作者:来自 Elastic Matthew Adams
一种使用 Elasticsearch 和 Jina embeddings 进行无监督文档聚类的实用且可复现的方法。
从向量搜索到强大的 REST APIs,Elasticsearch 为开发者提供了最全面的搜索工具集。深入 Elasticsearch Labs 仓库中的示例 notebooks,尝试一些新内容。你也可以今天就开始免费的试用,或在本地运行 Elasticsearch。
向量搜索通常从一个查询开始,但如果你没有查询怎么办?
组织会积累大量文档集合,例如支持工单、法律文件、新闻流和研究论文,并且在提出正确问题之前,需要先了解这些内容。在没有标签或训练数据的情况下,手动审阅成千上万的文档是不现实的。当你甚至不知道该搜索什么时,传统搜索也无能为力。
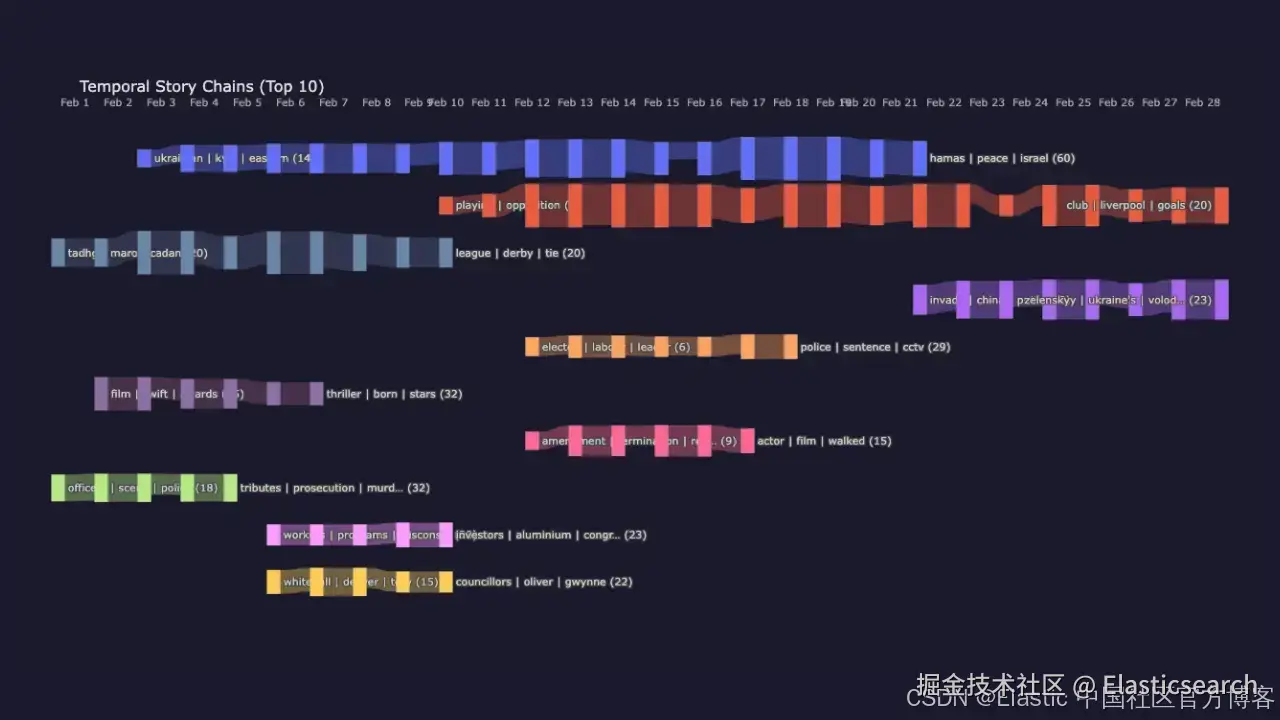
本文介绍了一种基于 Elasticsearch 原生能力的无监督文档聚类与时间序列故事追踪方法,用于解决这一发现问题。通过本文,你可以在多天时间范围内追踪类似这样的事件演化路径:
你将会了解:
- 为什么在没有查询进行主题发现时,使用聚类 embeddings(而不是检索 embeddings)至关重要。
- 如何通过基于密度探测的质心分类(density-probed centroid classification),结合 Elasticsearch 的 k-nearest neighbor (kNN) 和批量 msearch,实现按主题对文档进行分组。
- 如何使用 significant_text 自动为聚类打标签,使主题在无需训练模型的情况下也能被理解。
- 时间序列故事链(temporal story chains)如何连接每日聚类,展示主题如何随时间演化。
本文基于一个可运行的 Jupyter Notebook 生成。文中展示的内联输出均来自该流水线的真实运行结果。你可以克隆配套的 notebook 自行运行。
该流水线使用了约 8,500 篇来自 2025 年 2 月的 BBC News 和 The Guardian 文章作为测试语料。新闻数据具有清晰的时间特征,因此很适合演示,但这种模式适用于任何需要文档发现的场景:法律审查、合规监控、研究综述、客户支持分流。
技术栈:
- Jina v5 聚类 embeddings :用于主题分组的任务专用 Low-Rank Adaptation (LoRA) adapters。Jina 已加入 Elastic,其模型可通过 Elastic Inference Service (EIS) 原生使用。
- Elasticsearch :提供可扩展的 kNN、significant_text 标注以及向量存储能力。
- DiskBBQ:一种基于磁盘的向量索引格式,将 Better Binary Quantization (BBQ) 与分层 k-means 分区结合,用于加速近似最近邻(ANN)。该索引分区属于向量搜索内部机制,与本文使用的基于密度的聚类算法相互独立。bbq_disk 将量化向量存储在磁盘上,仅在堆内存中保留分区元数据,相比 bbq_hnsw 大幅降低资源消耗,同时保持较高召回率。
- 全局聚类 + 每日时间链接:用于发现主题及其演化。
你需要准备:
- 一个 Elasticsearch 部署(Elastic Cloud、Elasticsearch Serverless 或 Elastic Self-Managed 8.18+ / 9.0+):bbq_disk 需要 8.18 或更高版本。可选的 diversify retriever 部分需要 9.3+ 或 serverless。
- 一个 Jina API key:免费额度包含 1000 万 tokens,足以覆盖核心聚类流程(约 425 万 tokens)。可选的检索与聚类对比需要额外一次 embedding 计算。
- 一个 Guardian API key(免费)。
设置
安装所需的 packages:
go
`pip install elasticsearch pandas numpy plotly umap-learn python-dotenv pydantic-settings datasets requests`AI写代码可选(仅当你运行该仓库中的 scraping helpers 时需要):
go
`pip install beautifulsoup4`AI写代码然后在项目根目录的 .env 文件中配置 API keys:
ini
`
1. ELASTIC_CLOUD_ID=your-cloud-id # or ELASTIC_HOST=https://...
2. ELASTIC_API_KEY=your-api-key
3. JINA_API_KEY=your-jina-key
4. GUARDIAN_API_KEY=your-guardian-key
`AI写代码该 notebook 调用了 load_dotenv(override=True),因此本地 .env 的值会优先生效。
css
`Connected to Elasticsearch`AI写代码第 1 部分:发现式聚类 ------ 为什么需要聚类 embeddings?
大多数向量搜索使用的是检索 embeddings,它们被训练用于将查询与相关文档进行匹配。这对于搜索非常有效,但并不适用于发现。当你希望在没有任何查询的情况下找出语料中存在哪些主题时,你需要能够将相似文档聚集在一起的 embeddings。
Jina v5 通过任务专用的 Low-Rank Adaptation (LoRA) adapters 解决了这个问题。LoRA 通过在特定内部层添加小规模低秩更新,同时保持大部分基础模型权重冻结,使模型行为能够针对特定任务进行调整,而无需完全重新训练。
同一个基础模型会根据 task 参数生成不同的 embeddings:
| Task | 训练目标 | 使用场景 |
|---|---|---|
| retrieval.passage | query-document 匹配 | 搜索、检索增强生成(RAG) |
| clustering | 主题分组(优化紧密聚类) | 发现、分类 |
clustering adapter 被训练用于让同一主题的文档在 embedding 空间中更接近,而不同主题的文档在空间中更远离。下面的可视化对比直观展示了这种差异。
检索 vs. 聚类:可视化对比
为了观察差异,我们使用两种 task 类型对一组文档进行 embedding。聚类是在原始的 1024 维 embedding 空间中完成的;均匀流形近似与投影(Uniform Manifold Approximation and Projection - UMAP)仅用于将这些 embeddings 投影到 2D 进行可视化。UMAP 能够保留局部邻域结构,因此适用于比较聚类的分离效果。
下面使用相同的 480 篇文档样本,分别用两种 task 进行 embedding,并通过 UMAP 投影到 2D。请注意在 clustering 面板中颜色分组是否更紧密、分离是否更清晰。
markdown
`1. Full dataset: 8,495 articles
2. Sources: guardian: 5749, bbc: 2746
3. Date range: 2025-02-01 to 2025-02-28
6. Sample: 480 docs across 8 sections
7. section
8. Film 60
9. World news 60
10. Australia news 60
11. Opinion 60
12. Football 60
13. US news 60
14. Sport 60
15. Business 60
18. Clustering embeddings: 480
19. Retrieval embeddings: 480
22. UMAP projection complete`AI写代码 检索 embeddings(左)会将主题更广泛地分散开;聚类 embeddings(右)则在相同文档上形成更紧密、更分离的分组。
检索 embeddings(左)会将主题更广泛地分散开;聚类 embeddings(右)则在相同文档上形成更紧密、更分离的分组。
聚类 embeddings 会产生更紧凑、视觉上更清晰的分组。检索 embeddings 会更均匀地分布主题,这非常适合搜索(细粒度相似性);但对于发现任务而言,更重要的是紧密的主题聚类。
这也是为什么在接下来的流程中使用 task="clustering"。
加载数据集
该语料库结合了 2025 年 2 月的两个新闻来源:
- BBC News (通过 HuggingFace 数据集 RealTimeData/bbc_news_alltime)
- The Guardian (通过 Guardian Open Platform API)
使用多个来源有助于验证:聚类识别的是主题,而不是来源本身的写作风格差异。
yaml
`1. Total articles: 8,495
3. Source breakdown:
4. source
5. guardian 5749
6. bbc 2746
8. Date range: 2025-02-01 → 2025-02-28
9. Days covered: 28
11. Sample article:
12. Source: guardian
13. Title: Carbon monoxide poisoning ruled out in death of Gene Hackman and wife, police sa
14. Section: Film
15. Text: Authorities have ruled out that Gene Hackman and his wife, Betsy Arakawa, died from carbon monoxide poisoning earlier this week in their home in Santa Fe, New Mexico. The Santa Fe county sheriff, Adan...`AI写代码使用 clustering 任务进行 embedding
对所有文档调用 Jina v5 API,并设置 task="clustering"。embedding 会被缓存到磁盘,因此后续运行将完全跳过 API 调用。
该 API 调用非常简单。与传统 embedding 使用方式的关键区别在于 task 参数:
bash
`
1. payload = {
2. "model": "jina-embeddings-v5-text-small",
3. "input": texts,
4. "task": "clustering", # ← This selects the clustering LoRA adapter
5. }
`AI写代码下面的耗时结果表示命中了缓存(cache hit)。首次调用 API 时会更慢,具体取决于语料库大小。
yaml
`1. Embeddings ready: 8,495 vectors of dimension 1024
2. Time: 0.6s`AI写代码索引到单个 Elasticsearch index
对于发现式聚类,整个月的数据会被写入同一个 index(docs-clustering-all)。按天的分区用于后续的时间序列故事关联(temporal story linking)。
该 index 的 mapping 使用 bbq_disk 作为向量字段:
json
`
1. {
2. "embedding": {
3. "type": "dense_vector",
4. "dims": 1024,
5. "index": true,
6. "similarity": "cosine",
7. "index_options": {
8. "type": "bbq_disk" // hierarchical k-means partitioning for ANN index lookup; separate from this post's clustering algorithm
9. }
10. }
11. }
`AI写代码一个 1024 维 float32 向量大小为 4 KB。bbq_disk 使用分层 k-means 将向量划分为多个小簇,对其进行二进制量化,并将全精度向量存储在磁盘上用于重排序(rescore)。只有分区元数据保留在 heap 中,因此即使处理大规模语料库,内存占用也能保持较低。
对于可以承担更多 heap 开销的工作负载,bbq_hnsw 会构建 Hierarchical Navigable Small World(HNSW)图,以更高资源成本换取更快的查询速度。
dense_vector 字段类型支持多种量化策略:bbq_disk 和 bbq_hnsw 是最适合高维 embeddings(如本示例中 1024 维向量)的选择。
sql
`1. Indexed 8,495 documents into docs-clustering-all
2. Time: 57.5s`AI写代码聚类:基于密度探测的质心分类
传统聚类算法(如 HDBSCAN)假设你可以将完整的 N×d 向量矩阵加载到内存中,并进行多轮全量迭代更新。对于 8,495 篇文档、1024 维向量来说,这在内存上是可行的(约 35 MB),但当规模扩展到数百万文档时,就需要额外的基础设施支持。
该算法在概念上类似于 KMeans++ 初始化 + Voronoi 分配 + 噪声阈值机制,但它使用 Elasticsearch kNN 搜索作为计算原语,将几乎所有计算都放在服务端完成:
-
从 5% 的文档中采样作为 density probes(随机采样,最少 50 个)。
-
通过批量 msearch kNN 进行密度探测 。每个 probe 会发起一次 kNN 查询,并记录其邻居的平均相似度。平均相似度越高,表示 embedding 空间中的区域越密集。
msearch 会将多个 search 请求合并到一次 HTTP 调用中,这一点非常关键:密度探测会生成数百个 kNN 查询,如果不批量处理,会产生极高的请求开销。 -
通过去重与多样性选择高密度种子点:将高于中位数密度的候选按密度降序排序,并采用贪心方式选择,仅当其与已有 seed 的 cosine similarity 低于分离阈值时才接受。这是唯一的客户端计算部分(约 0.01 秒处理 8k 文档)。
-
通过 msearch kNN 对所有文档进行质心分类:每个 seed 作为一个 centroid,kNN 搜索其邻近文档(高于相似度阈值)。每个文档被分配到返回得分最高的 centroid。小型 cluster 会被视为 noise 并移除。
Elasticsearch 负责主要计算工作:density probe 的 msearch、classification 的 msearch,以及用于标签生成的 significant_text。对于本数据集(8,495 篇文档),5% 的 density-probe 会生成 425 次 kNN 查询,这些查询通过 msearch 被合并为 9 次 HTTP 请求(batch size = 50),避免了逐请求调用的开销。结合 bbq_disk ANN 检索,这使得整个聚类流程既快速又可扩展。kNN 查询在 clustering 阶段使用较小的 num_candidates 以提升速度;而生产环境搜索则应提高该值,以换取更高召回率(但会增加延迟)。
最终得到的 clusters 具有自然大小分布,由 embedding 空间中围绕每个 centroid 的密度决定,而不是固定 k 值。高密度主题区域会形成更大的 cluster,而小众主题则形成更小的 cluster。
为什么不用 KMeans 或 HDBSCAN?
KMeans 假设聚类是球形分布,并且需要将完整的 N×d 矩阵加载到内存中。对于能够放入内存的语料库,HDBSCAN 是一个很强的替代方案,它可以处理任意形状的聚类,并且具有成熟的密度语义。
基于密度探测的质心方法面向的是另一类场景:当你希望在同一个系统中同时完成存储、检索和聚类,或者当数据规模大到无法在客户端进行矩阵运算时。该方法使用 Elasticsearch kNN 作为计算原语,能够处理任意大小的 cluster,并将几乎所有计算保留在服务端完成。
yaml
`1. Clustered global index in 31.6s
2. Total clusters: 82
3. Total noise: 2420 (28.5%)
4. Density probes: 425 kNN queries via 9 _msearch HTTP calls`AI写代码理解噪声率
约 28% 的噪声率是设计结果,而不是失败模式。当文档无法在配置的 similarity_threshold 下归入任何高密度 cluster 时,它们不会被强行分配到错误的类别,而是保持未分配状态。这相当于一个质量门控机制:评论文章、短新闻以及一次性事件通常难以聚类,因为它们缺乏形成稳定主题组所需的语义密度。
该阈值是可调的:降低 similarity_threshold 会使聚类更加激进(更多文档被分配,但 cluster 更松散),而提高该阈值则会使 cluster 更紧密,同时增加噪声比例。对于这个混合新闻语料库,约 30% 的噪声属于合理的运行状态。在生产环境中,应根据领域特定的质量标准来调整该阈值。
使用 significant_text 自动生成标签
现在每个 cluster 都需要一个可读的人类标签。Elasticsearch 的 significant_text 聚合会找出在 "前景集合"(cluster)中出现频率异常高的词,并与 "背景集合"(整个语料库)进行对比。
其底层使用统计启发式方法(默认 JLH score),平衡绝对频率和相对频率的变化,不依赖机器学习,也不调用大型语言模型(LLM)。例如,一个关于英国政治的 cluster 可能会突出 starmer、labour、downing 等词,因为这些词在该 cluster 中的出现频率显著高于整个新闻语料库。
在这个全局处理阶段中,标签直接基于 docs-clustering-all 计算,因此前景和背景都来自整个月的数据。在第 2 部分中,标签会使用按天的索引模式(docs-clustering-*),通过通配符跨多个 index 进行查询,从而为 significant_text 提供更广泛的背景以增强对比效果。
一个最小查询结构如下:
bash
`
1. {
2. "size": 0,
3. "query": { "term": { "cluster_id": "72" } },
4. "aggs": {
5. "label_terms": {
6. "significant_text": {
7. "field": "text",
8. "size": 5,
9. "filter_duplicate_text": true
10. }
11. }
12. }
13. }
`AI写代码significant_text 同时也充当一个质量门控(quality gate):如果某个 cluster 无法生成显著词项(significant terms),说明它没有具有区分性的词汇。这类 cluster 本质上是语义不连贯的分组,应当被重新归入噪声(noise),而不是赋予一个具有误导性的标签。
一个轻量级的确定性清理步骤会移除噪声标签词(如数字 token、通用词汇),并在必要时回退到一条代表性标题(representative headline)。这样可以保持标签完全基于 Elasticsearch 原生能力,同时提升可读性。
markdown
`1. Sample cluster labels:
2. cluster 3 (200 docs) arsenal | mikel | villa
3. cluster 1 (198 docs) volodymyr | ukrainian | kyiv
4. cluster 0 (196 docs) hostages | hamas | israeli
5. cluster 4 (187 docs) scrum | rugby | borthwick
6. cluster 52 (185 docs) fossil | renewable | renewables
7. cluster 10 (156 docs) labour | gwynne | mps
8. cluster 40 (151 docs) novel | novels | literary
9. cluster 11 (149 docs) mewis | sarina | wiegman
10. cluster 44 (143 docs) flooding | rainfall | rain
11. cluster 13 (131 docs) doge | musk | elon
12. cluster 12 (128 docs) murder | insp | knockholt
13. cluster 5 (124 docs) putin | backstop | starmer
16. Reassigned 35 docs from incoherent clusters to noise
17. Total docs: 8,495
18. Clustered: 6,040 (71.1%)
19. Noise: 2,455 (28.9%)`AI写代码可视化 clusters
下面的可视化展示了全局聚类(global clustering)阶段的结果:按日期划分的聚类与噪声文档分布、整个月数据的 UMAP 投影,以及一个来源混合图(source-mix chart),用于验证 clusters 反映的是主题而不是数据来源本身。
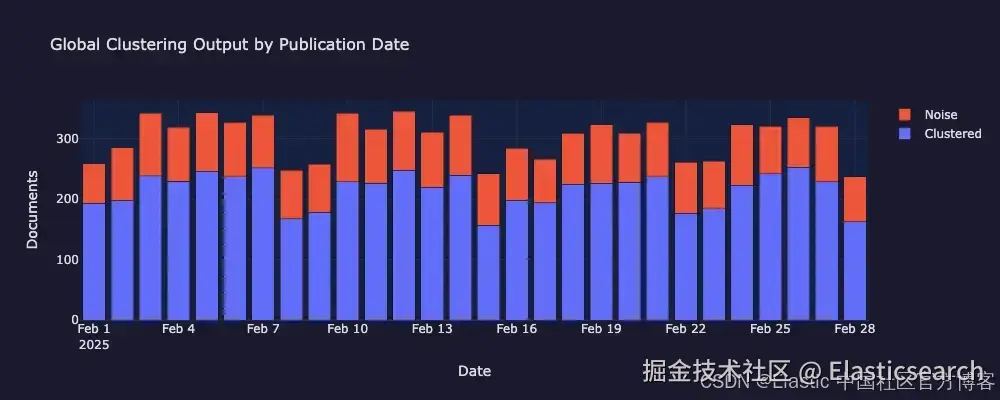
2025 年 2 月期间按天统计的聚类文档与噪声文档分布。
 整个月的 UMAP 投影:每个彩色"岛屿"代表一个主题 cluster,灰色点表示噪声(noise)。
整个月的 UMAP 投影:每个彩色"岛屿"代表一个主题 cluster,灰色点表示噪声(noise)。
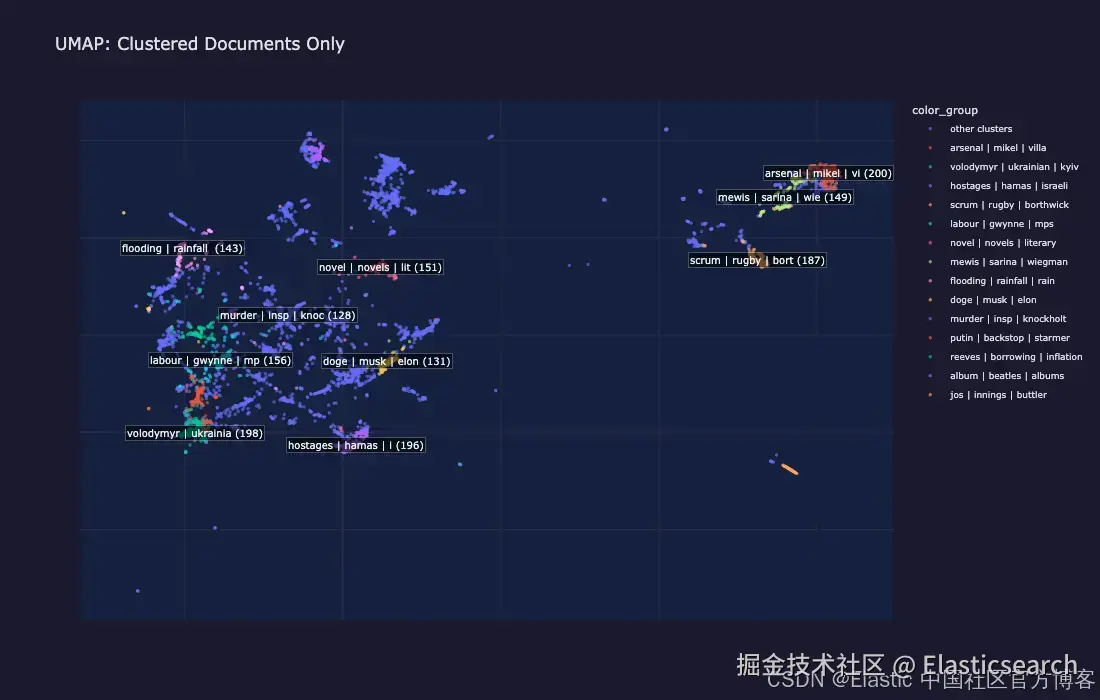 仅展示已聚类文档:去除噪声后,主题结构更加清晰可见。
仅展示已聚类文档:去除噪声后,主题结构更加清晰可见。
 聚焦视图突出一个聚类( Premier League football )与其他所有聚类对比。
聚焦视图突出一个聚类( Premier League football )与其他所有聚类对比。
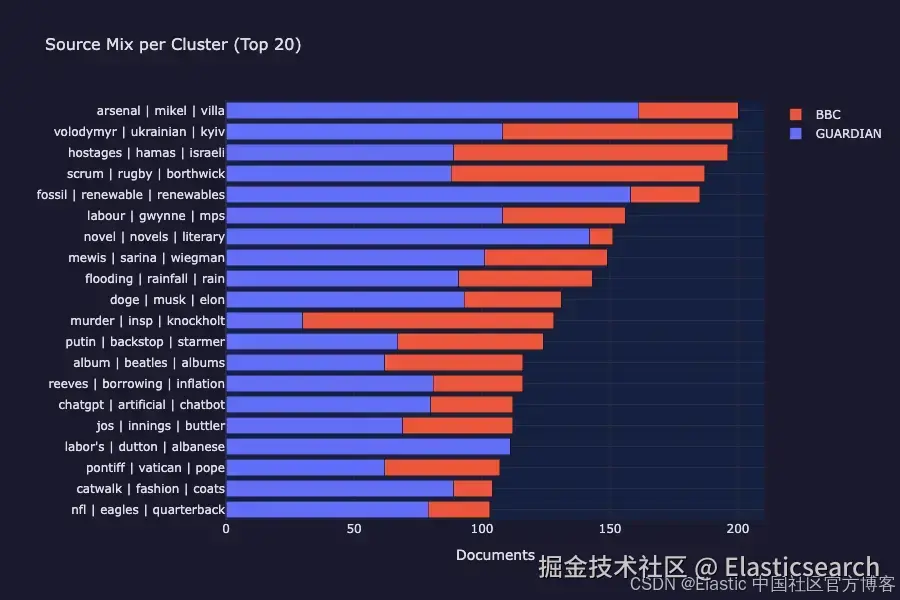 每个聚类的来源混合情况: BBC 和 Guardian 都出现在所有主要聚类中,证实这是基于主题的分组,而不是基于来源的分组。
每个聚类的来源混合情况: BBC 和 Guardian 都出现在所有主要聚类中,证实这是基于主题的分组,而不是基于来源的分组。
每个在 UMAP 中的彩色"岛屿"代表一个聚类:一组通过 embedding 相似度纯粹发现的、关于同一主题的文章。灰色噪声点是那些无法清晰归入任何聚类的文章(通常是短文章、评论性文章或一次性报道)。
来源分布图表进一步确认,这些聚类同时包含来自 BBC News 和 The Guardian 的文章。这说明聚类是按主题而不是按来源进行分组的,这正是无监督发现应该产生的结果。
使用 diversify retriever 探索聚类的广度
普通 kNN 返回的是与聚类中心(centroid)最相似的文档(也就是最密集的核心区域)。但真实的聚类往往包含多个子主题。diversify retriever 使用 Maximal Marginal Relevance(MMR)来检索那些既与中心相关、又彼此之间具有差异性的文档。
关键参数是 λ(lambda):
- λ = 1.0 → 纯相关性(等同于普通 kNN)。
- λ = 0.0 → 纯多样性(结果最大程度分散)。
- λ = 0.5 → 平衡:既与主题相关,同时覆盖不同角度。
版本说明:diversify retriever 可用于 Elastic Cloud Serverless 和 Self-Managed Elasticsearch 9.3+。更早版本仍可使用聚类与时间链接部分;只有这一探索步骤需要 diversify retriever。
一个最小的 retriever 请求结构如下:
bash
`
1. {
2. "size": 8,
3. "retriever": {
4. "diversify": {
5. "type": "mmr",
6. "field": "embedding",
7. "lambda": 0.5,
8. "query_vector": "<cluster-centroid-vector>",
9. "retriever": {
10. "knn": {
11. "field": "embedding",
12. "query_vector": "<cluster-centroid-vector>",
13. "k": 50,
14. "num_candidates": 100
15. }
16. }
17. }
18. }
19. }
`AI写代码type, field, and query_vector 参数在 diversify 层是必需的:field 告诉 MMR 使用哪个 dense_vector 字段来进行结果间相似度计算,而 query_vector 提供用于 relevance scoring 的参考点。
这使你能够回答:"这个 cluster 实际覆盖了什么?"而不仅仅是"它的中心是什么?"
vbnet
`1. Exploring cluster 52 (185 docs)
2. Label: fossil | renewable | renewables
3. Centroid computed (dim=1024)
6. ========================================================================
7. Plain kNN (closest to centroid)
8. ========================================================================
9. 1. [0.9738] Green campaigners fear ministers are poised to award billions of pounds in fresh subsidies to Drax power station, despite strong concerns...
10. 2. [0.9710] Thirteen more oil and gas licences could be cancelled as ministers decide new guidance for fossil fuel extraction after a landmark court...
11. 3. [0.9699] Experts have accused the fossil fuel industry of seeking special treatment after lobbyists argued greenhouse gas emissions from oilfields...
12. 4. [0.9681] Burning wood is a terrible way of producing electricity . Chopping down trees destroys habitats for wildlife, and growing new trees cannot...
13. 5. [0.9649] Keir Starmer will do huge damage to the global fight against climate change if he gives in to political pressure and allows the development...
14. 6. [0.9641] Labour will next week be confronted with stark policy choices that threaten to expose the fault lines between the Treasury and the...
15. 7. [0.9638] The Drax power station near Selby in north Yorkshire burns imported wood pellets The government has agreed a new funding arrangement with...
16. 8. [0.9581] If you care about the world we are handing on to future generations, the news on Thursday morning was dramatic. This January was the...
18. ========================================================================
19. Diversify retriever (MMR, lambda=0.5)
20. ========================================================================
21. 1. [0.9738] Green campaigners fear ministers are poised to award billions of pounds in fresh subsidies to Drax power station, despite strong concerns...
22. 2. [0.9434] Oil and gas interests have waged a coordinated campaign to kill pro-electrification policies that ban gas connections in new buildings ,...
23. 3. [0.9303] It was interesting to read that new licences for oil and gas production in the North Sea are being delayed by legal action ( Thirteen more...
24. 4. [0.9139] The US energy secretary, Chris Wright, has said he "would love to see Australia get in the game of supplying uranium and maybe going down...
25. 5. [0.9077] Rachel Reeves was facing criticism on Saturday night as it was confirmed that a report she cited as evidence that a third runway at...
26. 6. [0.8996] When Margaret Thatcher opened the Hadley Centre for Climate Change in 1990 journalists suggested she was attempting to appear to be doing...
27. 7. [0.8993] The vast majority of governments are likely to miss a looming deadline to file vital plans that will determine whether or not the world has...
28. 8. [0.8987] European imports of seaborne gas shipments fell by a fifth last year to their lowest level since the pandemic, according to a new report,...
30. Overlap: 1/8 documents appear in both result sets
32. Avg pairwise similarity (lower = more diverse):
33. Plain kNN: 0.9057
34. Diversify retriever: 0.6965`AI写代码纯 kNN 结果围绕主题的一个角度聚类:即与 centroid 以及彼此最相似的文档。diversify retriever 会呈现同一 cluster 的不同方面:子主题、不同来源以及多样化视角。
diversity metric 在定量上验证了这一点:diversify retriever 结果的平均 pairwise similarity 更低,意味着返回的文档覆盖范围更广。
这对于以下情况很有用:
- 理解一个 cluster 实际覆盖的内容,不仅是中心,还包括边缘。
- 生成 summary:多样化的代表性文档能为 LLM 提供更好的素材。
- 为人工 review 或下游 labeling 提供代表性示例。
- 质量检查:如果 diverse 结果看起来不连贯,可能说明 cluster 需要拆分。
第 2 部分:时间故事链
跨天追踪故事
第一部分在全月范围内进行全局 clustering 用于 topic discovery。对于时间流,相同的 density-probed centroid classification 会在每日 index 上独立运行,然后将跨相邻天的 clusters 连接起来。注意,每日 cluster 与 Part 1 的全局 cluster 是独立的:每一天都会生成自己的 cluster assignment 和 labels,以适配当天的内容。
连接方法:sample-and-query
对于 day A 的每个 cluster:
- 采样几个代表性 documents。
- 在 day B 的 index 上运行 kNN。
- 统计命中的结果落在 day B 各个 cluster 的数量。
- 如果命中比例超过阈值(kNN fraction ≥ 0.4),则记录一条 link。
这种方法很快(每个 cluster 只查询少量 documents,而不是全部),并且直接使用 Elasticsearch 的 native kNN,不需要外部工具。
rust
`
1. Preparing daily indices for temporal linkage...
4. Indexed 8,495 docs into 28 daily indices
7. Temporal links found: 808 in 145.4s
9. Strongest links:
10. 2025.02.01 'league | arsenal | premier' -> 2025.02.02 'league | season | striker' (100%)
11. 2025.02.03 'league | striker | loan' -> 2025.02.04 'league | striker | season' (100%)
12. 2025.02.03 'score | operator | gedling' -> 2025.02.04 'league | striker | season' (100%)
13. 2025.02.12 'playoff | leg | bayern' -> 2025.02.13 'league | players | injury' (100%)
14. 2025.02.14 'league | injury | football' -> 2025.02.15 'league | premier | football' (100%)
15. 2025.02.18 'russia | ukraine | talks' -> 2025.02.19 'saudi | russia | arabia' (100%)
16. 2025.02.18 'football | league | bayern' -> 2025.02.19 'league | manchester | players' (100%)
17. 2025.02.21 'league | premier | manchester' -> 2025.02.22 'game | players | defeat' (100%)
18. 2025.02.21 'rugby | calcutta | brilliant' -> 2025.02.22 'game | players | defeat' (100%)
19. 2025.02.26 'metals | kyiv | ukrainian' -> 2025.02.27 'ukraine | russia | talks' (100%)
`AI写代码kNN 比例为 100% 表示源 cluster 中所有采样文档都落入同一个目标 cluster,这是最强的跨天连接关系。上面的多数链接都是足球相关的,这很合理:Premier League 的报道每天都有,且主题连续性很高。
score | operator | gedling → league | striker | season link 是一个小众本地足球 cluster(Gedling 是一个非联赛俱乐部)在下一天被吸收到更广泛的 Premier League cluster 中的例子,这是不同粒度每日重新聚类时的自然结果。
构建 story chains
story chain 是跨连续日期链接起来的一系列 clusters。
单个 pairwise link 只能告诉你"周一的 UK politics cluster 连接到了周二的某个 cluster"。而 chains 能还原完整叙事:一个故事从周一开始,在一周中演进,并在周五逐渐消退。
chains 通过 greedy 方式构建,只使用 kNN fraction ≥ 0.4 的链接,这意味着至少 40% 的采样文档都落入同一个目标 cluster。从最早的 cluster 开始,算法始终沿着最强的 outgoing link 继续推进。
yaml
`1. Strong links (kNN fraction >= 0.4): 244
2. Story chains spanning 3+ days: 18
3. Chain 1: 'ukrainian | kyiv | eastern' (19 days: Feb 3 → Feb 21)
4. Chain 2: 'playing | opposition' (19 days: Feb 10 → Feb 28)
5. Chain 3: 'tadhg | maro | cadan' (10 days: Feb 1 → Feb 10)
6. Chain 4: 'invade | china | putin' (8 days: Feb 21 → Feb 28)
7. Chain 5: 'elected | labour | leader' (7 days: Feb 12 → Feb 18)
8. Chain 6: 'film | swift | awards' (6 days: Feb 2 → Feb 7)
9. Chain 7: 'amendment | termination | reporting' (6 days: Feb 12 → Feb 17)
10. Chain 8: 'officers | scene | police' (5 days: Feb 1 → Feb 5)`AI写代码最长的链跟踪了 Ukraine--Russia 在 2025 年 2 月连续 19 天的报道,这并不意外,因为地缘政治的高强度持续性。第二长的链是 Premier League 足球,同样覆盖了 19 天的月内时间段。较短的链包括颁奖季(电影/奖项,6 天)、Six Nations 橄榄球(10 天)以及英国政治领导层相关报道(7 天)。每一条链都代表一个故事弧线,这些结构完全是算法基于跨每日索引的 embedding 相似度自动发现的。
Sankey:可视化故事流
Sankey 图是一种流向可视化,其中连线宽度表示连接强度。在这里,每一条垂直带代表一天,每个节点是一个每日 cluster(大小由文档数量决定),每条彩色路径追踪一条跨时间的 story chain。连接宽度编码 kNN overlap 强度:越粗的连线表示越多采样文档落入目标 cluster。每种颜色对应一条固定 chain,因此同一颜色从左到右的路径就代表一个故事的演进。
例如,Ukraine--Russia 链(在较长路径中可见)从 2 月初持续流向第三周,并且始终保持较粗的连接,表明跨天之间具有稳定且强的主题连续性。
2025 年 2 月中跨天流动的 temporal story chains。每一条彩色路径代表一个持续跨越多天的故事;连接宽度表示 kNN 重叠强度。
本方法实现的内容
本教程展示了一个完整的无监督文档聚类流程,构建在 Elasticsearch 之上:
- embedding 聚类:Jina v5 的 task-specific adapters 生成的 embedding 针对主题分组进行了优化,而不仅仅是 query-document 匹配。
- 全局发现聚类:在单一索引中对整个月数据进行聚类,可以最大化跨天的主题发现能力。
- 密度探测的质心分类:抽样 5%,通过 msearch kNN 探测密度,选择多样且高密度的 seed,再将所有文档分类到 centroids。Elasticsearch 承担主要计算,仅 seed 选择在客户端执行(约 0.01s)。
- significant_text 标注:通过显著性检验生成有意义的 cluster 标签,无需任何 ML 模型或人工标注。无法产生显著词项的 cluster 被判定为不连贯并降为 noise ------ 内置质量控制机制。
- 时间故事链接:通过每日索引 + sample-and-query 跨索引 kNN 追踪故事如何随时间演变。
关键要点:
- embedding task 类型很重要:用于 clustering 的 embedding 能显著提升主题聚类紧密度。
- Elasticsearch 可以同时作为存储层和聚类引擎,通过 kNN search 实现。
- density-probed centroid classification 将几乎所有计算留在 server-side,cluster 大小由 embedding 空间密度自然决定。
- significant_text 既快速又可解释,同时适用于自动标注和质量控制。
适用场景:
- 你拥有带时间戳的文本数据,并希望在没有标注数据的情况下进行主题发现。
- 你希望用一套技术栈同时完成存储、向量检索、标注和时间关联。
可扩展方向:
- 多周期聚类(周级、月级汇总)。
- 实时数据流入与增量 cluster 分配。
- 使用 LLM 基于 significant_text 词项生成 cluster summary。
- 在更大规模下,采样的 KMeans centroids 可以作为 density-based clustering 的 warm-start seed,从而降低 probe 阶段成本。
尝试方式
将你自己的带时间戳文档语料替换进去;任何带日期的文本集合都可以使用该流程。完整 notebook 和代码可在配套仓库中获取。
- 启动免费 Elastic Cloud 试用:几分钟内即可创建支持 bbq_disk 的托管集群。
- 尝试 Elasticsearch Serverless:无需管理集群,自动扩展,支持本教程中的全部功能。