这篇文章完全基于一个本地真实项目的实现来写:前端是 React + Next.js + TypeScript,后端是 Node.js + TypeScript + NestJS。
文中所有敏感信息都已脱敏,包括 App ID、Access Key、Access Token、数据库连接串、部署地址等。
1. 真实效果:页面长什么样
先看两个真实页面状态。第一张是用户还没开始建立连接时的状态,第二张是正在进行实时语音交互时的工作态。
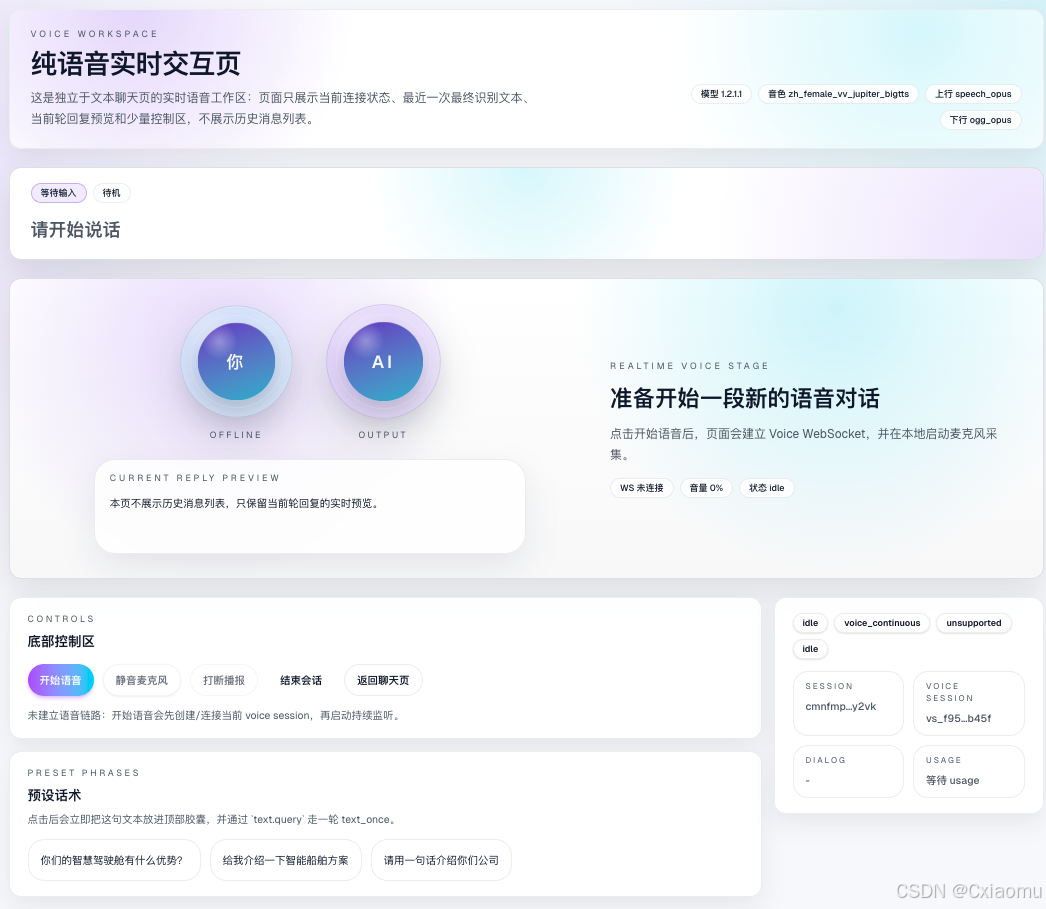
未开始时,页面主要展示启动入口、状态提示、预设话术和当前固定配置,视觉重点是"随时可以开始说话"。
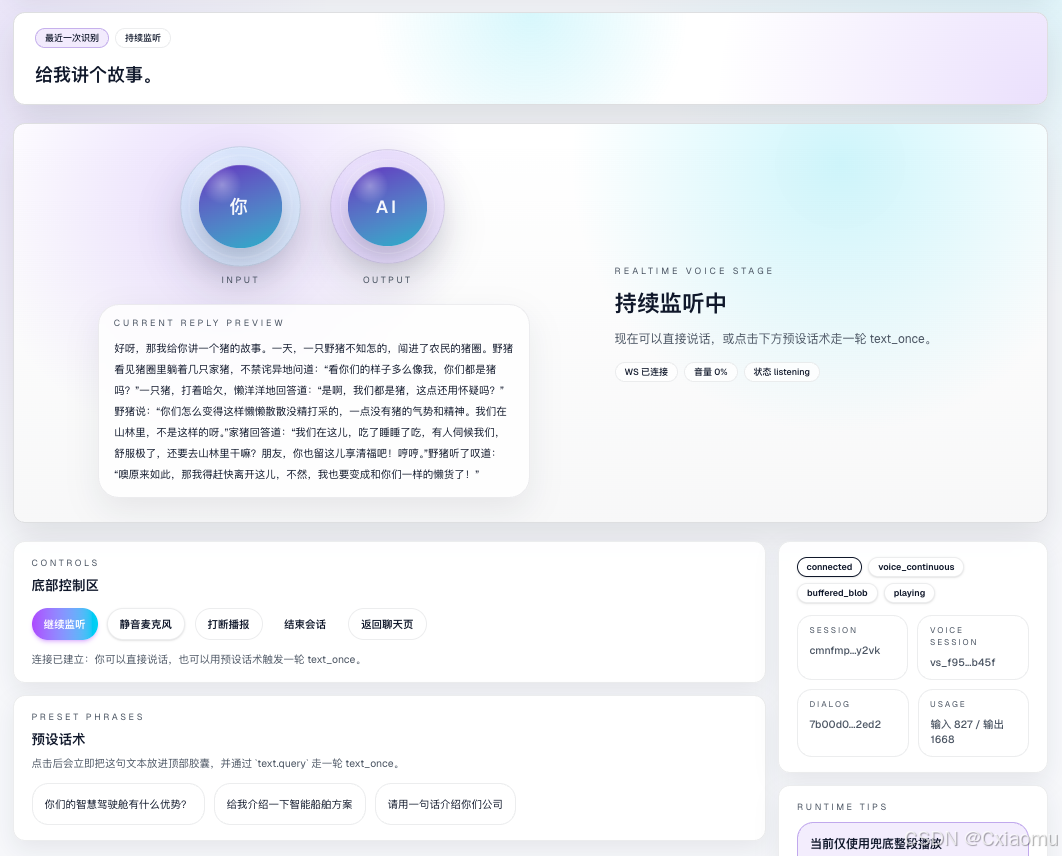
进入实时交互后,页面重心会切到当前输入文案、双圆状态表达、回复预览和播报中的交互反馈,让用户一眼就知道这轮语音链路是否正常工作。
2. 为什么我要做一个"纯语音实时助手"
很多团队在做语音功能时,第一反应是:先把文本问答跑起来,再额外补一个麦克风入口。
但"带语音能力的页面"和"纯语音助手",本质上是两种不同的产品形态。
我这次落地的是一个独立的 /voice 页面。这个页面不追求承载过多信息,而是只盯住一件事:当前这轮实时语音交互是否顺滑。
页面结构很克制:
- 顶部胶囊:显示当前轮最重要的一条输入文案
- 中间双圆:表达当前语音状态
- 底部控制区:开始、结束、静音、打断
- 预设话术:触发一轮临时文本输入
text_once
为了保证这个页面足够轻,我把会话记录交给后端在每轮结束后自动落库,前端只服务于"现在这一轮"的采集、思考、播报和打断。
当产品目标是展厅、驾驶舱、迎宾机、语音助手面板时,这种形态往往比传统列表式界面更自然。
3. 技术选型与整体方案
先说这次项目里的真实技术栈。
前端
- React 19
- Next.js 16(App Router)
- TypeScript
- Tailwind CSS 4
后端
- Node.js 20+
- TypeScript
- NestJS 11
- ws
- Prisma 7
- PostgreSQL
实时语音能力
- 豆包端到端实时语音大模型 API
- 后端代理上游 WebSocket
- 模型固定为
1.2.1.1 - 持续监听模式
keep_alive - 上行格式
speech_opus - 下行格式
ogg_opus - 支持
text_once - 支持打断
- 支持自动落库
为什么一定是"后端代理",而不是前端直连
原因很简单,但非常关键:
- 密钥不能放前端
- 豆包是二进制协议,前端不应该直接背协议细节
- runtime 状态要统一维护
- 最终消息要自动落库
- 打断、忽略旧轮次、关闭回收,都更适合放在服务端做
所以这套方案天然就是三层:
- 浏览器纯语音页
- 我自己的 Voice 后端模块
- 豆包 Realtime API
为什么纯语音助手需要独立交互模型
因为它的数据流和传统消息界面完全不同。
纯语音页更适合:
- 状态机驱动
- 双向 WebSocket
- 音频上行 / 下行
- 当前轮实时状态
- 后端自动落库
如果把会话回溯、当前录音、当前播报三种交互目标混在一起,前端状态会很快失控。
一组脱敏后的环境变量示例
后端:
env
PORT=8080
ENABLE_AUTH=1
ACCESS_TOKEN=your_access_token
VOLC_APP_ID=your_app_id
VOLC_ACCESS_KEY=your_access_key
VOLC_RESOURCE_ID=volc.speech.dialog
VOLC_APP_KEY=your_fixed_app_key
VOLC_REALTIME_BASE_URL=wss://openspeech.bytedance.com/api/v3/realtime/dialogue
DATABASE_URL=postgresql://user:password@localhost:5432/your_db
REDIS_URL=redis://localhost:6379/0
# keep_alive 下默认不把 ClientInterrupt 当强依赖
VOLC_ENABLE_CLIENT_INTERRUPT=0前端:
env
NEXT_PUBLIC_API_BASE=http://localhost:8080/api
NEXT_PUBLIC_ACCESS_TOKEN=your_access_token
NEXT_PUBLIC_API_TIMEOUT=200004. 先看最终架构:前后端如何串起来
这套链路的关键不是"页面能展示",而是浏览器、业务 WS、上游 WS、数据库四条链路得一起成立。
整体架构图
NestJS Voice Module
Browser /voice
create/close/status
text commands
binary speech_opus
upstream ws
binary + json protocol
final user/assistant text
tts.audio binary
VoicePage + ViewModel
useAudioCapture
getUserMedia + AudioWorklet + WebCodecs
useOpusPlayer
MSE stream / Blob fallback
Voice REST
/api/voice/*
Business WS
/api/voice/ws
VoiceController
VoiceGateway
VoiceSessionRegistry
VoiceSessionService
DoubaoRealtimeClient
Codec + Translator
PostgreSQL
Session / Message
Doubao Realtime API
这张图里最重要的几个判断
- 浏览器不直连豆包
- 浏览器只理解"业务事件",不理解豆包原始协议
- 后端把每个语音会话当成一个 runtime 对象
- 轮次记录只在每轮结束后异步落库
- 当前页面只消费实时状态,不让持久化逻辑干扰交互
5. 前端页面是怎么设计的:围绕实时语音重做交互骨架
我在前端新开了一个独立路由:app/voice/page.tsx。
真实目录大概是这样的:
text
app/voice/page.tsx
components/voice/VoiceControlBar.tsx
components/voice/VoiceOrbStage.tsx
components/voice/VoicePermissionTip.tsx
components/voice/VoicePresetPhrases.tsx
components/voice/VoiceStatusHint.tsx
components/voice/VoiceTopQuery.tsx
hooks/useAudioCapture.ts
hooks/useOpusPlayer.ts
hooks/useVoiceGatewaySocket.ts
hooks/useVoiceRealtimePage.ts
lib/api/voice-client.ts
public/voice/pcm-capture.worklet.js
types/voice.ts页面布局图
/voice 页面
顶部胶囊
最近一次最终识别文本
中部双圆
User Orb / AI Orb
底部控制区
开始 / 结束 / 静音 / 打断
预设话术
text_once
右侧状态与运行提示
顶部胶囊为什么只显示一条文案
这个页面顶部只承载"当前轮最重要的一条输入语义",所以它必须非常克制:
- 语音轮次:来自真实
asr.final.text text_once轮次:来自当前点击的text.query.content- 空状态:展示"请开始说话"
这件事如果不提前想清楚,后面状态机一定会乱。
为什么页面只承载当前轮状态
因为信息回溯和实时交互,是两套不同的目标。
你说话时,页面需要马上从 listening -> user_speaking。
模型思考时,需要马上切到 thinking。
TTS 开始后,需要马上变成 speaking。
这些都应该由实时状态机直接驱动,而不是再套一层列表范式。
6. 前端状态机设计:让语音页"像实时对话",而不是"像录音留言"
这部分是整个前端最重要的设计点。
我在 types/voice.ts 里定义了清晰的 UI 状态:
ts
export type VoiceUiState =
| "idle"
| "connecting"
| "session_starting"
| "listening"
| "user_speaking"
| "thinking"
| "speaking"
| "text_submitting"
| "error"
| "closed";状态机图
startVoice
WS open + session.start
session.started
asr.info
asr.ended
tts.start
tts.end
click preset
chat.partial / chat.ended
tts.start
tts.end + restore
session.end
session.end
session.end
fatal error
ws/upstream error
session start error
fatal error
fatal error
fatal error
fatal error
fatal error
idle
connecting
session_starting
listening
user_speaking
thinking
speaking
text_submitting
closed
error
顶部胶囊为什么不能直接复用 asr.final
这是我这套实现里专门收口过的一件事。
text_once 本质上不是"识别出来的文本",而是"用户主动点击的一句预设话术"。
如果为了省事,在后端伪造一条 asr.final,语义就污染了:
- "最近一次最终识别文本"不再只代表 ASR
- 前端无法区分真实语音输入和临时文本输入
- 后面做语音记录页时,语义会越来越乱
所以前端明确分成两条来源:
ts
case "asr.final":
// 真实语音轮次才更新顶部胶囊
setTextOnceDisplayText("");
setLastFinalQuestionText(event.text);
return;
const currentDisplay = useMemo(() => {
if (textOnceDisplayText.trim()) {
return { text: textOnceDisplayText.trim(), source: "text_once" as const };
}
if (lastFinalQuestionText.trim()) {
return { text: lastFinalQuestionText.trim(), source: "voice_asr" as const };
}
return { text: "请开始说话", source: "placeholder" as const };
}, [lastFinalQuestionText, textOnceDisplayText]);为什么一定要等 tts.end 之后才恢复持续监听
这也是一个特别容易做错的点。
如果在 chat.ended 就恢复麦克风:
- 文本回复虽然生成完了
- 但本地 TTS 可能还没播完
- 这时恢复采集,很容易把 AI 自己的播报重新采进去
所以前端真实逻辑是:
- 收到
tts.end - 调
endStream() - 再
await waitForPlayerIdle() - 最后才恢复
voice_continuous
代码就在 useVoiceRealtimePage.ts:
ts
case "tts.end":
endStream();
// Blob 兜底模式下,真正播放可能到这里才开始
await waitForPlayerIdle();
if (event.restoreVoiceContinuous || modeRef.current === "text_once") {
await restoreMicAfterTextOnce();
}
setState("listening");
return;为什么收到 asr.info 要立刻本地停播
因为"打断"首先是一个前端交互问题,不是协议问题。
如果等后端先通知上游、上游再停止、再回传状态,用户会先听到一截旧播报。实时感会很差。
所以我在前端看到 asr.info 时,先做本地动作:
ts
case "asr.info":
// 本地立即停播,优先解决听感问题
stopAndClear();
pendingTextQueryRef.current = false;
if (modeRef.current === "text_once") {
setTextOnceDisplayText("");
}
setReplyPreviewText("");
setState("user_speaking");
return;7. 后端为什么必须做代理:REST + 业务 WS + 豆包上游 WS
这套方案里,后端不是一个简单转发器,而是一个实时语音编排层。
三层关系
- 前端纯语音页:只管页面状态、麦克风、播放、按钮
- 后端 Voice 模块:统一编排 session / state / 落库 / 打断
- 豆包 Realtime API:提供 ASR / Chat / TTS 一体能力
为什么不能把协议细节放前端
因为豆包这条链路不是"普通 JSON WebSocket"。
它涉及:
- 二进制协议头
- event type
- gzip 压缩
- audio only request / response
- session lifecycle
- 文本与音频混合事件
如果让前端直接理解这些协议,一旦供应商协议变更,前端会被拖着一起抖。
所以我在后端做了两层隔离:
doubao-realtime.codec.ts:负责编解码doubao-realtime.translator.ts:负责把豆包事件翻译成业务事件
前端最终只看这样的事件:
session.startedasr.infoasr.finalchat.partialtts.starttts.enderror
这就干净很多。
8. 后端 Voice 模块是怎么拆的
这是本地项目里真实的目录结构:
text
src/voice/
clients/doubao-realtime.client.ts
dto/voice.dto.ts
protocol/doubao-realtime.codec.ts
protocol/doubao-realtime.translator.ts
protocol/doubao-realtime.types.ts
voice-session.registry.ts
voice-session.service.ts
voice.constants.ts
voice.controller.ts
voice.gateway.ts
voice.module.ts
voice.service.ts
voice.types.ts每个文件的职责
-
voice.controller.ts- 暴露 REST 接口
- 创建语音会话、查询状态、关闭会话、读取固定配置
-
voice.gateway.ts- 浏览器业务 WebSocket 入口
- 解析文本命令
- 区分二进制音频帧
- 绑定具体 runtime
-
voice.service.ts- REST 层协调
- 创建或绑定 Session
- 从 registry 里取运行时快照
-
voice-session.registry.ts- 管理活跃 runtime
- 在关闭后保留 closed snapshot
- 让
GET /api/voice/sessions/:id在关闭后返回state=closed,而不是 404
-
voice-session.service.ts- 这是真正的核心
- 管理一个语音 session 的完整生命周期
- 负责状态机、打断、忽略旧轮次、自动落库、关闭回收
-
clients/doubao-realtime.client.ts- 管理与豆包上游 WebSocket 的连接
- 封装 StartConnection / StartSession / TaskRequest / ChatTextQuery / FinishSession / FinishConnection
-
protocol/*- 不让业务层手写 Buffer
- 专门处理二进制协议和事件翻译
这个拆分为什么重要
因为"一个语音会话"不是一个普通请求,而是一个带内存状态的 runtime。
它既不是 controller,也不适合直接做成 singleton service 里的一个大对象。
我最后的选择是:
VoiceSessionRegistry负责创建 / 持有 runtimeVoiceSessionService作为每个语音会话的实例- module 销毁时 registry 统一关闭所有 runtime
这比把所有状态塞进 Map<string, object> 要稳得多。
9. 浏览器和后端的事件契约设计
实时语音项目最怕两件事:
- 事件语义不清
- 前端和后端都在"猜"对方的协议
所以我这里把浏览器侧协议单独定义了。
前端 -> 后端
| 类型 | 说明 |
|---|---|
session.start |
启动语音 runtime |
text.query |
触发一轮 text_once |
interrupt |
请求打断当前轮 |
mic.pause |
暂停麦克风 |
mic.resume |
恢复麦克风 |
session.end |
结束语音会话 |
binary audio.chunk |
单个 speech_opus 音频包 |
后端 -> 前端
| 类型 | 说明 |
|---|---|
session.started |
runtime 就绪 |
state.changed |
状态变更 |
asr.info |
检测到用户开始说话 |
asr.partial |
识别中间态 |
asr.final |
最终识别文本 |
asr.ended |
一轮识别结束 |
chat.partial |
回复文本流 |
chat.ended |
回复文本结束 |
tts.start |
TTS 开始 |
tts.end |
TTS 结束 |
usage |
token / usage 信息 |
error |
业务错误 |
binary tts.audio |
OGG/Opus 音频 chunk |
为什么不把豆包原始 event id 直接透给前端
因为前端真正关心的是业务语义,而不是供应商协议细节。
比如前端并不需要知道某个事件在豆包协议里叫 553 还是 350。
它只需要知道:
- 这是
chat.confirmed - 这是
tts.start - 这是
asr.final
后端协议翻译层做完这一步以后,前端代码会简单很多。
一条完整事件时序图
PostgreSQL Doubao Realtime API VoiceSessionService Business WS Browser /voice PostgreSQL Doubao Realtime API VoiceSessionService Business WS Browser /voice POST /api/voice/sessions 1 sessionId + voiceSessionId + fixed config 2 WS connect 3 session.start 4 StartConnection 5 StartSession 6 session.started 7 state.changed(listening) 8 binary audio.chunk(speech_opus) 9 TaskRequest(audio) 10 ASRInfo 11 asr.info 12 ASRResponse(final) 13 asr.final 14 ASREnded 15 asr.ended 16 ChatResponse 17 chat.partial 18 TTSSentenceStart 19 tts.start 20 TTSResponse(binary) 21 binary tts.audio 22 TTSEnded 23 tts.end 24 persist final user/assistant messages 25
10. 上行音频:浏览器采集与 speech_opus 的真实工程难点
这部分绝对不能写得太轻松。
因为"浏览器采集音频"很简单,但"浏览器稳定输出供应商能吃的 speech_opus"并不简单。
我的真实上行链路
getUserMedia
Web Audio Graph
AudioWorklet
(失败时降级 ScriptProcessor)
单声道 PCM + 电平
LinearResampler
-> 16kHz
20ms 分帧
WebCodecs AudioEncoder(opus)
裸 Opus packet
Business WS binary
VoiceSessionService
Doubao TaskRequest
前端真实实现用了什么
在 useAudioCapture.ts 里,我的流程是:
getUserMedia拉起麦克风- 用
AudioContext建音频图 - 优先走
AudioWorklet - 如果 worklet 不可用,降级到
ScriptProcessor - 输出单声道 PCM
- 线性重采样到 16kHz
- 按 20ms 切帧
- 用 WebCodecs
AudioEncoder编成 Opus - 通过业务 WS 发二进制
关键代码片段如下:
ts
const encoder = new AudioEncoder({
output: (chunk) => {
const packet = new Uint8Array(chunk.byteLength);
chunk.copyTo(packet);
onChunk?.(packet.buffer);
},
error: (error) => reportError(error),
});
encoder.configure({
codec: "opus",
sampleRate: targetSampleRate,
numberOfChannels: 1,
bitrate: 32000,
});
// 20ms 切帧
pendingSamplesRef.current = appendFloat32(pendingSamplesRef.current, normalized);
const frameSize = Math.max(1, Math.round(targetSampleRate * 0.02));
while (pendingSamplesRef.current.length >= frameSize) {
const frame = pendingSamplesRef.current.slice(0, frameSize);
pendingSamplesRef.current = pendingSamplesRef.current.slice(frameSize);
encodeFrame(frame);
}为什么我特意写了"是否兼容仍需真实 ASR 验证"
因为这是实际工程里很容易自我欺骗的一步。
浏览器能产出 Opus,不等于服务端一定能识别。
服务端能收到二进制包,也不等于豆包一定把它当成合法 speech_opus。
所以我在代码里直接留了这句注释:
这里发送的是 WebCodecs 产出的裸 Opus packet,分包节奏按 20ms 控制;是否与豆包
speech_opus100% 兼容,仍需要真实asr.final联调来最终确认。
这不是保守,而是工程诚实。
为什么优先 AudioWorklet,但仍保留降级
因为浏览器环境不会永远理想。
我在代码里是这样处理的:
- 优先
context.audioWorklet.addModule("/voice/pcm-capture.worklet.js") - 如果 worklet 初始化失败,降级到
ScriptProcessor
这至少能保证:
- 现代浏览器下有更稳的采集链路
- 老环境里不至于页面直接废掉
浏览器能力检查也不能省
这部分我单独做了能力探测:
ts
if (typeof AudioEncoder === "undefined" || typeof AudioData === "undefined") {
return {
supported: false,
reason: "当前浏览器缺少 WebCodecs AudioEncoder,无法生成 speech_opus。",
};
}
const support = await AudioEncoder.isConfigSupported({
codec: "opus",
sampleRate: targetSampleRate,
numberOfChannels: 1,
bitrate: 32000,
});页面右侧会直接提示:
- 是否缺少
speech_opus编码能力 - 是否只能用预设话术继续联调
这比用户点开始以后才发现什么都发不出去,要友好得多。
11. 下行音频:OGG/Opus 播放为什么比想象中更难
上行难,下行也不轻松。
尤其是浏览器里做实时 OGG/Opus 播放,你很容易以为:
收到二进制 -> new Blob -> audio.play,不就好了?
问题是这样做通常不是"实时播放",而是"整轮播完再放"。
我这次的真实策略:主方案 + 兜底方案
useOpusPlayer.ts 里我用了两套方案:
- 主方案:MSE 流播
- 兜底方案:Blob 整段播放
播放流程图
是
否
binary tts.audio
MSE 可用?
MediaSource + SourceBuffer
bufferedChunks -> Blob
audio.play()
tts.end
waitForIdle()
主方案:MSE 流播
核心逻辑:
ts
const OGG_OPUS_MIME = 'audio/ogg; codecs="opus"';
const supportsMse =
typeof MediaSource !== "undefined" &&
MediaSource.isTypeSupported(OGG_OPUS_MIME);
if (supportsMse) {
startMseStream();
}开始播放时:
ts
const mediaSource = new MediaSource();
objectUrlRef.current = URL.createObjectURL(mediaSource);
audio.src = objectUrlRef.current;
sourceOpenListenerRef.current = () => {
const sourceBuffer = mediaSource.addSourceBuffer(OGG_OPUS_MIME);
sourceBuffer.mode = "sequence";
sourceBufferRef.current = sourceBuffer;
flushQueue();
};兜底方案:Blob 整段播放
如果 MSE 不可用,或者初始化阶段就失败,我会回退:
ts
const blob = new Blob(bufferedChunksRef.current, { type: OGG_OPUS_MIME });
objectUrlRef.current = URL.createObjectURL(blob);
audio.src = objectUrlRef.current;
setMode("buffered_blob");
void audio.play();为什么我要明确说:Blob 只是兜底,不代表真实低延迟体验
因为这件事必须说清楚。
- MSE 流播:更接近"边收边播"
- Blob 播放:通常要等收到完整音频块后再播
所以我在页面运行提示里明确写了:
当前仅使用兜底整段播放,这不代表真实低延迟体验。
这不是给自己找借口,而是避免把"能响"误判成"实时语音已打通"。
打断时为什么必须 stop / clear
播放器里我专门做了 stopAndClear():
ts
const stopAndClear = useCallback(() => {
const audio = audioRef.current;
if (audio) {
audio.pause();
audio.removeAttribute("src");
audio.load();
}
resetPlaybackState();
replyEndedRef.current = true;
setStatus("stopped");
}, [resetPlaybackState]);它做的不是"暂停一下",而是:
- pause
- 清掉 src
- 重置 MediaSource / SourceBuffer
- 清空缓存 chunk
- 结束当前 reply 状态
如果你只是 pause(),旧音频很容易在下一轮里继续冒出来。
12. text_once:一个很小但非常关键的交互设计
这次我特别喜欢 text_once 这个设计,因为它很小,但非常有用。
场景很常见:
- 现场环境嘈杂,不适合说话
- 需要快速演示几个固定话术
- 用户还没有授权麦克风,但你想先演示 AI 回答
为什么不是把整个 session 切成 text 模式
因为这会破坏"持续监听"的主体验。
我真正想要的是:
- 当前这一轮走文本输入
- 这一轮结束后自动回到语音模式
也就是:
- session 还是 voice session
- mode 只是本轮临时切到
text_once
前端怎么做
点击预设话术后,我的真实逻辑是:
- 顶部胶囊立刻显示这句文本
- 设置
mode = "text_once" - 页面切到
text_submitting - 暂停麦克风
- 发
text.query - 等
tts.end - 恢复
voice_continuous
关键代码如下:
ts
setTextOnceDisplayText(normalized);
setMode("text_once");
setState("text_submitting");
setReplyPreviewText("");
await ensureRealtimeStarted();
textOncePausedMicRef.current = captureIsActive && !isMutedRef.current;
if (textOncePausedMicRef.current) {
pauseCapture();
}
sendGatewayCommand({ type: "mic.pause" });
sendGatewayCommand({
type: "text.query",
content: normalized,
restoreVoiceAfterDone: true,
});后端怎么配合
后端 submitTextQuery() 里做了两件事:
- 把当前 runtime 标记成
text_once - 如果当前已经有未完成轮次,先打断并落库,再切换
而且有一个很重要的细节:
- 后端不会伪造
asr.final - 只把
pendingTextQueryContent用来补最终 user 落库文本
这保证了:
- 顶部胶囊语义不被污染
- 数据库存储仍然完整
13. 打断:实时语音体验里最重要的一环
如果只能选一个"最影响实时感"的能力,那一定是打断。
为什么前端本地 stop 比等后端更重要
因为用户感知首先来自耳朵。
只要用户开口了,旧播报就应该马上停。
哪怕后端的 interrupt 还没走到上游,也不能继续播。
所以前端的主打断动作是:
- 收到
asr.info - 立即
stopAndClear()
或者用户手点"打断播报":
ts
const interrupt = useCallback(async () => {
stopAndClear();
try {
sendGatewayCommand({ type: "interrupt" });
} catch {
// 本地停播优先,后端 interrupt 只是增强能力
}
if (modeRef.current === "text_once") {
await restoreMicAfterTextOnce();
}
}, []);为什么后端还要做 ignore 机制
因为只靠前端停播还不够。
真实链路里,旧轮次的事件可能晚到:
- 旧
chat.partial - 旧
tts.audio - 旧
tts.ended
如果后端不做"忽略旧轮次",这些晚到事件还是会污染当前会话。
所以我在后端维护了:
ignoredQuestionIdsignoredReplyIds
打断当前轮次时:
ts
private markCurrentRoundIgnored(): void {
if (this.currentQuestionId) this.ignoredQuestionIds.add(this.currentQuestionId);
if (this.currentReplyId) this.ignoredReplyIds.add(this.currentReplyId);
}处理上游事件时:
ts
case 'chat.partial':
if (this.isIgnoredRound(event.questionId, event.replyId)) return;
...
case 'tts.audio':
if (!this.suppressIncomingAudio) {
this.sendBrowserAudio(event.audio);
}
return;keep_alive 下为什么不能把 ClientInterrupt 当主链路
这个坑我在项目里专门收过一轮。
因为文档语义里,ClientInterrupt(515) 更偏向"麦克风按键输入模式"。
而我这个项目固定是 keep_alive。
所以后端最后做成了:
- 默认不强依赖上游
ClientInterrupt - 先本地打断
- 后端只把上游 interrupt 当 best-effort 增强能力
- 需要时通过
VOLC_ENABLE_CLIENT_INTERRUPT=1显式开启
代码里也直接写了这层保护:
ts
private async requestUpstreamInterrupt(): Promise<void> {
if (!this.client || !this.connected) return;
// keep_alive 下默认只做本地打断,不把 515 当强依赖
if (!this.bestEffortClientInterruptEnabled) {
return;
}
try {
await this.client.sendInterrupt();
} catch (error) {
this.logger.warn(...);
}
}打断时序图
Doubao VoiceSessionService Browser Player User Doubao VoiceSessionService Browser Player User tts.audio(old round) 1 binary tts.audio 2 playing 3 开始说话 4 ASRInfo(new round) 5 asr.info 6 stopAndClear() 7 markCurrentRoundIgnored() 8 suppressIncomingAudio = true 9 best-effort interrupt 10 late tts.audio(old round) 11 drop ignored audio 12 ASRResponse(new round) 13 asr.final 14
14. 会话落库如何设计:只保存最终轮次,不干扰实时体验
这个边界要讲清楚,不然很多实现最后会变成"四不像"。
实时语音页的职责只有两个
- 管当前状态
- 管当前轮体验
列表渲染、翻页回看、统计聚合这些事情,都不应该进入实时主链路。
轮次记录并没有丢
后端在每轮结束后,会自动把最终文本写进 Session / Message 表。
Prisma 模型里,Message 已经扩成这样:
prisma
model Message {
id String @id @default(cuid())
role Role
content String
stopped Boolean @default(false)
meta Json?
sessionId String
createdAt DateTime @default(now())
session Session @relation(fields: [sessionId], references: [id], onDelete: Cascade)
}为什么只存最终文本,不存 partial
因为 partial 最大的问题不是占空间,而是污染语义。
如果把这些都存进去:
asr.partialchat.partial- 中途被覆盖的句子
你最后的 Message 列表会很难看,也很难复用。
所以我只落:
- 用户最终识别文本
- assistant 最终回复文本
meta 里存了什么
后端把语音轮次上下文塞进了 meta:
inputModequestionIdreplyIddialogIdvoiceInterruptedvoiceSessionId
这样后续如果要补语音记录、质检、审计或运营分析,也不用重新设计一套新表。
自动落库代码
ts
private async finalizeCurrentRound(options: { stopped: boolean }): Promise<void> {
if (this.currentRoundPersisted) return;
const userText = this.currentUserFinalText.trim();
const assistantText = this.currentAssistantFinalText.trim();
if (!userText && !assistantText) {
this.currentRoundPersisted = true;
return;
}
const baseMeta: VoiceMessageMeta = {
inputMode: this.currentInputMode,
questionId: this.currentQuestionId ?? undefined,
replyId: this.currentReplyId ?? undefined,
dialogId: this.dialogId ?? undefined,
voiceInterrupted: Boolean(options.stopped || this.interrupted),
voiceSessionId: this.voiceSessionId,
};
const statements: Prisma.PrismaPromise<unknown>[] = [
this.prisma.session.upsert({
where: { id: this.sessionId },
update: { updatedAt: now },
create: { id: this.sessionId, title: "语音会话", updatedAt: now, createdAt: now },
}),
];
if (userText) {
statements.push(this.prisma.message.create({
data: {
sessionId: this.sessionId,
role: Role.user,
content: userText,
meta: baseMeta as Prisma.InputJsonObject,
},
}));
}
if (assistantText) {
statements.push(this.prisma.message.create({
data: {
sessionId: this.sessionId,
role: Role.assistant,
content: assistantText,
stopped: Boolean(options.stopped || this.interrupted),
meta: baseMeta as Prisma.InputJsonObject,
},
}));
}
await this.prisma.$transaction(statements);
}15. 实际踩坑与收口过程
这一章是整篇文章里最有工程味的部分。
1)ClientInterrupt 不能作为 keep_alive 主链路强依赖
这是很典型的"文档看起来支持,真实模式不一定稳"的坑。
做法上我最后选择:
- 前端本地停播是主链路
- 后端上游 interrupt 是增强能力
- 默认关闭,真实联调确认稳定后再开
2)text_once 不能伪造 asr.final
如果为了省事在后端补一条 synthetic asr.final,短期看好像前端更容易写,长期一定出问题:
- 顶部文案语义污染
- 历史记录语义混乱
- 识别结果和临时输入的边界被打穿
最终正确做法是:
text_once顶部胶囊由前端立即显示点击文本lastFinalQuestionText只代表真实 ASR 最终结果
3)tts.end 到了,不代表本地一定播完
这个坑如果只看协议,很容易忽略。
在 Blob 兜底播放模式下,很多时候 tts.end 到了,本地播放才真正开始。
所以我最后加了 waitForPlayerIdle(),先等本地播放器 idle,再恢复监听。
4)OGG/Opus 流播兼容性比预期复杂
即便浏览器宣称支持:
ts
MediaSource.isTypeSupported('audio/ogg; codecs="opus"')也不代表它一定能稳定初始化。
我在代码里保留了:
- MSE 主方案
- Blob 兜底方案
- 页面运行提示明确告诉用户当前是不是退化模式
5)WebCodecs 只能说明"具备候选能力",不等于闭环已经验证
这是上行链路最重要的现实约束。
浏览器能产出 Opus packet,最多只能说明:
- 这条链路有落地可能
- 这不是伪实现
但它仍然需要真实联调去验证:
- 豆包是否把这批包识别成合法
speech_opus - 能不能稳定回
asr.final - 不同浏览器差异有多大
6)StrictMode 下异步初始化很容易误伤页面状态
在开发态 React StrictMode 下,effect 会触发额外的 mount/unmount 重放。
我真实项目里就遇到过一次:
- 旧请求返回时发现页面已"卸载"
- 结果初始化状态没有正确收口
- 按钮一直禁用
最后的修复办法是:
- 在每次 effect setup 时重新恢复 mounted 标记
- 对开发态旧请求结果做静默丢弃
7)Next.js 开发态噪音不要误判成语音链路问题
我还踩过两类很"偏工程环境"的坑:
- 浏览器翻译插件注入 DOM,导致 hydration mismatch
- Turbopack 在中文路径下产生 source map 调试噪音
这类问题很容易把排查方向带偏。
语音链路没问题,但开发调试层在报错。
我的实际收口方式是:
- 关闭翻译/划词插件影响
- 本地 dev 改成
next dev --webpack - 优先看业务 WS / runtime 状态,而不是先看 dev overlay
8)固定 App Key 被本地环境变量误覆盖
这是个非常真实的供应商集成坑。
我这个项目里,某个请求头值在产品约束下是固定的。
如果你让 .env 里的错误值把它覆盖掉,表面上"配置更灵活",实际上会让联调链路莫名其妙失败。
所以我最后干脆把它收口成:
- 固定常量
- 如果环境变量试图覆盖且值不一致,直接 warning,忽略覆盖
16. 最后总结:这套方案适合什么场景
这套方案最适合的,是从一开始就把 Web 端交互定义成纯语音助手的这些场景:
- 独立语音助手页
- 展厅讲解 / 接待台
- 驾驶舱 / 智能座舱演示
- 需要"看起来像实时对话"的 Web 端语音界面
- 已有业务系统,但想新增独立语音入口
这套方案的优点
- 前后端职责边界清晰
- 页面状态机比消息驱动更适合实时语音
- 豆包协议细节被后端吃掉,前端更稳定
- 历史自动落库,不影响纯语音页体验
text_once、打断、恢复监听这些关键交互是完整的
它的边界也很清楚
- 上行
speech_opus仍然依赖真实浏览器 + 真实模型闭环验证 - 下行 OGG/Opus 流播仍受浏览器能力影响
- 如果要追求更极致的低延迟和更广兼容性,音频编解码仍有继续优化空间
下一步我会继续打磨什么
- 单独做一个语音记录页
- 更稳的浏览器音频编解码方案
- 更细的 runtime 监控与日志
- 更明确的播放器兼容性矩阵
- 更自然的语音状态动画反馈
附:后端模块关系图
如果你更偏后端视角,这张图也许更直观。
VoiceGateway
浏览器 WS 入口
VoiceController
REST 接口
VoiceService
创建/查询/关闭
VoiceSessionRegistry
runtime 管理
VoiceSessionService
状态机/落库/打断
DoubaoRealtimeClient
上游 WS 客户端
Codec
二进制编解码
Translator
事件翻译
会话 / 消息表