Enterprise RAG Challenge 冠军方案深度拆解:研报级学习笔记
方案来源 : Ilya Rice --- How I Won the Enterprise RAG Challenge | 开源代码
成绩 : 两个奖项类别均第一 + SotA榜首 | 核心模型: GPT-4o-mini (Reranking) + o3-mini (Answering)
引言
plain
=== 输入输出梳理 ===
输入: 100份企业年报PDF(每份最多1000页)+ 100道自动生成的问答题
输出: 每题一个简洁答案(int/float/bool/str/list[str])+ 证据页码引用
=== 核心难点识别 ===
难点1: PDF解析的"信息无损"问题
- 旋转90°的大表格、Caesar cipher编码文本、多列混排、图片+文字混合图表
- Engineering Trick: Docling + DoclingParseV2Backend + EasyOCR兜底 + 正则表达式批量清洗
特别精妙:检测到cipher编码的文档整个走OCR路径
难点2: 大表格语义检索失效
- 表头与数据距离太远(1500 tokens隔开),embedding相似度大幅下降
- Engineering Trick: 表格序列化(HTML→LLM→attribute-value pair),但最终发现反而有害(加噪),
最终winning config中 use_serialized_tables=False ← 这是反直觉的重要发现!
难点3: 多公司DB的检索空间爆炸
- 100个公司混在一起,答案永远只在单个公司的报告里
- Engineering Trick: per-company FAISS索引 + 正则表达式公司名路由,搜索空间缩小100倍
难点4: LLM认知容量有限,规则越多越容易忘
- 4种答案类型各有3-6个特殊规则(货币、千位/百万单位、括号负数、N/A条件)
- Engineering Trick: 按answer type路由到4套独立prompt,而非把所有规则塞进一个prompt
难点5: LLM幻觉页码引用
- LLM会引用它"想象"出来的页码,不在检索结果里
- Engineering Trick: _validate_page_references()后处理,把不在retrieval_results里的页码全部剔除
难点6: 2.5小时时间窗口,100份×最多1000页文档
- Engineering Trick:
1) RunPod 4090 GPU加速Docling解析(40分钟搞定15000页)
2) ThreadPoolExecutor并行处理questions(25个并行,2分钟答完100题)
3) LLM Reranking batch:3页一批给GPT-4o-mini,既省钱(<$0.01/题)又提速
=== 最反直觉的发现 ===
- 表格序列化(精心设计的大工程)最终hurt而非help,因为Docling已经解析得够好了
- 加更多文本=加噪,反而降低检索信噪比
- 小模型 Llama 8b + 这套pipeline 胜过80%参赛者!说明pipeline工程比模型选择更重要项目全局视角
业务痛点与赛题设定
这不是一个普通的 RAG 问答题------它是一个极端压力测试:
| 约束条件 | 具体数值 | 工程挑战 |
|---|---|---|
| 文档规模 | 100份PDF,每份最多1000页 | 15,000页总量,2.5小时内解析完 |
| 答案格式 | int/float/bool/str/list[str] 5种严格类型 |
不能含单位、不能含注释、货币必须匹配 |
| 证据要求 | 每答案必须附页码引用 | 反幻觉的硬性约束 |
| 时间窗口 | 原始规则要求100题10分钟内 | 强制并行化设计 |
该方案的"胜负手"
不是某个单一的魔法技术,而是五层协同效应的叠加:
- Docling定制解析 → 信息无损的Markdown+HTML输出
- Per-Company独立FAISS索引 → 检索空间缩小100倍
- Parent Document Retrieval → 小块定位+全页上下文的最优平衡
- LLM Reranking(GPT-4o-mini) → 将向量检索的0.3权重与LLM语义判断0.7权重加权融合
- 三路路由 + CoT Structured Output → 消除规则混乱,强制推理链
多模态数据摄入与解析 (Data Ingestion & Parsing)
What: Docling + DoclingParseV2Backend
python
# src/pdf_parsing.py 核心配置
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
ocr_options = EasyOcrOptions(lang=['en'], force_full_page_ocr=False) # 按需OCR
pipeline_options.ocr_options = ocr_options
pipeline_options.do_table_structure = True # 表格结构识别
# TableFormerMode = ACCURATE 模式(代码后段)Why: 为什么选Docling而不是其他方案
作者测试了约20款解析器,包括:
- 商业API(Adobe PDF Services等)
- 传统解析库(pdfplumber, PyMuPDF)
- ML增强解析器(Unstructured.io等)
Docling的核心优势(IBM开发,这也是赛事组织者之一的产品):
- 原生支持GPU加速(NVIDIA 4090 上40分钟处理15000页)
- **TableFormer模型:**专门训练的表格结构识别,输出同时包含Markdown和HTML两种格式
- 可以输出包含完整元数据的JSON(位置、页码、类型标注)
How: 解析管道的四个阶段
plain
PDF
│
▼
[Docling DoclingParseV2Backend]
│ → JSON(含元数据:page, block_type, table_id)
│ → HTML格式表格(关键!)
▼
[parsed_reports_merging.py - PageTextPreparation]
│ → 复杂JSON → 简化的 {pages: [{page: N, text: "...markdown..."}]} 结构
▼
[正则表达式批量清洗]
│ → 修复font encoding问题(Caesar cipher文档 → 整体走OCR路径)
│ → 清理PDF解析artifact
▼
[text_splitter.py - TextSplitter]
│ → RecursiveCharacterTextSplitter(Langchain)
│ → chunk_size=300 tokens, chunk_overlap=50 tokens
└─ → 每chunk保留 {page: N, text: "...", id: K, type: "content"}| 工具 | 角色 | 备注 |
|---|---|---|
| Docling (IBM) | 主力 PDF 解析器 | 支持 GPU 加速,RTX 4090 解析 100 份报告仅 40 分钟 |
| OCR 回退 | 处理 Caesar 密码字体编码异常文档 | 用 regex 检测后整页走 OCR |
| 自定义 Regex 批处理 | 清洗解析噪声(错误语法、页眉页脚残余) | 约 12 条正则规则 |
关于Caesar Cipher的工程处理------这是最精彩的细节之一:
某些PDF字体编码破损,视觉上看文字正常,但程序提取出来是乱码。作者发现这是「每个词的ASCII码按不同偏移量位移」的**变体Caesar cipher(可能是打印厂的字体库Bug)。解码后仍有大量Artifact,因此对这类文档采用 整体强制OCR**策略而非尝试解码。**通过 regex 识别后直接 OCR 全页,是一个务实的工程 Fallback**。
正则清洗的工程哲学:用一批正则(文中提到"dozen正则")批量处理解析Artifact,而不是个案处理------这是生产系统的正确思路。
切块策略 (Chunking) 的精髓:小块检索 + 大块阅读
这是整个架构中最优雅的设计权衡:
| 策略 | chunk_size | chunk_overlap | 检索精度 | 答题上下文 |
|---|---|---|---|---|
| 纯页级别(朴素) | ~2000 tokens | 0 | 低(语义稀释) | 充足 |
| 纯小块(极端) | 100 tokens | 0 | 高 | 不足 |
| 本方案(两段式) | 300 tokens检索 | 50 tokens | 高 | 全页(Parent Retrieval) |
核心insight :chunk是指针 ,不是内容 。找到chunk后,用chunk.page查到完整页面文本,把整页喂给LLM。
python
# src/text_splitter.py
def _split_page(self, page, chunk_size=300, chunk_overlap=50):
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-4o", # 使用gpt-4o的tokenizer计数
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
chunks = text_splitter.split_text(page['text'])
# 每个chunk携带其所在的page编号 ← 这是Parent Retrieval的关键
return [{"page": page['page'], "text": chunk, ...} for chunk in chunks]- 每个 Chunk 保存
page元数据作为父页指针 - 检索时找到精准 Chunk → 通过元数据回溯完整页面送入上下文(Parent Document Retrieval)
- 这是 Small-to-Big Retrieval 模式的典型工程实现
表格序列化的「美丽失败」
表格序列化的设计逻辑极为精妙:将大表格转换为独立的语义完整字符串:
plain
原始大表:
| 指标\年份 | 2019 | 2020 | 2021 | 2022 |
| 股东权益 | 637 | 535 | 577 | 1274 | (单位:百万日元)
序列化后:
subject_core_entity: Shareholders' equity
information_block: Shareholders' equity for years 2019-2022:
¥637,422M (2019/3), ¥535,422M (2020/3), ¥577,782M (2021/3), ¥1,274,570M (2022/3)但最终 use_serialized_tables=False 是winning config!
原因分析:
- Docling的TableFormer已经把表格解析得足够好
- 序列化后额外增加的文本 = 增加噪声 = 降低信噪比
- 对于300-token的小块检索,多余文本会「稀释」相关chunk的向量相似度分数
工程教训:不要先入为主地认为"更多处理=更好结果"。A/B测试胜过直觉。
检索与召回引擎 (Retrieval & Reranking)
架构设计:Per-Company独立FAISS索引
python
# src/ingestion.py - VectorDBIngestor
def _create_vector_db(self, embeddings):
embeddings_array = np.array(embeddings, dtype=np.float32)
dimension = len(embeddings[0])
index = faiss.IndexFlatIP(dimension) # IP = Inner Product = 余弦相似度
index.add(embeddings_array)
return index**Why ****IndexFlatIP**而不是IndexIVFFlat/HNSW?
| 索引类型 | 搜索方式 | 精度 | 速度 | 适用规模 |
|---|---|---|---|---|
IndexFlatIP |
全量暴力搜索 | 100%精确 | 慢(线性) | <10万向量 |
IndexIVFFlat |
近似最近邻(分桶) | 略有损失 | 快 | >10万向量 |
IndexHNSW |
图近邻近似 | 略有损失 | 最快 | >100万向量 |
每个公司的报告平均约150页×每页约6个chunk = ~900个向量/公司。这个规模下暴力搜索几乎是瞬时的,选FlatIP是正确的。
Per-Company独立索引的核心优势:
- 搜索空间从
100公司 × 900向量 = 90,000缩小到900向量/次(缩小100倍) - 完全消除跨公司信息混淆的可能性
- 路由错误 = 答案必错,但路由逻辑极简(正则匹配公司名)
嵌入模型选择:text-embedding-3-large
OpenAI的text-embedding-3-large,维度3072,在MTEB榜单上表现优秀。选择它的pragmatic理由:
- 比开源模型更稳定的API(竞赛中不希望管理本地服务)
- 与FAISS无缝集成
- 批量嵌入:每批最多1024个文本(代码中的
text_chunks = [text[i:i+1024]...])
LLM Reranking:整个方案的核心胜负手
这是最精妙的设计,完整实现在src/reranking.py:
python
# src/reranking.py - LLMReranker.rerank_documents()
def rerank_documents(self, query, documents, documents_batch_size=4, llm_weight=0.7):
# 将documents分成每批documents_batch_size个
doc_batches = [documents[i:i+documents_batch_size]
for i in range(0, len(documents), documents_batch_size)]
vector_weight = 1 - llm_weight # 0.3
def process_batch(batch):
texts = [doc['text'] for doc in batch]
# 一次API调用评估整批文档 ← 这是降本增效的关键
rankings = self.get_rank_for_multiple_blocks(query, texts)
results = []
for doc, rank in zip(batch, rankings['block_rankings']):
doc_with_score = doc.copy()
doc_with_score["combined_score"] = round(
llm_weight * rank["relevance_score"] + # 0.7 * LLM评分
vector_weight * doc['distance'], # 0.3 * 向量余弦相似度
4
)
results.append(doc_with_score)
return results
# 并行处理所有批次
with ThreadPoolExecutor() as executor:
batch_results = list(executor.map(process_batch, doc_batches))
all_results.sort(key=lambda x: x["combined_score"], reverse=True)
return all_results完整的Reranking流程(实际winning config参数):
plain
查询向量化
↓
FAISS检索 Top-30 chunks(llm_reranking_sample_size=30)
↓
Parent Document Retrieval:chunks → 对应完整页面(去重)
↓
LLM Reranker(GPT-4o-mini,batch_size=2,即每次2页)
└→ combined_score = 0.7×LLM_relevance + 0.3×cosine_similarity
↓
取Top-10页面(top_n_retrieval=10)
↓
拼接为RAG上下文字符串,送入Answering LLMReranking的**Structured Output Schema**(精华):
python
# src/prompts.py
class RetrievalRankingSingleBlock(BaseModel):
"""Rank retrieved text block relevance to a query."""
reasoning: str = Field(
description="Analysis of the block, identifying key information and how it relates to the query"
)
relevance_score: float = Field(
description="Relevance score from 0 to 1, where 0 is Completely Irrelevant and 1 is Perfectly Relevant"
)Relevance Score的11档精确定义(0.0, 0.1, 0.2 ... 1.0)让模型有清晰的"锚点",而**reasoning**字段强制模型在打分前先推理(CoT效果)。
批量评分(Multiple Blocks)的妙处:
- 同一批次的多个块互相参照,模型能给出相对一致的分数(比单独评分更稳定)
- 一次API调用处理2-3个文档,成本约是单独调用的1/2
成本核算:
- Reranking成本:每题 < $0.01(GPT-4o-mini)
- 相比把整个1000页文档全部过LLM(约$0.25/题),节省25倍成本
BM25的存在与选择性使用
python
# src/ingestion.py - BM25Ingestor
class BM25Ingestor:
def create_bm25_index(self, chunks):
tokenized_chunks = [chunk.split() for chunk in chunks] # 简单空格分词
return BM25Okapi(tokenized_chunks)BM25(Best Match 25)作为补充实现了,但最终winning config没有用它 (use_bm25_db=False)。
**作者的结论:BM25在这个场景中"往往降低了检索质量"。作者发现简单合并 Dense+Sparse 在本任务上不稳定,有时反而降低质量 ------这与业界常见认知相符:****Hybrid Search 需要精细调优。**原因分析:
- 问题是自然语言问句,与文档中的专业财务术语的词汇overlap较低
- 简单空格分词没有stemming/lemmatization,匹配能力弱
- LLM Reranking已经能弥补纯向量检索的不足,BM25多此一举
Agent编排与防幻觉
三路路由机制
这是整个方案中架构最优雅的部分:
路由1:数据库路由(DB Router)
python
# src/questions_processing.py - QuestionsProcessor._extract_companies_from_subset()
def _extract_companies_from_subset(self, question_text):
company_names = sorted(self.companies_df['company_name'].unique(),
key=len, reverse=True) # 长名字优先匹配,防止子串问题
found_companies = []
for company in company_names:
escaped_company = re.escape(company)
pattern = rf'{escaped_company}(?:\W|$)'
if re.search(pattern, question_text, re.IGNORECASE):
found_companies.append(company)
question_text = re.sub(pattern, '', question_text, flags=re.IGNORECASE)
return found_companiesWhy不用LLM做公司名提取?
- 赛题规则保证公司名总是明确出现在问题中
- 正则匹配比LLM快100倍,成本为零
- 确定性输出,不会幻觉出不存在的公司名
实现的关键细节:
- 按名字长度降序排列,先匹配长名字(防止"Apple"匹配到"Apple Inc."中的子串)
- 匹配后将该名字从问题文本中删除,防止重复匹配
路由2:Prompt路由(Schema Router)
python
# src/api_requests.py 中的路由逻辑(基于kind字段)
PROMPT_MAP = {
"number": AnswerWithRAGContextNumberPrompt,
"name": AnswerWithRAGContextNamePrompt,
"names": AnswerWithRAGContextNamesPrompt,
"boolean": AnswerWithRAGContextBooleanPrompt,
"comparative": ComparativeAnswerPrompt
}
# 根据 question["kind"] 选择对应Prompt类四套独立Prompt的设计哲学:LLM的认知资源是有限的。**把所有类型的规则塞进一个prompt,模型会"顾此失彼"。**独立化后:
numberprompt:专注货币匹配、千位/百万换算、括号负数、精确匹配(不允许计算推导)nameprompt:专注人名全称提取、N/A判定namesprompt:专注职位名称(单数形式!)、产品名(候选产品不算)booleanprompt:专注"有无"的语义判断
Number Prompt中最硬核的规则(直接看Field描述):
python
# src/prompts.py - AnswerWithRAGContextNumberPrompt.AnswerSchema
final_answer: Union[float, int, Literal['N/A']] = Field(description="""
# 货币不匹配 → N/A
- Return 'N/A' if metric provided is in a different currency than mentioned in the question
# 禁止推导计算 → N/A(防止LLM自作聪明做算术)
- Return 'N/A' if metric is not directly stated in context EVEN IF it could be
calculated from other metrics
# 千位/百万换算的内嵌示例(Few-shot)
- Example for numbers in thousands:
Value from context: 4970,5 (in thousands $)
Final answer: 4970500
# 括号=负数
- Pay attention if value wrapped in parentheses, it means the value is negative
Value from context: (2,124,837) CHF
Final answer: -2124837
""")路由3:复合问题路由(Multi-Query Router)
python
# src/questions_processing.py - process_comparative_question()
def process_comparative_question(self, question, companies, schema):
# Step 1: LLM分解问题
rephrased_questions = self.openai_processor.get_rephrased_questions(
original_question=question,
companies=companies
)
# 例: "Which has higher revenue, Apple or Microsoft?"
# → {"Apple": "What was Apple's revenue?", "Microsoft": "What was Microsoft's revenue?"}
# Step 2: 并行处理每个子问题
with concurrent.futures.ThreadPoolExecutor() as executor:
future_to_company = {
executor.submit(process_company_question, company): company
for company in companies
}
# 各公司的答案并行获取
# Step 3: 汇总后送给ComparativeAnswerPrompt做比较
comparative_answer = self.openai_processor.get_answer_from_rag_context(
question=question,
rag_context=individual_answers, # 传入各公司的独立答案
schema="comparative"
)CoT + Structured Output:防幻觉的核心机制
四字段Schema的设计是精髓:
python
class AnswerSchema(BaseModel):
# 字段1:强制推理(至少5步、至少150词)
step_by_step_analysis: str = Field(
description="Detailed step-by-step analysis... at least 5 steps and at least 150 words."
)
# 字段2:提炼摘要(约50词,便于调试)
reasoning_summary: str = Field(
description="Concise summary of the step-by-step reasoning process. Around 50 words."
)
# 字段3:页码引用(后处理验证)
relevant_pages: List[int] = Field(...)
# 字段4:最终答案(严格类型约束)
final_answer: Union[float, int, Literal['N/A']] = Field(...)CoT 防幻觉的具体指令设计:
- 明确区分"被请求度量"和"类似但不完全相同的度量"
- 强制分析单位(千/百万)并要求补零(避免量级错误)
- 对括号内数值(负数)、不同货币单位等边缘情况逐一在 Prompt 中标注
CoT的防幻觉机制详解:
Number类型的step_by_step_analysis字段描述中,明确规定了5步推理链:
- 确定问题中指标的精确含义(是什么?)
- 审查上下文中的候选指标(找什么?)
- 仅当指标含义完全匹配才接受(不接受同类但不同含义的指标)
- 拒绝条件:上下文指标比问题指标宽泛/狭窄、需要计算推导、聚合不匹配
- 若有任何疑问,默认返回
N/A
这5步推理链的设计针对性地解决了 最常见的幻觉模式:LLM倾向于"找相似的"而不是"找完全一致的"。
SO Reparser:最后一道防线
python
# src/prompts.py - AnswerSchemaFixPrompt
class AnswerSchemaFixPrompt:
system_prompt = """
You are a JSON formatter.
Your task is to format raw LLM response into a valid JSON object.
Your answer should always start with '{' and end with '}'
Your answer should contain only json string, without any preambles, comments, or triple backticks.
"""
user_prompt = """
Here is the system prompt that defines schema:
"{system_prompt}"
Here is the LLM response that not following the schema:
"{response}"
"""实现逻辑:
schema.model_validate(answer)验证Pydantic schema- 验证失败 → 把原始response + schema定义 → 发给LLM重新格式化
- 对小模型**(Llama 8b)**尤其关键,能将schema合规率从~50%提升到100%
页码引用的后处理防幻觉
python
# src/questions_processing.py - _validate_page_references()
def _validate_page_references(self, claimed_pages, retrieval_results, min_pages=2, max_pages=8):
retrieved_pages = [result['page'] for result in retrieval_results]
# 剔除LLM"发明"的页码
validated_pages = [page for page in claimed_pages if page in retrieved_pages]
if len(validated_pages) < len(claimed_pages):
removed = set(claimed_pages) - set(validated_pages)
print(f"Warning: Removed {len(removed)} hallucinated page references: {removed}")
# 如果有效引用太少,从检索结果中补充
if len(validated_pages) < min_pages and retrieval_results:
for result in retrieval_results:
if result['page'] not in set(validated_pages):
validated_pages.append(result['page'])
if len(validated_pages) >= min_pages:
break
return validated_pages[:max_pages] # 最多8页这个后处理函数优雅地解决了:**"LLM说答案在第42页,但第42页根本没有在检索结果里"**这个经典幻觉场景。
大白话费曼类比
类比一:整个RAG系统 = 图书馆考试助手
想象你是一个公司年报图书馆的管理员,有100个独立的书架,每个书架对应一家公司(Per-Company FAISS索引)。
同学来问:"苹果公司2022年的总资产是多少?"
第一步(DB路由):你听到"苹果公司",立刻走到苹果公司那个书架(而不是搜索100个书架)。
第二步(向量检索):你把问题转换成一张"需求卡片"(embedding向量),然后用卡片在书架上快速扫描,找出30张"长得最像"的卡片对应的书页(Top-30 chunks)。
第三步(Parent Document Retrieval):你找到的是书签,不是书页。用书签找到对应的完整书页------因为回答问题需要读整页,不是读只言片语。
第四步(LLM Reranking):你请一个聪明的助手(GPT-4o-mini)快速浏览这30页,给每页打0-1分:"这页能回答这个问题吗?"助手每次看2-3页,并发打分(ThreadPoolExecutor)。
第五步(CoT回答):把评分最高的10页交给主考官(o3-mini),他必须按5步推理流程作答:先确认问题问的是什么,再找证据,再验证匹配,再给出答案,绝不允许猜测。
第六步(防幻觉):主考官报告"答案在第78页",你检查书签里确实有第78页------如果没有,把这个幻觉页码划掉。
类比二:LLM Reranking = 招聘的二轮面试制度
你要从1000名简历中(所有chunks)选出最匹配岗位(问题)的员工。
第一轮(向量检索,海选):HR用关键词搜索系统快速筛出30份简历(向量余弦相似度)。这一步快但不精准------可能漏掉表述方式不同的好候选人,也会混入"表面匹配"的差候选人。
第二轮(LLM Reranking,精选):部门主管(GPT-4o-mini)亲自读这30份简历,给每份打1-10分并写评语(reasoning字段)。这一步慢但精准。
最终录用(Combined Score):最终得分 = 主管评分×0.7 + 系统匹配分×0.3。主管的判断权重更高,但不完全丢弃系统筛选的信息。
批量面试(batch_size=2-3):主管每次同时读2-3份简历,横向对比后打分------比一份份单独读更一致,更省时。每批花费<$0.01。
可直接"抄作业"的神级工程Trick
Trick 1:Prompt类型路由 + Pydantic Schema自描述
这是代码最值得复用的设计模式------Prompt即文档,Schema即规则:
python
# 可复用的Prompt路由框架(仿写,加满注释)
from pydantic import BaseModel, Field
from typing import Union, Literal, List
import inspect, re
class NumberAnswerPrompt:
"""数值类问题的Prompt,包含所有防幻觉规则"""
instruction = """
You are a RAG answering system. Answer ONLY based on provided context.
Before answering, think step by step with at least 5 steps.
"""
class Schema(BaseModel):
step_by_step_analysis: str = Field(
description="5-step analysis. Step1: what exactly does the metric mean? "
"Step2: find candidates in context. Step3: strict match check. "
"Step4: reject if ambiguous. Step5: conclude."
)
reasoning_summary: str = Field(description="50-word summary for debugging")
# 关键:final_answer的description就是业务规则文档
final_answer: Union[float, int, Literal['N/A']] = Field(description="""
- Numbers in thousands: multiply by 1000 (e.g., '4970 (in thousands)' → 4970000)
- Parentheses = negative: (2,124,837) → -2124837
- Currency mismatch → N/A
- Cannot be calculated → N/A (must be directly stated)
- Not in context → N/A
""")
# 动态从Schema类源码生成pydantic_schema字符串(作者的巧妙做法)
pydantic_schema = re.sub(r"^ {4}", "", inspect.getsource(Schema), flags=re.MULTILINE)
# 路由字典:简洁、可扩展
PROMPT_ROUTER = {
"number": NumberAnswerPrompt,
"boolean": BoolAnswerPrompt,
"name": NameAnswerPrompt,
}
def route_and_answer(question_kind: str, context: str, question: str):
prompt_cls = PROMPT_ROUTER[question_kind]
# 使用 llm.beta.chat.completions.parse() 获得结构化输出
response = llm.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": prompt_cls.instruction},
{"role": "user", "content": f"Context: {context}\nQuestion: {question}"}
],
response_format=prompt_cls.Schema # 自动强制JSON格式
)
return response.choices[0].message.parsedTrick 2:LLM Reranker + 加权融合(可即插即用)
python
# 可直接复用的LLM Reranker核心逻辑
from pydantic import BaseModel, Field
from openai import OpenAI
from concurrent.futures import ThreadPoolExecutor
from typing import List, Dict
class BlockRanking(BaseModel):
reasoning: str = Field(description="Why this block is or isn't relevant")
relevance_score: float = Field(description="0=irrelevant, 1=perfectly answers the query")
class BatchRanking(BaseModel):
block_rankings: List[BlockRanking]
def llm_rerank(
query: str,
documents: List[Dict], # [{"text": "...", "distance": 0.85, ...}]
llm_weight: float = 0.7,
batch_size: int = 3,
top_n: int = 10
) -> List[Dict]:
"""
核心算法:
combined_score = llm_weight × llm_relevance + (1-llm_weight) × cosine_similarity
"""
client = OpenAI()
vector_weight = 1 - llm_weight
def score_batch(batch: List[Dict]) -> List[Dict]:
# 将多个文档格式化为带编号的块
blocks = "\n\n---\n\n".join(
[f"Block {i+1}:\n\"\"\"\n{doc['text']}\n\"\"\"" for i, doc in enumerate(batch)]
)
user_msg = f'Query: "{query}"\n\nBlocks:\n{blocks}\nProvide exactly {len(batch)} rankings.'
# Structured Output保证JSON格式正确
completion = client.beta.chat.completions.parse(
model="gpt-4o-mini",
temperature=0,
messages=[
{"role": "system", "content": "Rate each block's relevance to the query (0-1)."},
{"role": "user", "content": user_msg}
],
response_format=BatchRanking
)
rankings = completion.choices[0].message.parsed.block_rankings
results = []
for doc, rank in zip(batch, rankings):
scored = doc.copy()
scored["llm_score"] = rank.relevance_score
# 加权融合:LLM判断 + 向量相似度
scored["combined_score"] = llm_weight * rank.relevance_score + vector_weight * doc["distance"]
results.append(scored)
return results
# 分批并行处理(降低延迟)
batches = [documents[i:i+batch_size] for i in range(0, len(documents), batch_size)]
with ThreadPoolExecutor() as executor:
all_results = [item for batch_result in executor.map(score_batch, batches) for item in batch_result]
return sorted(all_results, key=lambda x: x["combined_score"], reverse=True)[:top_n]Trick 3:页码引用幻觉过滤器(防幻觉后处理)
python
def validate_page_references(
claimed_pages: List[int],
retrieval_results: List[Dict],
min_pages: int = 2,
max_pages: int = 8
) -> List[int]:
"""
三步防幻觉:
1. 剔除LLM凭空捏造的页码
2. 如果有效页码不足min_pages,从检索结果中补充
3. 限制最多max_pages,防止堆砌
"""
retrieved_page_set = {r['page'] for r in retrieval_results}
# Step 1: 过滤幻觉页码
valid_pages = [p for p in claimed_pages if p in retrieved_page_set]
hallucinated = set(claimed_pages) - set(valid_pages)
if hallucinated:
print(f"⚠️ Hallucinated pages removed: {hallucinated}")
# Step 2: 补充页码(保证最少引用数量,满足竞赛/业务要求)
if len(valid_pages) < min_pages:
existing = set(valid_pages)
for result in retrieval_results:
if result['page'] not in existing:
valid_pages.append(result['page'])
existing.add(result['page'])
if len(valid_pages) >= min_pages:
break
return valid_pages[:max_pages]系统架构流程图
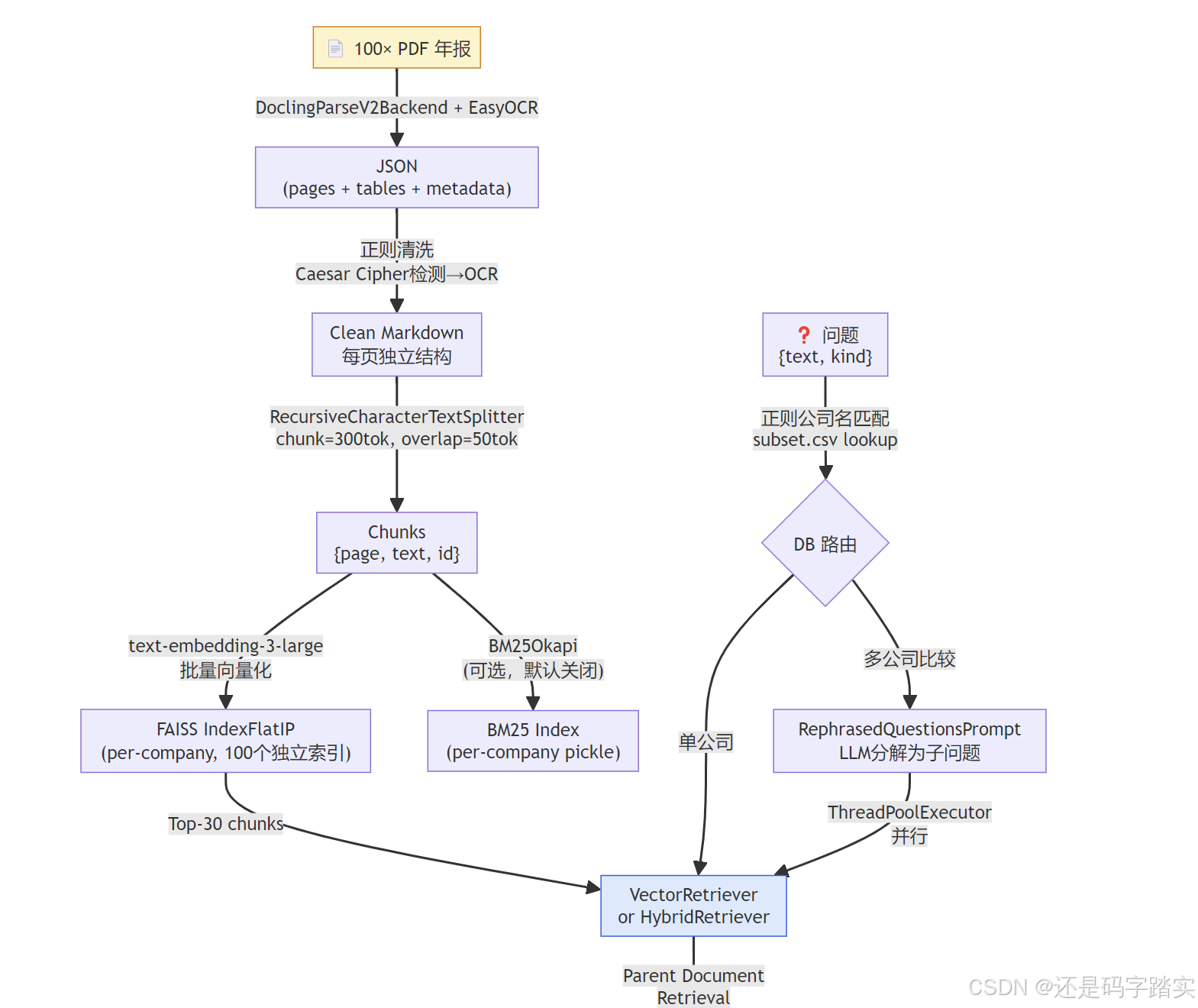
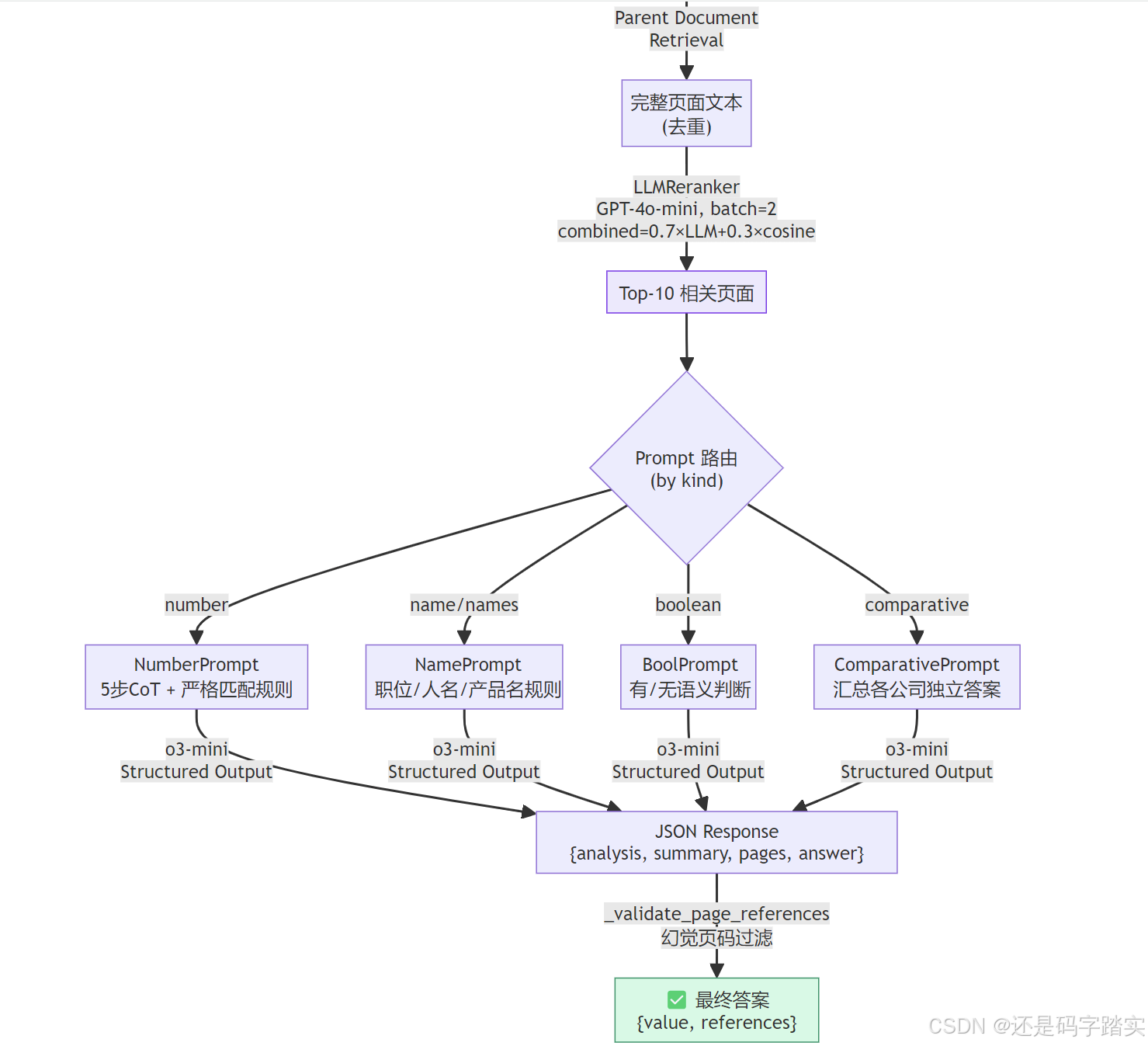
关键配置演进与消融实验总结
作者在pipeline.py中保留了完整的配置演进历史,这本身就是一份教科书级的消融实验记录:
| 配置 | 核心增量特性 | 备注 |
|---|---|---|
base_config |
基础vDB + SO CoT | GPT-4o-mini |
parent_document_retrieval_config |
+ Parent Document Retrieval | GPT-4o |
max_config |
+ 表格序列化 + LLM Reranking | 意外:seq_tab hurt performance |
max_no_ser_tab_config |
去掉表格序列化 | GPT-4o |
max_nst_o3m_config ⭐ |
换用 o3-mini | 最终冠军配置 |
ibm_llama70b_config |
换用开源Llama 70b | IBM WatsonX,与o3-mini仅差几分 |
gemini_thinking_config |
Full Context模式 | 不用检索,直接喂整份报告 |
基座模型
| 版本 | 模型 | 特点 |
|---|---|---|
| 最优配置(v4) | o3-mini-2025-01-31 |
最高分,强推理 |
| 性价比配置(v0) | gpt-4o-mini-2024-07-18 |
成本低,速度快 |
| 开源配置(v6) | <font style="color:#DF2A3F;">Llama-3.3-70b</font>(IBM WatsonX) |
仅比 o3-mini 低几分 |
| 超小模型(v7) | <font style="color:#DF2A3F;">Llama-3.1-8b</font> |
仍超 80% 参赛者 |
| 全文检索配置(v8/9) | Gemini-2.0-flash-thinking |
百万 Token 长上下文,无 RAG 直接塞全文 |
最反直觉的三个实验结论:
- 表格序列化反而有害(花了大量工程投入,最终不用)
- BM25混合检索反而有害(向量检索已经够好)
- Llama 8b + 这套pipeline 胜过80%参赛者(pipeline > model)
可迁移的核心设计原则
"RAG的魔法在细节里" ------ Ilya Rice
- 隔离索引(Isolation First):能per-entity建索引就不要混在一起。搜索空间越小,精度越高,成本越低。
- Chunk是指针,Page是内容(Pointer-Content Separation):用小块找位置,用大块给上下文。这是Parent Document Retrieval的本质。
- 路由胜过堆规则(Route Over Rules):与其把100条规则塞进一个prompt,不如拆成10个专用prompt各管10条。LLM的注意力是有限的稀缺资源。
- 验证闭环(Validation Loop):任何LLM输出都要做后处理验证(页码验证、Pydantic schema验证)。不要盲目信任LLM的格式和引用。
- 成本意识(Cost-Aware Design):LLM Reranking < 0.01/题 vs 全量扫描 0.25/题。好的系统设计天然就是经济的。
- 实验驱动,反直觉的结果才是最宝贵的(Empirical > Intuitive) :表格序列化这个"精心设计的大工程"最终被抛弃。测量胜过猜测。