英伟达推出的一款全新模型在多项顶尖最新基准测试中一骑绝尘;它与此前表现最佳的模型相比,究竟有何不同之处?
推荐阅读:世界动作模型(WAM)的泛化能力是否优于视觉语言动作模型(VLA)?
英伟达团队前几个月发布了一系列机器人模型,其中一款在网上引发广泛热议的便是 DreamZero ------ 一种 "世界 - 动作模型",它不仅能预测机器人动作,还能生成视频预测。尤为值得关注的是,它在两项极具代表性的基准测试中均取得了榜首成绩:RoboArena 与 MolmoSpaces。

我来简要梳理一下这意味着什么,以及我们能从这些结果中获得哪些启示。在本文中,我将阐述:
-
从宏观视角解析 DreamZero 区别于其他策略模型与世界模型的核心特点
-
简要介绍 RoboArena 和 MolmoSpaces 两项基准测试
-
对其差异之处及性能提升的可能原因进行一些推测
DreamZero 是什么?

DreamZero 是英伟达推出的一款世界 - 动作模型 。实际上,它借鉴了世界模型中的诸多核心理念 ------ 主要是视频生成对机器人任务具有重要价值 这一思路,但在几个关键维度上重构了原有范式。最核心的区别在于,它同时对动作生成与视频生成进行联合建模。
通常,世界模型主要分为两类:
-
基于动作条件的世界模型
:学习观测状态 x 与动作 a 到下一状态 x' 的映射关系,即 x' = f (x, a)。典型代表如 V-JEPA 2,或是近期 RISE 论文中的世界模型。
-
逆动力学世界模型
:例如英伟达的 DreamGen 或 1x 世界模型,这类模型先学习 x' = f (x),再通过逆动力学模型得到 a = g (x, x')。
而 DreamZero 更接近传统的机器人策略模型,但同时具备预测未来视频的能力 ------ 因此其学习目标更近似于 (x', a) = f (x)。当然,以上表述都是对真实训练目标的高度简化,具体细节可查阅原论文。
也可以将其与传统的视觉 - 语言 - 动作(VLA)模型对比:DreamZero 同样会预测未来场景状态,这为世界的后续演化提供了更丰富的监督信号。
基准测试
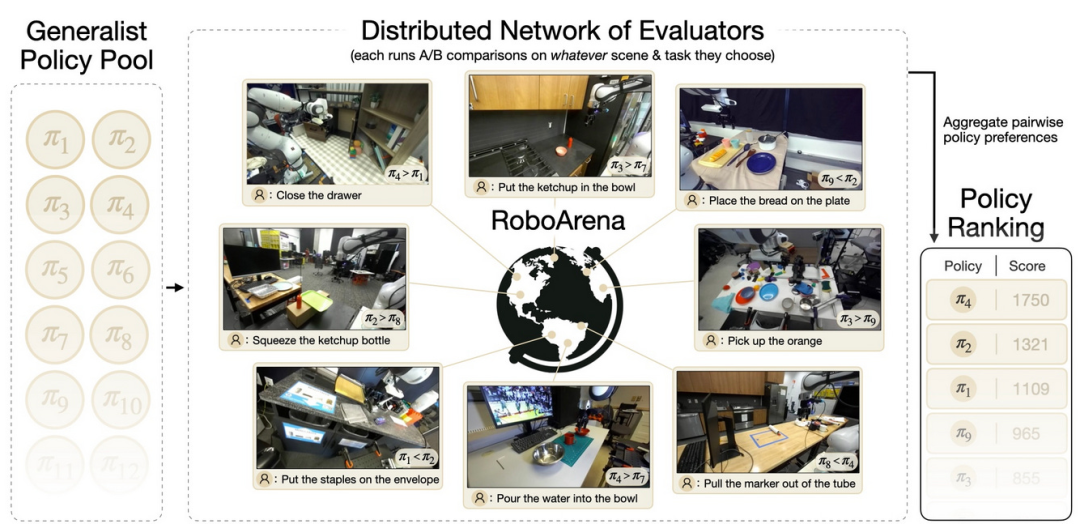
RoboArena 是一项基于 Droid 数据集的分布式 "真实世界" 评测基准。全球各地的评测人员使用配置相近的机器人与实验环境,通过不同的自然语言指令,开展一系列开放式机器人任务评测。
这意味着该测试集对 DreamZero 而言属于同分布数据,因为 DreamZero 正是在 Droid 数据集上训练的,二者包含高度相似的任务与实验设置。但即便如此,这依然是一次真实环境下的评测,面临现实场景中所有的复杂问题与环境变化,且具体任务均由评测人员选定。它同时也是一项"头对头" 对比评测基准,类似于在大语言模型发展中极具影响力的 Chatbot Arena。我曾在一篇关于机器人学习评测的文章中对此做过详细阐述。

MolmoSpaces 是一项全新的基准测试,具备高保真物理引擎以及多样化的程序化生成环境。其中,MolmoSpaces-Bench 专门用于测试模型在各类拾取、放置、打开、关闭任务及其组合任务中的可控泛化能力。
这是一个全新的评测基准,性能上限远未达到饱和。而 DreamZero 在这两项基准测试中均表现出色:

我们能从中得到什么启示?
我专门对比一下 pi-0.5 与 DreamZero,因为 pi-0.5 是目前排名第二的模型。
- 训练数据 :正如 Mahi Shafiullah 在 X 上指出的,pi-0.5 使用了超过 1 万小时的真实机器人数据、VLM 数据以及 Droid 数据集进行训练。而DreamZero 则根据不同模型版本,分别在 DROID 数据集或 Agibot 数据集上训练。
训练数据的分布很可能在这里起到了决定性作用。可以看到,在 DreamZero 论文中:DreamZero 在 AgiBot 任务上大幅超越 pi-0.5(pi-0.5 的训练数据中不包含这类数据),但在双方都使用过的 DROID-Franka 实验设置上,两者表现就非常接近。
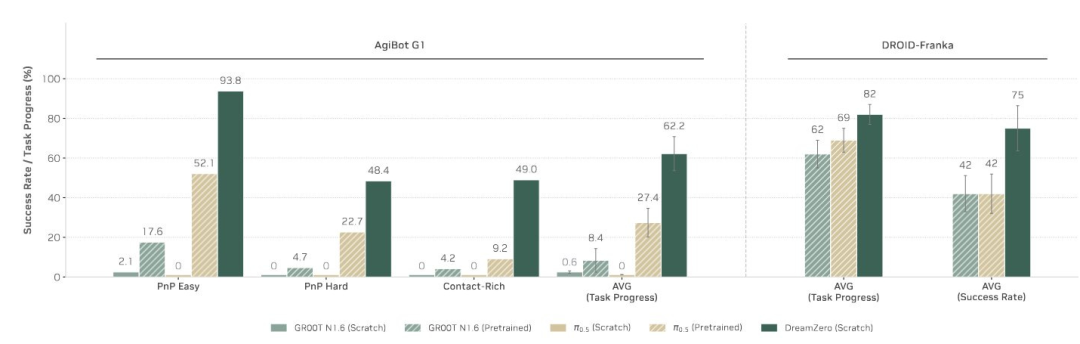
在我看来,这似乎也表明:那额外的 1 万小时机器人数据,可能并没有人们想象中那么有用 。在合适的机器人数据上做预训练,看起来才是至关重要的;在最近另一篇博客文章里,Physical Intelligence 团队也展示了:在同分布的合作方数据上进行预训练,能带来巨大的性能提升:
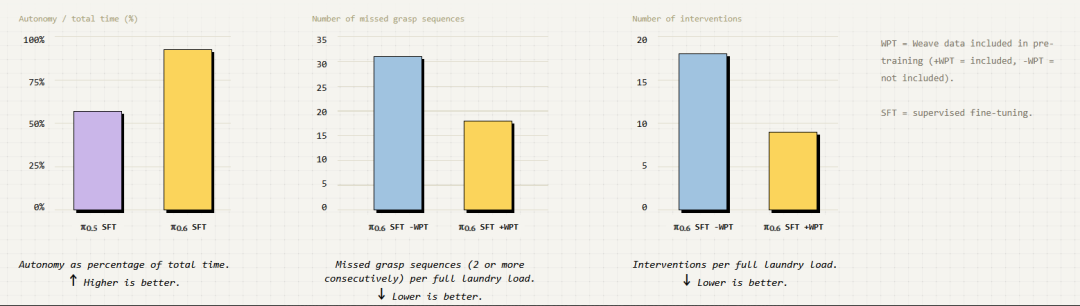
因此,从不同类型机器人 上额外采集的 1 万小时数据,或许实际上并不比你手头随便有的普通视频数据更好。这对那些想要训练跨机体通用机器人大脑的研究者来说,可能不是个好消息。也许从其他机器人形态上学到的东西,并不比直接使用廉价、海量的第一视角视频数据多多少。
模型主干 :DreamZero 基于 Wan2.1-I2V-14B-480P 构建,这是一个参数量达 140 亿 的视频生成模型,最多可支持 8 帧 上下文输入。相比之下,pi-0.5 基于参数量仅 30 亿 的开源视觉语言模型 PaliGemma 训练,模型小得多。而且它只输入单帧图像 ,而非 8 帧历史信息。这一点对部分可观测 或动力学难以建模的任务影响极大 ------ 而几乎所有真实机器人任务都属于这类情况。
模型规模 :DreamZero 是一个超大规模模型,论文中的大量工作其实都在围绕如何让这个 140 亿参数的巨型模型实现实时运行 。论文中的消融实验也表明:模型大小在此处带来了极为显著的性能差异。
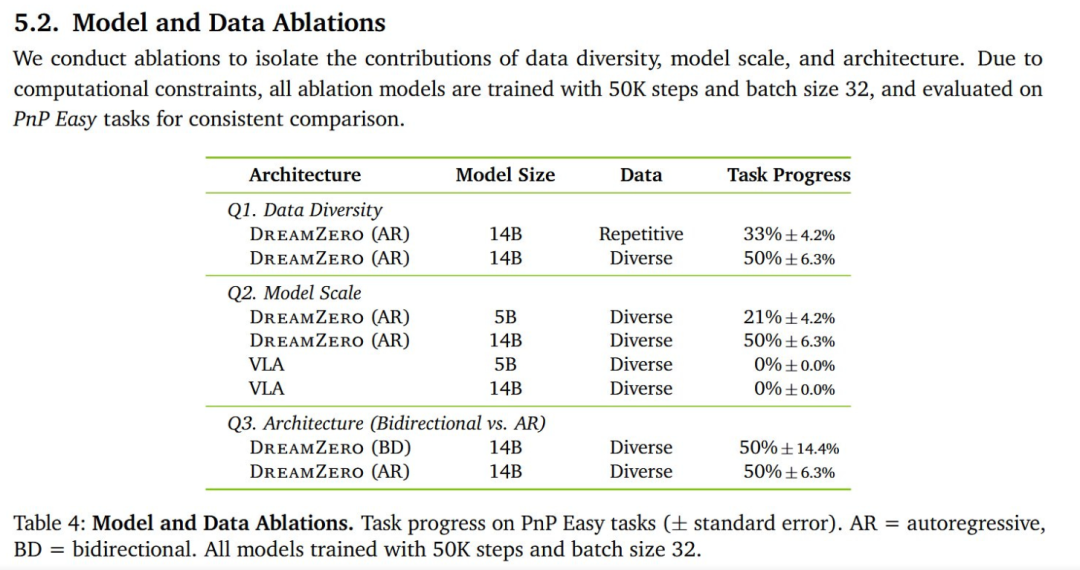
引入更多历史帧信息以及扩大模型规模,通常会带来一个问题:这往往会让模型更难训练,并且在数据量不足 的场景下更容易出现过拟合。
大语言模型(LLM)由于数据极其丰富,过拟合基本不成问题,但机器人领域与之不同 ------ 即使在今天,我们本质上始终处于数据稀缺的环境中。即便是最小的大语言模型数据集,规模也远超 DROID 数据集。
因此有一个观点:视频生成目标函数起到了 "辅助损失" 的作用,它为 DreamZero 模型构建了结构化约束,使其学习到某种内在的世界模型。与机器人动作带来的稀疏信号相比,它提供了强度更高的监督信息。这反过来让模型能更好地适配未参与训练、多样化的 MolmoSpaces 环境。
结语
仅从这些论文中,我们还无法确定很多事情。我们无法获取 Physical Intelligence 使用的全部数据,也很难接触到 NVIDIA 用于推理的 GB200 芯片。但在我看来,令人振奋的是:想要在真实机器人任务上取得出色效果,或许并不需要像之前认为的那么多数据。我也期待看到更多这一方向的研究。
我还有最后一个问题:如果视频生成 "仅仅" 是一个辅助损失,我们还需要依赖它多久?当未来部署数千台智能机器人时,这种设计最终是否会被精简掉?所有这类模型是否终将被专门针对机器人优化、做过机器人领域微调的视频模型全面超越?这看起来可能性极大,但可能还需要几年时间。
我认为视频生成模型应该会优于 VLA(视觉 - 语言 - 动作)模型。让模型的核心围绕图像 / 视频展开,比以文本为核心要更合理。
我的疑问是:**什么样的数据能提升视频生成的精度?**我猜是在预训练中加入更多视频数据,但肯定存在更有效的后训练方案或数据组合。
我认为 "辅助损失" 这个定位值得更深入地探讨。
预测未来视频不只是一种正则化手段。它会迫使模型构建一个更接近物理因果模型的结构。这种信号远比单纯的动作标签丰富得多 ------ 动作标签本质上只是一系列路径点,完全不包含这些路径点为何正确的信息。在机器人这种数据稀缺的场景下,这种差异带来的效果会快速放大。
我最近在思考的一点是:在我看来,问题或许不是 "视频生成模块最终会不会被蒸馏掉",而是 "蒸馏之后,世界表征会以何种形式保留下来?"
像素级的视频生成能力可能会被蒸馏掉,但它所学到的因果推理能力必须以某种方式保留。在没有视频生成目标作为训练支架的情况下,能否做到这一点,在我看来是更核心的开放性问题。