目录
[二、Claude Code 介绍](#二、Claude Code 介绍)
[2.1 Claude Code 是什么](#2.1 Claude Code 是什么)
[2.2 Claude Code 核心特点](#2.2 Claude Code 核心特点)
[2.3 与其他AI编程工具对比](#2.3 与其他AI编程工具对比)
[三、CLAUDE.md 项目记忆文件介绍](#三、CLAUDE.md 项目记忆文件介绍)
[3.1 CLAUDE.md 文件概述](#3.1 CLAUDE.md 文件概述)
[3.1.1 CLAUDE.md 是什么?](#3.1.1 CLAUDE.md 是什么?)
[3.1.2 CLAUDE.md 核心特点](#3.1.2 CLAUDE.md 核心特点)
[3.1.3 CLAUDE.md 核心价值](#3.1.3 CLAUDE.md 核心价值)
[3.2 CLAUDE.md 目录结构说明](#3.2 CLAUDE.md 目录结构说明)
[3.2.1 Claude.md 文件存放目录优先级](#3.2.1 Claude.md 文件存放目录优先级)
[3.3 Claude.md 文件创建](#3.3 Claude.md 文件创建)
[3.3.1 Claude.md 文件创建的几种方式](#3.3.1 Claude.md 文件创建的几种方式)
[3.4 Claude.md 文件项目操作实践](#3.4 Claude.md 文件项目操作实践)
[3.4.1 Claude.md 文件可以存放的内容](#3.4.1 Claude.md 文件可以存放的内容)
[3.4.1.1 必须放的内容(核心价值)](#3.4.1.1 必须放的内容(核心价值))
[3.4.1.2 推荐放的内容(高价值)](#3.4.1.2 推荐放的内容(高价值))
[3.4.2 基于已有项目创建CLAUDE.md](#3.4.2 基于已有项目创建CLAUDE.md)
[3.4.3 基于微服务项目级CLAUDE.md文件使用](#3.4.3 基于微服务项目级CLAUDE.md文件使用)
[3.4.4 记忆加载过程](#3.4.4 记忆加载过程)
[3.4.5 基于规则文件开发接口](#3.4.5 基于规则文件开发接口)
[3.4.6 Claude.md 应用最佳实践](#3.4.6 Claude.md 应用最佳实践)
一、前言
在AI技术日新月异的今天,开发者们正经历着一场前所未有的效率革命。面对日益复杂的开发需求和快速迭代的技术栈,借助AI工具提升开发效率已不再是选择题,而是必选项。在这种情况下,各种AI编程工具纷纷出现,甚至一度让开发者感觉到眼花缭乱。借助AI编程工具,不仅可大幅提升编程效率,对开发者来说,也是一场自我迭代和升级的过程,让开发者自身从一个纯粹的编程人员逐步转型为AI编程全站工程师,从而实现自身更大的价值,本篇将详细介绍近期AI编程中非常火热的Claude Code,以及CLAUDE.md文件规则编写在AI辅助编程中的重要作用。
二、Claude Code 介绍
2.1 Claude Code 是什么
Claude Code是Anthropic推出的本地化AI编程助手,专为开发者设计。它不是一个简单的代码补全工具,而是一个能理解你的项目、执行复杂任务、自动化开发流程的智能编程伙伴。

AI编程之旅始于GitHub Copilot的早期版本。记得当时虽然惊艳于它"自动补全"的能力,但受限于上下文理解深度和代码质量,实际应用中常常是"有点作用,但不多"。随后出现的Cursor、Warp等新一代AI编程工具虽然引起了我的关注,却因种种原因未能深入体验。
2.2 Claude Code 核心特点
Claude Code 具备如下核心特点:
-
技术搭档式协作
-
能读懂整个代码库结构,理解项目架构和业务逻辑
-
主动分析代码依赖关系,提供符合项目规范的代码建议
-
根据项目上下文智能推断开发意图,减少重复沟通
-
-
CLI交互方式
-
通过自然语言描述需求(如"修复这个bug"、"重构这段代码")
-
支持复杂任务分解,自动执行多步骤操作
-
提供实时反馈,让开发过程透明可控
-
-
深度集成开发流程
-
不仅能写代码,还能管理Git版本控制
-
调用本地工具链,执行构建、测试等任务
-
根据你的代码习惯和项目规范优化输出
-
2.3 与其他AI编程工具对比
下表汇总了市面上几款主流的AI编程工具,从多个维度对他们各自的特点进行了对比
|-----------|------------------|--------------------|---------------|
| 特性 | Claude Code | GitHub Copilot | Cursor |
| 项目理解深度 | 能分析整个代码库,理 解项目架构 | 能分析整个代码库,理 解项目架构 | 有限的项目理解能力 |
| 有限的项目理解能力 | 可直接执行任务,端到 端自动化 | 仅提供代码建议,需手动采纳 | 半自动化,需要更多人介入 |
| 模型优化 | 原厂优化,稳定性高,响应快速 | 第三方集成,性能依赖网络 | 第三方集成,稳定性一般 |
| 本地化支持 | 完全本地化,数据安全 性高 | 云端服务,有数据隐私顾虑 | 混合模式,部分功能依赖云端 |
三、CLAUDE.md 项目记忆文件介绍
3.1 CLAUDE.md 文件概述
3.1.1 CLAUDE.md 是什么?
CLAUDE.md 是 Claude Code 的"项目记忆文件",记录项目结构、构建命令、代码规范、架构决策等信息,让 Claude Code 快速理解项目上下文。
简单来说,claude.md是Claude Code的持久化记忆配置文件,本质是一个普通的Markdown文件,却能在每次启动Claude Code会话时,自动被加载到AI的上下文里,相当于给AI提前"灌输"项目信息和规则,不用你反复叮嘱。
举个直观的例子:如果把Claude Code比作一位临时加入你团队的工程师,claude.md就是你给他的「项目手册」------里面写清了项目技术栈、编码规范、工作流要求,他一看就懂,不用你花半小时反复讲解背景,上手就能配合干活。
3.1.2 CLAUDE.md 核心特点
CLAUDE.md 是 Claude Code 的项目知识库文件,其具备以下特点:
-
持久化存储:记录项目相关信息,长期有效
-
自动读取:Claude Code 自动加载,无需重复解释
-
团队共享:整个团队可以共享同一份配置
-
持续演进:随项目发展不断更新
3.1.3 CLAUDE.md 核心价值
CLAUDE.md 是一个为 Claude 代码助手(或类似 AI 编程助手)提供项目上下文和指导的配置文件。
其核心价值包括:
1、提供项目上下文
-
快速告知 AI 项目的技术栈(语言、框架、依赖)
-
说明项目结构和模块组织方式
-
明确关键文件和目录的用途
2、规范AI行为
-
定义代码风格和命名约定
-
指定测试命令、构建流程、运行方式
-
设置响应格式偏好(如简洁或详细)
3、提高协作效率
-
减少重复性的背景说明
-
避免 AI 产生不符合项目规范的代码
-
保持代码生成的一致性
4、知识沉淀
-
记录项目的特殊约定或架构决策
-
保存常见的开发工作流
-
传递团队的最佳实践
5、节省 Token 成本
-
避免每次对话都要重新说明项目背景
-
精准的指令减少试错和纠正次数
3.2 CLAUDE.md 目录结构说明
很多人反馈说Claude.md用起来没有方向,核心是没搞懂它应该存放的位置和优先级规则
- Claude.md放在不同位置,作用范围不同,冲突时也有明确的覆盖逻辑,记住这两点,就能避免90%的配置踩坑
3.2.1 Claude.md 文件存放目录优先级
bash
┌─────────────────────────────────────────────────────────────────┐
│ 文件位置层级 │
│ │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 最高优先级: 特定规则 │ │
│ │ 位置: .claude/rules/*.md │ │
│ │ 说明: 针对特定模块或功能的详细规则 │ │
│ └───────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 第二优先级: 模块级配置 │ │
│ │ 位置: src/.claude/CLAUDE.md │ │
│ │ 说明: 针对特定模块的配置 │ │
│ └───────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 第三优先级: 项目配置 │ │
│ │ 位置: CLAUDE.md (项目根目录) │ │
│ │ 说明: 全局项目配置 │ │
│ └───────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 最低优先级: 用户级配置 │ │
│ │ 位置: ~/.claude/CLAUDE.md │ │
│ │ 说明: 用户个人偏好设置 │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘1)各优先级使用场景
通过上面的目录结构不难看出,Claude.md支持4个层级的存放位置,覆盖个人到企业不同场景,新手建议从项目级和用户级入手:
-
企业级:
- 仅企业账号可用,路径随系统不同(如macOS:/Library/Application Support/ClaudeCode/CLAUDE.md),作用于企业内所有用户,用于统一企业级编码策略和安全规范。
-
项目级:
- 放在项目根目录(路径:./CLAUDE.md),仅对当前项目生效,是最常用的位置。适合存放项目专属的技术栈、团队规范、项目架构等内容,建议纳入Git版本控制,方便团队共享。
-
用户级:
- 放在用户主目录(路径:~/.claude/CLAUDE.md),作用于个人所有项目,适合存放跨项目通用的个人偏好,比如缩进规则、引号使用习惯、常用快捷指令等。
2)优先级规则
如果多个位置都存在Claude.md文件时,AI会按「优先级从高到低」加载,冲突内容通常以高优先级为准,规则其实很简单,记好下面这个顺序即可:
企业级 > 项目级 > 用户级
举个实际例子理解:
你在用户级claude.md中配置了"代码使用单引号",但当前项目的项目级claude.md中配置了"代码使用双引号",那么在这个项目中,AI会优先遵循"双引号"规则------项目级覆盖用户级。
**小tips:**如果担心规则冲突,可以在claude.md中用emoji标记重点规则,AI会优先识别这类明确指引,提升规则命中率。
2、Claude.md 目录结构示例
bash
project/
├── CLAUDE.md # 项目根目录配置
├── src/
│ ├── .claude/
│ │ └── CLAUDE.md # 模块级配置
│ └── components/
├── .claude/
│ └── rules/
│ ├── auth.md # 认证相关规则
│ ├── database.md # 数据库相关规则
│ └── api.md # API 设计规范
└── docs/
└── CLAUDE.md # 文档模块配置3.3 Claude.md 文件创建
基于上面的描述,创建 Claude.md可以手动按照上面的目录结构创建,也可以自动生成,通常比较推荐的实践方式是:
- 自动生成,人工再根据生成的文件,结合经验和项目实际情况进行微调优化
3.3.1 Claude.md 文件创建的几种方式
下面介绍几种Claude.md 文件的创建方式,不用手动从零编写,这3种方式能快速搞定,建议新手优先考虑选择前两种:
-
自动生成:
- 在项目根目录启动Claude Code,输入「/init」命令,AI会自动分析项目结构、依赖和关键文件,生成初始的claude.md,后续只需人工修改完善即可
-
手动创建:
- 进入对应目录(项目根目录或用户主目录),通过命令「touch CLAUDE.md」创建文件,再写入基础规则(比如技术栈、编码规范等)
-
快速添加:
- 在Claude Code对话中,输入以「#」开头的内容(比如「# 所有代码需遵循PEP8规范」),选择"存入claude.md",即可快速将规则添加到对应文件中;也可输入「/memory」命令,直接在编辑器中编辑claude.md。
3.4 Claude.md 文件项目操作实践
通过上面的介绍后,我们知道了Claude.md的作用,目录结构,以及创建的方式,接下来通过几个实际案例操作演示下如何创建并使用Claude.md 文件。
3.4.1 Claude.md 文件可以存放的内容
Claude.md文件中可以存放多种类型的文件,比如项目技术栈,编码规范,构建命令等,从大的分类上讲,可以分为两类:必须放的内容,推荐放的内容
3.4.1.1 必须放的内容(核心价值)
1、技术栈声明
存放项目中的核心技术栈内容
- 作用:让AI知道可用的库和API,避免建议不兼容的技术
bash
## Tech Stack
- Java 21 + Spring Boot 3.3.x
- Maven 3.9+ (use wrapper)
- PostgreSQL 16 + Redis 7
- Kafka 3.x for messaging
- Testcontainers + JUnit 52、项目结构
作用:让AI能准确找到和创建文件
bash
## Project Structure
- `src/main/java/com/example/domain/` - 核心业务逻辑
- `src/main/java/com/example/api/` - REST controllers
- `src/main/resources/db/migration/` - Flyway脚本
- `src/test/java/` - 单元测试和集成测试3、构建和运行命令
作用:AI知道如何执行测试、构建等操作
bash
## Common Commands
- Build: `./mvnw clean package`
- Run: `./mvnw spring-boot:run -Dspring-boot.run.profiles=dev`
- Test: `./mvnw test`
- DB migration: `./mvnw flyway:migrate`4、关键约定(禁止事项)
作用:防止AI产生不符合规范的代码
bash
## CRITICAL RULES
- NEVER use `@Autowired` on fields - use constructor injection
- NEVER catch `Exception` without logging
- NEVER use `eager` fetching in JPA
- NEVER hardcode credentials5、架构决策记录
作用:AI理解设计意图,做出一致的扩展
bash
## Architecture Decisions (ADRs)
- Outbox pattern for reliable event publishing
- CQRS for order querying (separate read/write models)
- Circuit breaker for all external HTTP calls3.4.1.2 推荐放的内容(高价值)
这部分的内容,是对上述必须放的内容的补充
1、常用模式和代码示例
作用,让AI编写代码的时候提供参考
bash
## Code Patterns
### Repository Pattern
```java
public interface OrderRepository extends JpaRepository<Order, Long> {
Optional<Order> findByOrderNumber(String orderNumber);
}2、DTO Mapping
Use MapStruct: @Mapper(componentModel = "spring")
- 作用:AI能给出正确的配置建议
bash
**作用**:示范正确写法,减少纠正次数。
### 7. 环境配置说明
```markdown
## Environment Setup
- Dev: `application-dev.yml` (local Postgres, Redis)
- Staging: Kubernetes namespace `staging`
- Prod: Requires approval for deployment
## Required Environment Variables
- `DB_PASSWORD` - PostgreSQL password
- `KAFKA_BOOTSTRAP_SERVERS` - Kafka brokers3、测试策略
作用:AI生成的测试符合项目标准
bash
## Testing Guidelines
- Unit tests: Mock all dependencies
- Integration tests: Use `@Testcontainers` for real DB
- E2E tests: Run with `-Pe2e` profile
- Target coverage: 80% (use JaCoCo)4、依赖和版本约束
作用:避免版本冲突,避免AI 生成代码的时候另起一套
bash
## Version Constraints
- Spring Boot: 3.3.x ONLY (not 3.2.x or 3.4.x)
- Java: 21 LTS only
- Jackson: 2.17+ (for Java 21 records support)
- Avoid: Lombok, Apache Commons Lang 2.x5、重要文件位置
作用:快速定位关键配置
bash
## Key Files Reference
| Purpose | Location |
|---------|----------|
| Main config | `src/main/resources/application.yml` |
| Security rules | `SecurityConfig.java` |
| Error handling | `GlobalExceptionHandler.java` |
| API docs | `openapi.yaml` (generated) |3.4.2 基于已有项目创建CLAUDE.md
进入本地某个项目目录中,进入Claude 交互式命令行窗口中,使用 /init 命令让AI生成一个初始化的CLAUDE.md文件
然后,AI会对当前的项目进行完整的拆解、分析
生成完成后,在项目的根目录下,生成了左侧的CLAUDE.md文件,该文件中主要包含了下面的核心内容:
-
构建命令
-
项目的基础设施
-
核心业务微服务模块
-
服务之间通讯方式
-
项目规范
-
关键技术栈和技术选型
-
..
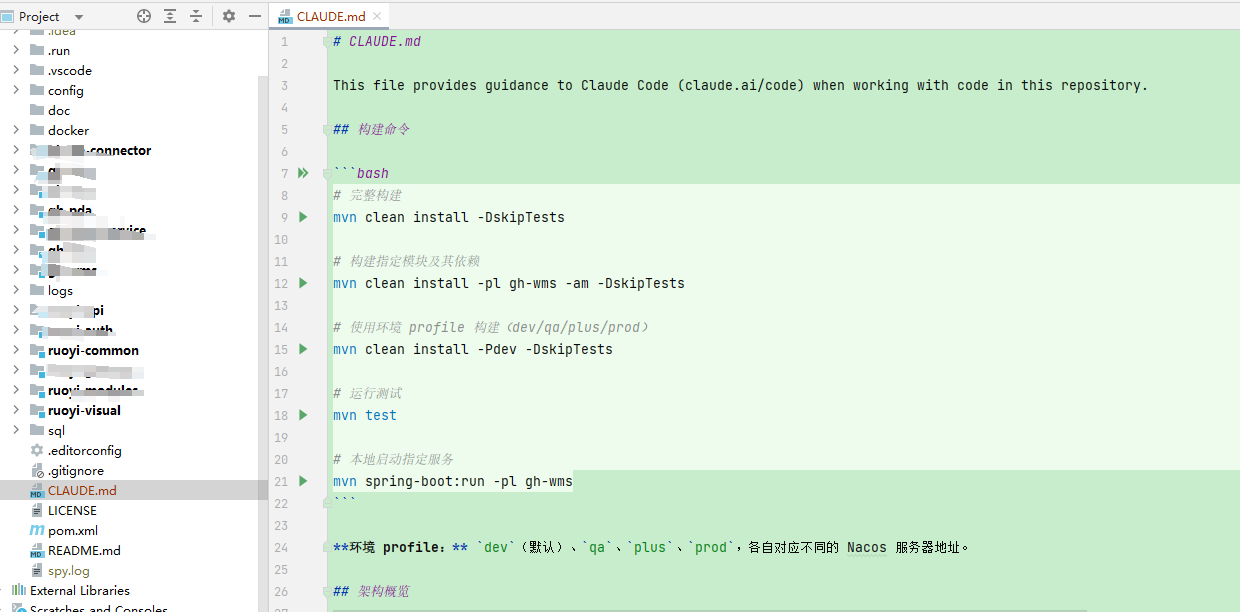
结合前面的描述,该文件属于*项目根目录配置 文件,*属于全局配置文件,全局生效
3.4.3 基于微服务项目级CLAUDE.md文件使用
更多情况下,在实际的开发实践中,不同的微服务项目都有属于项目级的规则,比如开发规范、构建标准、技术栈等,一个项目级的CLAUDE.md文件目录结构如下:
java
your-java-microservice/
├── CLAUDE.md # 主配置文件(80-150行)
├── .claude/
│ ├── rules/ # 模块化规则
│ │ ├── testing.md # 测试规范(条件加载)
│ │ ├── api-design.md # API设计规范
│ │ ├── database.md # 数据库操作规范
│ │ └── security.md # 安全规范
│ └── commands/ # 自定义命令
│ ├── test.md
│ └── build.md
└── agent_docs/ # 详细文档(可选)
├── architecture-guide.md
└── deployment.md仍然基于上述的项目,与Claude Code 共创这几个文件,按照上面的目录结构,依次生成这些文件
1)生成项目级的CLAUDE.md文件
输入下面的提示词

有了这个文件后,不管是新进入团队的人,还是其他人想快速了解项目时,看这个文件就能了解
- 如果初始化的CLAUDE.md文件中仍然有一些不尽人意,或者需要继续补充的地方,直接在对应的位置加进去即可
2)生成项目级下面的其他规则文件
按照上述的项目级的目录结构,我们再依次生成其他的项目规则文件,参考下面的提示词
bash
在当前工程的 ./claude/rules 目录下,依次生成api-design.md(API接口设计规范),database.md(数据库操作规范),testing.md(测试规范),作为后续团队对该项目的开发规范,生成后,接下来我将与你持续共创并完善这些文件内容
最后,几个文件按照规范要求生成,并放在指定的目录下
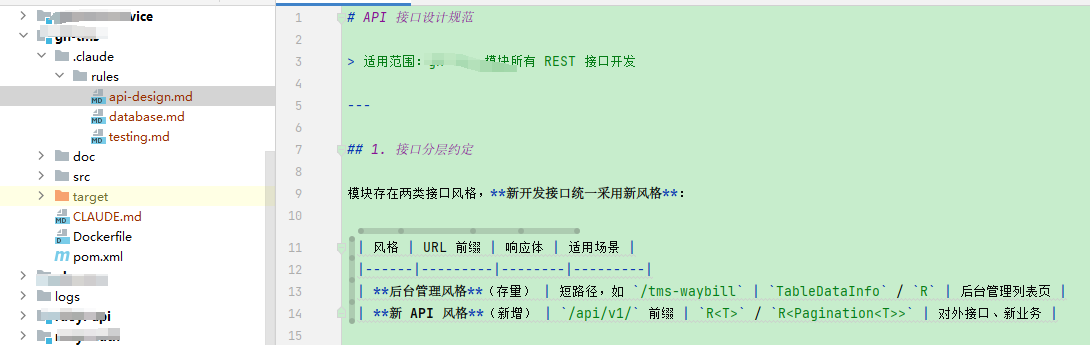
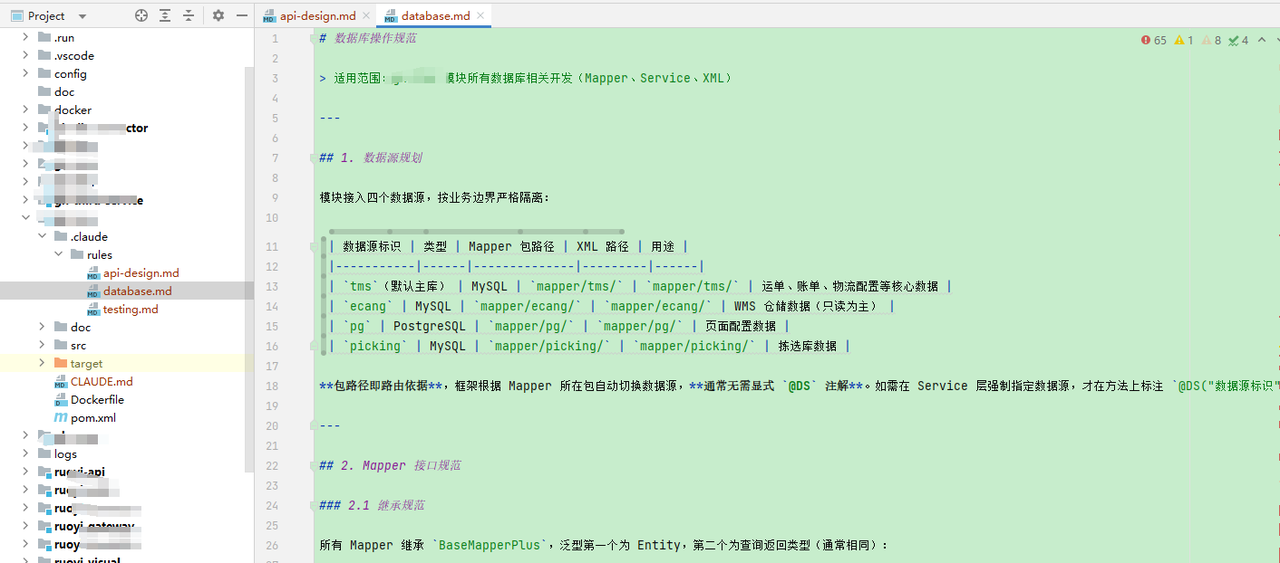
3.4.4 记忆加载过程
CLAUDE.md 文件生成后,你不需要做任何"额外操作"来"激活"它 ------ Claude Code 会自动读取并应用。但知道如何与它交互、如何利用它的能力,才能真正发挥价值。
一、立即验证:确认配置生效
在开始使用前,先确认 CLAUDE.md 已被正确加载。 启动 Claude Code 并检查状态:
bash
# 在项目根目录启动 Claude Code
cd your-java-microservice
claude基于上面已经生成了 CLAUDE.md 文件的情况下,先退出并重新开启会话,启动后,Claude 会自动读取 CLAUDE.md。可以通过以下命令验证:
bash
> /status # 查看当前会话状态和配置
> /context # 查看上下文窗口占用,确认 CLAUDE.md 已加载在项目的根目录下,下面的检查加载的是全局的那一个CLAUDE.md文件
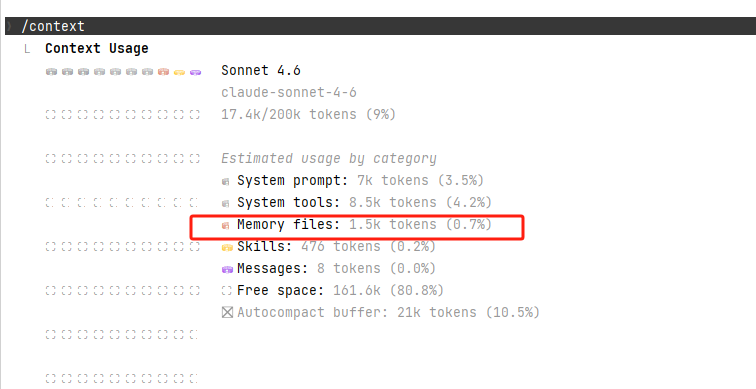


如果是项目级的话,还需进入到项目目录下,如下,进入到具体的项目目录下之后,再次查看:
- 通过输出的日志信息不难发现,进入到项目目录后,又把前文中项目下的几个md文件自动加载到上下文记忆中
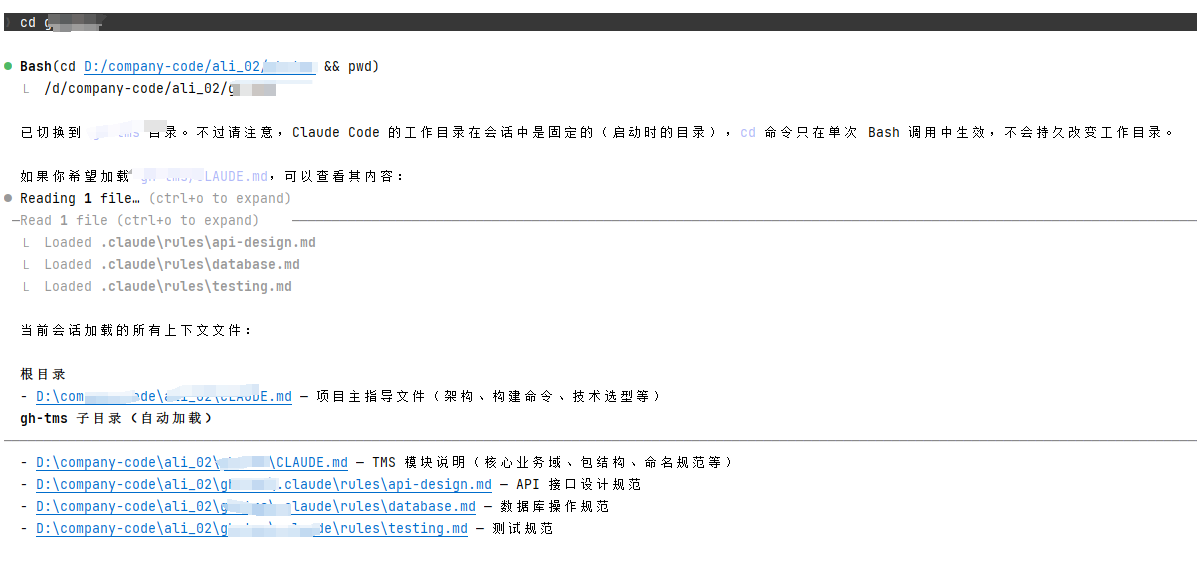
3.4.5 基于规则文件开发接口
上面几步总结下来就是,编写规则,完善规则,将规则加载到claude 的记忆,这些可以理解为前置的步骤,或者准备,这些准备都是为接下来实际项目开发做参考使用的,即通过这些文件来规范AI编写代码应该遵守的边界,下面我们提一个明确的需求,让AI为我们生成一个接口,最后检查AI生成的接口是否符合预期的要求,需求提示词如下:
bash
参考 @doc\api-develop-standard.md 规范,在TmsWaybillController 新增一个查询订单表的接口,支持多参数查询,比如订单号,创建时间,客户编号我这里明确要求AI 编写接口的时候需要参考我提前指定好的API编写规范文件,确保生成的接口与当前的接口规范是一致的
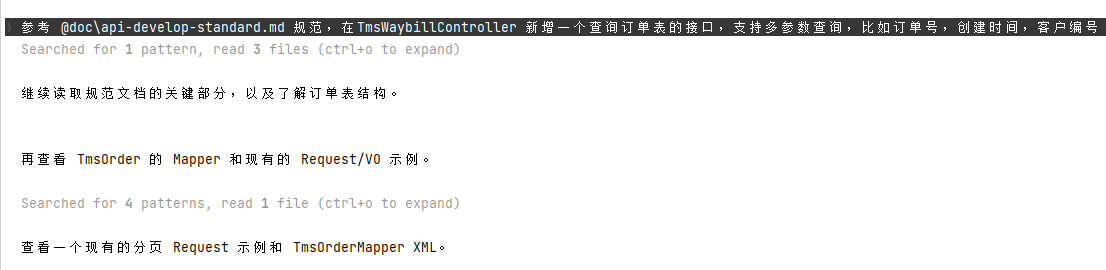
接口效果如下,生成的代码基本是按照当前项目的规范,参考了上面创建的CLAUDE.md文件的同时,也遵循了引用的接口编写规范文件
bash
/**
* 分页查询订单表
*/
@PostMapping("/order/list")
@Operation(summary = "分页查询订单列表", description = "支持按订单号、客户编号、创建时间范围查询")
public R<Pagination<TmsOrderVO>> orderList(@RequestBody TmsOrderPageRequest request) {
return R.ok(tmsOrderService.listByPage(request));
}
@Override
public Pagination<TmsOrderVO> listByPage(TmsOrderPageRequest request) {
Page<TmsOrder> page = PageHelper.startPage(request.getPageNum(), request.getPageSize());
List<TmsOrder> list = tmsOrderMapper.listByPage(request);
List<TmsOrderVO> voList = list.stream().map(order -> {
TmsOrderVO vo = new TmsOrderVO();
BeanUtils.copyProperties(order, vo);
return vo;
}).collect(Collectors.toList());
return new Pagination<>(request.getPageNum(), request.getPageSize(), page.getTotal(), voList);
}3.4.6 Claude.md 应用最佳实践
Claude.md 配置的核心原则是:「精简、精准、分层」不用写多余的说明,只放AI每次会话都需要用到的信息,否则会消耗过多Token,反而降低AI的遵从度。结合一线实操经验,以下总结了几个个最佳实践,可以直接套用。
1)按层级拆分内容,不重复、不冗余
这是最关键的原则。不同层级的Claude.md各司其职,发挥不同的作用,为避免重复维护,具体分工可以参考这个决策树:
-
用户级(~/.claude/CLAUDE.md):
- 放「通用、跨项目」的内容,比如个人编码风格(缩进2空格、行尾必须加冒号)、常用操作(提交前运行npm test)、通用安全规则(禁止硬编码敏感信息)
-
项目级(项目根目录/CLAUDE.md):
- 放「项目专属」的内容,比如项目技术栈(React 18 + TypeScript)、项目结构(/src/components为UI组件目录)、团队编码规范(组件命名用PascalCase)、构建命令(npm run build)
2)控制文件长度,避免Token浪费
Claude Code 上下文Token有限,因此Claude.md 并非越长越好,建议遵循这个下面这个长度标准:
-
单文件最佳长度:
- 100-200行,最多不超过300行,超过这个范围,AI的规则遵从度会明显下降
-
内容精简技巧:
- 只写"指令性内容",删除多余的说明(比如"以下规则是团队讨论决定的");复杂规则可通过「@path/to/file.md」语法导入其他文件,拆分维护,最大递归深度为5层
3)用「What-Why-How」结构组织内容
清晰内容结构能让AI更容易识别规则,建议按"What -Why -How"的逻辑组织内容,比如:
-
What(是什么):
- 项目技术栈、目录结构、核心架构(比如"前端用React 18 + Zustand,后端用Node.js")
-
Why(为什么):
- 项目目的、设计原则、约束条件(比如"项目需兼容IE11,避免使用ES6+新特性")
-
How(怎么做):
- 构建命令、测试方法、开发流程(比如"运行npm run dev启动本地服务,提交前需运行npm lint")
4)精准配置paths,减少无效加载
如果项目是多语言、多模块,可在Claude.md 文件开头用paths元数据限定规则的生效范围,避免无关内容加载消耗Token,如下示例:
- 这样一来,只有操作Python文件时,这部分规则才会被加载,操作其他类型文件(如.js)时不会生效,大幅提升Token使用效率。
bash
---
paths: "**/*.java" # 仅对Java文件生效
---
# Java 专属规则
1. 必须遵循本项目中 /doc/ap-dev-rule.md 的接口编写规范
2. 变量命名采用驼峰命名
3. 严格遵守MVC的编写规范5)团队协作必做:纳入Git版本控制
如果是团队项目,项目级Claude.md 一定要纳入Git版本控制,确保所有的团队成员都能使用统一的规则,避免AI生成的代码风格不一致;而用户级claude.md属于个人偏好,不建议纳入Git,避免冲突。
bash
修改Claude.md后无需重启Claude Code,保存后会自动加载生效
若未生效,输入「/restart」命令重启会话即可。6)避开3个常见坑
下面几个坑在实际使用中需要避免:
-
规则冲突,优先级搞混
- 记住"项目级覆盖用户级",冲突时优先检查项目级claude.md的规则,避免模糊表述(比如同时写"可用单引号"和"可用双引号");
-
内容过于冗余,写了任务特定的规则(比如"实现登录功能用JWT")
- 这类内容无需写进claude.md,仅保留"所有会话都需要的通用规则",否则AI会将其视为噪音,忽略整个文件
-
规则过多不拆分
- 如果规则超过20条,建议改用「.claude/rules/」文件夹分类管理,比单文件claude.md更易维护,且加载更精准
四、写在文末
本文通过较大的篇幅详细介绍了Claude Code 中Claude.md 这个非常重要的"记忆文件",其实claude.md的用法并不复杂,核心就是通过"分层配置+精准规则",让Claude Code记住你的偏好、你的项目规范,从而减少重复沟通,提升编码效率。
对于新手来说,先从项目级claude.md入手,用「/init」命令生成初始文件,再补充项目技术栈和编码规范;熟悉后再配置用户级claude.md,统一个人编码习惯;多项目维护时,用好分层规则,就能轻松搞定AI编码的"默契感"。
最后提醒:claude.md不是"一劳永逸"的,建议定期用「/memory」命令检查、更新规则,删除过期内容,让AI始终保持"精准记忆"。