设计目标 :建立系统化认知框架,理解 Agent 与传统程序的本质差异,掌握 ReAct 思维链、工具调用等核心范式,为后续编码实践奠定理论基石。避免"只会调 API 不懂原理"的陷阱。
2.1 Agent 本质:从"程序"到"自主实体"的范式跃迁
🔑 核心定义(对比传统 Linux 应用)
表格
| 维度 | 传统 Linux 应用 | 智能体(Agent) | 为什么重要 |
|---|---|---|---|
| 执行模型 | 确定性流程(if-else/循环) | 概率性推理 + 工具调用 | Agent 需处理模糊指令 |
| 输入 | 结构化参数(CLI 参数/配置文件) | 自然语言指令 + 环境上下文 | 需解析人类意图 |
| 决策 | 预设逻辑分支 | LLM 推理 + 工具选择 | 动态生成执行路径 |
| 输出 | 固定格式结果(stdout/文件) | 多模态响应(文本/动作/反思) | 需适应用户需求 |
| 状态管理 | 进程内存/文件系统 | 对话历史 + 工具状态缓存 | 支持多轮交互 |
2.2 Agent 核心组件深度解析(附代码骨架)
🧠 三元架构模型
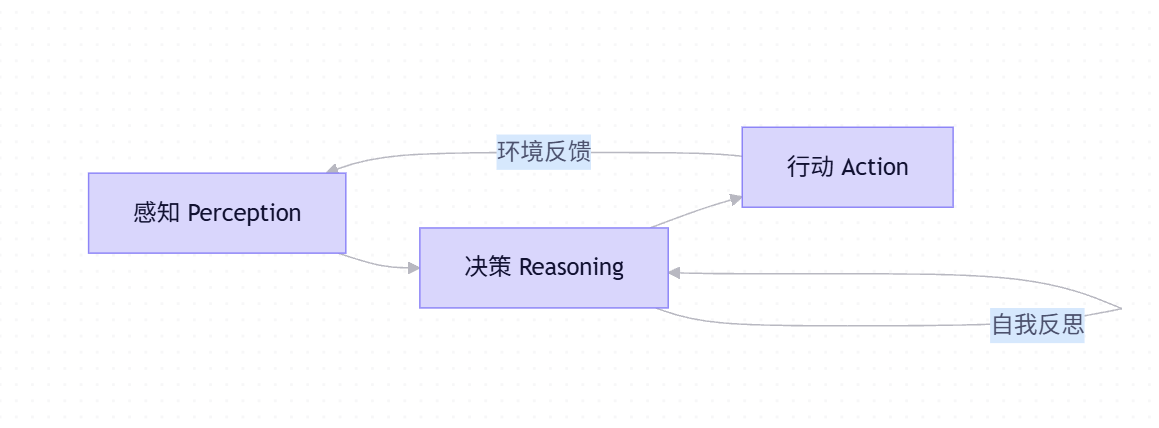
1. 感知层(Perception)
- 输入:用户指令 + 工具输出 + 历史对话
- 关键处理 :
- 指令解析(提取意图/参数)
- 上下文压缩(避免 token 溢出)
- 敏感信息过滤(安全前置)
2. 决策层(Reasoning)← 核心创新区
- 思维链(Chain-of-Thought):LLM 生成推理步骤
- 工具选择(Tool Selection):根据当前状态选择技能
- 错误恢复:检测工具调用失败并重试/换工具
3. 行动层(Action)
- 工具执行:调用预定义函数(如搜索、计算)
- 结果格式化:将工具输出转为 LLM 可理解的文本
- 状态更新:持久化关键中间结果
2.3 ReAct 框架:推理与行动的黄金标准
📜 原理精解(对比 CoT)
| 方法 | 思维链 | 行动能力 | 适用场景 |
|---|---|---|---|
| CoT | "因为...所以..." | ❌ 无 | 纯推理问题 |
| ReAct | "思考→行动→观察→再思考" | ✅ 工具调用 | 需外部知识/操作的任务 |
最小可运行 ReAct 示例(纯 Python + requests)
python
import requests
import json
class ReActAgent:
def __init__(self, llm_api_key):
self.llm_api_key = llm_api_key
self.history = []
def think(self, query: str) -> str:
"""生成 ReAct 思维链(简化版)"""
prompt = f"""
当前任务:{query}
历史行动:
{chr(10).join(self.history[-3:]) if self.history else '无'}
请按格式输出:
Thought: [你的推理]
Action: [工具名] [参数]
Observation: [等待工具返回]
"""
# 实际项目应调用 LLM API(此处简化)
return "Thought: 需要查询天气 → Action: get_weather Beijing"
def act(self, action: str) -> str:
"""执行工具调用"""
if action.startswith("get_weather"):
city = action.split()[1]
# 模拟天气 API 调用
return f"Observation: {city} 当前晴,25°C"
return "Observation: 未知工具"
def run(self, query: str, max_steps=3):
for step in range(max_steps):
thought_action = self.think(query)
print(f"🔄 Step {step+1}: {thought_action}")
if "Action:" in thought_action:
action = thought_action.split("Action:")[1].strip()
obs = self.act(action)
self.history.append(f"{thought_action}\n{obs}")
print(f"✅ {obs}")
if "Answer:" in obs: # 终止条件
return obs.split("Answer:")[1].strip()
else:
return thought_action # 直接回答
return "⚠️ 达到最大推理步数"
# 使用示例
if __name__ == "__main__":
agent = ReActAgent(llm_api_key="sk-...")
result = agent.run("北京明天适合户外活动吗?")
print(f"\n🎯 最终答案: {result}")2.4 🛠️ Skill(工具)设计黄金法则
| 原则 | 说明 | 反面案例 |
|---|---|---|
| 单一职责 | 一个 Skill 只做一件事 | "全能工具"包含搜索/计算/翻译 |
| 幂等性 | 多次调用相同参数结果一致 | 调用"随机数生成器"导致结果不可复现 |
| 明确边界 | 参数校验 + 错误提示 | 未校验城市名导致 API 404 |
| 安全沙箱 | 隔离危险操作(如文件系统) | 直接执行用户输入的 shell 命令 |
| 可观测性 | 记录调用日志/耗时 | 无法定位性能瓶颈 |