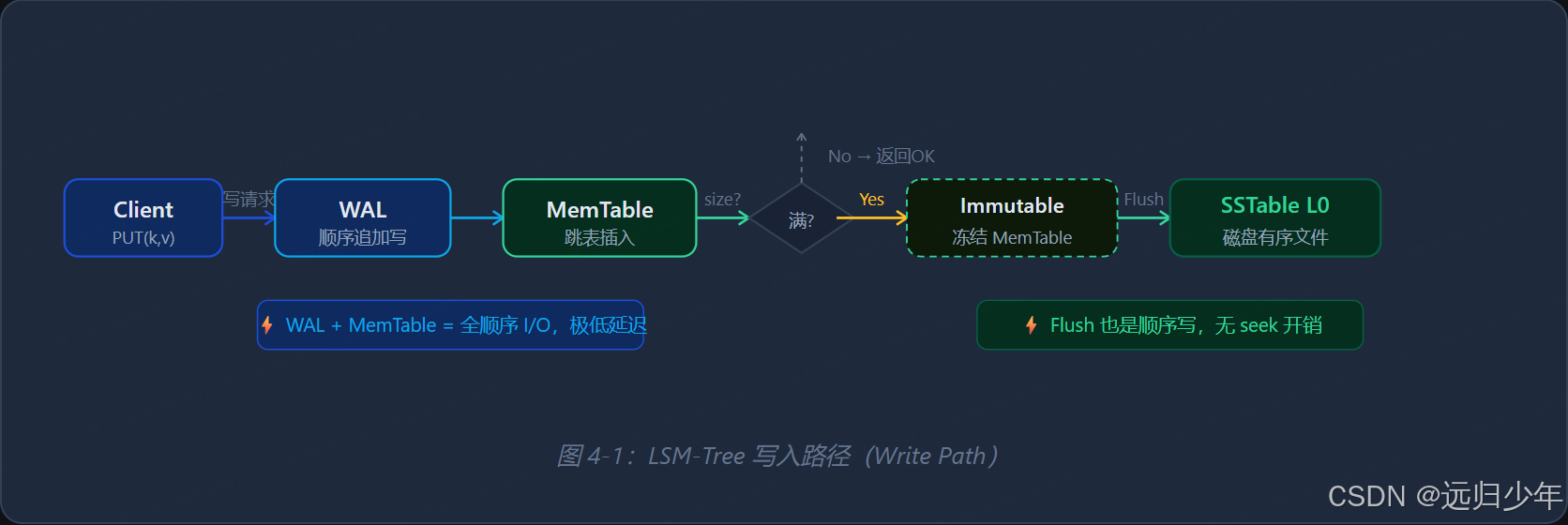
写入延迟极低的秘密:WAL 是顺序追加写(Sequential Append),MemTable 是内存操作,两者都不涉及随机磁盘 I/O。相比 B+ 树每次写入都可能触发随机磁盘寻道,LSM-Tree 的写入延迟稳定且极低,尤其在 SSD 和 HDD 上优势明显。
READ 读取路径
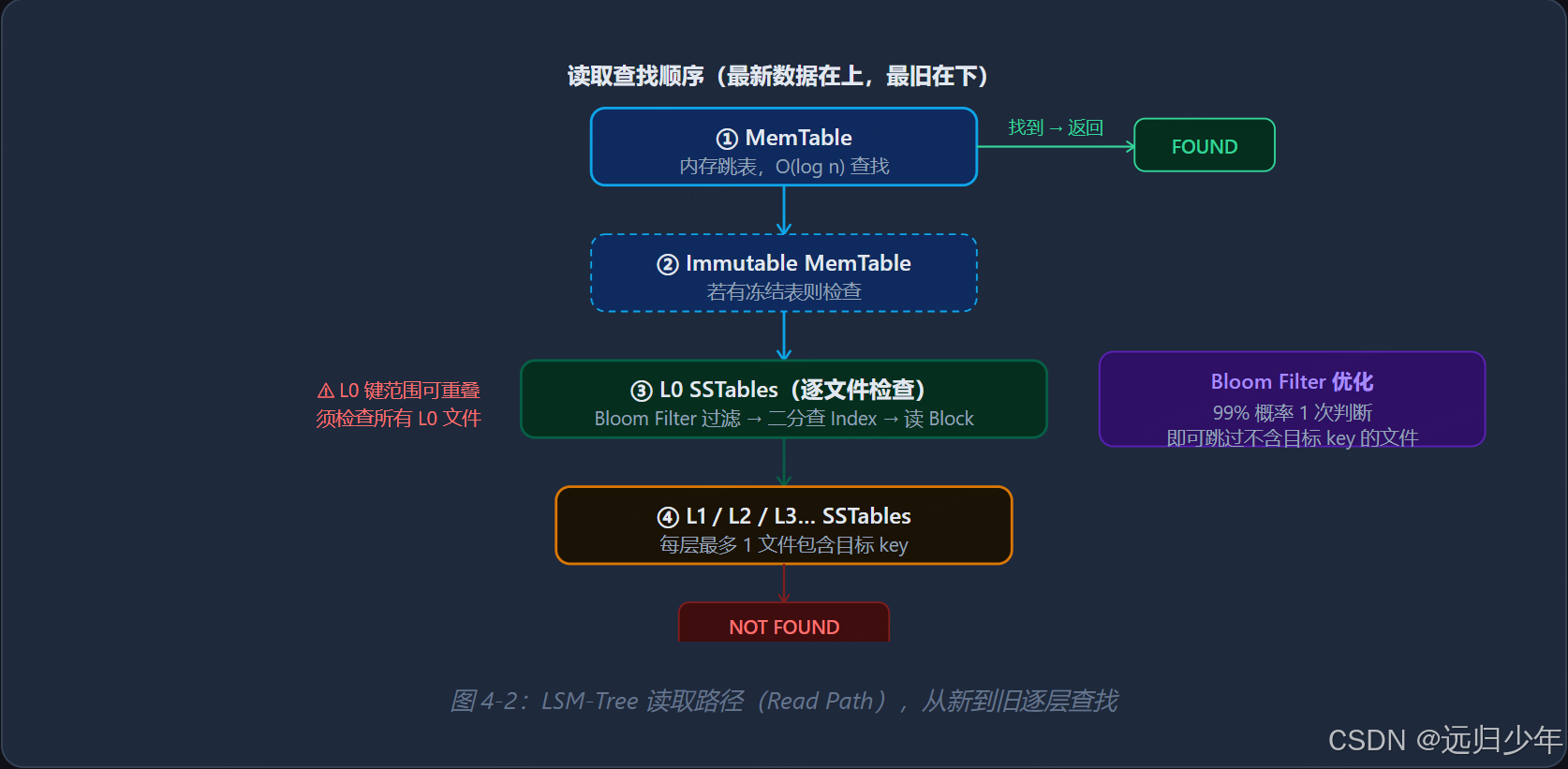
读取的最坏情况需要检查所有层级,但 Bloom Filter 大幅减少了实际 I/O。实践中:**点查(Point Lookup)**通常只需 1~2 次磁盘 I/O;**范围扫描(Range Scan)**在同层内效率极高(文件内有序),但跨层合并需要多路归并,性能略低于 B+ 树。
五、Compaction 策略对比
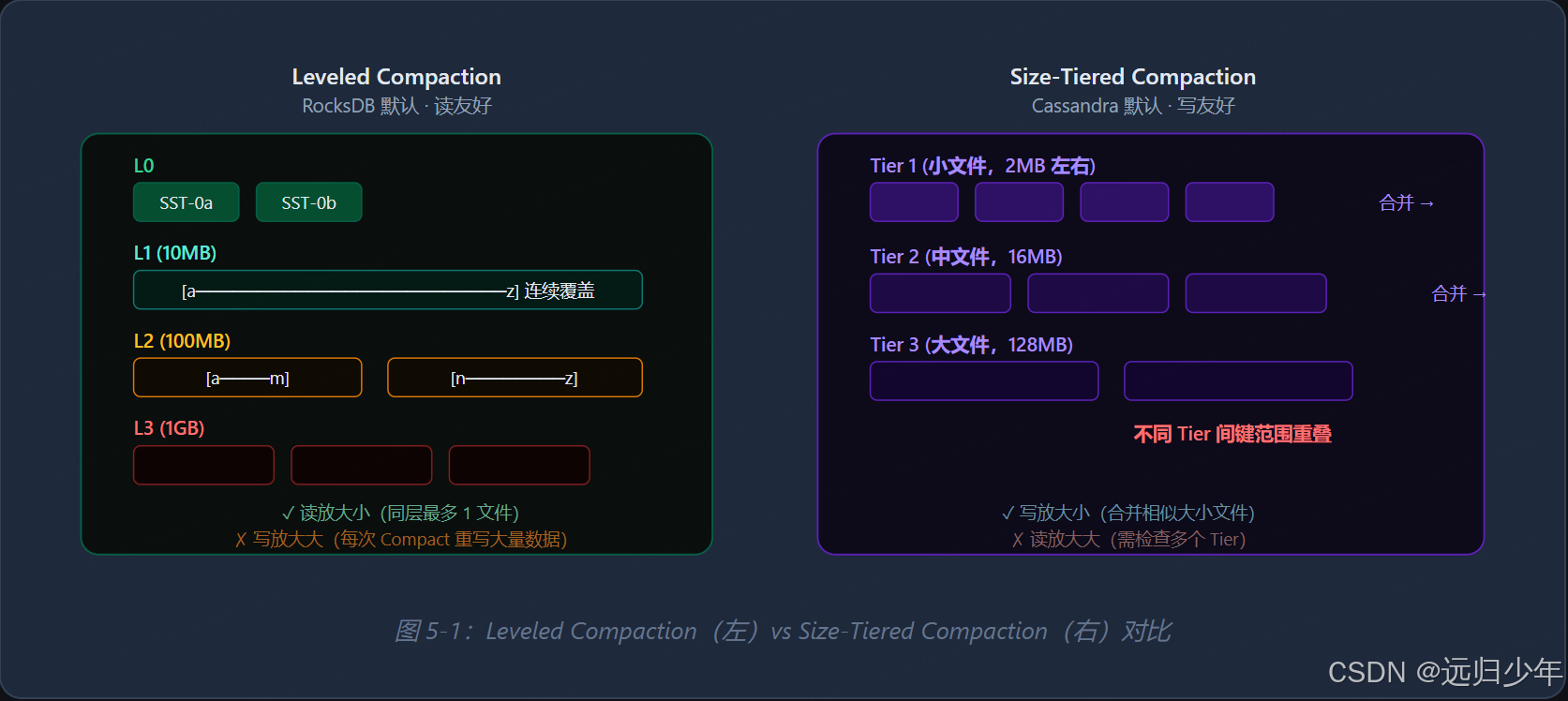
| 策略 | 代表系统 | 写放大 | 读放大 | 空间放大 | 适用场景 |
|---|---|---|---|---|---|
| Leveled | RocksDB, LevelDB, TiKV | 高(10~30x) | 低(≈层数) | 低(≈1.1x) | 读多写少,存储空间敏感 |
| Size-Tiered | Cassandra, ScyllaDB | 低(≈4x) | 高 | 高(2~3x) | 写密集型,时序数据 |
| FIFO | RocksDB(时序场景) | 极低 | 高 | 可控 | 仅保留最新 N 条记录 |
| Universal | RocksDB(可选) | 极低(1~2x) | 中 | 中(2x) | 写极其密集,可接受较高读延迟 |
六、与其他概念的关联关系
LSM-Tree 并不孤立存在,它与以下核心概念紧密协作:
6.1 MVCC(Multi-Version Concurrency Control,多版本并发控制)
LSM-Tree 天然支持 MVCC:每次写入都是新增一条带 Sequence Number 的记录,而不是原地修改。Compaction 时按 sequence 保留最新版本。RocksDB 的 Snapshot 读正是基于此实现的。
go
// RocksDB Snapshot 读示例(Go)
snapshot := db.NewSnapshot()
defer db.ReleaseSnapshot(snapshot)
opts := &ReadOptions{Snapshot: snapshot}
// 此读取会看到 snapshot 创建时刻的数据状态
val, _ := db.Get(opts, []byte("key"))6.2 Iterator / Merge-Sort 迭代器
范围查询需要对多个 SSTable 和 MemTable 同时迭代,底层是一个多路归并堆(Min-Heap),将各来源的迭代器按 key 顺序归并,相同 key 取最新版本(Sequence Number 最大者)。
6.3 Tombstone(墓碑记录)
删除操作不会立即删除数据,而是插入一条 Tombstone(墓碑标记)。只有在 Compaction 且该 Tombstone 已经下沉到最低层时,才会真正清除数据。这意味着删除后在 Compaction 完成之前,磁盘空间不会立即释放。
七、进阶特性与底层原理
7.1 写放大(Write Amplification)的量化分析
写放大系数(Write Amplification Factor, WAF)= 实际写入磁盘的字节数 / 用户写入的字节数。在 Leveled Compaction 中,一条数据从 L0 下沉到 LN 的过程中被重写次数约为:
WAF ≈ N × level_size_multiplier
例如:4 层 × 10 倍比例 = WAF ≈ 40x
即写入 1GB 数据,实际磁盘 I/O 约 40GB------这是 LSM-Tree 在写密集场景下对磁盘寿命(尤其是 SSD)的主要压力
7.2 Bloom Filter 的数学原理
布隆过滤器使用 k 个哈希函数将每个 key 映射到一个大小为 m bits 的位图中。对于 n 个 key,误判率 p 与参数关系如下:
cpp
// 最优参数计算
// 给定 n(key 数量)和目标误判率 p
m = ceil(n * log(p) / log(1 / pow(log(2), 2))) // 位图大小
k = round((m / n) * log(2)) // 哈希函数个数
// RocksDB 中 bits_per_key=10 对应误判率约 1%
// bits_per_key=14 对应误判率约 0.1%(内存消耗更大)
options.filter_policy = NewBloomFilterPolicy(10, false)7.3 Block Cache 分层缓存架构
RocksDB 使用 LRU Cache 或 Clock Cache 缓存热点 SSTable 的 Data Block,同时将 Index Block 和 Bloom Filter Block 缓存在独立的更高优先级区域(Pin to Top-Level),确保元数据命中率接近 100%,避免每次查询都因 Index 缺失而触发额外 I/O。
cpp
// RocksDB Block Cache 配置示例
auto cache = NewLRUCache(
4 * 1024 * 1024 * 1024LL, // 4GB Block Cache
-1, // num_shard_bits(-1 = 自动)
false, // strict_capacity_limit
0.9 // high_pri_pool_ratio:90% 给 Index/Filter
);
BlockBasedTableOptions t_opts;
t_opts.block_cache = cache;
t_opts.cache_index_and_filter_blocks = true;
t_opts.pin_top_level_index_and_filter = true;八、生产实践与调优指南
| 常见问题 | 根因 | 解决方案 |
|---|---|---|
| 写入停滞(Write Stall) | L0 文件数超过 level0_slowdown_writes_trigger,Compaction 速度跟不上写入 |
增大 max_background_compactions;降低写入速率;使用 Rate Limiter |
| 读性能劣化 | Bloom Filter 未启用或 bits_per_key 太低;Block Cache 命中率低 | 启用 Bloom Filter(≥10 bits/key);增大 Block Cache;Pin index/filter blocks |
| 磁盘空间膨胀 | Tombstone 积压未被 Compaction 清理;Size-Tiered 策略空间放大 | 调小 max_compaction_bytes;显式触发 CompactRange;考虑切换 Leveled Compaction |
| SSD 寿命快速消耗 | 写放大过高(WAF > 30) | 开启 use_direct_io_for_flush_and_compaction;降低 max_bytes_for_level_multiplier;使用 Universal Compaction |
| 范围查询慢 | LSM-Tree 多层数据需多路归并迭代 | 避免大范围扫描;使用前缀 Bloom Filter;考虑 Prefix Extractor 减少检查范围 |
| 启动恢复慢 | WAL 太大,重放耗时长 | 调小 max_total_wal_size;增加 MemTable flush 频率;使用 avoid_flush_during_recovery 优化 |
关键配置参数速查(RocksDB)
write_buffer_size (默认 64MB)
单个 MemTable 的大小上限。调大可减少 flush 次数(降低写放大),但增加内存用量和宕机恢复时间。推荐 64MB~256MB。
max_write_buffer_number (默认 2)
允许同时存在的 MemTable 数(含 Immutable)。调大可在 flush 卡顿时提供缓冲,避免 Write Stall。推荐 3~6。
level0_file_num_compaction_trigger (默认 4)
L0 文件达到此数量时触发 Compaction。调大可减少 Compaction 频率但增加读放大。
target_file_size_base (默认 64MB)
L1 层单个 SSTable 的目标大小。与 level_size_multiplier 共同决定层级结构。
最佳实践建议
✅ 始终开启 Bloom Filter:对于点查密集的场景(如缓存、用户数据存储),10 bits/key 的 Bloom Filter 可消除 99% 的无效磁盘 I/O,是收益最大的单项优化。
✅ 将 Block Cache 设置为可用内存的 30%~50%:确保热点数据常驻内存,尤其要 Pin Index Block 和 Filter Block,让元数据的读取完全在内存中完成。
✅ 监控写放大系数(WAF):生产环境 WAF 超过 30x 时需排查 Compaction 策略是否合理;SSD 设备上 WAF 是影响磁盘寿命的关键指标。
✅ 时序数据使用 FIFO Compaction + TTL :对于按时间写入的监控数据,FIFO 策略配合compaction_options_fifo.ttl可实现低开销的数据自动过期,写放大接近 1x。
✅ 批量写入使用 WriteBatch:将多条写操作合并为一个 WriteBatch 原子提交,可以显著减少 WAL sync 次数,提升吞吐量 5~10 倍。
九、完整生命周期图
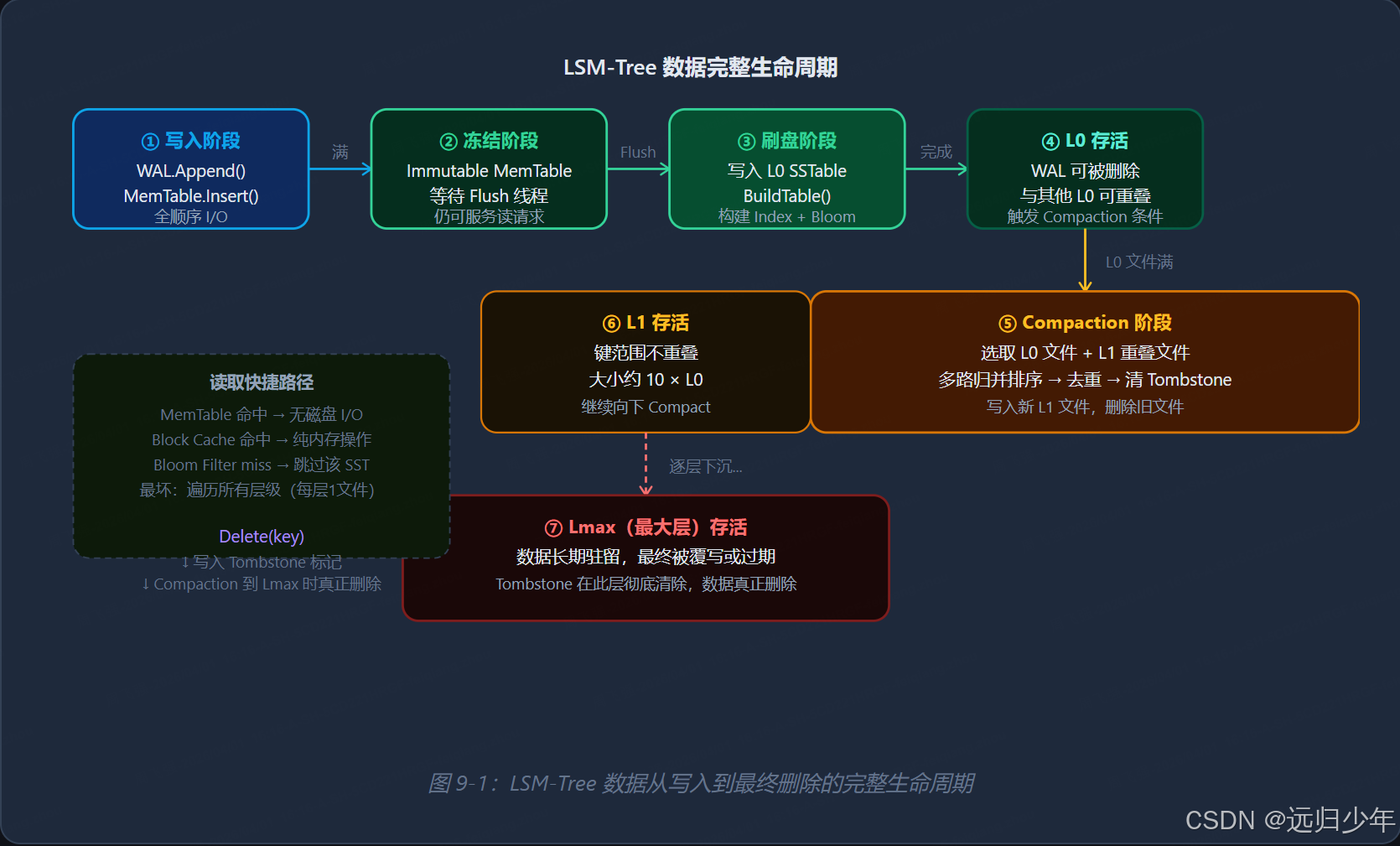
十、总结与学习路线
LSM-Tree 学习路径
├── 入门基础
│ ├── 理解顺序写 vs 随机写的性能差异(I/O 原理)
│ ├── 掌握 MemTable / WAL / SSTable 的定义与职责
│ └── 动手运行 LevelDB 或 RocksDB 的入门 Demo
│
├── 核心机制
│ ├── 写入路径全流程(WAL → MemTable → Flush → L0)
│ ├── 读取路径(MemTable → Immutable → L0 → LN)
│ ├── Bloom Filter 原理与参数调优
│ └── Compaction 触发条件与 Leveled vs Size-Tiered 对比
│
├── 进阶专题
│ ├── 写放大 / 读放大 / 空间放大的量化分析
│ ├── MVCC + Snapshot + Sequence Number 机制
│ ├── Block Cache 分层缓存架构(LRU / Clock)
│ └── RocksDB 源码阅读:version_set.cc / compaction.cc
│
└── 生产实战
├── 调优实战:监控 WAF / Block Cache 命中率 / Compaction Score
├── 场景选型:时序数据(FIFO)/ 用户数据(Leveled)/ 日志数据(Size-Tiered)
├── 高级特性:Column Family / Prefix Bloom / Rate Limiter / Titan(分离大 Value)
└── 延伸学习:TiKV(Raft + RocksDB)/ InfluxDB IOx / Pebble(CockroachDB)核心记忆要点
① 写入全顺序化:WAL 追加 + MemTable 内存写,彻底消除随机磁盘寻道,这是 LSM-Tree 高写入吞吐的根本原因。
② SSTable 不可变性:一旦写入磁盘永不修改,极大简化并发控制,实现 Lock-Free 读取。
③ 读写放大的本质权衡:降低写放大(Size-Tiered)会增加读放大;降低读放大(Leveled)会增加写放大。没有免费的午餐。
④ Bloom Filter 是读性能的关键防线:每个 SSTable 1% 的误判率,就能将 99% 的无效 I/O 消灭在内存中。
⑤ Compaction 是异步后台进程:写入速度超过 Compaction 速度会触发 Write Stall,这是生产中最常见的性能问题。
⑥ 删除不是立即生效:Tombstone 需要等到 Compaction 下沉到 Lmax 才能真正清除数据和释放空间。
⑦ 层级大小倍数(level_size_multiplier)决定 WAF:默认 10x 意味着 4 层结构 WAF ≈ 40x,对 SSD 寿命有显著影响。
⑧ LSM-Tree ≠ 万能:点查和顺序扫描优秀,但大范围随机读、频繁更新小字段的场景,B+ 树(如 InnoDB)更合适。
参考资料
| 资源 | 类型 | 说明 |
|---|---|---|
| O'Neil et al. (1996) - The LSM-Tree Paper | 论文 | LSM-Tree 原始论文,ACM Digital Library |
| RocksDB Wiki (github.com/facebook/rocksdb) | 官方文档 | 最权威的 LSM-Tree 生产实践指南 |
| 《数据库系统内幕》- Alex Petrov | 书籍 | 第 7 章详细讲解 LSM-Tree 存储引擎设计 |
| LevelDB 源码(github.com/google/leveldb) | 源码 | 精简实现,适合入门阅读,约 1.5 万行 C++ |
| 《Designing Data-Intensive Applications》- Kleppmann | 书籍 | 第 3 章 Storage Engines,英文必读经典 |