在 C 和 C++ 中,#define 和 typedef 都可以用来给现有的类型起一个别名,但其实他们两个有着本质上的区别,本文将带你彻底区分 #define 和 typedef 。
1. 核心本质差异
我们先讲最干货的,让你知道他们在底层到底有什么不同。
#define:
#define 本质上只是简单的文本替换。
在 预处理阶段 ,也就是说编译器真正开始编译代码之前,预处理器 就会把代码中所有出现宏名称的地方,按照宏定义替换成相应的内容。
typedef:
typedef 本质上是为一个 已有的数据类型 创建一个新的别名。它不仅仅是简单的文本替换,它实际上产生了一个新的类型名称。
在 编译阶段 ,编译器 会将用 typedef 定义的类型别名视为全部类型的一种进行语法和语义分析。
2. 实际使用场景分析
在了解 #define 和 typedef 的核心本质差异之后,本章我们从实际的使用场景入手,结合代码分析二者的差异。
2.1 连续声明指针
这个应该是大家最熟悉的一点,也是 #define 和 typedef 在处理指针别名时的最大区别。请看下面 C 代码:
c
#define PTR_INT int*
typedef int* Ptrint;
PTR_INT a, b;
Ptrint x, y;我们先来分析 #define:第一章中说过,#define 只是简单的文本替换,因此 PTR_INT a, b 在预处理阶段进行替换之后会变成 int* a, b ,我们都知道 * 只与 a 结合,这就导致 a 是 整型指针 ,而 b 却是一个整型变量。
再看 typedef:Ptrint 被编译器视为一个确确实实存在的 类型 ,而不是文本替换。因此 Ptrint x, y 声明了两个变量 x 和 y,它们的类型都是 Ptrint,因此x 和 y 都是整型指针。
我们进行实际测试,将上面的 C 代码文件命名为 demo.c,然后用下面命令将 C 代码分别进行预处理和编译:
bash
gcc -E demo.c -o demo.i
gcc -S demo.i -o demo.s产生的 demo.i 代表预处理之后的文件,demo.s 代表编译之后的文件。
我们先来看 demo.i,这是预处理之后的文件:
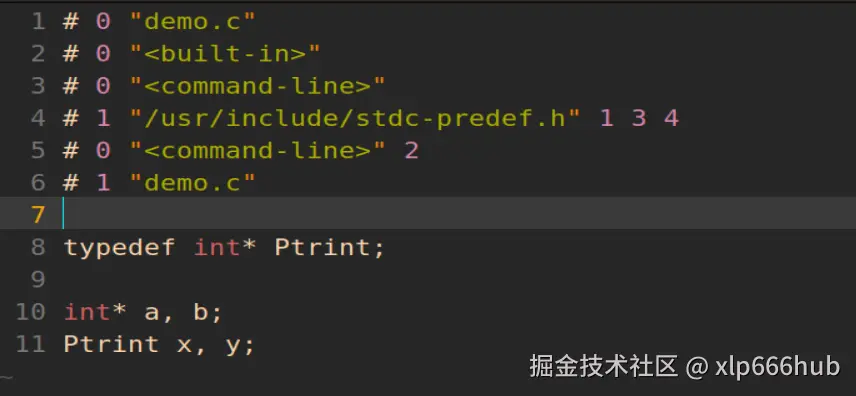
可以看到,PTR_INT 确实被替换成 int * 了。并且,如我们第一章所说,#define 的处理发生在预处理阶段,而 typedef 的处理发生在编译阶段,因此 Ptrint 并没有发生变化,这也是符合预期的。
再来看看编译后的文件 demo.s:
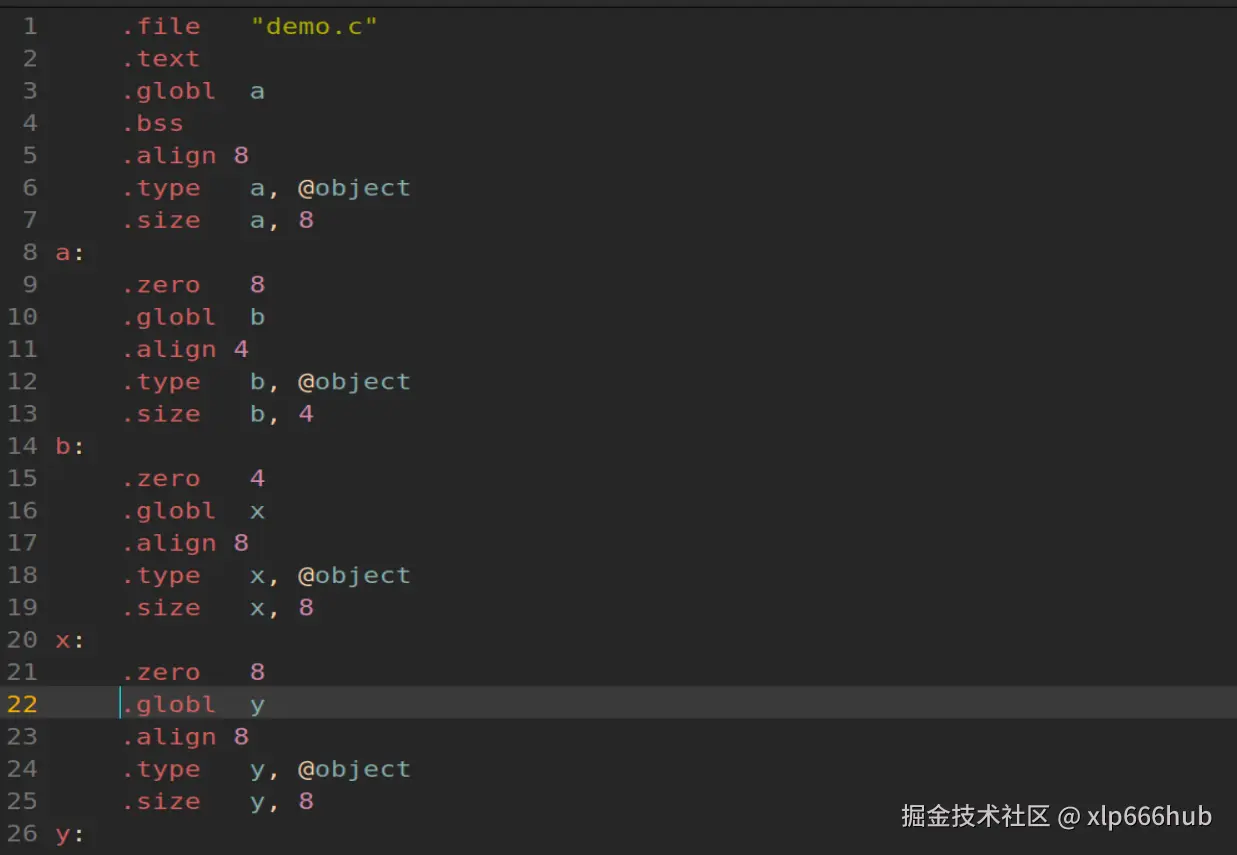
这里只截取了我们需要注意的部分,并没有截取全部内容。还要先说明一下,在我用的 64 位 Ubuntu 虚拟机中,指针大小为 8 字节,int 的大小为 4 字节。
我们可以看到截图中:
arduino
.size a, 8
.size b, 4
.size x, 8
.size y, 8这就说明,除了 b 只分配了 4 个字节之外,别的 a,x,y 都分配了 8 个字节,刚好证明 b 的类型是 int,而其他三个都是 int * 。
2.2 与const结合使用
当与 const 结合使用时,二者的表现也完全不同。请看下面代码:
c
#define PTR_INT int*
typedef int* PtrInt;
const PTR_INT p1;
const PtrInt p2;对于 #define:预处理之后是 const int* p1,这里 const 修饰的是 int,表示 p1 是一个 指向常量 的指针,也就是说 指针的指向可以变,但不能通过指针修改值。
对于 typedef:PtrInt 是一个指向 int 的 指针 。当用 const 修饰它时,const 修饰的是 指针本身 ,所以 p2 会解析为 int* const p2 ,即 p2 是一个 常量指针 ,也就是说 指针的指向不能变,但是可以通过指针修改其指向的值。
我们用下面代码进行编译测试:
c
#define PTR_INT int*
typedef int* PtrInt;
int main()
{
int num[2] = {2,5};
const PTR_INT p1 = &num[0];
const PtrInt p2 = &num[1];
p1 = &num[1];//改变p1指向
*p1 = 10;//改变p1指向位置的值
p2 = &num[0];
*p2 = 20;
return 0;
}编译结果如下:
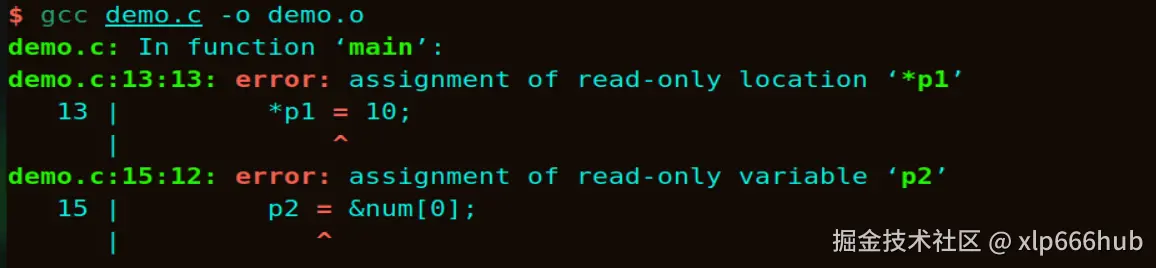
可以看到,指出了存在错误的地方,也正如我们上述所说,p1 可以改变指向,但不能通过解引用修改值,p2 相反。
2.3 作用域的差异
#define:一旦在一个文件中定义,从定义的那一点开始,直到文件结束,所有的宏都会被替换,并且它可以无视大括号 {} 构成的块。
typedef:他遵循块作用域的规则,如果定义在一个 {} 内部,那么别的 {} 内是不可以使用的。
比如下面代码:
c
void func1()
{
#define MY_INT int
typedef float MY_FLOAT;
MY_FLOAT f = 1.0;
}
void func2()
{
MY_INT i = 10;
MY_FLOAT f;//这里会报错
}我们编译一下:

可以看到,它提示 func2 中有个不认识的类型名称 MY_FLOAT。
2.4 类型检查相关
#define: 预处理阶段就完成了替换,不进行任何类型检查。如果宏定义有语法错误,预处理器不会报错,错误会被带入编译阶段,但编译器的报错会指向替换后的代码,而不是宏定义本身,一旦出错极难调试。
typedef: 在编译阶段处理,有严格的类型检查 。如果类型不匹配或有语法错误,编译器会明确指出 typedef 存在的问题,有利于调试。
2.4.1 #define错误用法示例
如下代码,加入我们把 unsigned 误写成 unsign :
c
#define UINT unsign int
int main()
{
UINT a = 10;
UINT b = 20;
UINT c = 30;
return 0;
}尝试编译一下:
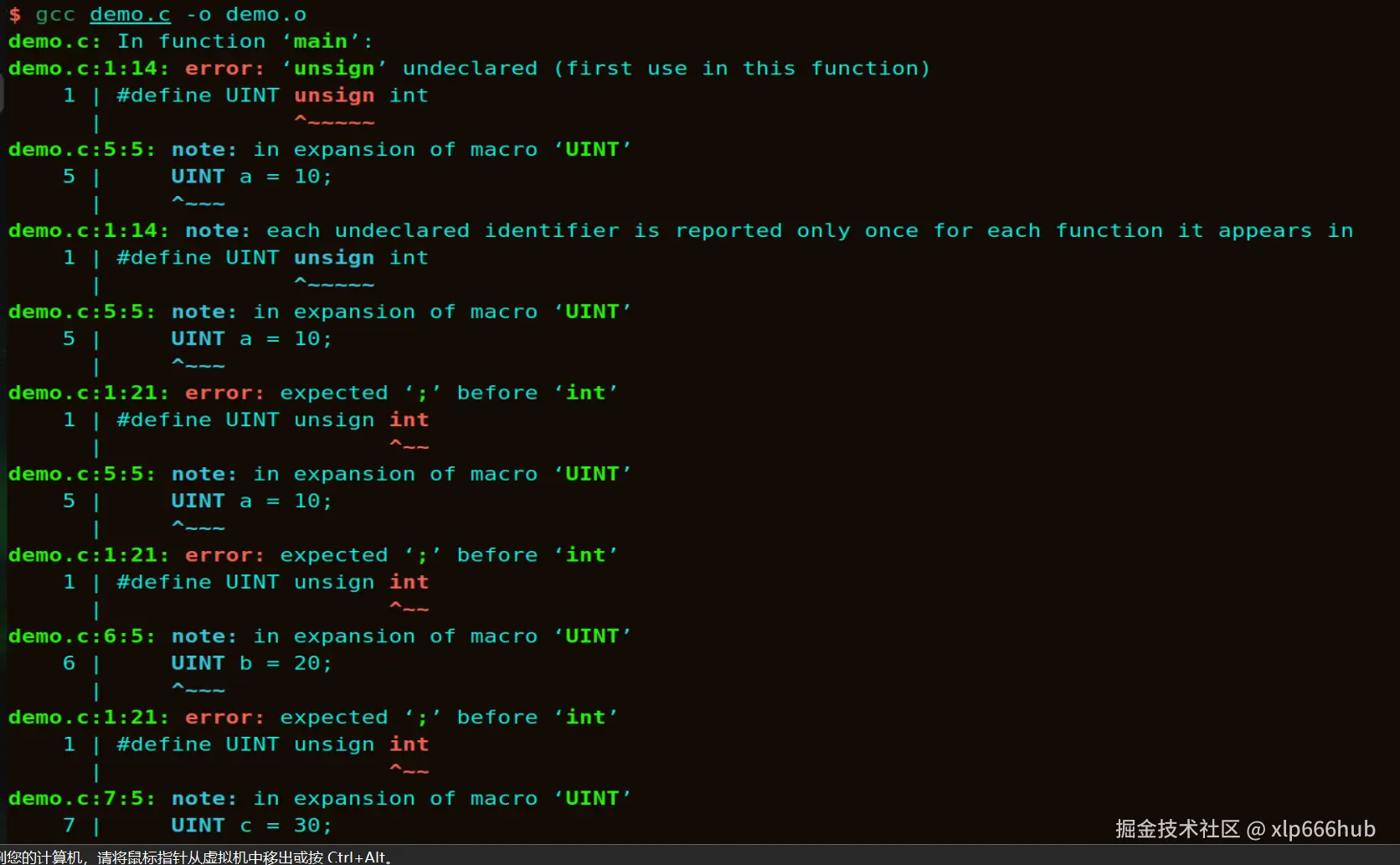
可以看到,报错的内容比代码本身都长的多,看起来就让人头大,正如上面所说,预处理器只是做简单的文本替换,并不检查错误,这就导致编译器会产生许多无法准确定位问题根源的报错,导致难以调试。
2.4.2 一个稍复杂的语法错误
当你想当然的写下下面的代码,问题就产生了:
c
#define ARRAY_5 int[5]
int main()
{
ARRAY_5 arr;
arr[0] = 100;
return 0;
}大家可以看看编译后的报错信息:
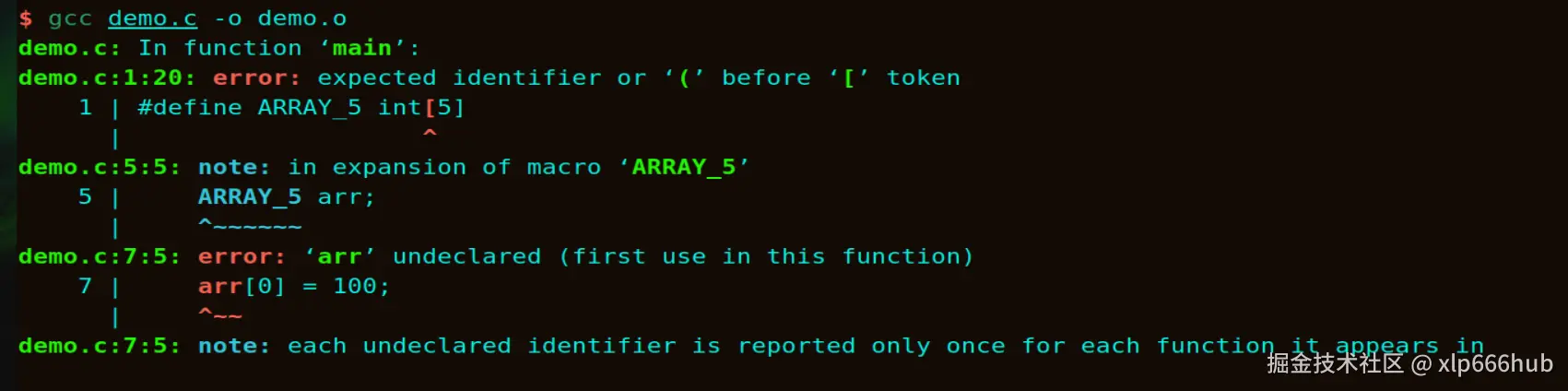
报错信息极其难懂:"在 [ 之前期望一个标识符或 ("。拿着这种报错信息你怎么排查错误?
为什么报错是这样呢?归根结底还是预处理器的无脑替换,替换之后第 5 行变成了:int[5] arr;
而在 C 语言中这当然是违法的,正确的写法是 int arr[5];
这就是简单文本替换的劣势所在。
2.5 复杂类型的封装
对于复杂的声明,typedef 具有压倒性的优势,而 #define 几乎无法胜任,可以参考2.4.2的例子。
举两个例子:
定义一个大小为 10 的整型数组类型:
c
typedef int array10[10];
array10 arr; //等价于intarr[10];定义函数指针:
c
typedef void (*FuncPtr)(int);
FuncPtr p = &my_function;2.6 功能范围差异
#define 的功能更广,它不仅能为类型取别名,还能定义常量、定义带参数的宏函数,比如#define MAX(a,b) ((a)>(b)?(a):(b))、甚至控制条件编译。
而 typedef 的功能单一,只能用于类型。
本文完。
关注我,我会持续更新干货。