作者:肯梦
EventHouse 是阿里云 EventBridge 推出的 AI 原生数据平台。本文将深入剖析 EventHouse 的核心能力及其在人工智能时代下的定位,介绍 EventHouse 如何作为 AI 数据底座,帮助企业在瞬息万变的市场中,以前所未有的速度挖掘数据价值,驱动业务增长。
引言:数据平台的消费者,正在从"人"变成"Agent"
2025 年被广泛视为 AI Agent 商业元年。IDC 在其 FutureScape 2026 报告中指出,企业数据平台正在从"以人为中心的查询式访问"转向"以 Agent 为中心的程序化访问"。这意味着,数据的消费者不再只是编写 SQL 的分析师,更是能够自主调用数据、自主执行分析的 AI Agent。
然而,大多数企业的数据基础设施并没有为此做好准备。
事件数据,例如用户行为、交易流转、系统状态、IoT 遥测等,是企业最有价值的实时信息流,但同时也是最容易被浪费的数据资产。事件总线(EventBus)和事件流(EventStreaming)解决了事件的路由与分发,却往往在事件被消费之后画上了句号。后续的存储、治理与深度分析长期处于"各自为政"的状态:数据工程师需要跨多个系统手动拼接数据,ETL 流水线带来了 T+1 的延迟,而 AI Agent 更是无从接入这些散落各处的数据源。
这正是 EventHouse 要解决的问题------为 Agent 提供统一的数据集成桥梁,打造面向 AI 的数据底座。
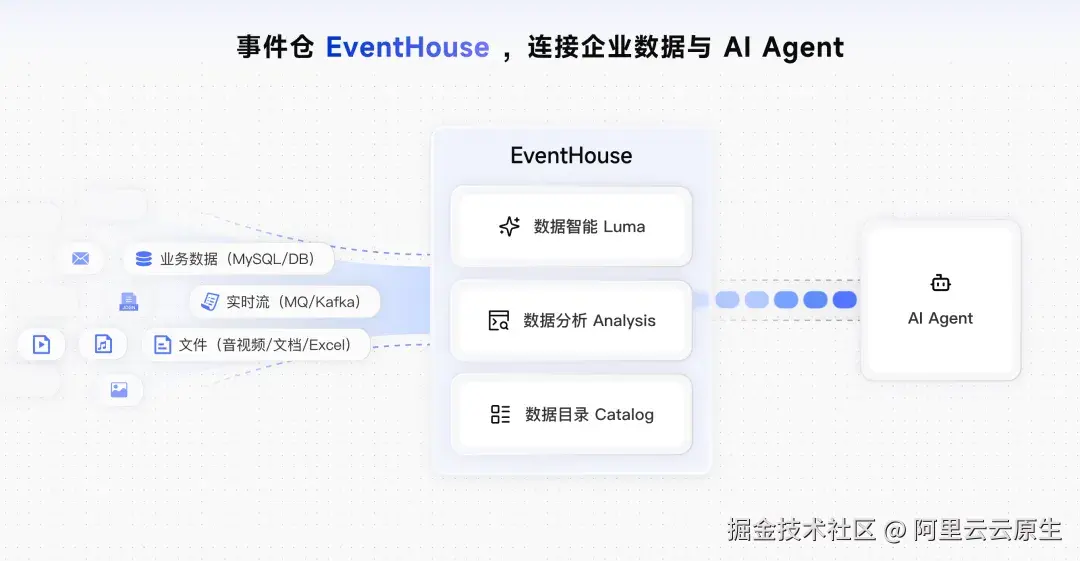
从 EventBus 到 EventHouse:AI 时代的数据基础设施升级
在数字化转型的浪潮中,企业积累了海量的事件数据,这些数据记录了用户行为、系统状态、交易流转等宝贵信息。然而,长期以来,这些数据往往被"束之高阁",成为难以利用的"暗数据"。
传统的事件总线(EventBus)主要解决的是事件的"路由与分发"问题,即确保一个事件能够准确无误地从生产者传递给消费者,但一旦事件被消费,其后续的存储、治理与深度分析便常常被忽视。这种模式导致了数据价值的巨大浪费,也催生了对新一代数据基础设施的需求。
事件仓(EventHouse)正是在这一背景下应运而生,它标志着数据基础设施从单纯的"数据管道",演进为融合存储、治理与智能分析能力的"AI 数据底座"。
一方面,EventHouse 继承了数据湖的开放性和灵活性,能够容纳来自 Kafka、RocketMQ、MySQL 等多种来源的结构化、半结构化乃至非结构化数据;另一方面,它融合了数据仓库的可靠性与高性能,提供 ACID 事务、Schema 管理、权限控制等企业级治理能力。其核心使命是解决事件数据的"存储、治理与智能分析"三大难题,将原本被视为生命周期结束的事件,转变为可供反复挖掘、持续增值的核心资产。
EventHouse 如何搭建 AI-Ready 数据底座?看懂这套分层架构
EventHouse 并非一个孤立的存储引擎,而是一个由多个解耦层组成的完整体系。其架构设计借鉴了业界领先的 DataMesh 和 Lakehouse 思想,旨在构建一个真正面向未来的数据平台。
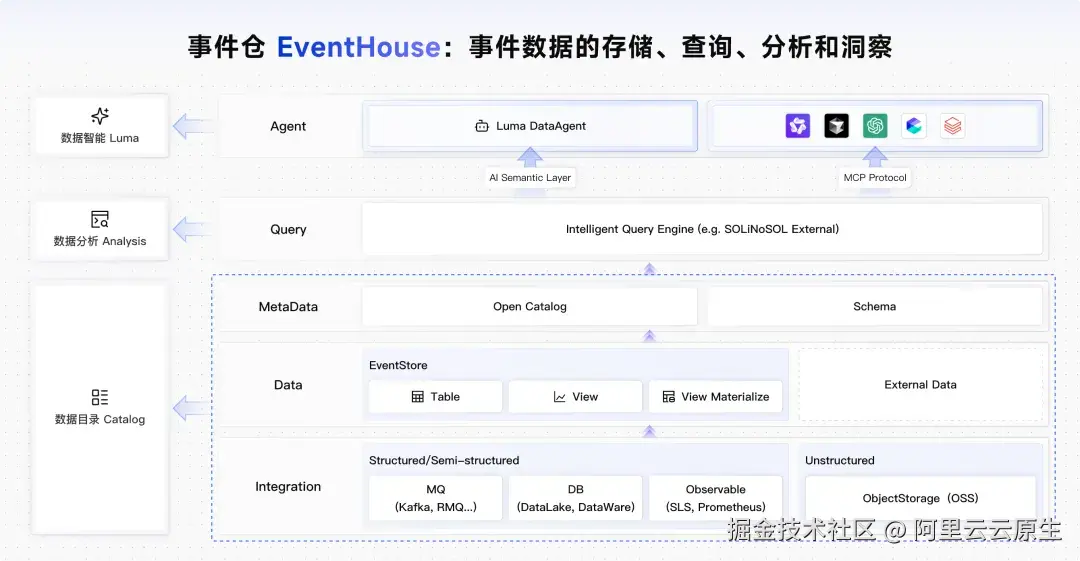
EventHouse 的核心架构采用分层解耦的设计,清晰地分为集成层、数据层、元数据层、数据查询与智能分析层。每一层都由特定的核心组件支撑,共同构成了一个完整的数据处理与分析闭环。同时,每个层级都相对独立,既可拆分使用,也可一站式端到端使用。
1. 集成层:统一接入多源异构数据
集成层是整个系统的入口,它如同一个多功能的"翻译官",能够无缝对接 Kafka、RocketMQ 等多种消息队列,MySQL 等关系型数据库以及对象存储 OSS,实现对全模态数据的统一接入。这确保了无论数据最初以何种形式产生,都能够进入 EventHouse 进行统一处理。
2. 数据层:EventStore,面向事件流的原生存储
数据层的核心是 EventStore,它是一种专门为事件流设计的存储格式。与通用文件存储不同,EventStore 针对 JSON 等事件数据进行了专用的列式压缩,能够显著降低存储成本,据测算,较传统数据库可节省 50% 以上。
更重要的是,它提供了类似关系型数据库的表(Table)、视图(View)甚至物化视图(Materialized View)等抽象,使分析师能够使用熟悉的 SQL 语法进行复杂查询,同时保留数据湖的扩展性。
3. 元数据层:Open Catalog,统一治理的关键枢纽
元数据层是连接异构数据源的桥梁,也是实现统一治理的关键。EventHouse 采用兼容 Hive Metastore Thrift API 标准的 Open Catalog,能够自动发现并注册来自不同源头的数据元信息,例如 Kafka Topic、RDS 表结构等。
当上游数据模式发生变化时,Catalog 还能够管理兼容性的 Schema 演进,避免下游分析任务因模式不匹配而中断。同时,它能自动追踪事件从产生到分析的全链路血缘,极大简化故障排查和影响评估。
4. 数据查询层:Intelligent Query Engine,实现流批一体与 Zero ETL
数据查询层由 Intelligent Query Engine 主导,它解决了传统数仓无法处理高并发实时事件、而传统消息队列又缺乏复杂关联分析能力的根本矛盾。
该引擎最突出的特点是"流批一体"------使用同一种 SQL 语法,既可以查询历史归档数据(批量),也可以查询正在流入的实时事件流(流式),极大降低了用户的使用门槛。
此外,它还支持"零 ETL"(Zero ETL)和联邦查询(Federated Query)(待发布)。用户可以直接在 EventHouse 中通过 SQL JOIN 操作,将内部存储的表与外部数据源(例如 OSS 上的日志文件或另一个 RDS 数据库中的维表)进行联合分析,无需任何数据物理搬迁。
5. 智能分析层:Luma Agent 驱动"对话即分析"与"自主分析"
智能分析层是 EventHouse 最具前瞻性的部分,它通过引入自研的 Luma Agent 和 MCP 协议,将 AI 能力深度融入数据平台。
这一层的目标,是实现"对话即分析",最终迈向"自主分析"。用户不再需要编写复杂的 SQL,也不必等待报表生成,而是可以直接通过自然语言提问,获得即时的回答。
更进一步,内置的 Luma DataAgent 能够像人类专家一样,主动监控数据、发现问题、规划分析路径并执行查询,最终输出带有根因分析和行动建议的完整报告。这标志着数据分析范式的深刻变革:从被动响应转向主动洞察。
综上所述,EventHouse 通过其分层解耦的现代化架构,不仅解决了传统数据平台在处理实时事件流方面的痛点,更前瞻性地布局了 AI 原生能力,致力于打造一个开放、统一且智能的数据底座。它的出现,为企业有效管理和利用海量事件数据,提供了一个全新的、极具吸引力的解决方案。
EventHouse 能为企业解决什么问题?三大核心能力拆解
1. Catalog ------ 让数据"找得到、连得上、信得过"
1.1 要解决的问题
企业的事件数据散布在消息队列、业务数据库、对象存储等各个角落。在分析之前,往往要花费大量时间在"找数据"和"理解数据"上。
1.2 核心能力
EventHouse 构建了一个名为 Catalog 的统一元数据中心,兼容 Apache Hive Metastore Thrift API 标准。当一个新的 Kafka Topic 或 RDS 表被接入时,Open Catalog 自动捕获其 Schema、分区信息和数据类型,将其注册为可查询的逻辑表。数据的可发现性从"天级别"缩短到"秒级别"。
选择兼容 Hive Metastore,而非自研封闭协议,是一个深思熟虑的生态决策。这意味着企业现有的 Spark、Flink、Presto 等计算引擎可以直接对接 EventHouse 的元数据,不存在厂商锁定的风险。
更重要的是,Catalog 不只是数据的"登记处",还是治理的"指挥中心"------它能够自动追踪事件从产生到分析的全链路血缘,管理 Schema 的兼容性演进,确保上游数据模式变化不会中断下游分析任务。
1.3 场景示例
一家电商平台的订单支付事件通过 RocketMQ 实时流入,用户画像数据则存储在 MySQL 中。过去,运营人员需要分别在 MQ 控制台和数据库客户端查询,然后在 Excel 中手动关联。现在,通过 Open Catalog 创建一个 Order_View 虚拟视图,逻辑上将实时支付流与用户表进行关联,所有分析师直接查询这个统一视图即可。底层的元数据映射、数据源连接、权限校验全部由 Catalog 自动完成。
2. Intelligent Query Engine ------ Zero ETL,让分析结果不再是"昨天的天气"
2.1 要解决的问题
传统数仓依赖 ETL 流水线搬运数据,成本高、延迟大;传统消息队列能够处理实时流,却难以完成复杂的关联分析。两套系统、两套语法、两套运维,几乎是大多数企业数据团队的日常。
2.2 核心能力
EventHouse 的 Intelligent Query Engine 正是为解决这一矛盾而构建的。它的核心特性包括:
- 流批一体的统一 SQL:同一套 SQL 语法,既可以查询历史归档数据,也可以查询正在流入的实时事件流,无需维护流处理和批处理两套代码。
- Zero ETL 跨源查询:通过标准 SQL JOIN,将 EventHouse 内部表与外部数据源(如 SLS 日志文件、RDS 维表)直接联合分析,无需任何物理数据搬迁。
- 计算下推优化:在执行跨源查询时,引擎会将过滤条件和计算逻辑下推到数据源端执行,只拉取必要结果集。例如,查询某一天的数据时,引擎会命令外部 MySQL 只返回当天记录,而非全表扫描。这样不仅显著降低网络传输量,也使查询性能更接近本地分析。
- 联邦查询(Federated Query) 能力即将上线,届时将进一步打通跨数据源的实时分析链路。
2.3 场景示例
一家物联网企业需要将设备实时遥测数据流与存储在 RDS 中的设备档案进行 Join,构建设备健康画像。传统方案需要先把遥测数据通过 ETL 导入数仓,延迟至少 T+1。使用 EventHouse 后,运维团队可以直接通过一条 SQL 完成跨源关联,数据可用性从 T+1 提升至准实时,异常设备的发现和响应速度显著提升。
3. Luma Agent + MCP 协议 ------ 从"对话即分析"到"自主分析"
3.1 要解决的问题
即使拥有统一的数据视图和强大的查询引擎,"会写 SQL"仍然是一道门槛。业务人员有问题、有直觉,但缺少直接验证的技术手段。
3.2 核心能力
这是 EventHouse 与传统数据平台拉开本质差距的地方。它通过两条路径,将 AI 能力深度融入数据底座。
- 路径一:AI 语义层(Luma Agent)
大语言模型虽然博学,但它并不理解企业内部的业务字段。当用户问"昨天北京地区支付失败的订单有多少"时,LLM 可能知道要查 order 表,但不知道"支付失败"究竟对应的是 status_code='FAIL',还是 payment_result=false。这种歧义,正是 Text-to-SQL 准确率不高的核心原因。
Luma Agent 的 AI 语义层,解决的正是这个问题。它允许数据治理者在 Catalog 中为每个字段标注业务描述、业务别名和计算逻辑。当用户使用自然语言提问时,Luma 会基于这些语义标注,将用户意图精准映射到正确的数据字段和业务逻辑上。
更进一步,内置的 Luma DataAgent 可以像人类专家一样主动监控数据、发现异常、规划分析路径并执行查询,最终输出包含根因分析和行动建议的完整报告。从"对话即分析",到"自主分析"。
- 路径二:原生 MCP 协议(即将上线)
MCP(Model Context Protocol)正在成为 AI Agent 连接外部工具的事实标准------可以把它理解为 AI Agent 世界的"USB 接口"。自 2025 年以来,LangChain、Dify、Coze 等厂商以及互联网头部企业陆续接入 MCP 生态,增长势头迅猛。
EventHouse 将原生支持 MCP 协议,并将自身的查询能力------流式查询、物化视图分析、告警触发等------全部封装为 MCP Tools。这意味着,任何支持 MCP 协议的 AI Agent 都可以像调用标准 API 一样无缝接入 EventHouse,获取实时事件数据。接入 EventHouse,就是接入整个 AI Agent 数据生态。
3.3 场景示例
一个企业自研的风控 Agent 在检测到异常交易模式后,可自动通过 MCP 协议调用 EventHouse 的查询工具,拉取关联用户的历史行为数据和实时交易流,执行多维关联分析,生成风险评估报告并推送给风控团队。这将大幅减少人工介入环节,让风控响应从"小时级"压缩至"分钟级"。
为什么是现在?Data+AI 一体化,正从趋势变成刚需
Data+AI 平台的一体化趋势,正在从"行业预判"走向"企业刚需"。有几股力量正在同时推动这件事发生:
1. 数据管理市场正从"点工具堆叠"收敛为"统一生态系统"
过去十年,企业为了应对不同的数据问题,通常会采购一套 ETL 工具、一套元数据管理工具、一套数据质量检测工具、一套 BI 平台。最后却发现,仅仅是让这些工具彼此打通和"对话",就要付出与购买它们相当的成本和精力。
行业的共识正在转向:围绕数据网格(Data Fabric)和 AI 驱动的方式,把这些分散能力融合到一个集成化的数据生态系统里。
EventHouse 的 Open Catalog + 查询引擎 + Luma Agent 的一体化设计,本质上就是在事件数据这个垂直领域落地这一理念------端到端地解决数据集成问题。
2. 自然语言正成为数据交互入口,但对数据治理提出更高要求
这听起来有点矛盾:自然语言降低了数据消费的门槛,但如果底层元数据混乱、字段语义不清晰,那么 LLM 生成的 SQL 很可能就是错的,而且你甚至不知道它错在哪里。
Gartner 的判断是,数据质量差和治理不足将导致大量 GenAI 项目停留在概念验证阶段无法上线。
这也是为什么 EventHouse 在推出 Luma Agent 之前,先建设 AI 语义层和 Open Catalog:不是先追求"自然语言查数据"的酷炫体验,而是先夯实语义标注、元数据治理、Schema 演进这些基础设施,让 Text-to-SQL 的准确率真正具备生产可用性。
3. Agentic AI 正在重构软件交互方式,企业数据平台必须提前准备
AI Agent 不只是"自然语言查数"这么简单。它会分解复杂任务、调用多个工具、自主执行端到端的分析流程。这意味着,数据平台必须提供标准化的、可被程序调用的接口,而不只是给人看的仪表盘;同时需要具备足够完善的治理框架,确保 Agent 的自主操作是安全、可控且可审计的。
EventHouse 原生支持 MCP 协议,并在 Open Catalog 内置权限控制与血缘追踪,正是在为 Agentic 的未来做好基础设施准备。
如果你正面临这些挑战,欢迎参与 EventHouse 公测
随着模型能力不断提升,Data Agent 正在走出 POC 阶段,真正进入企业生产环境。数据管理工具从碎片化走向融合,数据消费从"人写 SQL"走向"Agent 自主调用",而连接这两端的关键,正是扎实的数据治理能力。
EventHouse 目前正在公测中。如果你的团队正面临以下挑战,我们期待与你共同探索:
- 实时事件数据积累了海量规模,却无法被高效分析和利用。
- 跨数据源查询依赖复杂的 ETL 流水线,分析结果总是滞后于业务。
- 希望让 AI Agent 直接接入业务数据,实现自主分析和智能决策。
让我们一起定义下一代事件数据平台!
👉 点击此处参与公测
eventbridge.console.aliyun.com/cn-chengdu/... (目前已在成都、杭州地域上线,其他地域将陆续开放)
👥 钉钉交流群:44552972