前言
前段时间主要在做遥感去雾实验以及写小论文,目前也是顺利的投出去了,近期我从小目标检测转到做遥感变化检测研究,这段时间也看了一些开源的工具,如rschange、torchange、open-cd,于是我自己参考了一下rschange写了一个用于训练模型的代码,方便做对比实验。当前变化检测领域正往大模型方向SAM、Cilp、DINO等方面靠,但我个人仍倾向于从CNN和Transformer的结构创新入手,今天要介绍的是具有并行通道-空间交互与聚合的双流网络DCSI-UNet。
论文地址:A Dual-Stream UNet With Parallel Channel--Spatial Interaction and Aggregation for Change Detection
代码仓库:https://github.com/ZChaoyv/DCSI-UNet
我创建了一个用于复现变化检测模型的仓库:https://github.com/Auorui/CDLab
变化检测的难点
变化检测通常建立端到端的单流或双流网络对输入的双时相图像进行对比分析,生成像素级二值变化图,但本质上就是像素级二分类任务。作者这里抓住了一个问题,就是由于成像时间不同,会有一下伪变化影响结果,如下图所示:
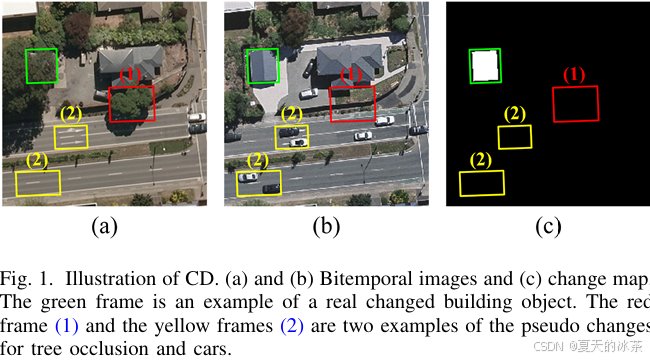
其中红色框(1)和黄色框(2),树木的遮挡以及形式的车辆都是与任务无关的伪变化,这个点就是对于差异特征的挖掘不够充分,所以需要增强差异特征的捕捉,减少与任务无关的干扰。
另外,一些传统的方法仅通过特征相减提取差异,没有对双时相特征在通道、空间维度的交互,导致隐藏差异难以捕捉,说明对双时相特征之间交互不够,另外通道注意力和空间注意力常被单独使用,无法兼顾变化区域的边缘细节和语义相关性。
总结一下里面的内容,就是目前很多方法忽略了F1与F2之间的关系,只看差值,而不是去看为什么不同;Transformer确实能建模全局,计算量大还是单独处理特征,没有做到交互;现有注意力(通道、空间)没有联合建模。
作者解决的思路也很清晰,在"通道 + 空间"两个维度,同时做"跨时相交互"。在编码器阶段,用双流结构分别提取双时相特征,然后并行引入两个模块,CGIM 做通道维交互;SGAM 做空间维交互。解码阶段除了常规 skip connection,还引IAM 聚合多层通道/空间交互特征入,最后用一个 weight adaptive prediction head 来融合三个分支预测结果。
网络结构
下图为论文当中DCSI-UNet的结构图,在前面的编码阶段采用的ResConv获取双时相特征图,ResConv如下图右下角所示,将这两个特征输入到CGIM和SGAM模块,增强特征在通道维度与空间维度上的交互作用,再经过跳跃连接对经过这两个模块的交互特征进行解码,四个解码过程的特征再经过IAM模块进行聚合,与原本解码的两个特征经过权重自适应预测头预测变化图。
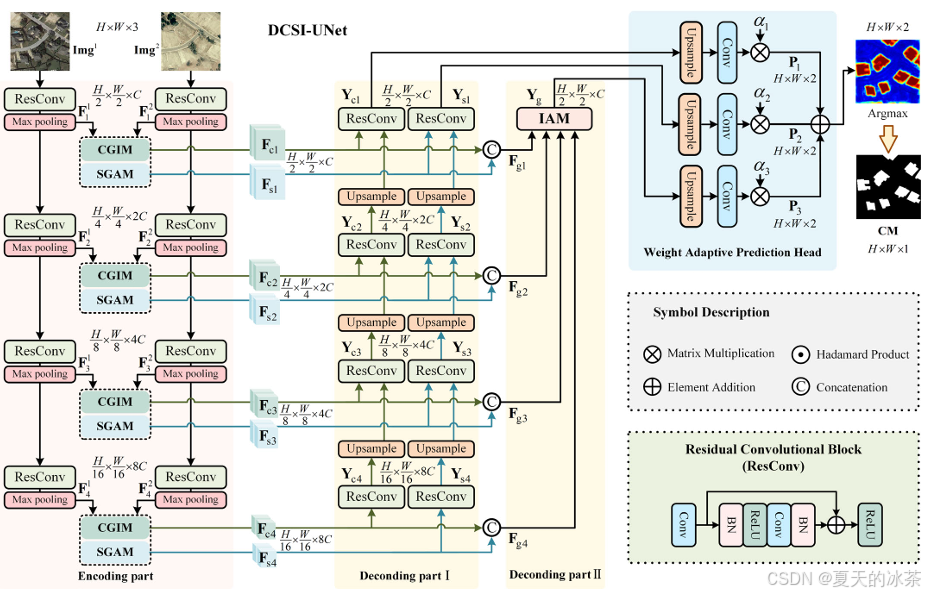
输入:img1、img2
S1: 双流编码器
→ 获得多层特征F1、F2
S2: 每一层做:
→ CGIM (通道交互)
→ SGAM(空间交互)
S3: 解码(两条支路)
→ Channel分支
→ Spatial分支
S4: IAM融合(重点!)
→ 多尺度 + 通道空间融合
S5: 输出预测
整个过程比较易理解,接下来我们来学习一下这篇文章中提出的模块。
通道组交互模块CGIM
这个模块的目的是,不同通道之间是如何体现变化呢?是根据F1和F2共同生成 Query。
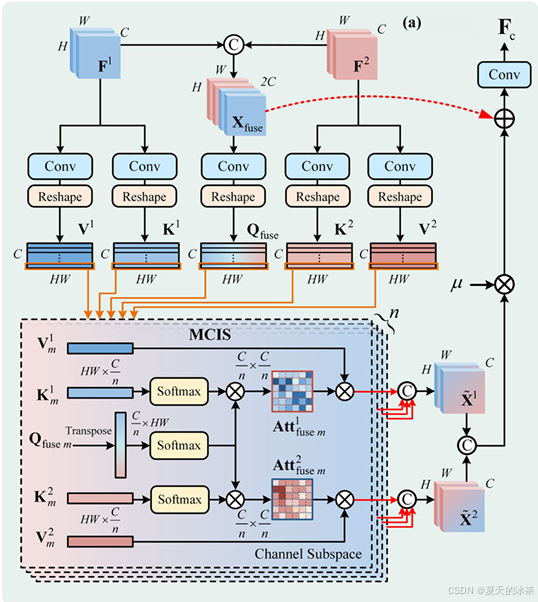
Query是共享认知,Key/Value是各自的信息。我们知道标准的Transformer是在HWxHW的空间维度做attention,用于建模像素与像素之间的关系,这里则是在通道。pytorch的matmul默认是:
python
(..., N, d) × (..., d, M) → (..., N, M)为了让 attention 发生在"通道维度",必须对张量进行重排,使其满足矩阵乘法的维度要求,所以必须把Q维度摆成(batch, heads, HW, C/head),这里把通道拆成多个子空间,结果就是每一个空间位置(HW)都有一个通道分布(Softmax概率,dim=-1)
而Key/Value的维度则是(batch, heads, C/head, HW),最终得到的是一个通道 × 通道的注意力矩阵(batch, heads, C/head, C/head)。
随后,该注意力矩阵作用于 Value,对原始通道特征进行加权重组,使每一个通道能够融合来自其他通道的信息,从而实现跨通道的语义交互。
上述的详细过程可如下面的代码所示:
python
class CGIM(nn.Module):
def __init__(self, in_channels, out_channels, num_heads=4):
super(CGIM, self).__init__()
self.num_heads = num_heads
self.in_channels = in_channels
self.query = nn.Conv2d(in_channels * 2, in_channels, kernel_size=1)
self.key1 = nn.Conv2d(in_channels, in_channels, kernel_size=1)
self.value1 = nn.Conv2d(in_channels, in_channels, kernel_size=1)
self.key2 = nn.Conv2d(in_channels, in_channels, kernel_size=1)
self.value2 = nn.Conv2d(in_channels, in_channels, kernel_size=1)
self.mu = nn.Parameter(torch.zeros(1))
self.conv_cat = nn.Sequential(
nn.Conv2d(in_channels * 2, out_channels, 3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU())
self.softmax = nn.Softmax(dim=-1)
def forward(self, F1, F2):
Q_fuse = self.query(torch.cat([F1, F2], dim=1))
batch_size, channels, height, width = Q_fuse.shape
# Reshape for multi-head attention / 针对多头注意力进行重塑
Q_fuse = Q_fuse.view(batch_size, self.num_heads, -1, height * width).permute(0, 1, 3, 2)
K1 = self.key1(F1).view(batch_size, self.num_heads, -1, height * width)
V1 = self.value1(F1).view(batch_size, self.num_heads, -1, height * width)
K2 = self.key2(F2).view(batch_size, self.num_heads, -1, height * width)
V2 = self.value2(F2).view(batch_size, self.num_heads, -1, height * width)
# Cross attention / 交叉注意力
Att_1 = torch.matmul(self.softmax(K1), self.softmax(Q_fuse))
X1_wave = torch.matmul(Att_1, V1).view(batch_size, -1, height, width)
Att_2 = torch.matmul(self.softmax(K2), self.softmax(Q_fuse))
X2_wave = torch.matmul(Att_2, V2).view(batch_size, -1, height, width)
return self.conv_cat(torch.cat([self.mu * X1_wave + F1, self.mu * X2_wave + F2], dim=1))空间高斯注意力模块SGAM
SGAM是解决空间上哪里发生了真实变化,这里用到了高斯分布建模差异。我们知道在变化检测里面,光影等变化并非是真实变化,学习的应该是这里面的异常点。
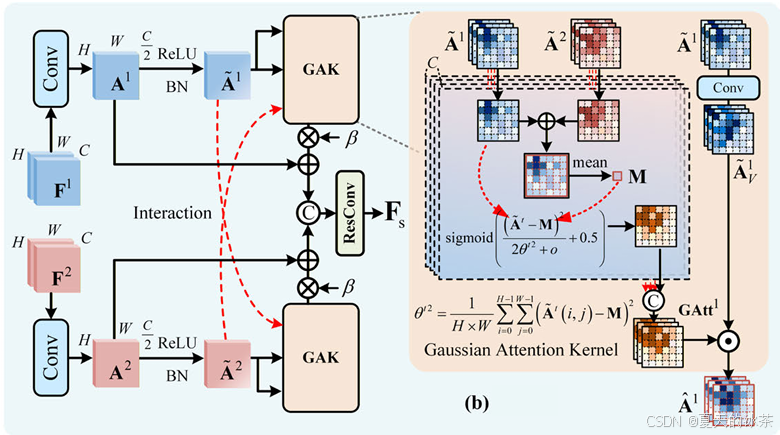
输入的特征首先进行1x1卷积降维,得到低维特征A1和A2,随后,对二者进行融合,计算其平均特征M = (A1 + A2) / 2,该平均特征 M 可以被视为双时相的共享参考分布。
在此基础上,再通过高斯建模来刻画特征偏离程度,显示计算空间均值μ = mean(M),然后计算每个位置相对于该均值的平方偏差(A - μ)^2,并进一步得到方差σ² = sum((A - μ)^2) / (H × W),最终构建高斯响应,对权重映射应用sigmoid函数进行归一化,以获得高斯注意力分数。
python
import torch
import torch.nn as nn
class CMConv(nn.Module):
def __init__(self, in_ch, out_ch, kernel_size=3, stride=1, padding=1, dilation=3, groups=1, dilation_set=4,
bias=False):
super(CMConv, self).__init__()
self.prim = nn.Conv2d(in_ch, out_ch, kernel_size, stride, padding=dilation, dilation=dilation,
groups=groups * dilation_set, bias=bias)
self.prim_shift = nn.Conv2d(in_ch, out_ch, kernel_size, stride, padding=2 * dilation, dilation=2 * dilation,
groups=groups * dilation_set, bias=bias)
self.conv = nn.Conv2d(in_ch, out_ch, kernel_size, stride, padding, groups=groups, bias=bias)
# Gradient masking hook / 梯度掩码 Hook
def backward_hook(grad):
out = grad.clone()
out[self.mask.bool()] = 0
return out
self.mask = torch.zeros(self.conv.weight.shape).byte().cuda()
_in_channels = in_ch // (groups * dilation_set)
_out_channels = out_ch // (groups * dilation_set)
# Generate mask / 生成掩码
for i in range(dilation_set):
for j in range(groups):
self.mask[(i + j * groups) * _out_channels: (i + j * groups + 1) * _out_channels,
i * _in_channels: (i + 1) * _in_channels, :, :] = 1
self.mask[((i + dilation_set // 2) % dilation_set + j * groups) * _out_channels: ((
i + dilation_set // 2) % dilation_set + j * groups + 1) * _out_channels,
i * _in_channels: (i + 1) * _in_channels, :, :] = 1
self.conv.weight.data[self.mask.bool()] = 0
self.conv.weight.register_hook(backward_hook)
self.groups = groups
def forward(self, x):
# Channel splitting and merging / 通道拆分与合并
x_split = (z.chunk(2, dim=1) for z in x.chunk(self.groups, dim=1))
x_merge = torch.cat(tuple(torch.cat((x2, x1), dim=1) for (x1, x2) in x_split), dim=1)
x_shift = self.prim_shift(x_merge)
return self.prim(x) + self.conv(x) + x_shift
class SGAM_Conv_Block(nn.Module):
def __init__(self, in_ch, out_ch):
super(SGAM_Conv_Block, self).__init__()
self.conv1 = nn.Conv2d(in_ch, out_ch, kernel_size=3, padding=1)
self.BN1 = nn.BatchNorm2d(out_ch)
self.ReLU = nn.ReLU(inplace=False)
self.conv2 = CMConv(out_ch, out_ch, kernel_size=3, padding=1)
self.BN2 = nn.BatchNorm2d(out_ch)
def forward(self, x):
x = self.conv1(x)
return self.ReLU(x + self.BN2(self.conv2(self.ReLU(self.BN1(x)))))
class GaoSi_core(nn.Module):
def __init__(self, in_ch):
super(GaoSi_core, self).__init__()
def forward(self, M, A):
_, _, h, w = A.size()
q = M.mean(dim=[2, 3], keepdim=True) # Spatial mean / 空间均值
k = A
square = (k - q).pow(2) # Variance calculation / 方差计算
sigma = square.sum(dim=[2, 3], keepdim=True) / (h * w)
att_score = square / (2 * sigma + 1e-8) + 0.5
att_weight = nn.Sigmoid()(att_score)
return att_weight * A
class SGAM(nn.Module):
def __init__(self, in_ch, out_ch):
super(SGAM, self).__init__()
native_ch = out_ch // 2
self.SGAM_conv = nn.Conv2d(in_ch, native_ch, kernel_size=1)
self.BN1 = nn.BatchNorm2d(native_ch)
self.ReLU = nn.ReLU(inplace=True)
self.GaoSi = GaoSi_core(native_ch)
self.conv_finally = SGAM_Conv_Block(out_ch, out_ch)
self.beta = nn.Parameter(torch.zeros(1))
def forward(self, F1, F2):
A1 = self.SGAM_conv(F1)
A2 = self.SGAM_conv(F2)
A1_wave = self.ReLU(self.BN1(A1))
A2_wave = self.ReLU(self.BN1(A2))
M = (A1_wave + A2_wave) * 0.5 # Mutual feature / 交互特征
A1_hat = self.GaoSi(M, A1)
A2_hat = self.GaoSi(M, A2)
result = torch.cat([A1_hat * self.beta + A1, A2_hat * self.beta + A2], dim=1)
return self.conv_finally(result)实际上这个机制属于是基于统计分布的空间异常检测,从直观上来看,当某一位置特征接近均值μ时,说明其与整体分布一致,通常对应于未发生变化的区域,其权重较低;而当某一位置显著偏离均值时,说明其属于分布中的"异常点",更可能对应真实变化区域,其权重较高。
这里作者通过引入高斯分布的空间建模方法,将双时相特征的平均表示作为参考分布,对偏离该分布的区域进行自适应加权,从而显式建模变化区域。该方法将变化检测问题转化为统计意义上的异常检测问题,相比传统基于相关性的注意力机制,能够更有效地区分真实变化与伪变化,提高空间定位的准确性,我个人认为这里的创新其实是比通道部分更有意思。
当然,这里的高斯建模更应该理解为是一种判别的近似,通过构造双时相特征的平均表示作为参考分布,利用偏离程度来衡量潜在变化,而非对真实数据分布进行精确建模,一定程度上能抑制一些光照等变化,但对于复杂场景如非均匀光照变化、大范围背景扰动会影响对伪变化的抑制能力,我觉得这个模块要与通道交互模块一起协同最佳。
交互特征聚合模块IAM
前面已经有了两个分支,CGIM处理通道关系,SGAM处理空间异常,分别在找语义变化和位置变化,但这些信息是分层的,我觉得这里应该是有一点检测当中的FPN、PAN的一些影响,就是深层的变化语义如何给传递到浅层的空间细节。我感觉这个地方是一个很好的创新点,我完全可以将检测当中的一些金子塔结构的融合用到变化检测当中里面,完全又是一个故事。
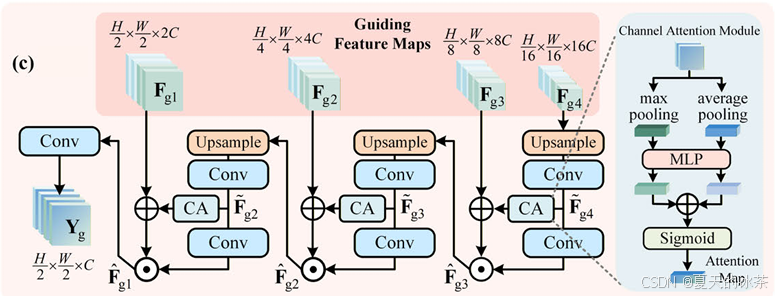
这里每一层,通过通道注意力机制提取重要语义信息,并结合卷积生成的空间门控,对浅层特征进行加权调制,实现语义引导下的空间细化,这部分不仅增强了变化区域的表达能力,同时抑制了浅层特征中的噪声信息,能实现多尺度变化信息的有效聚合。
但我对于这里还是要有一些批评性的看法,这种逐级上采样和串行传播,如果深层特征存在偏差,可能对浅层会产生误导吧,而且这里的注意力机制主要还是基于通道,是不是应该引入空间注意力(或更全局的建模方式)进一步增强呢?
总结
整体来看,DCSI-UNet这篇文章还是相当具有学习的地方,研究点从特征差分提升到了特征关系建模的层面,在"通道"和"空间"两个维度上进行了有针对性的设计,有效建模双时相之间的差异。