 文档说明:
文档说明:
本手册旨在指导初级实施人员在 Proxmox VE (PVE) 虚拟化环境中,从零开始搭建 Oracle 19c RAC (Real Application Clusters) 双节点集群。该集群将作为高可用容灾备份平台的底层基座,具备节点级故障自动切换(Failover)与完整归档恢复能力。
📑 全书总体大纲
为确保部署过程的条理性,本实施手册分为以下六个章节依次推进:
-
第一章:架构规划与 PVE 底层配置
-
明确网络 IP 规划与核心软件准备。
-
完成 PVE 虚拟机双网卡及共享存储(Shared Storage)的底层强制配置。
-
-
第二章:操作系统环境预处理
-
配置 Linux 系统主机解析(hosts)。
-
创建集群专属的用户与组隔离体系。
-
配置 UDEV 规则,实现共享磁盘的固化与赋权。
-
-
第三章:Grid Infrastructure 核心准备与排雷
-
核心软件的静默解压规范。
-
安装集群心跳依赖组件(cvuqdisk)。
-
-
第四章:Grid 集群大脑部署与资源拉起
-
通过图形界面初始化集群,拉起 VIP 与 SCAN IP 资源。
-
配置 ASM(自动存储管理)集群注册表磁盘组。
-
-
第五章:ASM 数据盘划分与数据库软件安装
-
创建业务数据专属的 ASM 磁盘组(+DATA)。
-
完成 Oracle Database 软件的纯二进制安装。
-
-
第六章:DBCA 集群建库与容灾特性开启
-
使用 DBCA 实例化 RAC 数据库。
-
开启归档模式(Archive Mode)与快速恢复区(FRA),完成容灾底座验收。
-
🟢 第一章:架构规划与 PVE 底层配置
RAC 架构的核心在于"共享"与"冗余"。在开始任何操作系统的配置之前,必须在虚拟化底层打好坚实的网络与存储基础。
1.1 网络架构与 IP 地址规划
Oracle RAC 依赖多层网络来实现业务访问与底层数据同步。每个节点至少需要配置两块物理/虚拟网卡。请在部署前,严格按照下表规划并记录您的 7 个 IP 地址:
| IP 角色分类 | 数量 | 作用描述 | 示例网段地址 |
|---|---|---|---|
| Public IP (公网/管理) | 2 | 绑定于网卡 1。用于管理员 SSH 登录服务器,以及基础的网络通信。 | rac1: 192.168.10.244 rac2: 192.168.10.243 |
| Private IP (私网/心跳) | 2 | 绑定于网卡 2。专用于两个节点间的高速内存数据同步(Cache Fusion)。必须与 Public IP 处于不同网段。 | rac1: 10.10.10.1 rac2: 10.10.10.2 |
| Virtual IP (VIP) | 2 | 逻辑 IP,挂载于网卡 1。当某节点宕机时,VIP 会自动漂移至存活节点,加速客户端连接的故障转移。 | rac1-vip: 192.168.10.242 rac2-vip: 192.168.10.241 |
| SCAN IP (统一入口) | 1 | 整个集群对外的唯一逻辑入口。业务系统或备份软件只需连接此 IP,由其进行负载均衡。 | rac-scan: 192.168.10.240 |
1.2 核心软件准备
请前往 Oracle 官方网站下载适用于 Linux x86-64 平台的 19c 核心安装包。RAC 环境必须同时部署以下两个组件:
-
Grid Infrastructure (GI):
LINUX.X64_193000_grid_home.zip(集群管理软件,提供 ASM 存储及高可用组件支持)。 -
Oracle Database:
LINUX.X64_193000_db_home.zip(数据库核心程序)。
1.3 PVE 虚拟机创建与网卡配置
-
在 Proxmox VE 中创建两台虚拟机,分别命名为
rac1和rac2(记录其对应的 VM ID,如 100 和 101)。 -
网络配置: 为每台虚拟机添加两块网络设备。
-
net0: 接入业务网桥(如vmbr0),对应 Public IP 网段。 -
net1: 接入独立的内部网桥(如vmbr1或隔离的 VLAN),对应 Private IP 网段。
-
-
安装 Oracle Linux 7.x 或 CentOS 7.x 操作系统。
1.4 PVE 共享存储强制配置(关键步骤)
单机环境下的虚拟磁盘是独占模式。要运行 RAC,必须配置共享磁盘(Shared Disk),使两台虚拟机能够同时对其进行并发读写。
步骤 1:添加磁盘实体
在 PVE 图形界面中,为 rac1 虚拟机添加两块新的硬盘。总线/设备类型建议选择 VirtIO Block 或 SCSI。
-
磁盘 1:50GB(用于存放集群 OCR 和表决磁盘)。
-
磁盘 2:200GB(用于存放业务数据)。
步骤 2:修改底层配置文件开启共享
PVE 图形界面默认不提供完全的 RAC 共享级参数设置,必须通过宿主机命令行强制修改。
-
通过 SSH 登录 PVE 宿主机(非虚拟机内部)。
-
编辑
rac1的虚拟机配置文件(假设 ID 为 100):nano /etc/pve/qemu-server/100.conf -
找到刚刚添加的磁盘行(例如
scsi1和scsi2),在行的最末尾追加共享与缓存参数,share=1,cache=none。修改后的效果如下:scsi1: local-lvm:vm-100-disk-1,size=50G,share=1,cache=none scsi2: local-lvm:vm-100-disk-2,size=200G,share=1,cache=none -
保存并退出。
-
编辑
rac2的虚拟机配置文件(假设 ID 为 101):nano /etc/pve/qemu-server/101.conf -
将
rac1配置文件中完整修改过的那两行磁盘代码,原封不动地复制粘贴 到rac2的配置文件中。 -
保存并退出。
步骤 3:验证共享状态
同时启动 rac1 和 rac2 虚拟机。分别在两台系统的命令行中输入 lsblk 命令。如果两台机器均能看到容量一致、未分区的相同磁盘(如 /dev/sdb 和 /dev/sdc),则 PVE 共享存储配置成功。
这是一份直接可执行的系统级配置标准。在安装 Oracle RAC 之前,必须对两台 Linux 操作系统进行严格的"标准化"改造,以确保网络互通、权限隔离以及磁盘路径的永久固化。
🟢 第二章:操作系统环境预处理
执行说明: 本章的所有操作,必须在 rac1 和 rac2 两台节点上分别执行,且配置内容必须保持绝对一致。
2.1 基础环境与安全机制处理
为了防止网络拦截和权限冲突,必须关闭 Linux 默认的防火墙和 SELinux。
1. 关闭并禁用防火墙:
systemctl stop firewalld
systemctl disable firewalld2. 关闭 SELinux:
编辑配置文件:
vi /etc/selinux/config将 SELINUX=enforcing 修改为 SELINUX=disabled。
(注意:修改后需重启服务器方能彻底生效,可暂缓至本章结束时一并重启)
2.2 配置集群主机名解析 (hosts)
Oracle RAC 集群内部组件高度依赖主机名进行通信,绝不能依赖路由器动态分配(DHCP)或外部 DNS。
操作步骤:
编辑 /etc/hosts 文件:
vi /etc/hosts将第一章规划的 7 个 IP 地址严格映射到主机名,并追加到文件末尾。两台机器的配置必须一字不差:
# Public IP (管理网络)
192.168.10.244 rac1
192.168.10.243 rac2
# Private IP (心跳网络)
10.10.10.1 rac1-priv
10.10.10.2 rac2-priv
# Virtual IP (VIP,高可用飘移地址)
192.168.10.242 rac1-vip
192.168.10.241 rac2-vip
# SCAN IP (业务统一入口)
192.168.10.240 rac-scan2.3 创建集群专属的用户与组隔离体系
在生产级 RAC 架构中,职责必须分离:集群和共享存储由 grid 用户管理,而数据库软件及实例由 oracle 用户管理。
操作步骤:
依次执行以下命令,建立标准化的 Oracle 用户与组结构:
# 1. 创建基础组与数据库组
groupadd -g 54321 oinstall
groupadd -g 54322 dba
groupadd -g 54323 oper
# 2. 创建 ASM(自动存储管理)专属组
groupadd -g 54324 asmadmin
groupadd -g 54325 asmdba
groupadd -g 54326 asmoper
# 3. 创建 oracle 用户,并将其加入相关组
useradd -u 54321 -g oinstall -G dba,oper,asmdba oracle
# 4. 创建 grid 用户,并将其加入相关组
useradd -u 54322 -g oinstall -G asmadmin,asmdba,asmoper,dba grid
# 5. 分别设置密码(建议设置为统一的安全密码,例如 ABCD123)
passwd oracle
passwd grid2.4 配置 UDEV 规则绑定共享磁盘
原理说明: Linux 系统每次重启,由于驱动加载顺序不同,共享磁盘的盘符可能会发生变化(例如原来的 /dev/sdb 变成了 /dev/sdc)。如果不加干预,集群将找不到存储而全面崩溃。利用 UDEV 机制,可以通过磁盘的物理 SCSI ID,为其创建一个永久不变的别名,并赋予 grid 用户专属权限。
操作步骤:
1. 获取磁盘的唯一 SCSI ID
在任意一个节点上,针对第一章添加的 50G 和 200G 磁盘执行查询。假设这两块盘当前识别为 sdb 和 sdc:
/usr/lib/udev/scsi_id -g -u -d /dev/sdb
/usr/lib/udev/scsi_id -g -u -d /dev/sdc记录下屏幕输出的一串长字符,例如 36000c29a000000000000000000000001 和 36000c29a000000000000000000000002。
2. 编写 UDEV 规则文件
在 rac1 和 rac2 上均创建并编辑规则文件:
vi /etc/udev/rules.d/99-oracle-asmdevices.rules填入以下内容(请将 RESULT== 后面的值替换为您刚才查询到的实际 SCSI ID):
# CRS 磁盘 (50G)
KERNEL=="sd*", SUBSYSTEM=="block", PROGRAM=="/usr/lib/udev/scsi_id -g -u -d /dev/$name", RESULT=="36000c29a000000000000000000000001", SYMLINK+="asm-crs1", OWNER="grid", GROUP="asmadmin", MODE="0660"
# DATA 磁盘 (200G)
KERNEL=="sd*", SUBSYSTEM=="block", PROGRAM=="/usr/lib/udev/scsi_id -g -u -d /dev/$name", RESULT=="36000c29a000000000000000000000002", SYMLINK+="asm-data1", OWNER="grid", GROUP="asmadmin", MODE="0660"3. 重新加载 UDEV 规则并验证
执行以下命令让规则立即生效:
/sbin/udevadm trigger --type=devices --action=change4. 验证绑定结果
ls -al /dev/asm*如果能看到类似以下输出,说明磁盘别名已成功创建,且权限正确归属于 grid:asmadmin:
lrwxrwxrwx 1 root root ... /dev/asm-crs1 -> sdb
lrwxrwxrwx 1 root root ... /dev/asm-data1 -> sdc
本章验收:
至此,Linux 操作系统的底层改造完毕。建议此时将 rac1 和 rac2 重启一次,重启后再次执行 ls -al /dev/asm* 和 ping rac1 等命令。如果磁盘别名依然存在且网络解析正常,即可进入下一章的软件安装环节。
🟢 第三章:官方软件获取与 Grid 核心准备
执行说明: 本章将带您从 Oracle 官网获取纯正的安装包,创建标准化的目录结构,并处理一个极易导致安装失败的"隐藏依赖"。
3.1 课前必备:去哪里搞到这两个"大家伙"?
Oracle 19c RAC 的部署需要两个独立的安装包。请在您的个人电脑(Windows/Mac)上提前准备好。
获取步骤:
-
注册账号: 访问 Oracle 官方网站(oracle.com),注册一个免费的个人账户。
-
访问下载页: 搜索或直接访问 "Oracle Database 19c Download" 页面。
-
选择版本: 必须选择
Linux x86-64版本。 -
下载这两个文件:
-
集群大脑包 (Grid): 找到
Oracle Database 19c Grid Infrastructure,下载得到压缩包(文件名通常为LINUX.X64_193000_grid_home.zip,约 2.8GB)。 -
数据库程序包 (Database): 找到
Oracle Database 19c,下载得到压缩包(文件名通常为LINUX.X64_193000_db_home.zip,约 3GB)。(小白提示:这两个包先存放在您的个人电脑上,稍后我们将通过工具把它们传到 Linux 服务器里。)
-
3.2 创建标准化安装目录
Oracle 官方推荐使用 OFA (Optimal Flexible Architecture) 标准路径。必须提前规划好这两个包"解压安家"的目录,并赋予严格的权限。
操作步骤:在 rac1 和 rac2 两台机器上,分别以 root 用户执行:
# 1. 创建 Grid 软件的家目录 (稍后放那个 2.8G 的包)
mkdir -p /u01/app/19.3.0/grid
# 2. 创建 Oracle 数据库的基础目录和家目录 (稍后放那个 3G 的包)
mkdir -p /u01/app/oracle/product/19.3.0/db_home
mkdir -p /u01/app/oracle/oraInventory
# 3. 严格分配目录的所有权 (这一步错将导致后续完全无法安装)
chown -R grid:oinstall /u01/app/19.3.0/grid
chown -R oracle:oinstall /u01/app/oracle
chown -R grid:oinstall /u01/app/oracle/oraInventory
# 4. 赋予 775 读写执行权限
chmod -R 775 /u01/3.3 配置专属环境变量
环境变量相当于告诉 Linux 系统,当你敲击 Oracle 命令时去哪里找程序,以及当前节点叫什么名字。
操作步骤:分别在两台节点上配置。 (注意:rac1 和 rac2 里的 ORACLE_SID 参数不一样!)
1. 配置 Grid 用户的环境变量
在 rac1 以 root 执行 su - grid,编辑 vi ~/.bash_profile,追加以下内容:
# rac1 节点的 Grid 环境变量
export ORACLE_BASE=/u01/app/grid
export ORACLE_HOME=/u01/app/19.3.0/grid
export ORACLE_SID=+ASM1
export PATH=$ORACLE_HOME/bin:$PATH在 rac2 以 root 执行 su - grid,编辑 vi ~/.bash_profile,追加以下内容:
(注意:rac2 的 SID 为 +ASM2)
# rac2 节点的 Grid 环境变量
export ORACLE_BASE=/u01/app/grid
export ORACLE_HOME=/u01/app/19.3.0/grid
export ORACLE_SID=+ASM2
export PATH=$ORACLE_HOME/bin:$PATH执行 source ~/.bash_profile 使其生效。
2. 配置 Oracle 用户的环境变量
在 rac1 执行 su - oracle,编辑 vi ~/.bash_profile,追加:
# rac1 节点的 Oracle 环境变量
export ORACLE_BASE=/u01/app/oracle
export ORACLE_HOME=$ORACLE_BASE/product/19.3.0/db_home
export ORACLE_SID=orcl1
export PATH=$ORACLE_HOME/bin:$PATH在 rac2 执行 su - oracle,编辑 vi ~/.bash_profile,追加:
# rac2 节点的 Oracle 环境变量
export ORACLE_BASE=/u01/app/oracle
export ORACLE_HOME=$ORACLE_BASE/product/19.3.0/db_home
export ORACLE_SID=orcl2
export PATH=$ORACLE_HOME/bin:$PATH执行 source ~/.bash_profile 使其生效。
3.4 核心软件包的上传与静默解压
严重警告: 许多初学者习惯用 root 上传解压,然后再去改权限。在 19c RAC 部署中,严禁使用 root 处理安装包,否则会在安装最后阶段遭遇权限校验崩溃。
操作步骤:仅在 rac1 节点执行:
-
打开文件传输工具(如 Xftp 或 WinSCP)。
-
使用
grid用户登录rac1服务器。 -
找到您在
3.1步骤下载的 集群大脑包 (LINUX.X64_193000_grid_home.zip)。 -
将该压缩包拖拽上传至刚才创建的对应目录中:
/u01/app/19.3.0/grid。 -
在
rac1命令行下,以grid用户身份进入该目录并解压。(小白提示:必须加入
-q参数进行静默解压。因为该包有几十万个小文件,直接解压会造成屏幕狂闪甚至软件卡死。)su - grid
cd /u01/app/19.3.0/grid
unzip -q LINUX.X64_193000_grid_home.zip
(解压约需 2-5 分钟,请喝口水,耐心等待命令行提示符重新出现。)
3.5 关键排雷:安装 cvuqdisk 依赖组件
为什么要做这一步? cvuqdisk 是集群检查共享磁盘的底层依赖。如果不装,稍后的安装图形界面会像瞎子一样,死活认不出你配置好的共享盘,导致部署直接"流产"。这个救命的安装包,就隐藏在刚刚解压出来的文件夹里。
操作步骤:
1. 在 rac1 上安装:
切换回 root 用户,定位到 rpm 目录进行安装:
# 声明环境变量,指定磁盘管理组
export CVUQDISK_GRP=dba
# 执行 RPM 安装
rpm -ivh /u01/app/19.3.0/grid/cv/rpm/cvuqdisk-1.0.10-1.rpm2. 在 rac2 上安装:
在 rac1 的 root 用户下,通过 scp 命令将该包推送给 rac2:
scp /u01/app/19.3.0/grid/cv/rpm/cvuqdisk-1.0.10-1.rpm root@rac2:/tmp/随后,登录 rac2 的 root 用户,执行安装:
export CVUQDISK_GRP=dba
rpm -ivh /tmp/cvuqdisk-1.0.10-1.rpm🟢 第四章:安装集群大脑 (Grid) 与拉起 VIP
执行说明: 本章操作主要在 rac1 节点上,通过图形化界面完成。请确保您使用的是带 X11 图形转发功能的终端工具(强烈推荐新手使用 MobaXterm)。
4.1 呼出图形化安装向导
为什么不能直接敲命令? Grid 的安装涉及极其复杂的跨节点校验,图形化界面的向导能帮我们规避 90% 的配置错误。
操作步骤:
-
在您的个人电脑上,打开 MobaXterm。
-
使用
grid用户(注意:绝不能用 root !)SSH 登录到rac1(192.168.10.244)。 -
进入我们上一章解压好的 Grid 目录,启动安装程序:
cd /u01/app/19.3.0/grid ./gridSetup.sh -
等待几秒钟,屏幕上会弹出一个带有 Oracle Logo 的图形化安装窗口。
(小白提示:如果报错说
Display not set,说明您的终端不支持图形转发。请换用 MobaXterm,并在 Session 设置中确认 X11 forwarding 是开启的。)
4.2 图形向导通关秘籍(核心 7 步)
接下来是纯图形化点选,请严格按照以下说明填写,这是咱们"灾备底座"成败的关键。
-
Configuration Option (配置选项): 选择
Configure a New Cluster(配置一个新集群),点击 Next.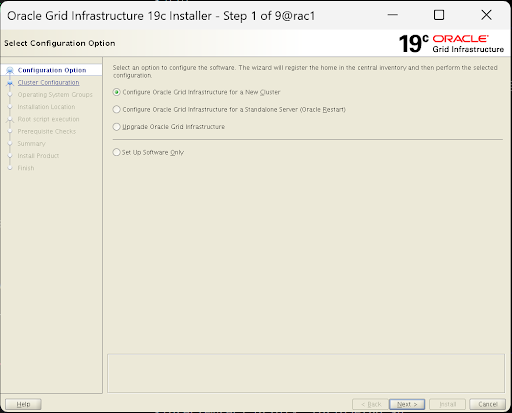
-
Cluster Name & SCAN (集群名与统一入口):
-
Cluster Name: 填
rac-cluster -
SCAN Name: 必须填咱们在
/etc/hosts里写的那个名字:rac-scan。 -
SCAN Port: 保持默认
1521。
-
-
Cluster Node Information (节点情报局):
-
列表里现在只有 rac1。点击下方的
Add...按钮。
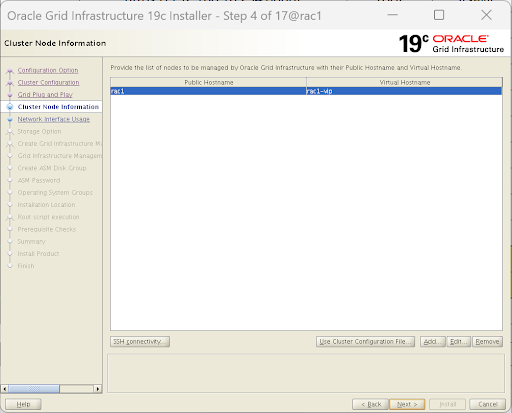
-
Public Hostname: 填
rac2 -
Virtual Hostname: 填
rac2-vip -
重点:点击
SSH Connectivity按钮。 填入 grid 用户的密码(ABCD123),点击Setup。程序会自动把两台机器打通"免密互信"。成功后点击 Next。
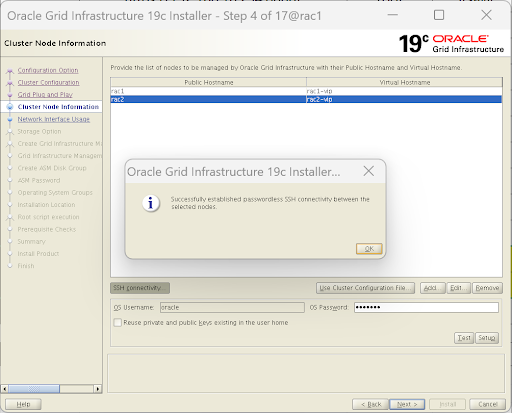
-
-
Network Interface Usage (网卡认亲):
系统会列出你的两块网卡(比如 eth0 和 eth1)。
-
192.168.10.x 网段的网卡,Usage 必须选
Public。 -
10.10.10.x 网段的网卡,Usage 必须选
ASM & Private(这是心跳线,选错必崩)。
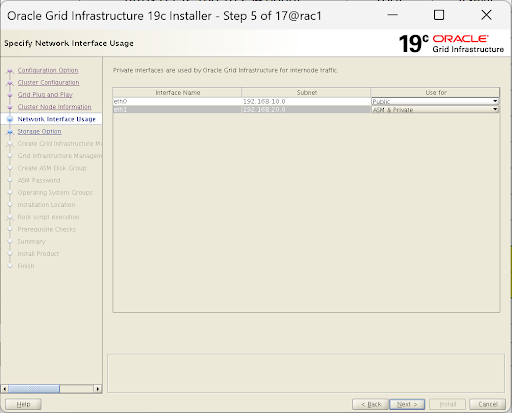
-
-
Storage Option (存储配置):
-
选择
Configure an Oracle Standalone Cluster。 -
在创建 ASM 磁盘组页面:
-
Disk Group Name: 填
+CRS(这是放集群配置的专有硬盘)。 -
Redundancy (冗余度): 因为咱们是 PVE 底层,选
External即可。 -
在下方列表中,勾选咱们在第二章绑定的那个 50G 磁盘(路径可能是
/dev/asm-crs1)。(小白提示:如果列表是空的,点击
Change Discovery Path,输入/dev/asm*就能扫出来了。)
-
-
Passwords (密码设置):
选择
Use same passwords for these accounts,统一填入打算设置的密码。有警告提示密码不够复杂,直接选 Yes 忽略。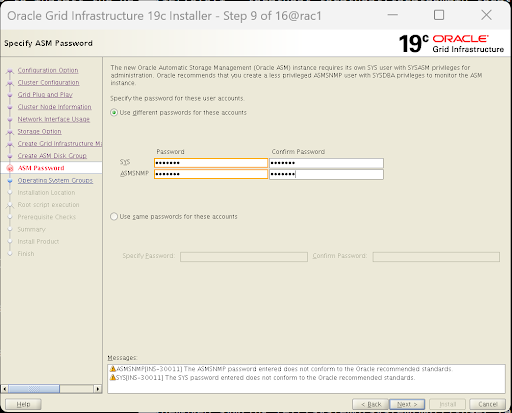
-
-
Prerequisite Checks (环境大考):
程序会自动检查两台机器的状态。
- 如果在 PVE 环境下提示
Resolv.conf、NTP或轻微的内存 Swap 警告(只要不是红色的 Error),可以直接勾选右上角的Ignore All(全部忽略),然后点击 Next 强制通过。
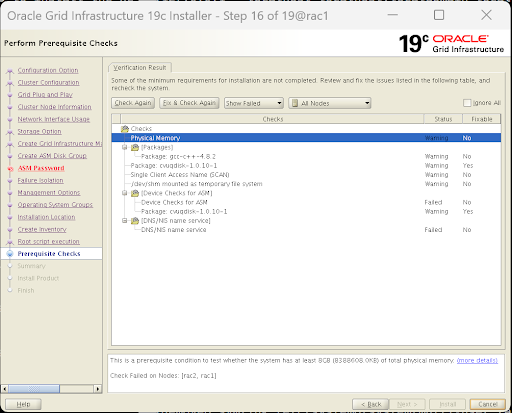
- 如果在 PVE 环境下提示
点击 Install,安装进度条正式开始滚动。
4.3 关键动作:执行 Root 脚本
安装进度条走到大约 80% 时,图形界面会突然弹出一个对话框,让你暂停! 它要求你在两台机器上以管理员身份执行几个脚本。
操作步骤:
请严格按照对话框里的顺序执行!
-
重新打开两个黑框框终端,分别用
root用户登录rac1和rac2。 -
第一步: 在
rac1敲入:/u01/app/oracle/oraInventory/orainstRoot.sh -
第二步: 在
rac2敲入:/u01/app/oracle/oraInventory/orainstRoot.sh -
第三步 (耗时较长): 在
rac1敲入:/u01/app/19.3.0/grid/root.sh。看着它跑完,直到出现Successfully configured Oracle Grid Infrastructure。 -
第四步: 在
rac2敲入:/u01/app/19.3.0/grid/root.sh。同样等待它跑完。
这四个脚本执行完毕后,回到图形界面,点击对话框上的 OK。向导会完成最后的收尾工作。
4.4 验收战果:见证"安全屏障"的诞生
当向导显示 Configuration of Oracle Grid Infrastructure succeeded 时,点击 Close。
此时,两台"单机"已经被彻底缝合成了一个"集群"。咱们来检验一下那三个"流动哨兵"(VIP 和 SCAN IP)有没有上班!
在 rac1 的 root 终端执行
/u01/app/19.3.0/grid/bin/crsctl stat res -t如果在大段的输出中,你能看到以下内容,并且状态都是 ONLINE,那么恭喜你,最难的一关已经过了!
-
ora.rac1.vip... ONLINE -
ora.rac2.vip... ONLINE -
ora.scan1.vip... ONLINE -
ora.CRS.dg... ONLINE
🟢 第五章:ASM 数据盘划分与数据库软件纯二进制安装
本章核心目标:
-
构建数字保险库: 告诉系统,"把那块 200G 的共享硬盘格式化,交给 ASM 管理,专门留给未来的核心业务数据和灾备归档使用。"
-
安装数据库躯壳: 把 3GB 的 Oracle 数据库程序安装到服务器上(强调:这一步只装纯软件,绝对不能在此刻建库)。
5.1 使用 ASMCA 创建 +DATA 磁盘组
普通的 Linux 系统用 fdisk 和 ext4 格式化硬盘,但在 RAC 集群里,为了让两台机器能同时安全地读写数据,硬盘必须完全交给 Oracle 专有的 ASM(自动存储管理)技术来接管。
操作步骤(全程仅在 rac1 节点操作):
-
登录图形化终端:
打开您的 MobaXterm 工具,以
grid用户(请时刻牢记,管底层存储的永远是 grid)SSH 登录rac1(192.168.10.244)。(避坑警告:绝对不能用 root 或 oracle 用户执行此操作!)
-
启动配置向导:
在终端输入以下命令并回车,呼出图形化存储配置界面:
asmca -
图形界面点选流程(保姆级):
-
界面弹出后,左侧导航栏默认处于
Disk Groups(磁盘组)标签下,右侧会显示上一章我们建好的+CRS磁盘组。 -
点击界面正下方的
Create(创建)按钮。 -
在弹出的新建磁盘组窗口中,严格按照以下参数填写:
-
Disk Group Name(磁盘组名称): 键盘输入大写的
DATA(系统稍后会自动在前面加上加号,变成+DATA)。 -
Redundancy(冗余级别): 点击下拉菜单,选择
External(外部冗余)。因为我们的 PVE 虚拟化底层或者客户机房的硬件存储阵列通常已经做过 RAID 保护了,这里不需要 Oracle 再额外消耗 CPU 性能去做软件层面的镜像备份。 -
Select Member Disks(选择成员磁盘):
在下方的空白列表中,寻找我们在第二章用 UDEV 绑定的那块 200G 磁盘(它的 Path 显示应该为
/dev/asm-data1)。在它前面的方框里 打勾。(抢救提示:如果列表是空的什么都没有,不要慌。点击下方的
Change Discovery Path按钮,将路径修改为/dev/asm*,然后点 OK,被隐藏的磁盘就会乖乖现身。)
-
-
-
确认并退出:
-
勾选完毕后,点击右下角的
OK。 -
等待大约十几秒到半分钟,系统会弹窗提示
Disk Group DATA created successfully。 -
点击
OK,然后点击主界面的Exit退出 ASMCA 工具。
至此,业务数据的"数字保险库"搭建完毕!未来所有的数据文件、精容数安要抓取的归档日志,全都会安全地存放在这里。
-
5.2 数据库软件解压(19c 特有巨坑)
核心避坑原理: 在老的 Oracle 11g 时代,安装包可以随便找个 /tmp 临时目录解压,然后通过向导安装到目标路径。但从 18c 和 19c 开始,Oracle 改变了规则:数据库的压缩包必须直接上传并解压到最终的软件运行目录(ORACLE_HOME)里! 如果您还按照老习惯解压错地方,安装过程将直接报废。
操作步骤(全程仅在 rac1 节点操作):
-
切换专属身份:
打开您的 Xftp 或 WinSCP 文件传输工具,使用
oracle用户(管数据库的专属用户)登录rac1服务器。 -
精准上传文件:
找到您电脑上下载好的 3GB 数据库安装包
LINUX.X64_193000_db_home.zip,将其拖拽上传到第三章提前建好的最终家目录中:/u01/app/oracle/product/19.3.0/db_home -
静默解压代码:
回到
rac1的命令行终端里,以oracle用户身份执行以下命令:# 1. 进入最终目标目录 cd /u01/app/oracle/product/19.3.0/db_home # 2. 确认当前路径无误后,执行静默解压 # (必须带 -q 参数,3GB 的包包含无数小文件,不加 -q 会导致终端满屏乱码甚至死机卡死) unzip -q LINUX.X64_193000_db_home.zip(喝口水,根据 PVE 的磁盘 IO 性能,这个解压过程大约需要 3-5 分钟,请耐心等待命令行提示符重新出现。)
5.3 图形化安装 Database 软件(仅装躯壳)
这一步我们只负责把数据库的二进制核心文件安装到系统底层并注册进集群,绝不能在这里直接建库。我们要把建库(配置容灾参数)这个最重要的事情留到下一章单独做。
操作步骤(在 rac1 图形界面执行):
-
启动安装向导:
确保当前终端仍是
oracle用户,且身处刚才解压的目录中 (/u01/app/oracle/product/19.3.0/db_home)。输入以下命令启动安装:./runInstaller -
图形界面点选流程(防错指南):
-
Step 1: Configuration Option(配置选项 - 决定生死的第一步)
极其重要: 必须选择中间的
Set Up Software Only(仅设置软件)。千万别顺手选了第一项去创建数据库!点击Next。 -
Step 2: Database Installation Options(安装类型)
选择第一项
Oracle Real Application Clusters database installation(RAC 集群数据库安装)。点击Next。 -
Step 3: Node Selection(节点选择与打通任督二脉)
-
列表中会列出
rac1和rac2,必须将两个节点前面的勾全部打上。 -
点击下方中间的
SSH Connectivity(SSH 连接性配置)按钮。 -
在弹窗中,输入
oracle用户的统一系统密码(例如ABCD123),点击Setup。 -
系统会在后台自动打通两台机器
oracle用户的免密互信,弹出Successfully established...提示后,点击OK关闭弹窗,然后点击Next。
-
-
Step 4: Database Edition(数据库版本)
默认选择
Enterprise Edition(企业版)。点击Next。 -
Step 5: Installation Location(安装位置)
由于我们是直接在 ORACLE_HOME 里解压运行的,这里系统会自动识别路径并变灰,保持默认即可。点击
Next。 -
Step 6: Operating System Groups(操作系统组赋权)
保持默认。系统会自动为您规划好的
dba,oper,backupdba等组进行对应分配。点击Next。 -
Step 7: Prerequisite Checks(先决条件大考)
安装程序会扫描两台机器的内核参数、内存和 Swap 等。如果在 PVE 环境下出现关于 NTP 或少量物理内存不足的警告(黄色的 Warning),不要纠结,直接勾选右上角的
Ignore All(忽略全部),强制通过。点击Next。 -
Step 8: Summary(汇总页面)
最后扫一眼配置单,确认无误后,点击右上角的
Install(安装)按钮,进度条开始在两台节点间同步文件!
-
-
关键动作:双节点执行 Root 脚本
当进度条走到大约 80% 到 90% 之间时,图形向导会突然弹出一个对话框让你暂停! 它要求你在两台服务器上以最高管理员
root权限去执行最终的注册脚本。-
重新打开两个干净的黑窗口终端,分别以
root用户登录rac1和rac2。 -
先去
rac1的 root 终端,复制对话框里提供的路径并执行:/u01/app/oracle/product/19.3.0/db_home/root.sh -
等
rac1跑完(出现 Finished 字样),再去rac2的 root 终端执行相同的命令:/u01/app/oracle/product/19.3.0/db_home/root.sh -
确保两台机器都顺利执行完毕后,切回到图形界面的那个暂停对话框,点击上面的
OK。
-
-
完美收官:
向导会自动跑完最后一点进度。当您看到绿色打勾图标和一行字:
The installation of Oracle Database was successful,点击Close。
至此,RAC 集群数据库的"物理躯体"已经完美部署在两台服务器上了!下一步,我们将开启第六章,通过 DBCA 为这具躯体注入真正的灵魂,并开启守护业务安全的"归档"防线。
🟢 第六章:DBCA 集群建库与容灾特性开启
本章核心目标:
在集群之上实例化 RAC 数据库,配置统一的业务入口(PDB),并强制开启归档模式,为灾备演练筑牢最后一道防线。
6.1 启动 DBCA (Database Configuration Assistant)
操作步骤(全程仅在 rac1 节点操作):
-
确认身份: 确保您当前使用的是
oracle用户。 -
启动向导: 在 MobaXterm 图形终端中,直接输入以下命令并回车:
dbca(等待几秒钟,带有 Oracle Logo 的建库向导界面将会弹出。)
6.2 容灾底座终极参数点选(每一项都关乎生死)
在这个界面按错一个按钮,可能导致整个灾备底座变回普通的单机库。请严格照抄以下保姆级配置:
-
Database Operation(数据库操作):
选择第一项
Create a database(创建数据库)。点击Next。 -
Creation Mode(创建模式 - 极其关键):
必须选择
Advanced configuration(高级配置)。默认的"典型配置"是个黑盒,无法满足我们对 RAC 集群和精容数安容灾对接的精细化要求。点击Next。 -
Deployment Type(部署类型 - 确认双机身份):
-
Database Type: 点击下拉菜单,选择
Oracle Real Application Clusters (RAC) database。 -
Configuration Type: 选择
Admin-Managed(管理员管理)。 -
Node Selection(节点选择): 看向下方的节点列表,必须将
rac1和rac2前面的勾全部打上! (如果不勾,建出来的就是个跑在集群里的单机库,毫无高可用可言)。点击Next。
-
-
Database Identification(数据库标识 - 决定业务连什么名字):
-
Global database name(全局数据库名): 填入您规划好的名字,统一使用
orcl。 -
SID Prefix(实例前缀): 填入
orcl。 -
容器化架构(19c 特性): 勾选
Create as Container database(创建为容器数据库)。 -
选择
Create a Container database with one or more PDBs。 -
PDB name: 填入
pdb(注意:以后所有的业务表、客户数据,以及精容数安的备份目标,都是这个 pdb,而不是外壳 orcl)。点击Next。
-
-
Storage Option(存储选项 - 数据安家):
-
选择下面那一项
Use following for the database storage attributes。 -
Database files storage type: 下拉选择
Automatic Storage Management (ASM)。 -
Database files location: 手动输入或浏览选择我们在第五章建好的大仓库
+DATA。 -
务必勾选
Use Oracle-Managed Files (OMF)(开启 OMF 后,Oracle 会自己管理成百上千个复杂的数据文件路径,这是高级 DBA 强烈推荐的防呆设计)。点击Next。
-
-
Fast Recovery Option(灾备之魂!全书最重要的一步):
这是整个底层为了迎合咱们灾备软件而做的最核心配置。如果这里不开,后续的备份保护方案全盘皆输。
-
勾选第一项
Specify Fast Recovery Area(指定快速恢复区)。 -
Recovery files storage type: 选
ASM。 -
Fast Recovery Area: 填入
+DATA。 -
Fast Recovery Area size: 保持默认(通常向导会分个十几 G,对于 POC 测试演示绰绰有余)。
-
全场最关键的一勾:务必勾选下方绿色的
Enable archiving(开启归档模式)。它相当于数据库的"全天候行车记录仪",记录数据库的每一次微小变更。咱们的备份软件要实现"增量抓取"和"秒级任意时间点找回",全靠它提供底层支持!点击Next。
-
-
Network Configuration(网络配置):
列表里会显示默认的集群监听器(在装 Grid 时已经自动建好了),保持默认勾选即可。点击
Next。 -
Configuration Options(配置选项 - 包含 4 个核心标签页):
-
Memory(内存)标签: 选择
Automatic Shared Memory Management(ASMM)。把内存分配权交给 Oracle 自己。 -
Sizing(容量)标签: 保持默认的 block size。
-
Character sets(字符集)标签(极其重要):
选择第一项
Use Unicode (AL32UTF8)。现代业务系统(特别是包含大量中文生僻字或对接 AI 数据的系统)必须用 UTF8。选错这个,存进去的中文全变成???乱码,神仙难救。 -
Connection mode(连接模式)标签: 保持默认的 Dedicated server mode。点击
Next。
-
-
Management Options(管理选项 - 性能瘦身):
-
取消勾选
Configure Enterprise Manager (EM) database express。 -
取消勾选
Run Cluster Verification Utility (CVU) checks periodically。(实战经验:EM 是个极度消耗服务器内存的网页版管理工具,我们的核心是演示容灾备份和秒级切换,关掉这些华而不实的功能,把宝贵的 CPU 和内存全留给数据库和备份进程!) 点击
Next。
-
-
User Credentials(用户凭证 - 统一密码):
选择第二项
Use the same administrative password for all accounts(所有超级管理员使用统一密码)。输入您的统一密码,例如
ABCD123。(此时如果弹窗警告提示"密码太短不符合标准",不要慌,直接无视它,点击
Yes强行继续) 。点击Next。 -
Creation Option(创建选项):
默认勾选了
Create database。不需要存模板,直接点击右下角的Next。 -
Prerequisite Checks(考前大核查):
系统会自动对两台服务器的各项指标做最后的扫瞄。只要没有红色的 Error 阻拦,看到黄色的 Warning 警告,直接勾选右上角的
Ignore All(忽略全部)。 -
Summary(终极确认清单):
这是临门一脚的发射台!请在这个页面最后扫视一遍:
-
Node List: 是否包含
rac1,rac2两个节点? -
Database Files Storage Type: 是否显示
ASM? -
Data Files: 路径是不是都在
+DATA下面? -
Archive Log Mode: 是不是显示
ARCHIVELOG?如果确认无误,深吸一口气,点击右下角的
Finish!
-
6.3 见证奇迹:进度条合龙
点击 Finish 后,进度条开始慢慢推进。在 PVE 虚拟化双机环境下,向导要在两台服务器之间同步海量数据、格式化表空间并拉起所有的集群服务进程,这个过程通常需要 20 到 40 分钟。
期间请去泡杯茶,保持网络畅通,绝对不要去动 PVE 的宿主机,更不要强行中断终端。
当屏幕上弹出一个白色窗口,赫然写着 Database creation complete (数据库创建完成)时,宣告您的 19c RAC 灾备安全屏障底层建筑正式封顶!点击 Close 关闭向导。
6.4 终极排雷与防线验收(实战交付标准)
建库完成后,很多实施人员会兴奋地敲击 sqlplus,结果迎面撞上经典的 ORA-12162: TNS:net service name is incorrectly specified 报错。这是因为你的 Linux 终端当前还处在"失忆状态",不知道该去连两个节点里的哪一个实例。
1. 补齐最后一块短板(环境变量声明):
在 rac1 终端,oracle 用户下执行:
# 告诉 Linux,我当前所在的 rac1 节点,对应的实例名是 orcl1
export ORACLE_SID=orcl1(为了避免以后每次登录都要敲,建议执行 echo "export ORACLE_SID=orcl1" >> ~/.bash_profile。去 rac2 节点也要做同样的操作,但 SID 要改成 orcl2)
2. 交付级验收报告(请在客户或领导面前执行这两组命令):
第一项:检查集群防线(验证 RAC 双活高可用)
srvctl status database -d orcl✔️ 完美的输出应为:
Instance orcl1 is running on node rac1
Instance orcl2 is running on node rac2
第二项:检查灾备底座(验证精容数安接管条件)
sqlplus / as sysdba进入 SQL> 提示符后,输入:
archive log list;✔️ 完美的输出应为:
Database log mode Archive Mode
Automatic archival Enabled
Archive destination USE_DB_RECOVERY_FILE_DEST
(解说词:看到 Archive Mode 这两个字,意味着数据库的时光机已经开启。无论是物理机房断电,还是操作员删库跑路,咱们的容灾软件都能通过这份底座,将数据精准恢复到事故发生前的那一秒!)