don't build your project on the Startup map
you can change it later on if you want to when you finish the project
attention snatching
- 关卡设计始终围绕 "性能适配" 展开:通过 Level Streaming(关卡流送)动态加载 / 卸载非活跃区域,结合 LOD(细节层次)、HLOD(层次细节)优化渲染,确保复杂场景在不同设备上流畅运行。
don't use is a kindness
将关卡拆分为静态环境层 (建筑、地形)、动态交互层 (NPC、道具)、特效层 (粒子、光效)、UI 层(HUD、界面),每个维度单独作为 Sublevel。
优势:可单独隐藏 / 冻结某层(如关闭特效层调试性能)
针对不同层设置渲染距离(如静态层拉远 LOD,动态层精准控制)。
关卡的 "序章 / 战斗 / 解谜" 等阶段创建独立 Sublevel,蓝图控制按需加载 / 卸载,
结合Level Streaming Volume和蓝图,设置 Sublevel 的加载半径:
World Partition+Sublevel 组合,将大地图切分为分区 Sublevel,
将不同 Sublevel 分配给不同美术 / 设计师,通过版本控制工具实现并行编辑:每个人仅锁定自己负责的 Sublevel,避免单关卡多人编辑的冲突问题。
常用场景模块(如街道、建筑组)制作为Level Instance,再嵌套到主关卡的 Sublevel 中,
Load Stream Level/Unload Stream Level节点,结合游戏事件(如触发机关、完成任务)动态加载隐藏的 Sublevel(如解锁密室、触发剧情场景)。
drift to sleep, and live the same day again and again and again
thrist trap and doomcrolling are your anesthesia.
the appear of youth is so often found in the blossoming of things,the precipice of actuality
"I'm Feeling Lucky"(手气不错)按钮叫这个名字,核心是因为:它是一场 "赌博"------ 你赌谷歌第一条结果就是你要的答案,赌中了就是 "幸运"。
一、字面 + 功能逻辑(最根本原因)
- 功能 :输入关键词 → 点按钮 → 直接跳转到排名第一的网页 ,跳过搜索结果列表和广告。
- 为什么叫 "Lucky"(幸运) :
- 你不看列表、不筛选、不验证,直接信任第一条。
- 如果正好是你要的 → 你很 Lucky(运气好)。
- 如果不是 → 白跑一趟,不幸运。
- 创始人布林原话:
"如果这个唯一的网站正是你要找的内容,那你真是太幸运了!"
二、历史背景(1998 年诞生时)
- 互联网很慢、很贵:省一次结果页加载 = 省时间、省钱。
- 谷歌想表达自信:"我们的算法准到你可以赌一把,直接去第一条"。
- 品牌性格:拒绝太死板、太商业化,加一点幽默和人情味。
三、一句话讲透
I'm Feeling Lucky = "我赌这第一条就是对的,我手气好"。
rarely do songs romanticize the mundane or monotonous daily rhythms of the relationship itself
simply put the idea of "love is more exciting than the experience itself",
如果角色跳跃的手感、射击的反馈、敌人的 AI 还没调好,就在精美的关卡里工作,一旦机制修改(比如跳跃高度变高),整个关卡的平台高度、障碍距离都要重做。
防止资产浪费: 在机制未定型前投入大量时间做场景布光、植被铺设,极易因为玩法调整导致这些精细工作报废。
技术架构优先: 独立开发初期应优先构建 GameMode 、Character 、UI 框架 以及 数据结构,这些是游戏的"地基"。
UE 项目建议的初期流程
建议将优先级按以下顺序排列:
- P0(最高优先级):核心 Gameplay 机制
- 在
Test_Level中实现玩家移动、战斗逻辑、核心交互。
- 在
- P1:数据驱动与基础设施
- 建立表格(Data Table)、全局管理器(Subsystems)、基础保存系统。
| 东西 | 用来放什么 | 什么时候用 | 绝对不要放什么 |
|---|---|---|---|
| Data Table | 角色属性、物品数据、任务配置、技能表 | 所有不改的模板数据 | 运行时会变的数值 |
| Subsystems | 音频管理、UI 管理、任务管理、全局状态 | 贯穿整个游戏的管理器 | 具体关卡内容、UI 界面 |
| Save Game | 玩家进度、解锁、等级、道具拥有情况 | 需要退出游戏还在的数据 | 临时状态、配置表 |
替代 "烂大街的 GameInstance 单例"
以前大家都这么干:
- 写个类继承
UGameInstance - 扔一堆管理器进去
- 到处
GetGameInstance<...>()
问题:
- GameInstance 越来越臃肿
- 所有管理器耦合在一起
- 改一个逻辑,整个文件乱套
Subsystem 的目的:把管理器拆碎,各自独立。
UE 有三类 Subsystem,这是它最强大的设计目的:
-
GameInstanceSubsystem跨关卡、全局一直存在 → 音频、UI、存档管理器
-
WorldSubsystem每个世界(关卡)一个 → 关卡内全局管理
-
EditorSubsystem只在编辑器里跑 → 编辑器工具
长期不乱,适合无记忆迭代。


P2:功能性灰盒关卡( 如果项目核心玩法 没有定型,建议继续停留在灰盒阶段。)
搭建第一章或核心场景的结构,测试通关时长和心流。
P3:美术风格验证(Vertical Slice)
只选一个极小的角落,做最高标准的视觉打磨,用于确定最终表现效果。
P4:大规模关卡铺设(Level Design)
在机制完全成熟后,再进行正式的关卡设计和资产填充。
应该把关卡看作 "逻辑的容器" 而不是 "精美的场景"。
初期保持关卡的"简陋"是为了后期"快速迭代"的最高效率。
Data Table 正在被 Data Registry(数据注册表) 逐步替代 / 增强
.h 文件:
其他模块想要使用你的类,必须包含 .h 文件。

.h 文件:契约(Contract)
.cpp 文件:秘密(Secret)
cpp 里写 public 语法合法但违反工程共识
UE 这里的 Public/Private非 C++ 语法的访问控制
标准 C++ 层面,与文件放哪个文件夹毫无关系。但在 虚幻引擎(UE)的模块化构建系统(Unreal Build Tool, UBT) 中,文件夹的名称(Public vs Private )具有特殊的工程意义,
Private 文件夹:
即便其他模块想强行 #include 里的文件,UBT 在编译预处理阶段通常会报错,或者链接器(Linker)会因为找不到符号而报错。
文件夹的 Private : 限制模块与模块之间的访问(UE 构建规则)。
假设你有两个模块: GameModule 和 EditorModule 。
- 你在
GameModule/Private/InternalLogic.h里定义了一个public类。 - 在
GameModule内部的任何地方,你都可以调用它。 - 但在
EditorModule里,你无法 引用这个类,因为 UBT 根本不让EditorModule看到GameModule的Private路径。
- 物理隔离: 通过文件夹强制隔离,迫使你思考哪些是"对外暴露的接口",哪些是"内部隐藏的逻辑"。
Header Guard 优化: 随着 C++20 标准的普及,UE 也在优化头文件的包含效率,但物理文件夹依然是管理可见性的最直观手段。
虚幻引擎
强烈建议 你通过 Editor(编辑器) 创建 C++ 类,而不是直接在 IDE(如 VS 或 Rider)中手动新建文件。
自动配置 .Build.cs :
编辑器会自动识别你的模块依赖。如果你手动创建文件,有时需要手动刷新项目文件(Generate Project Files),否则编译器可能找不到路径。
自动处理 Public/Private 结构:
在 Editor 中创建类时,你可以勾选"Public"或"Private"。它会自动帮你把 .h 放进 Public ,把 .cpp 放进 Private ,并处理好复杂的相对路径引用**** (例如 #include "MyFolder/MyClass.h" )。
生成关键的 generated.h 引用:
UE 的反射系统(用于蓝图、垃圾回收、序列化)要求每个类头文件末尾必须包含 #include "FileName.generated.h" 。
- Editor 创建: 自动帮你写好这一行,并生成正确的类名宏(如
GENERATED_BODY())。
为你的类加上 YOURPROJECT_API 宏。otherwise 跨模块调用(比如在编辑器模块里调用游戏模块)时会产生链接错误(LNK2019)。
后期/建议关闭编辑器,在磁盘上移动文件,
- 重新 Generate Project Files。
AWE 是 Address Windowing Extensions 的缩写,中文为 地址窗口扩展,是微软为 32 位 Windows 系统设计的内存管理技术,TestMem5 中提示需管理员权限启用 AWE,
CPU 的寿命设计冗余极大
- 官方 MTBF(平均无故障时间) :民用 CPU 的 MTBF 通常在10 万小时以上 (约 11.4 年),这个数值是在满负载、额定温度下的测试结果,日常满载使用远达不到这个时间阈值。
- 制程与工艺保障:现代 CPU 采用 7nm/5nm 等先进制程,晶体管的电气稳定性和抗疲劳性大幅提升,持续高负载下的电子迁移、热应力等老化问题,在普通用户的使用周期(3-5 年)内几乎可以忽略。
- TestMem5 的核心工作是多线程读写内存、执行内存运算逻辑,这些都是典型的通用计算任务,完全由 CPU 的运算核心处理;
- 即使是高 CPU 占用,也只是 CPU 在处理内存测试的指令,不会向 GPU 下发图形或并行计算任务。
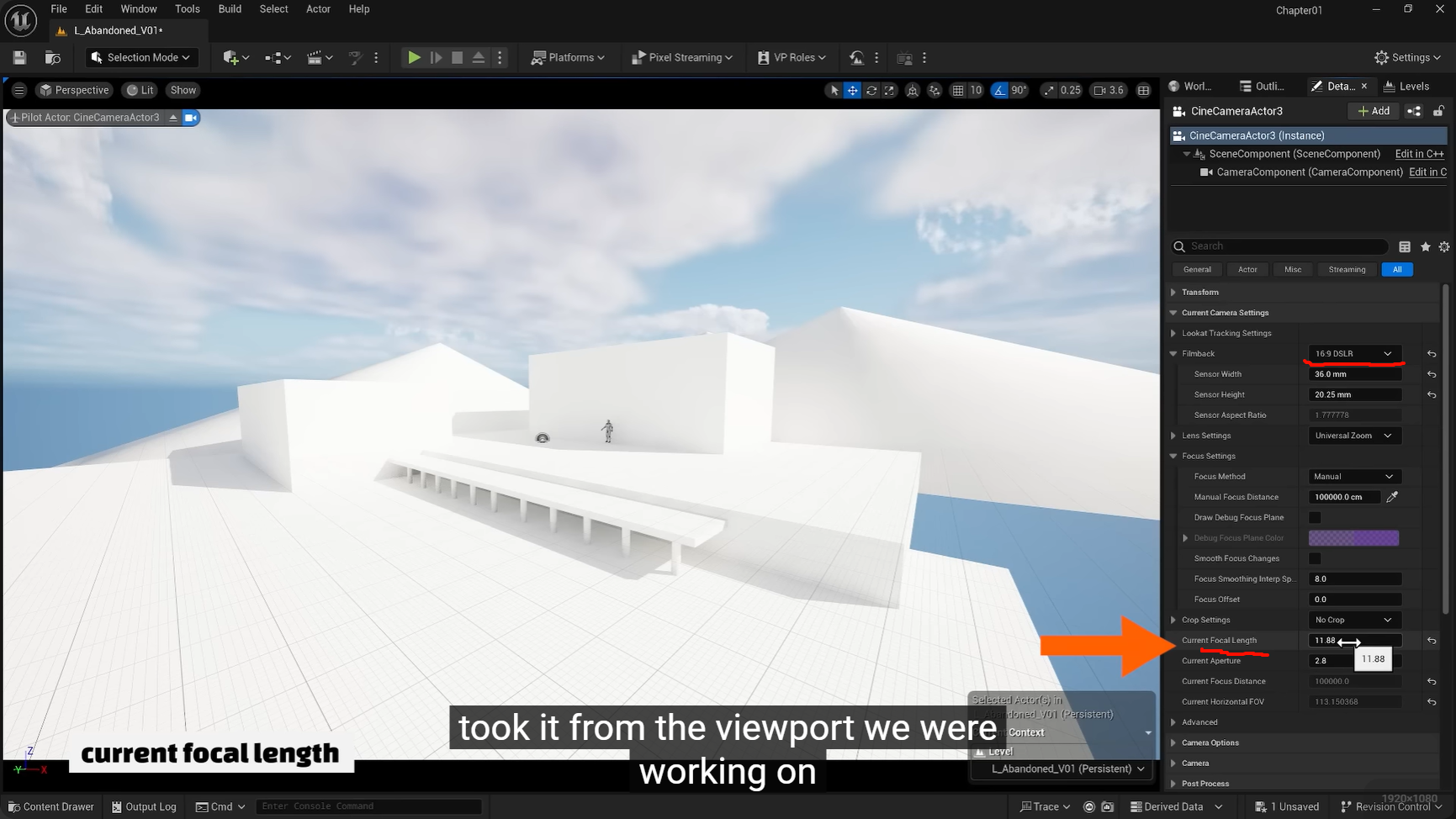
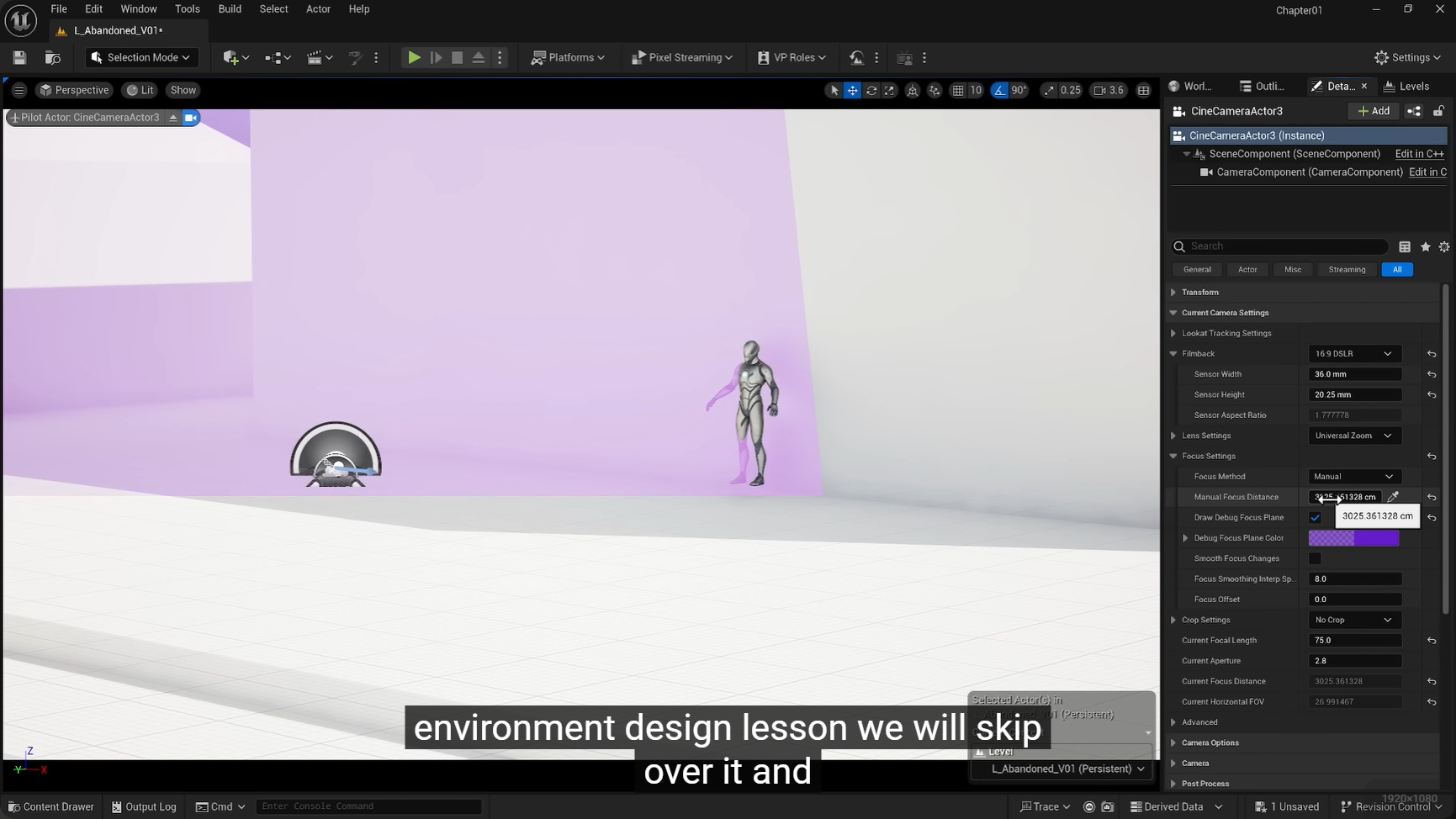
Current Focal Length(当前焦距)与 Current Aperture(当前光圈)参数,核心对应的是计算机图形学中的虚拟相机理论 ,以及摄影光学的基础光学原理,是 3D 引擎渲染与现实相机光学系统的结合应用,
短焦距(如 24mm)
长焦距(如 200mm)
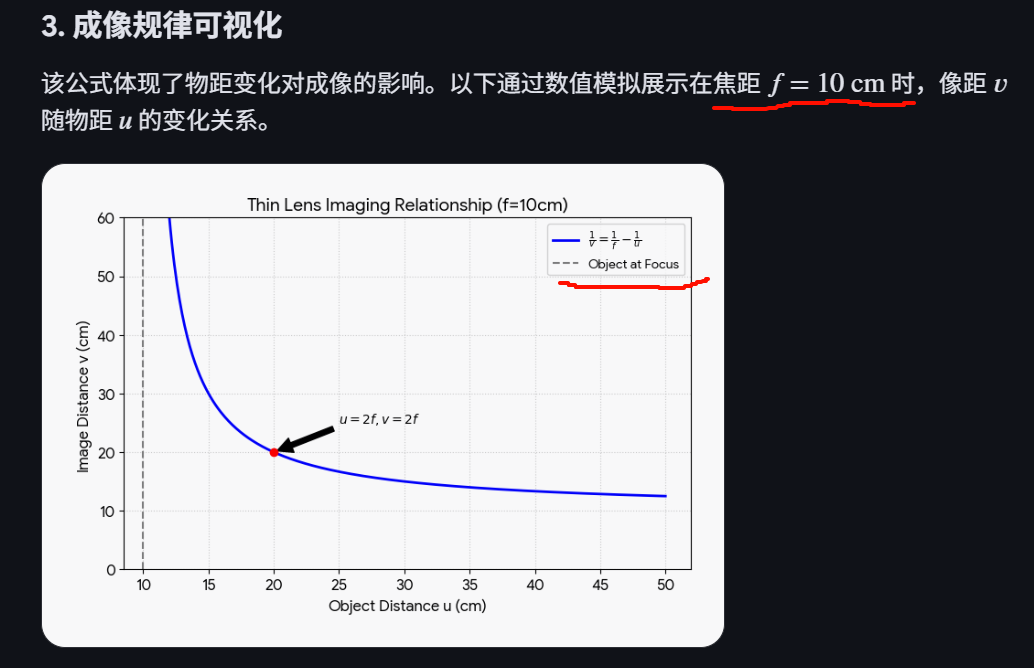
薄透镜成像公式:
1/f=1/u+1/v
(f为焦距,u为物距,v为像距)

相机镜头并非单纯的凸透镜
。现代相机镜头是由多片凸透镜 和凹透镜组合而成的光学系统。虽然最前方的镜片为了成像经常呈现凸出状,但为了修正色差、畸变等光学成像误差,内部会复合使用多种形状的镜片。
- 凸透镜的作用: 中央较厚、边缘较薄,主要用于汇聚光线。
- 凹透镜的作用: 中央薄、周边厚,通常与凸透镜配合使用来减少色差、畸变,提高成像清晰度。
虽然整体光学结构复杂,但为了捕捉较广的光线,镜头的最前面那一组镜片通常呈现为凸面镜。

镜片数量与结构 :简单镜头可能只需要少量镜片,而高性能镜头通常包含复杂的透镜组,如复杂变焦镜头结构可更为复杂。
https://phet.colorado.edu/sims/html/geometric-optics/latest/geometric-optics_all.html
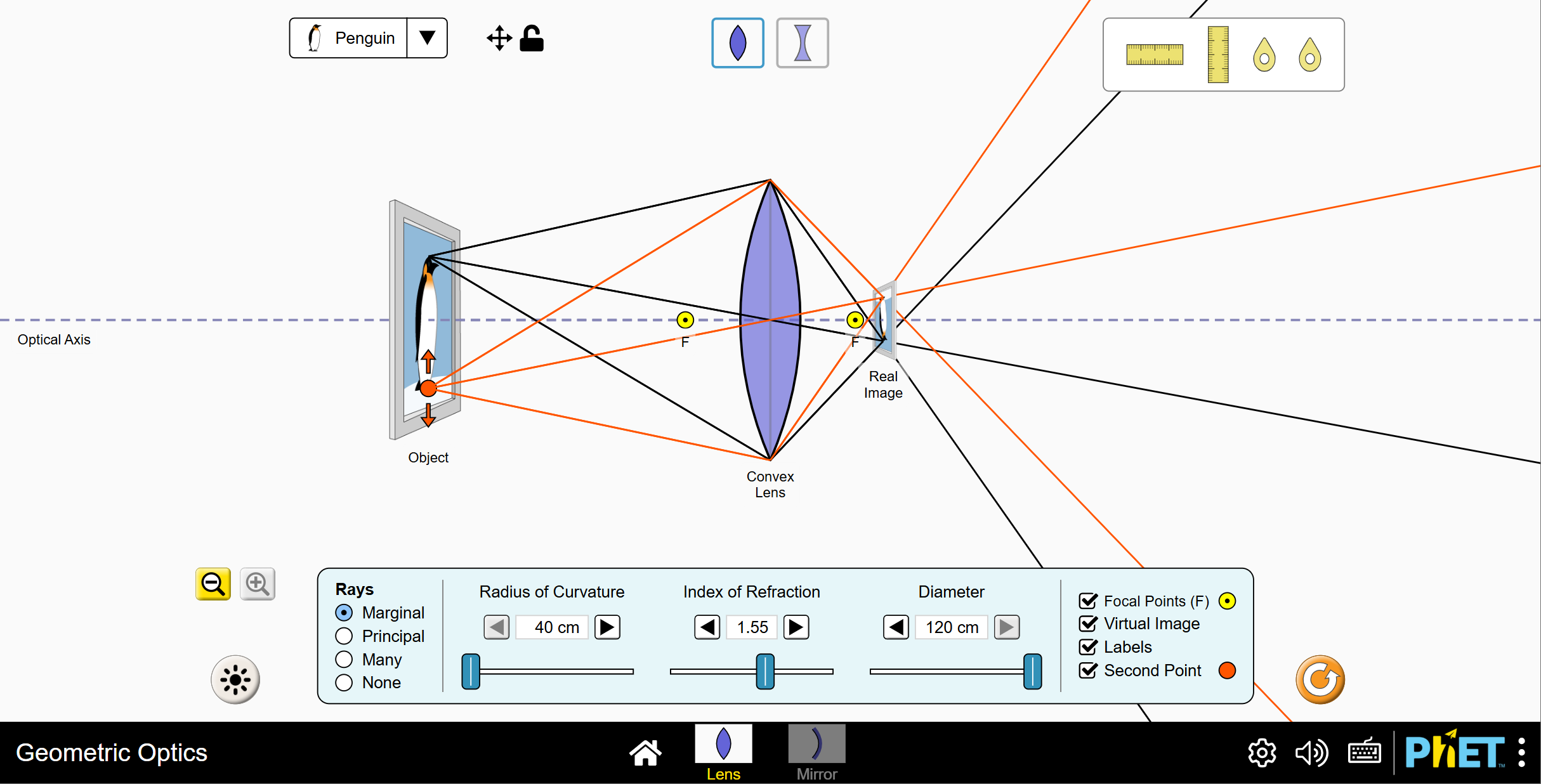
因为先有镜片,才有焦距,焦距属于镜片属性,一个焦距是为了一个缩放距离而生的,
重点在于同一束 光线在整个 convex lens的转运的过程里,没有发生信息分散,都来到了同一个点,信息分布越集中,场景的信息转运越无损,所以远方的一只小penguin,如果想捕捉下它最完整的一切,那必须把焦距调到最集中。
单片镜片成像会产生色散和畸变。组合镜片能通过让光线在镜片间经过多次折射和校正
Stands for Focus (from Latin focus, meaning "hearth" or "fireplace"---the point where light "burns" or concentrates).
u (Object distance):
- There is no direct word starting with u.
- In mathematics and physics,u and v are often used as a standard pair for variables (like x and y).
- By convention,u comes before v in the alphabet, just as the Object comes before the Image in the optical process.
v (Image distance):
- The second half of the 𝑢,𝑣 pair.
- Some mnemonic learners associate v with View (the resulting image you see), though this is not the formal etymology.

ue可以直接显示焦距的位置,
-
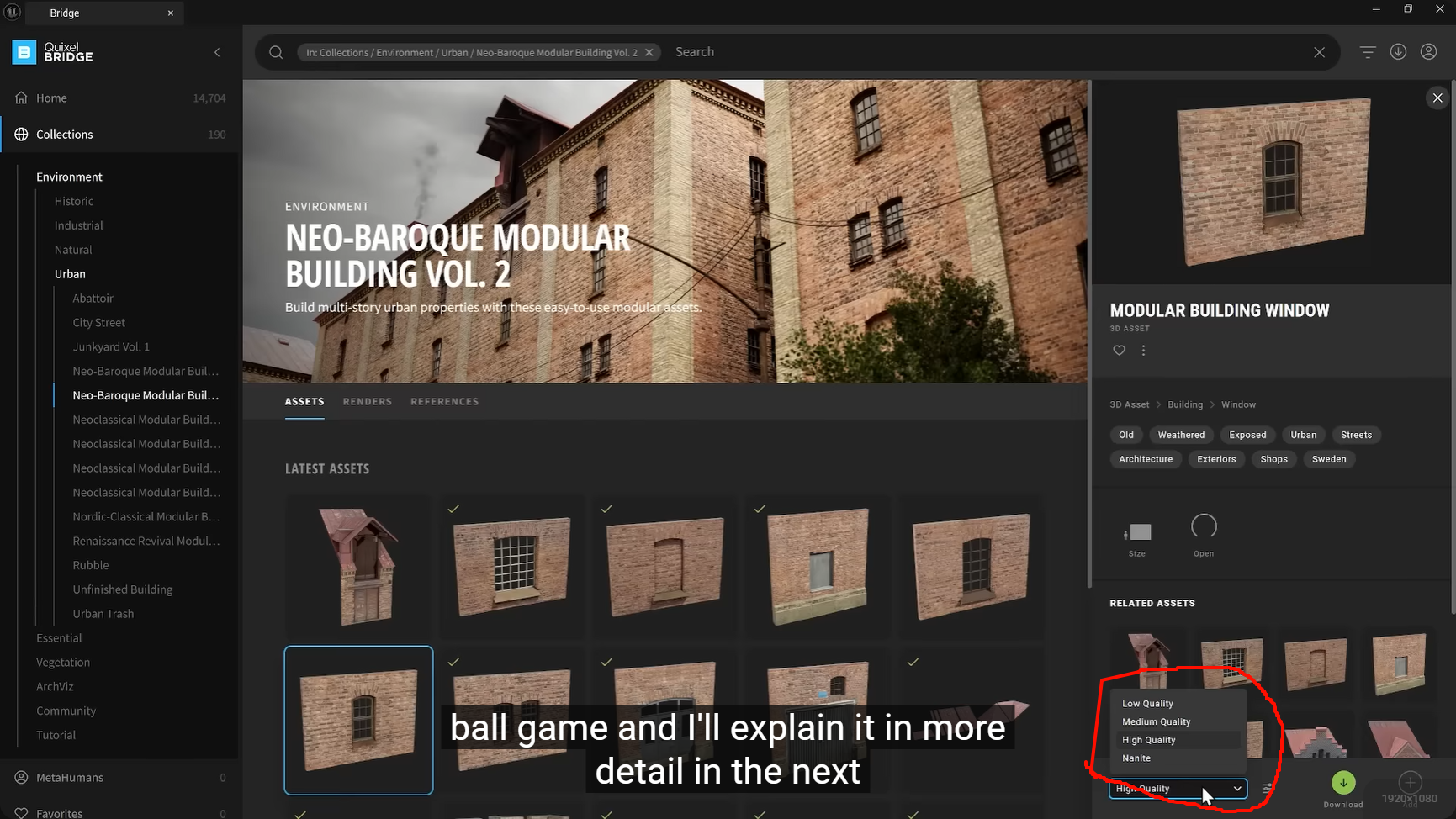
Low/Medium/High Quality :对应模型的几何面数 LOD(细节层次) + 贴图分辨率 的组合等级:
- Low Quality:低面数模型 + 低分辨率贴图(如 512×512),适配移动 / 低配设备;
- Medium Quality:中等面数 + 1K/2K 贴图,通用 PC / 主机;
- High Quality:高面数模型 + 4K/8K 贴图,适配高端 PC / 次世代主机;
-
Nanite 选项 :是基于 Nanite 技术的特化资产版本,并非独立的画质等级 ------ 该版本的模型会被预处理为适配 UE5 Nanite 的虚拟微多边形格式,导入 UE 后直接启用 Nanite 渲染,无需手动转换。
Post-apocalyptic fiction explores life after a civilization-ending catastrophe---such as nuclear war, pandemics, or environmental collapse---focusing on survival, psychology, and the rebuilding of society . Set in the aftermath, these stories often feature desolate landscapes, abandoned technology, and limited resources, highlighting human resilience and the remnants of lost civilization.
Isometric refers to "equal measurement ," describing systems (like crystals or drawings) with uniform dimensions or exercises where muscles contract without moving joints. Common examples include planks, wall sits, and isometric projections in design. Synonyms include equal-dimensional , isometrical , and constant-volume (in thermodynamics).
The Victorian era (1837--1901)
refers to the reign of Queen Victoria, characterized by industrial expansion, strict morality, and ornate aesthetics . It brought significant social changes, including industrialization, scientific advancements like Darwinism, and literature from authors such as Charles Dickens. It is synonymous with "old-fashioned," "prudish ," or "ornate".

一定要把这些内容清除,
Codebase Indexing(代码库索引)的核心是向量嵌入(Embedding) 。不同的 AI 服务商(OpenAI、Gemini、Ollama 等)生成的向量维度、模型结构、数据格式存在差异。- 限制:该功能需要严格匹配指定的 Embedding 接口规范。如果你的中转服务没有严格对齐这些接口的输入输出格式,系统无法正确生成向量,会直接导致检索失败。
-
-
对标 Cursor / Claude Dev,但完全开源免费(只花模型费)
-
支持 GPT-4o、Claude 3.5、Gemini、Grok、本地 Ollama 等全栈模型
-
可自托管、代码本地处理、离线可用,企业 / 隐私项目强需求
-
功能爆发:AI 智能体化
-
多角色模式:Architect(架构)、Code(编码)、Ask(问答)、Debug、Test
-
Boomerang 工作流:自动在模式间切换,一条龙完成复杂任务
-
代码库全量索引:理解整个项目、语义搜索、自动改文件 / 跑命令
-
团队协作、云端智能体、自定义角色、模板市场
-
社区与口碑
-
从 Cline 分叉后快速差异化,功能比原版更激进、更企业向
-
开发者反馈:效率 + 65%、bug 率 - 42%、文档完整性 ×3
-
个人 / 小团队 / 学生首选,口碑传播极强
-
一句话总结:Roo Code 现在是 AI 编程工具里的 "黑马增速",用户与功能都在爆发式增长。
| 模型系列 | 具体型号 | 输入价格 / M Token | 输出价格 / M Token | 特色/优惠 |
|---|---|---|---|---|
| OpenAI | GPT-5.4 | $1.25 | $7.50 | 批量模式(Batch API)享 50% 折扣 |
| GPT-5.4-mini | $0.375 | $2.25 | 适用于高并发、低成本场景 | |
| Anthropic | Claude 4.6 Opus | $5.00 | $25.00 | 较前代大幅降价,但仍属高端定价 |
| Claude 4.6 Sonnet | $3.00 | $15.00 | 性价比平衡点,提示词缓存可减免 70-80% | |
| Claude 4.5 Haiku | $0.25 | $1.25 | 极速响应,同级性能最强 | |
| Gemini 2.5 Pro | $1.25 | $10.00 | 缓存读取仅需 10% 基准价 | |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 极低成本,适合分类与路由任务 |
国内主流模型 API 价格对比 (USD)
| 厂商/模型系列 | 具体型号 | 输入价格 (USD/M) | 输出价格 (USD/M) | 备注 |
|---|---|---|---|---|
| 字节跳动 (豆包) | Doubao-Seed-2.0-pro | $0.28 | $0.55 | 保持极高性价比,适合大规模调用 |
| 智谱 AI | GLM-5-Turbo | $0.69 | $0.69 | 2026年Q1 调价后,输入输出同价 |
| 百度 (文心一言) | ERNIE 4.5 | $0.55 | $2.21 | 旗舰级模型,输出成本相对较高 |
| 月之暗面 (Kimi) | Kimi-v2-pro | $1.38 | $1.38 | 侧重长文本处理能力 |
| 百川智能 | Baichuan 4 | $13.79 | $13.79 | 定位高端企业级市场,单价较高 |
| 阿里云 (通义千问) | Qwen-Max-Latest | $0.55 | $1.66 | 开发者生态完善,经常有资源包优惠 |
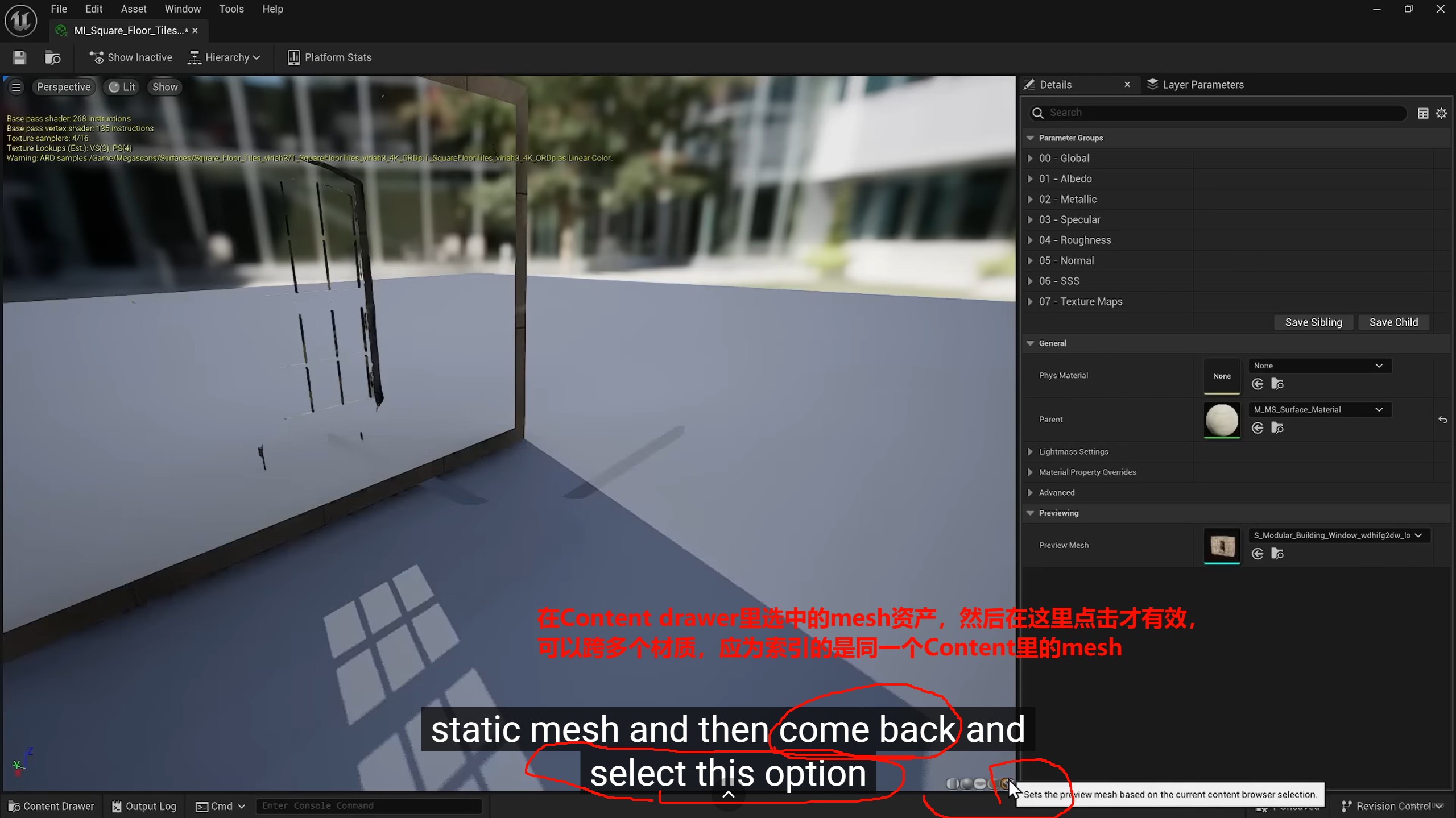
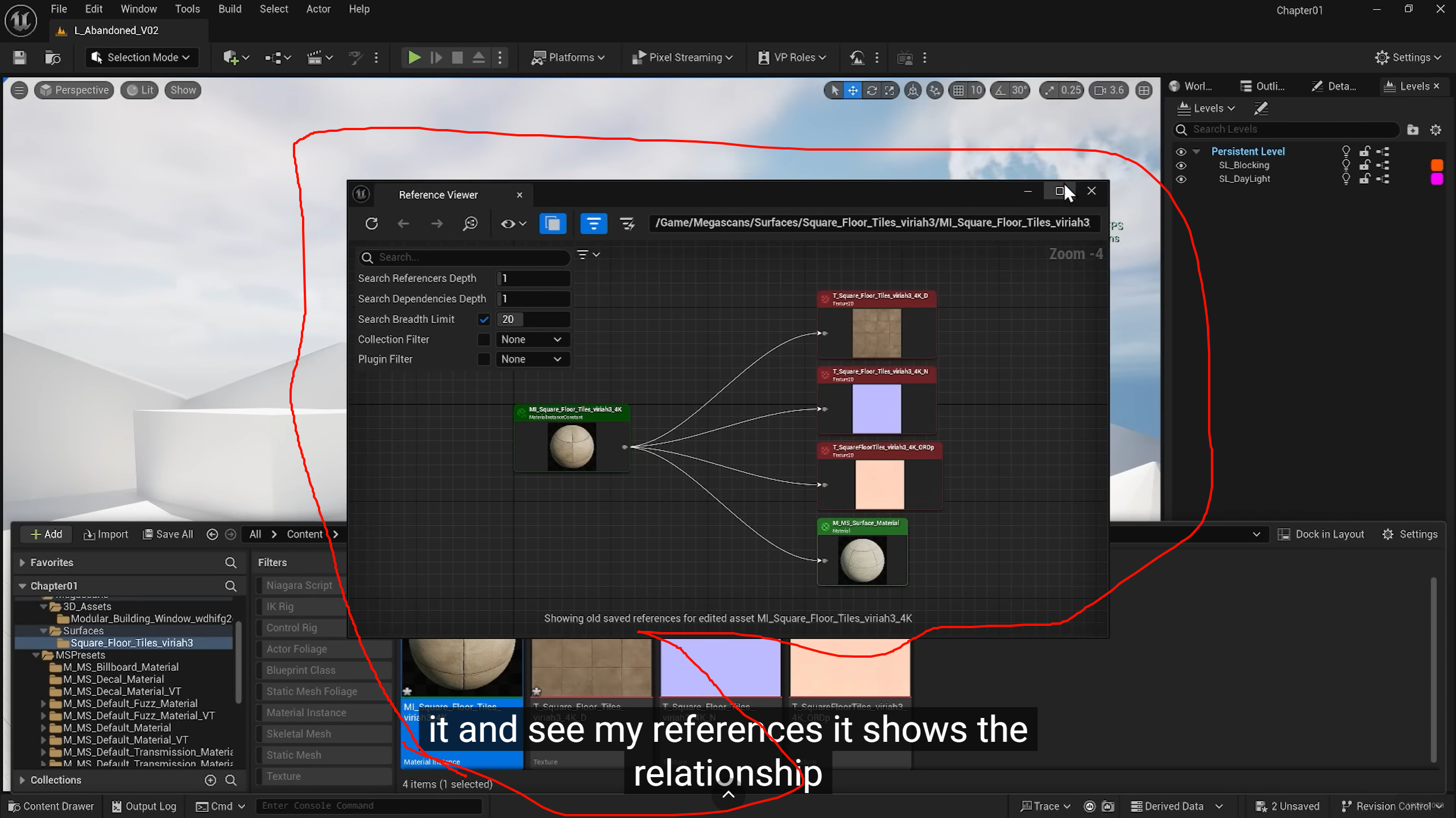
选中的是static mesh
so stupid
- My ignorant past (Focuses on lack of knowledge/awareness)
- My foolish past (Focuses on making bad choices)
Poetic & Reflective
- The folly of my youth (Classic, literary feel)
- My unspent years of ignorance (A bit more dramatic)
效率(Performance/Efficiency)不取决于你的意识(Conscious Awareness/Volitional Control),而是取决于自动化、潜意识加工、技能固化与神经通路的流畅度 ------ 这是认知心理学、神经科学与心流研究的核心结论。意识的作用是 启动、学习、纠错、处理新奇 ,而非维持高效执行; 越依赖刻意意识监控,效率越低。
认知科学基础:双重加工模型(System 1 vs. System 2)
Kahneman & Tversky(1979, 2011) 提出人类认知分为两套系统:
1. 意识系统(System 2 / 控制加工 Controlled Processing)
- 特征 :串行、慢速、高认知负荷、有限容量、需要注意力、自我监控、可主观感知
- 容量 :意识仅能处理 约 40--50 比特 / 秒 信息
- 能耗 :前额叶高度激活,极易疲劳、耗竭(Ego Depletion)
- 功能:学习新任务、逻辑推理、复杂决策、克服习惯、应对意外
- 效率 :低------ 刻意、缓慢、易出错、易受干扰
2. 潜意识 / 自动化系统(System 1 / Automatic Processing)
- 特征 :并行、极速、低 / 无负荷、大容量、无意识、不可控、习惯化
- 容量 :潜意识处理 约 1100 万比特 / 秒 (意识的 20 万倍)
- 能耗 :基底神经节、小脑、枕颞顶网络主导,能耗低 40--80%
- 功能:模式识别、技能执行、直觉、语义激活、情绪反应、习惯
- 效率 :高------ 流畅、稳定、错误率低、抗干扰
经典实验:复杂决策的「无意识思考优势」(Dijksterhuis 2006, 2009)
荷兰阿姆斯特丹大学 4 项实验(Science, 2006):
- 简单任务 (选毛巾、厨具):意识思考更优
- 复杂任务 (选房、选车、多维度决策):
- 组 A :有意识仔细思考 → 满意度低、错误多
- 组 B :分心后凭直觉(无意识加工)→ 满意度高、更优决策
- 职业高尔夫手刻意关注挥杆 → 命中率下降
- 钢琴家刻意想手指 → 卡顿、错音
- 程序员刻意想语法 → 写码变慢、BUG 增多
你不能通过主观意识监测自己是否进入了system1,这样的做法必定会导致你直接进入system1,这个问题不是一个人类可以解决的事情,人类可以解决的东西是主观意识通过加工后得出的,system1之间的对话无法导致system2更加占主导,
HUD(Heads-Up Display,平视显示器) 是 UE 中负责绘制游戏实时 UI (如血量、准星、提示文字、菜单)的核心类,继承自 AHUD(原生 C++)或通过 UHUDWidget(UMG)实现。
相机卡住是因为你的项目代码 / 蓝图中存在对 HUD 实例的依赖 ,当 HUD 为 None 时,触发空引用错误 ,导致游戏线程阻塞 或相机控制逻辑中断,
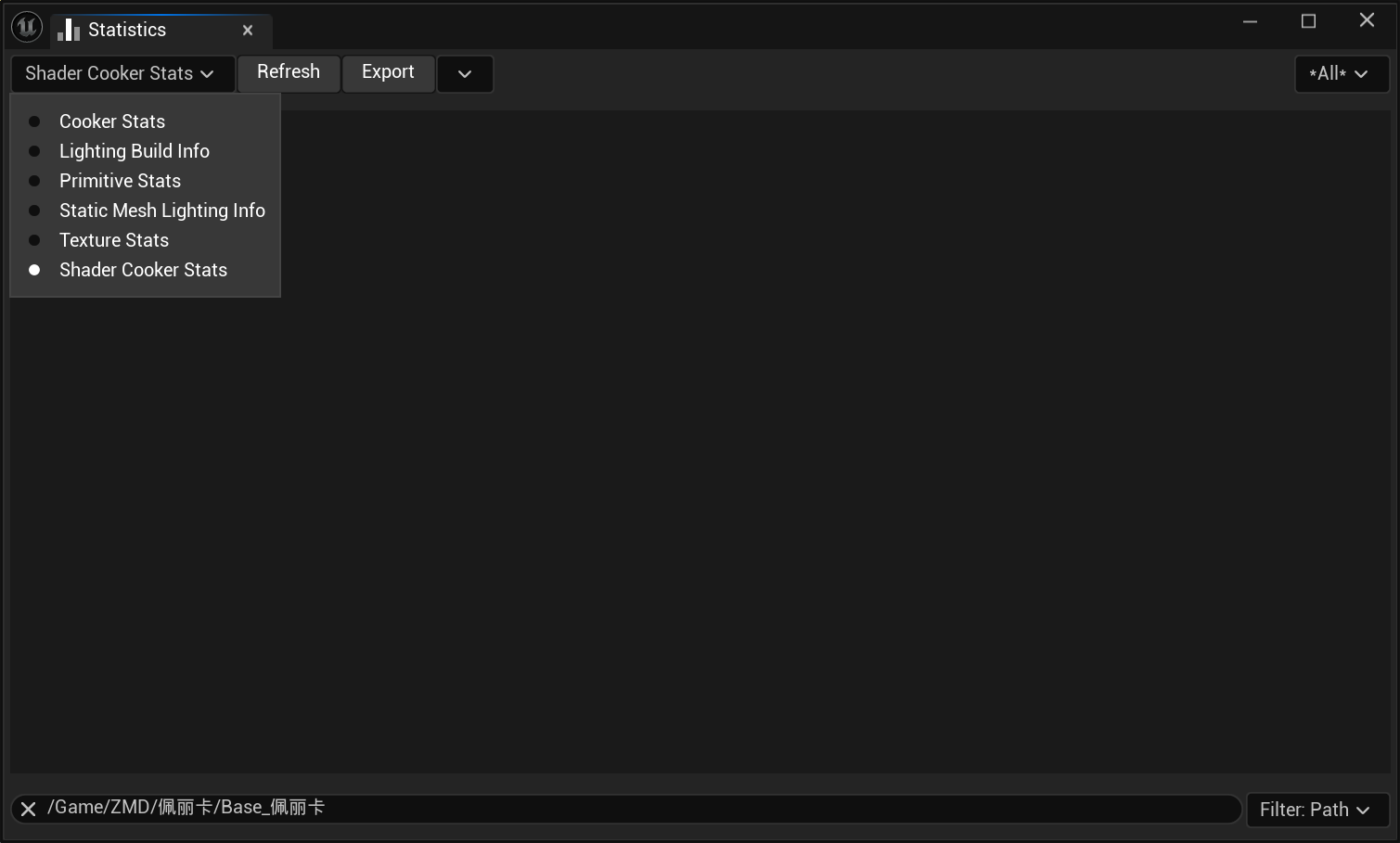
Shader Cooker Stats
着色器变体数量、编译耗时、目标平台支持情况,排查运行时着色器编译卡顿(Shader Pop)、着色器编译失败的问题。
Static Mesh Lighting Info
查看:静态网格体的光照贴图 UV 布局、光照贴图分辨率、烘焙错误信息,排查单个模型光照烘焙异常(如漏光、黑块)。
Cook-------UE 打包前将资源转换 为多平台 各自的格式
级联效应 (Cascading Effect)
当你打开或加载中间那个蓝色方框( BP_ThirdPersonCharacter 角色蓝图)时,引擎必须同时加载右侧所有与之连接的资源(如模型、材质、动画、粒子效果等)。
- 什么是级联效应? 如果你修改了右侧某个底层资源,或者这个角色蓝图本身被成百上千个其他蓝图引用,那么这种"连接关系"就像多米诺骨牌一样。
蓝图文件变得异常巨大,通常是因为 引用关系太乱。
- 硬引用 (Hard Reference):如图中所示,直接连在一起。加载角色时,右侧所有东西都会被强行塞进内存。
- 优化方案:开发者通常会学习使用"软引用 (Soft Reference)"或"接口 (Interface)"来断开这些连线,避免因为一个小改动就引起大规模的"级联反应"。
"级联"会导致内存膨胀 (Memory Bloat) :数据之间形成了强耦合 (Tight Coupling) 。即使你当前的关卡只需要角色跑动,不需要他施放技能,但因为蓝图里硬引用了技能特效,内存依然会把粒子系统和音效数据全部载入。序列化污染 (Serialization Contamination) :
当你修改右侧底层的一个结构体(Struct)或枚举(Enum)时,由于依赖链的存在,所有上游文件(向左追溯)的 DDC (Derived Data Cache) 都会失效,触发大规模的重新编译或重新保存。
循环引用风险 (Circular Dependency) :
如果数据流向成环(A 引用 B,B 引用 A),在数据加载阶段可能导致初始化顺序错误,甚至造成引擎启动时的死锁(Deadlock)。
数据表中只记录资源的 String Path (字符串路径),而不建立二进制链接。只有在逻辑真正需要时,才通过 Async Load (异步加载)将数据读入内存。
具体资产(Mesh/Texture)从逻辑蓝图中剥离,存储在 Data Asset 或 DataTable 中。角色类只持有一个指向 Data Asset 的引用,从而切断复杂的级联逻辑。
- 数据结构支持 :引擎预设了
UDataAsset类和UDataTable结构。它们在底层已经实现了序列化、编辑器内编辑和数据解析的功能。 - 软引用机制 (Soft References) :引擎提供了
TSoftObjectPtr(C++)和Soft Object Reference(蓝图)的数据类型。它允许你存储一个指向资产的"路径字符串",而不是直接把资产读入内存。
- 异步加载器 (Async Loading) :引擎内置了
StreamableManager,当你通过数据表找到某个资产路径时,引擎已经准备好了异步加载的接口,确保不会因为读取大贴图而卡住主线程。
你需要额外手动处理的部分 (Your Responsibility)
- 默认做法(错误) :在角色蓝图(BP_Character)的组件里,直接在
Skeletal Mesh下拉菜单里选好模型。这会产生硬引用。 - 你的工作 :
- 创建一个
PrimaryDataAsset(例如命名为PDA_HeroSkin)。 - 在这个 Data Asset 里定义变量:
Mesh、SkinTexture、IdleAnimation。 - 在角色蓝图中,删掉 原本选好的模型,只添加一个变量:
DataAssetReference。 - 在
BeginPlay时,根据这个变量去读取并给组件赋值。
- 创建一个
手动管理"加载时机" (Loading Policy)
- 引擎默认 :如果你在变量里用了"硬引用",引擎会在加载角色时自动、同步地加载所有关联资产(级联效应的来源)。
- 你的工作 :
- 将 Data Asset 里的资产变量类型改为 "软引用" (Soft Reference)。
- 编写逻辑:当玩家点击"换装"或"生成角色"时,显式调用
Async Load Asset节点。----也就是脱离级联,引擎本身也是在驯化开发者,不要写一坨,分开的话我给你我做好的优化奖励 - 处理加载完成后的回调(On Loaded),将加载好的对象设置给模型组件。
- 引擎默认:不知道你的游戏需要什么数据。
- 你的工作 :定义
DataTable的行结构(Row Structure)。例如:武器表应该包含攻击力(Float)、模型(Soft Mesh)、音效(Soft Sound)等。你需要规划哪些数据是常驻内存的,哪些是按需加载的。
引擎给了你"保险箱(DataAsset)"和"提取码(Soft Reference)",但如果你为了图省事直接把"金条(Mesh/Texture)"缝在"衣服(角色蓝图)"上,级联效应就无法避免。
将硬引用改为 TSoftObjectPtr 或 FPrimaryAssetId 时,该资源在 Reference Viewer 中的连线会消失。这意味着引擎的 Linker 在序列化该蓝图时,其 Import Table 会变干净。
-
- 加载该蓝图的
LoadPackage耗时会从"线性增长"变为"常数级"。
- 加载该蓝图的
专业开发需要区分什么是 "常驻内存数据" ,什么是 "瞬时负载资产"。
DataAsset/DataTable :仅存放轻量级的原始数据(数值、配置、资源路径字符串)。这是 "元数据域"。
Mesh/Texture/Anim :这是 "二进制大对象(Blob)域"。
把 Mesh 直接塞进 Character 蓝图,你就模糊了这两个域。
DataAsset 中转,你建立了一个中介层(Mediation Layer)。
级联效应的危害:在于其"过早绑定"。在游戏启动时,引擎就得确定这个 Character 到底长什么样,导致不必要的 IO 峰值。
极大地降低了 CDO(Class Default Object) 的体积。如果 CDO 太大,在编辑器里修改一个变量触发的 Reinstancing (重实例化)会让开发者体验极其痛苦(频繁的几秒钟卡顿)。
- Character -> 引用一个 Interface (无硬引用)。
- Character -> 持有一个 AssetID (只是个名字)。
- AssetManager -> 根据 AssetID 找到特定的 DataAsset。
- DataAsset -> 指向 SoftObjectPath。
当你做到这一步,引擎给你的终极奖励是:
你的项目可以轻松做 "热更新(Patching)" 、 "性能分级(LOD for Memory)" 以及 "秒开的编辑器体验"。