Hive 是大数据离线数仓的核心组件。我们这次将系统讲解 Hive 的安装、配置、Metastore 初始化及 DataGrip 连接实战,帮助你快速完成 Hive 环境搭建。
一、准备工作:安装 Hive 的先决条件
在正式开始安装 Hive 之前,请确保你的环境已经满足以下基本要求:Java 环境已安装、Hadoop 集群已启动并运行正常、MySQL环境已安装
二、下载并解压 Hive 安装包
- 访问 Apache Hive 官网:前往 Apache Hive 的官方网站 (hive.apache.org) 的下载页面。

-
选择合适的版本 :根据你的 Hadoop 版本和需求,选择一个稳定的 Hive 版本进行下载 (
apache-hive-x.y.z-bin.tar.gz)。- 假设你已经将安装包上传到
/export/softwares目录下,例如apache-hive-3.1.2-bin.tar.gz。
- 假设你已经将安装包上传到
-
解压安装包到指定目录 :将安装包解压到
/export/server目录下。- 示例解压命令:
bash
cd /export/softwares # 首先进入安装包所在目录
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /export/server/- 重命名目录为
hive:- 示例重命名命令:
bash
cd /export/server/
mv apache-hive-3.1.2-bin hive现在,你的 Hive 安装路径就是 /export/server/hive。
三、配置 Hive 环境变量
- 编辑配置文件
- 示例编辑命令 (当前用户):
bash
vim /etc/profile- 添加以下内容 :
bash
# HIVE_HOME
export HIVE_HOME=/export/server/hive
export PATH=$PATH:$HIVE_HOME/bin
export PATH=$PATH:/export/server/hive/bin- 使配置生效:
bash
source /etc/profile四、配置 Hive 核心文件
Hive 的核心配置在 $HIVE_HOME/conf (即 /export/server/hive/conf) 目录下。
hive-env.sh:- 复制模板并编辑:
bash
cd $HIVE_HOME/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh- 在
hive-env.sh中主要配置 (取消注释并修改):
bash
export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=$HIVE_HOME/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/libhive-site.xml:- 创建
hive-site.xml:
- 创建
bash
vim hive-site.xml- 在
hive-site.xml中添加或修改以下核心配置 (以 MySQL 为例): 注意:以下配置是非常基础的示例。
xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&allowPublicKeyRetrieval=true</value>
<description>JDBC connect string for a JDBC metastore. Added allowPublicKeyRetrieval=true for MySQL 8+ compatibility.</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore. Use com.mysql.cj.jdbc.Driver for MySQL 8+.</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value> </property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop01</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop01:9083</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>五、准备 Metastore 数据库 (以 MySQL 为例)
- 安装 MySQL 。 详细安装教程参考《CentOS 7 yum 安装 MySQL 并实现任意主机远程连接》
- 准备 MySQL JDBC 驱动 。
- 下载 MySQL JDBC 驱动 JAR 文件。
bash
wget https://repo1.maven.org/maven2/com/mysql/mysql-connector-j/8.4.0/mysql-connector-j-8.4.0.jar -O /tmp/mysql-connector-j-8.4.0.jar- 将 JAR 文件复制到
$HIVE_HOME/lib/(即/export/server/hive/lib/) 目录下。 示例复制命令:
bash
cp /tmp/mysql-connector-j-8.4.0.jar /export/server/hive/lib/六、初始化 Hive Metastore Schema (首次安装时执行)
- 执行 schema 初始化命令:
bash
$HIVE_HOME/bin/schematool -dbType mysql -initSchema -verbose如果看到 "Schema initialization SUCCESS",则初始化成功。 
创建Hive存储文件的目录:
bash
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
mkdir -p /export/server/hive/logs拷贝到hadoop02,hadoop03下面:
bash
cd /export/server/
scp -r hive hadoop02:$PWD
scp -r hive hadoop03:$PWD七、启动 Hive 服务和客户端 CLI
- 启动 HiveServer2 (重要!DataGrip 连接需要) :
- 后台启动 HiveServer2 命令:
bash
nohup /export/server/hive/bin/hive --service metastore > /export/server/hive/logs/metastore.log 2>&1 &
nohup /export/server/hive/bin/hive --service hiveserver2 > /export/server/hive/logs/hiveserver2.log 2>&1 &请确保 HiveServer2 服务已成功启动并正在运行,可以尝试使用一下命令来进行检查。
bash
# 1. 检查后台任务列表 (看是否有对应的 nohup 任务在运行)
jobs -l
# 2. 检查 Java 进程 (看是否有 Metastore 和 HiveServer2 对应的 Java 进程)
jps
# 3. 检查网络端口监听 (看 9083 和 10000 端口是否被监听)
netstat -naltp | grep 9083
netstat -naltp | grep 10000- (可选)启动 Hive CLI (用于直接命令行操作) :
- 启动命令:
bash
hive示例 HQL 命令 (查看数据库):
sql
hive> SHOW DATABASES;八、在 DataGrip 中连接 Hive
DataGrip 是一款强大的数据库 IDE。
- 打开 DataGrip。
- 新建数据源 (Data Source) :
+->Data Source->Apache Hive。
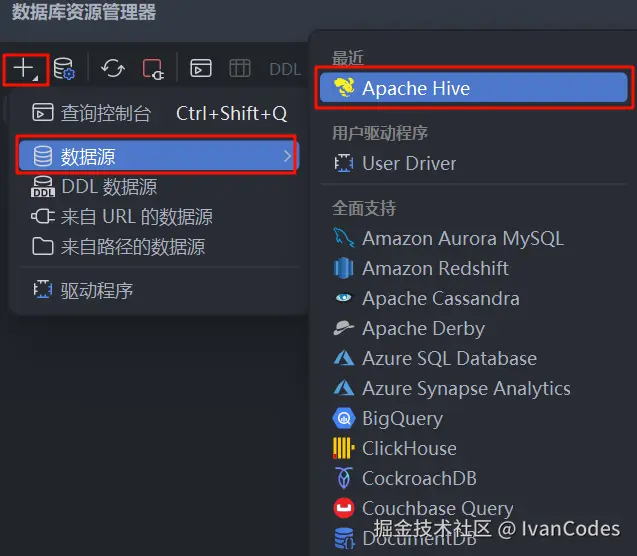
- 配置连接参数 :
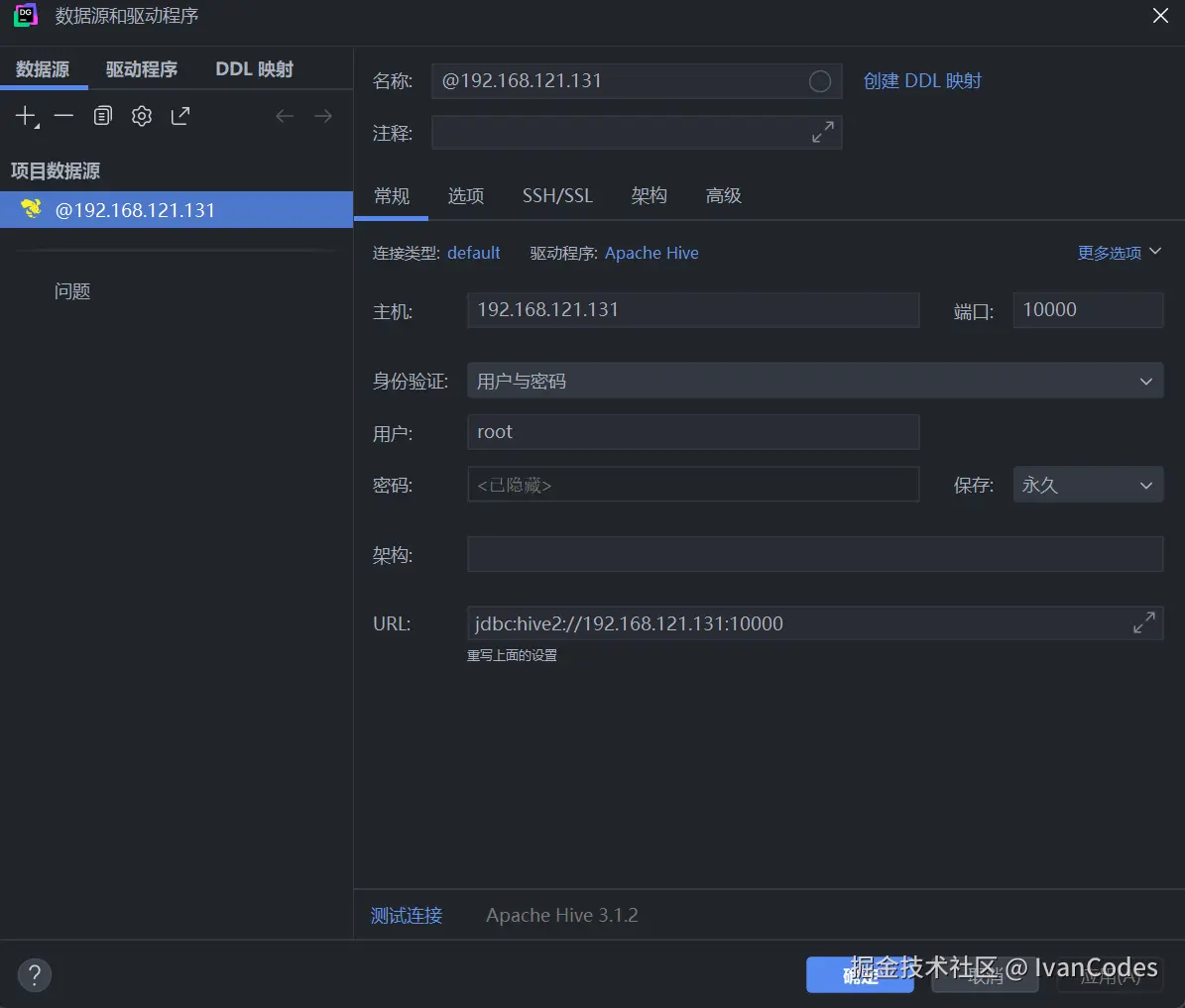
- 名称 : 自定义连接名 (例如
MyHiveCluster)。 - 主机: HiveServer2 主机名或 IP。
- 端口 : HiveServer2 端口号 (默认
10000)。 - 用户: 连接用户名 (若无特定认证,可留空或填 Hadoop 用户)。
- 密码: 对应密码。
- 名称 : 自定义连接名 (例如
-
测试连接 (Test Connection):
- 点击
Test Connection按钮。成功则显示 "Succeeded"。✅
- 点击
-
保存并连接:
- 点击
确定或应用。
- 点击
九、常见问题与排错提示
- DataGrip 连接 HiveServer2 超时或拒绝连接:检查 HiveServer2 服务状态、主机/端口配置、防火墙。
- JDBC 驱动问题:确保 DataGrip 加载了正确且完整的 Hive JDBC 驱动。
- 认证问题:若 HiveServer2 配置了认证,DataGrip 连接需相应调整。
- MySQL JDBC 驱动问题:强调
hive-site.xml中 javax.jdo.option.ConnectionDriverName (MySQL 8.x 用 com.mysql.cj.jdbc.Driver) 与$HIVE_HOME/lib/下的 ==JDBC JAR 版本必须匹配==,且旧版驱动要移除。 - MySQL 连接参数:如 serverTimezone, allowPublicKeyRetrieval 对 MySQL 8.x 的重要性。 Hadoop htrace-core*.jar 丢失问题:指出 Hadoop 的
common/lib目录可能缺少此文件,以及如何从 Maven 或 Hadoop 安装包恢复。 - Guava 版本冲突:解释 Hive 自带 Guava 与 Hadoop Guava 的版本差异,以及如何通过重命名 Hive 的 Guava JAR 来解决。
- Hive lib 目录完整性:强调如果 Hive 缺少核心类(如 ParseException),可能需要从原始安装包恢复整个 lib 目录。
- 服务启动日志检查:指导用户如何查看
nohup.out或$HIVE_HOME/logs/下的日志文件来定位服务启动失败的原因。 - getcwd 错误:提示用户不要在已被删除的目录中执行命令。
- HDFS 权限和目录:确保 Hive 在 HDFS 上的工作目录存在且权限正确。
恭喜你!你不仅搭建了 Hive 数据仓库,还能通过强大的 DataGrip 工具进行可视化操作和查询。大数据分析之旅,现在才刚刚开始!