在 AI 视频生成领域,我们长期被困在"单镜头"的牢笼里:生成的视频往往只有几秒到十几秒,且缺乏场景切换和叙事逻辑。想要生成一个有起承转合、有多角度运镜的完整故事片段,通常需要生成几十个独立视频再手动剪辑,不仅效率低,角色和场景的一致性也难以保证。
快手可灵团队提出了一种全新的多镜头长视频生成框架ShotStream,它不再是简单地延长视频时间,而是让 AI 真正学会了"导演思维":自动规划分镜、智能控制运镜、无缝处理场景切换。ShotStream 能够根据一个故事脚本,直接生成包含多个镜头、多种景别、流畅转场的完整视频序列,且角色与场景在不同镜头间保持高度一致。这标志着 AI 视频生成从"玩具"正式迈向了"电影制作"的门槛!ShotStream 是一种新颖的因果多镜头架构,可实现交互式故事讲述和高效的即时帧生成,在单个 NVIDIA GPU 上可达到16 FPS 。

相关链接
论文介绍

多镜头视频生成对于长篇叙事至关重要,但当前的双向架构存在交互性有限和延迟高的问题。论文提出了一种新型的因果多镜头架构------ShotStream,它支持交互式叙事和高效的即时帧生成。通过将任务重新定义为基于历史上下文的下一镜头生成,ShotStream 允许用户通过流式提示动态地指导正在进行的叙事。首先将文本到视频模型微调为双向下一镜头生成器,然后通过分布式匹配蒸馏将其提炼为因果学生模型。
为了克服自回归生成中固有的镜头间一致性和误差累积问题,引入了两项关键创新。首先,双缓存机制保持视觉连贯性:全局上下文缓存保留条件帧以确保镜头间一致性,而局部上下文缓存保存当前镜头内生成的帧以确保镜头内一致性。此外还采用了 RoPE 不连续性指示器来明确区分两个缓存,从而消除歧义。其次,为了减少误差累积,提出了一种两阶段蒸馏策略。该策略首先基于真实历史镜头进行镜头内自强化,然后逐步扩展到使用自生成历史的镜头间自强化,从而有效地弥合训练集和测试集之间的差距。
大量实验表明,ShotStream 能够以亚秒级的延迟生成连贯的多镜头视频,在单个 GPU 上即可达到 16 FPS 的帧率。它的性能与速度较慢的双向模型相当甚至更优,为实时交互式故事讲述铺平了道路。
方法概述
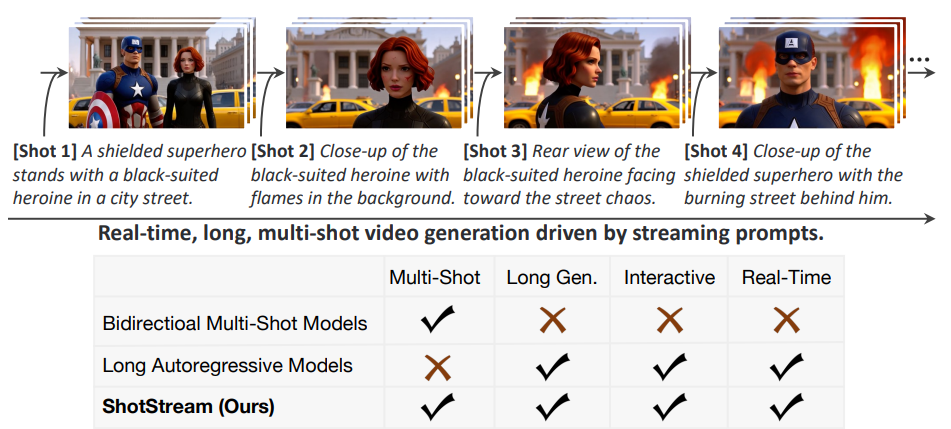
ShotStream 工作流程概述,该工作流程能够根据流媒体提示实时生成长视频、多镜头视频。
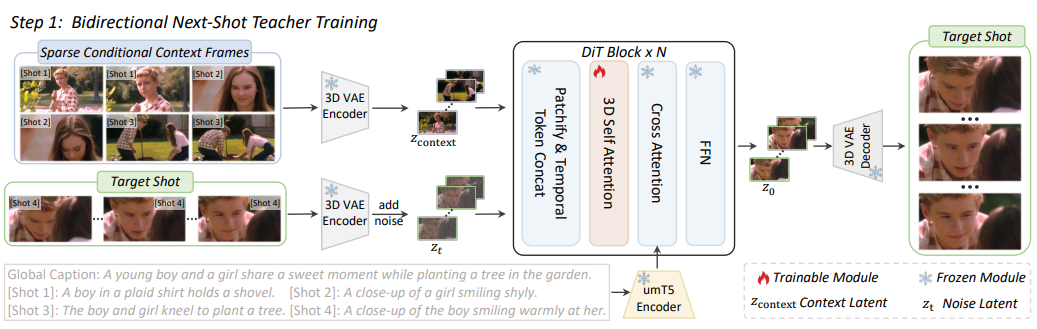
双向下一镜头教师模型架构。为了实现 ShotStream,首先将文本到视频模型微调为双向下一镜头模型,该模型根据先前镜头的稀疏上下文帧生成后续镜头。这些条件上下文帧通过 3D VAE 编码为潜在变量,并通过沿时间维度将它们与噪声潜在变量连接起来注入。在微调过程中,仅优化 DiT 模块中的 3D 时空注意力层。
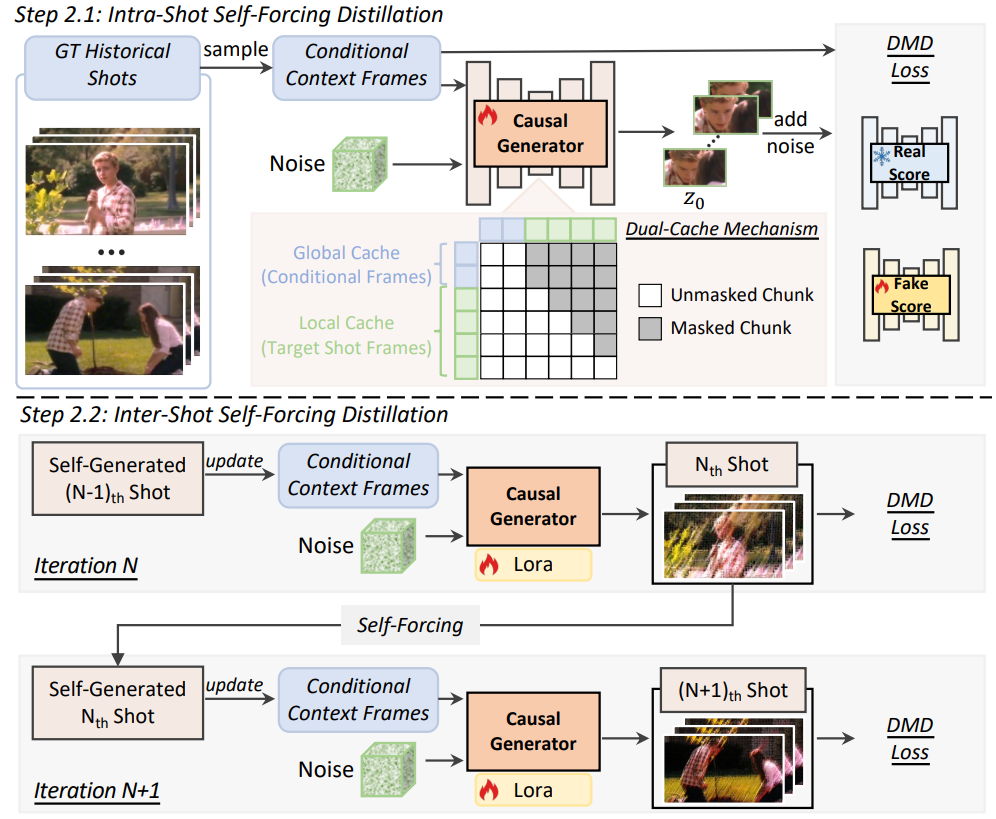
因果架构和两阶段蒸馏流程。将缓慢的多步骤双向教师模型蒸馏为高效的少步骤因果生成器。
-
为了保持视觉一致性,我们提出了一种新颖的双缓存机制:全局上下文缓存存储条件帧以确保镜头间的一致性,而局部上下文缓存则保留目标镜头内生成的帧以保证镜头内的一致性。
-
为了防止误差累积,我们采用了一种渐进式的两阶段蒸馏策略。在第一阶段,镜头内自驱动蒸馏(步骤 2.1),模型以真实历史镜头为条件,逐帧生成当前镜头。在第二阶段,镜头间自驱动蒸馏(步骤 2.2),模型以自身先前生成的镜头为条件,逐帧播放视频,同时迭代地逐帧生成每个镜头的帧。
可以总结为如下三点:
-
因果多镜头架构:提出了一种全新的因果多镜头架构,支持实时互动和超低延迟的视频生成。
-
两步蒸馏法:通过双向下一镜头教师模型和因果学生模型的蒸馏,实现了高效、连贯的多镜头视频生成。
-
实时流式生成:在单张NVIDIA GPU上实现了16 FPS的实时视频生成,为交互式叙事提供了可能。
实验
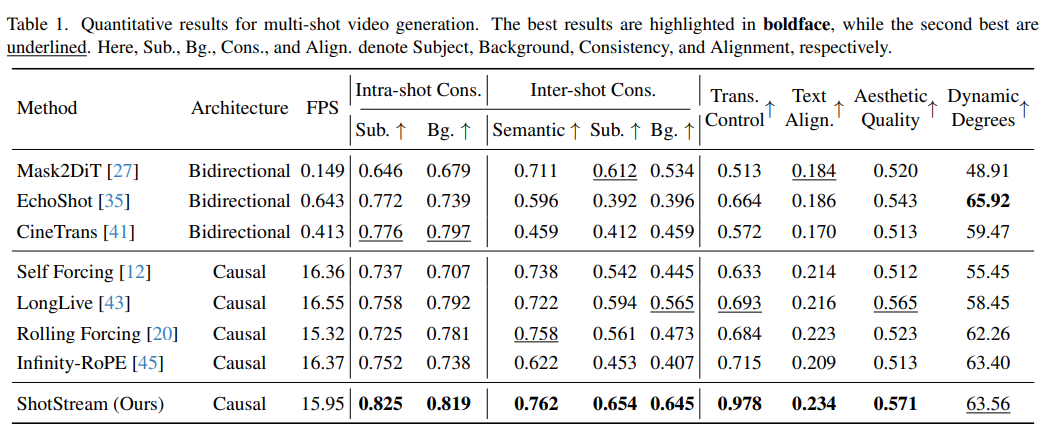
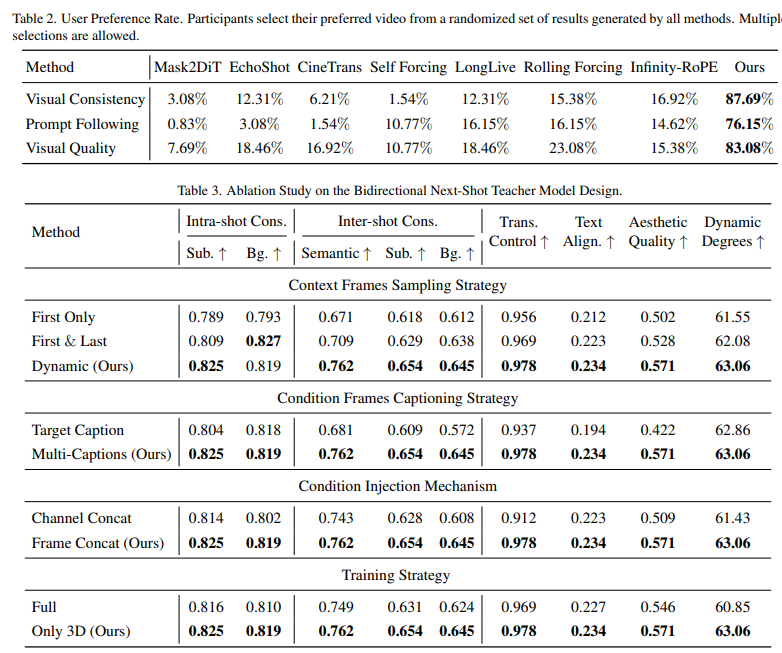
- 定量结果:ShotStream在各项评估指标上均优于或等同于基线模型,特别是在视觉一致性和提示跟随方面表现突出。

- 定性结果:通过用户研究,发现ShotStream生成的视频在视觉一致性、整体视觉质量和提示跟随方面均受到用户的高度偏好。ShotStream在单张NVIDIA H200 GPU上实现了16 FPS的实时生成速度,显著优于双向模型。
结论
ShotStream的诞生,不仅标志着视频生成技术的一次重大突破,更为交互式叙事开辟了无限可能。其独特的因果多镜头架构和两步蒸馏法,使得实时、连贯、无限长的视频生成成为现实。从AI驱动的游戏到教育短片生成,再到与AI进行实时的视觉故事共创,ShotStream正在将视频AI从"工具"向"伙伴"推进一大步。
技术的开源是创新浪潮的真正起点。ShotStream已经搭好了舞台,接下来,就看开发者、创作者们如何用它来演绎属于这个时代的视觉叙事革命了。