- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
python
- # ===================== 1. 环境兼容与库导入模块 =====================
# 导入数值计算库NumPy,用于数组、矩阵运算,是数据科学的基础库
import numpy as np
# 兼容新版NumPy:新版NumPy删除了np.object/np.bool/np.int别名,手动绑定原生Python类型,避免报错
np.object = object
np.bool = bool
np.int = int
# 导入数据处理库Pandas,用于读取、清洗、操作表格数据(核心数据处理工具)
import pandas as pd
# 导入高级可视化库Seaborn,基于Matplotlib,用于绘制更美观的统计图表
import seaborn as sns
# 导入基础绘图库Matplotlib,用于自定义图表、显示图像
import matplotlib.pyplot as plt
# 导入警告控制库,用于忽略无关紧要的程序警告
import warnings
# 导入日期时间库,用于获取当前时间、处理日期格式
from datetime import datetime
# 导入操作系统库,用于文件路径操作(本代码未直接使用,属于常规导入)
import os
# 忽略所有警告信息,避免控制台输出多余提示
warnings.filterwarnings('ignore')
# 从sklearn库导入数据集划分工具:将数据分为训练集和测试集
from sklearn.model_selection import train_test_split
# 从sklearn库导入数据归一化工具:将数据缩放到0-1之间(本代码未使用,属于常规导入)
from sklearn.preprocessing import MinMaxScaler
# 导入深度学习框架TensorFlow及其高级API Keras(用于构建神经网络模型)
import tensorflow as tf
from tensorflow import keras
# 导入Keras的顺序模型:线性堆叠神经网络层的基础模型
from tensorflow.keras.models import Sequential
# 导入Keras核心层:全连接层(Dense)、激活函数层(Activation)、 dropout层(防止过拟合)
from tensorflow.keras.layers import Dense, Activation, Dropout
# 导入早停回调函数:训练时自动停止,防止模型过拟合
from tensorflow.keras.callbacks import EarlyStopping
# 重复导入Dropout层(冗余代码,保留原逻辑不修改)
from tensorflow.keras.layers import Dropout
# 导入模型评估工具:分类报告、混淆矩阵(分类任务评估指标)
from sklearn.metrics import classification_report, confusion_matrix
# 导入回归任务评估指标:R2决定系数
from sklearn.metrics import r2_score
# 导入回归任务评估指标:平均绝对误差、平均绝对百分比误差、均方误差
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error, mean_squared_error
# ===================== 2. 数据读取与备份 =====================
# 读取本地CSV格式的澳大利亚天气数据集,赋值给data变量
data=pd.read_csv("weatherAUS.csv")
# 复制一份原始数据,避免后续操作修改原数据(数据处理的安全备份习惯)
df=data.copy()
# ===================== 3. 日期特征工程(时间数据处理) =====================
# 将数据中的'Date'列从字符串格式 转换为 标准日期时间格式(方便提取年/月/日)
data['Date'] = pd.to_datetime(data['Date'])
# 从日期列中提取【年份】,生成新列year
data['year'] = data['Date'].dt.year
# 从日期列中提取【月份】,生成新列Month
data['Month'] = data['Date'].dt.month
# 从日期列中提取【日期】,生成新列day
data['day'] = data['Date'].dt.day
# 删除原始的Date列(已经提取完年/月/日,原列无用),inplace=True表示直接修改原数据
data.drop('Date',axis=1,inplace=True)
# ===================== 4. 特征相关性分析(热力图可视化) =====================
# 筛选数据中的**数值型列**(整数、浮点数),相关性计算只支持数值类型
numeric_data = data.select_dtypes(include=[np.number])
# 创建一个画布,设置尺寸为20x15英寸(大尺寸方便看清热力图文字)
plt.figure(figsize=(20, 15))
# 绘制相关性热力图:
# numeric_data.corr():计算所有数值特征两两之间的相关系数
# square=True:热力图单元格为正方形
# annot=True:显示相关系数数值
# fmt='.2f':数值保留两位小数
ax = sns.heatmap(numeric_data.corr(), square=True, annot=True, fmt='.2f')
# 将x轴标签旋转90度,防止标签重叠
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
# 获取当前系统时间,作为图表x轴标签
nowtime=datetime.now()
plt.xlabel(nowtime)
# 显示热力图
plt.show()
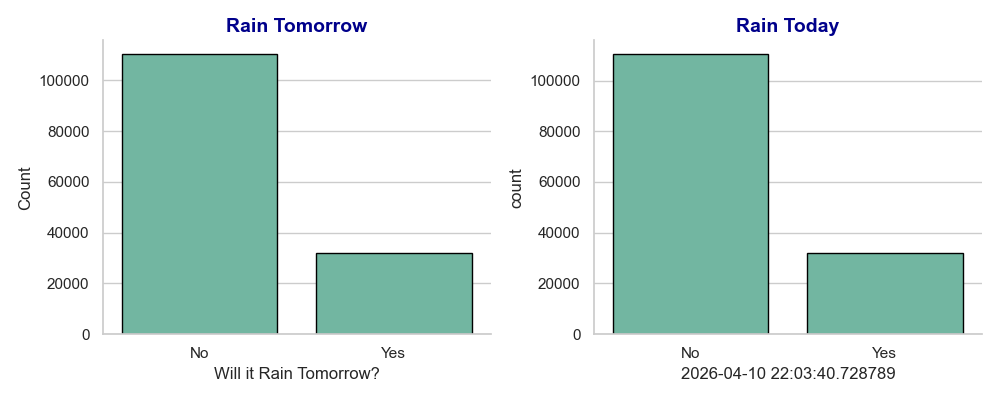
# ===================== 5. 降雨分布可视化(计数图) =====================
# 设置Seaborn绘图样式:白色网格背景 + Set2调色板
sns.set(style="whitegrid", palette="Set2")
# 创建1行2列的子图布局,总画布尺寸10x4英寸
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
# 定义图表标题统一样式:字体大小14、加粗、深蓝色
title_font = {'fontsize': 14, 'fontweight': 'bold', 'color': 'darkblue'}
# 第一个子图:统计【明天是否下雨】的样本数量
# x='RainTomorrow':以该列为分类依据
# data=data:使用当前数据集
# ax=axes[0]:指定绘制在第一个子图
# edgecolor='black':给柱状图添加黑色边框
sns.countplot(x='RainTomorrow', data=data, ax=axes[0], edgecolor='black')
axes[0].set_title('Rain Tomorrow', fontdict=title_font) # 设置子图标题
axes[0].set_xlabel('Will it Rain Tomorrow?', fontsize=12) # 设置x轴标签
axes[0].set_ylabel('Count', fontsize=12) # 设置y轴标签
axes[0].tick_params(axis='x', labelsize=11) # 设置x轴刻度字体大小
axes[0].tick_params(axis='y', labelsize=11) # 设置y轴刻度字体大小
# 第二个子图:统计【今天是否下雨】的样本数量
sns.countplot(x='RainToday', data=data, ax=axes[1], edgecolor='black')
axes[1].set_title('Rain Today', fontdict=title_font)
axes[1].set_xlabel('Did it Rain Today?', fontsize=12)
axes[1].set_ylabel('Count', fontsize=12)
axes[1].tick_params(axis='x', labelsize=11)
axes[1].tick_params(axis='y', labelsize=11)
# 去除图表顶部和右侧的边框,让图表更简洁
sns.despine()
# 自动调整子图间距,防止标签重叠
plt.tight_layout()
plt.xlabel(nowtime)
# 显示计数图
plt.show()
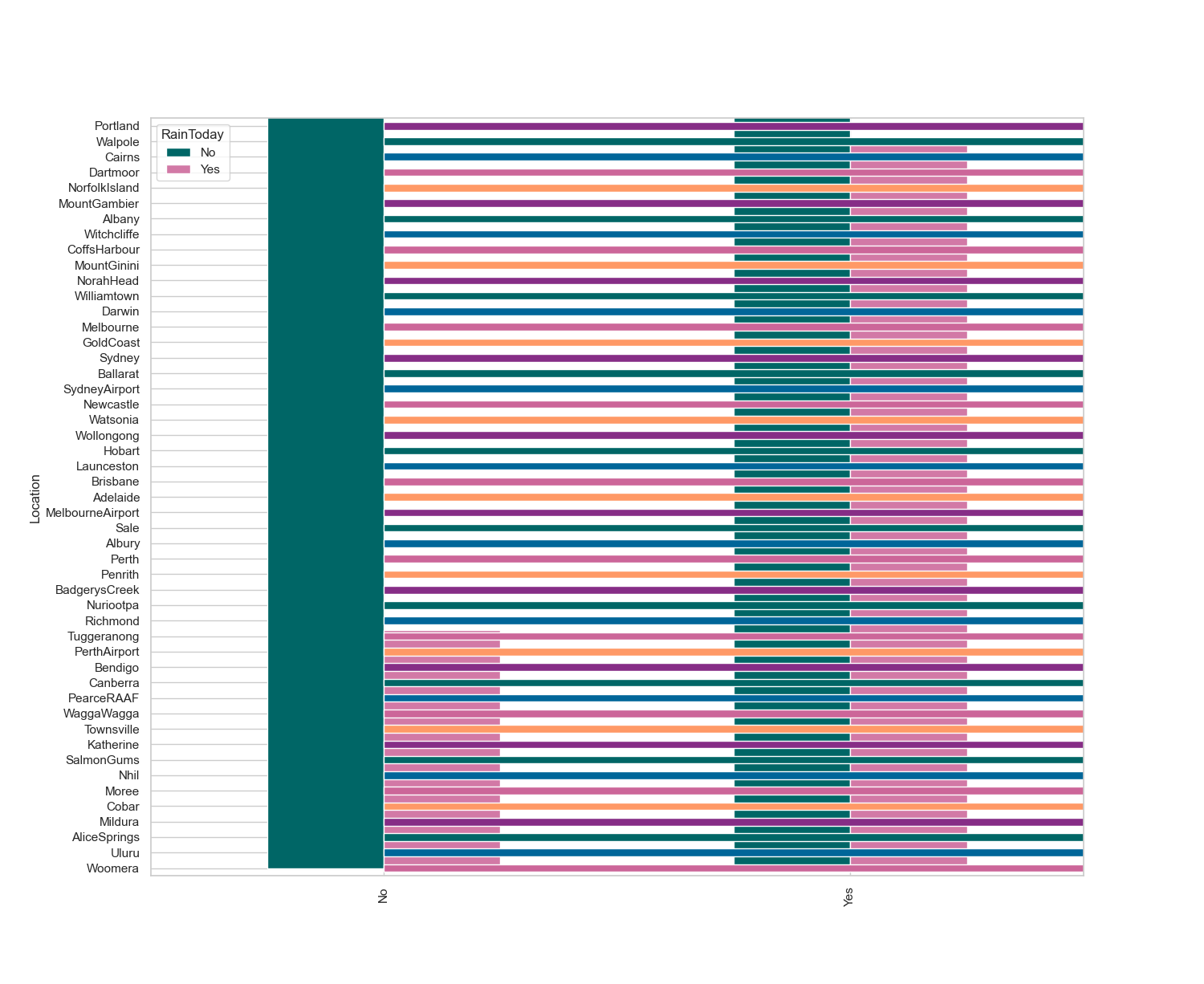
# ===================== 6. 降雨关联性与城市降雨分析 =====================
# 创建交叉表:统计【今天下雨】和【明天下雨】的数量关系
x=pd.crosstab(data['RainTomorrow'],data['RainToday'])
# 计算百分比:将交叉表数值转为百分比,便于对比比例
y=x/x.transpose().sum().values.reshape(2,1)*100
# 绘制柱状图:展示今天/明天下雨的百分比关系,设置自定义颜色
y.plot(kind="bar",figsize=(4,3),color=['#006666','#d279a6'])
# 重新创建交叉表:统计【不同城市】和【今天是否下雨】的数量关系
x = pd.crosstab(data['Location'], data['RainToday'])
# 计算每个城市 下雨/不下雨 的百分比
y = x / x.transpose().sum().values.reshape((-1, 1)) * 100
# 按【下雨天数占比】升序排序,方便对比城市降雨差异
y = y.sort_values(by='Yes', ascending=True)
# 定义自定义颜色列表,用于绘图
color = ['#cc6699', '#006699', '#006666', '#862d86', '#ff9966']
# 绘制水平条形图:展示各城市下雨占比,尺寸15x20英寸
y.Yes.plot(kind="barh", figsize=(15, 20), color=color)
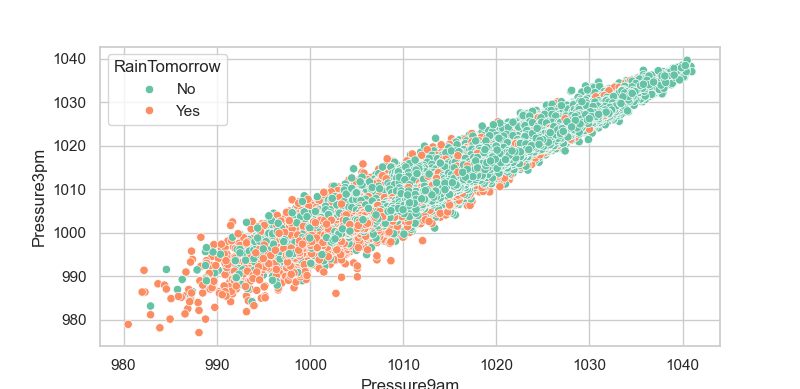
# ===================== 7. 特征与标签散点图可视化 =====================
# 创建画布8x6英寸,绘制散点图:
# x=上午气压,y=下午气压,颜色区分【明天是否下雨】,观察气压与降雨的关系
plt.figure(figsize=(8,6))
sns.scatterplot(data=data,x='Pressure9am', y='Pressure3pm',hue='RainTomorrow')
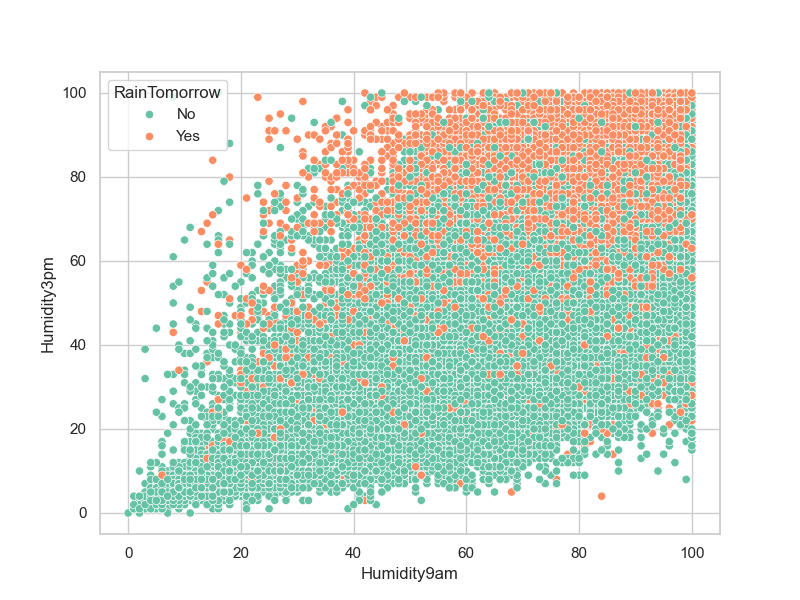
# 绘制散点图:上午湿度 vs 下午湿度,颜色区分明天下雨
plt.figure(figsize=(8,6))
sns.scatterplot(data=data,x='Humidity9am', y='Humidity3pm',hue='RainTomorrow')
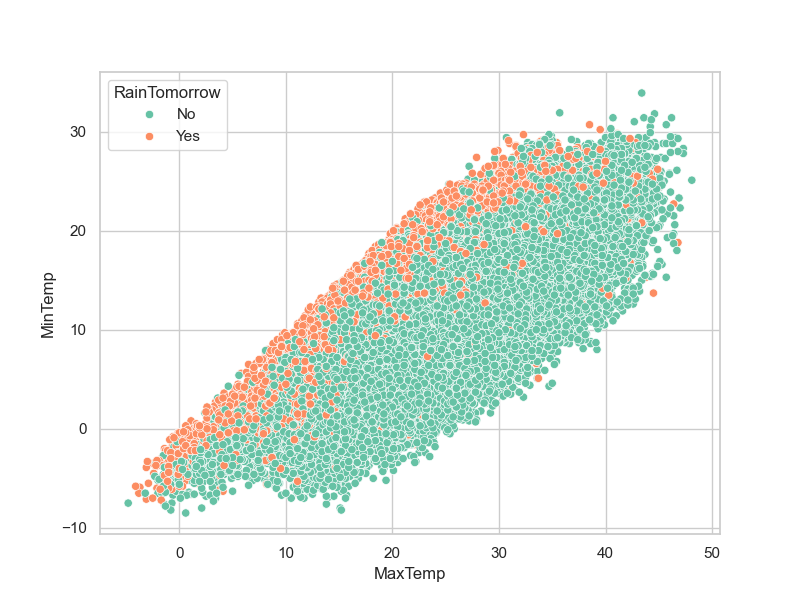
# 绘制散点图:最高温度 vs 最低温度,颜色区分明天下雨
plt.figure(figsize=(8,6))
sns.scatterplot(x='MaxTemp',y='MinTemp', data=data,hue='RainTomorrow')
# ===================== 8. 缺失值检测与处理(核心数据清洗) =====================
# 计算每一列缺失值的占比(缺失值数量 / 总行数 * 100),查看数据缺失情况
data.isnull().sum()/data.shape[0]*100
# 定义需要**随机填充**的列:蒸发量、日照时长、上午云量、下午云量
lst=['Evaporation','Sunshine','Cloud9am','Cloud3pm']
# 循环遍历这些列,用非空值随机填充缺失值
for col in lst:
# 提取当前列的非空数据
fill_list=data[col].dropna()
# 随机从非空数据中取值,填充该列的所有缺失值
data[col]=data[col].fillna(pd.Series(np.random.choice(fill_list,size=len(data.index))))
# 筛选出数据中的**分类型列**(文本类型,如城市、是否下雨)
s=(data.dtypes=='object')
object_cols=list(s[s].index)
# 循环遍历所有分类型列,用**众数**(出现次数最多的值)填充缺失值
# inplace=True:直接修改原数据,不创建副本
for i in object_cols:
data[i].fillna(data[i].mode()[0], inplace=True)
# 筛选出数据中的**浮点型数值列**
t=(data.dtypes=="float64")
num_cols=list(t[t].index)
# 循环遍历所有浮点型列,用**中位数**填充缺失值(中位数比均值更抗异常值)
for i in num_cols:
data[i].fillna(data[i].median(),inplace=True)
# ===================== 9. 分类特征编码(文本转数字) =====================
# 导入标签编码工具:将文本类型的分类特征 转换为 数字(神经网络只能处理数字)
from sklearn.preprocessing import LabelEncoder
# 创建标签编码器对象
label_encoder = LabelEncoder()
# 循环遍历所有分类型列,将文本转为数字(如Yes=1,No=0;城市名转为数字编号)
for i in object_cols:
data[i] = label_encoder.fit_transform(data[i])
# ===================== 10. 特征与标签划分 + 数据集拆分 =====================
# 特征X:删除目标列RainTomorrow(要预测的结果)和day列,剩余所有列作为输入特征
x=data.drop(['RainTomorrow','day'],axis=1).values
# 标签y:只保留RainTomorrow列(我们要预测的目标:明天是否下雨)
y=data['RainTomorrow'].values
# 将数据划分为训练集和测试集:
# test_size=0.25:25%数据作为测试集,75%作为训练集
# random_state=101:固定随机种子,保证每次运行划分结果一致
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25,random_state=101)
# 重复划分数据集(冗余代码,保留原逻辑不修改)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25,random_state=101)
# ===================== 11. 构建深度学习神经网络模型 =====================
# 导入Adam优化器(深度学习最常用的优化器,用于更新模型权重)
from tensorflow.keras.optimizers import Adam
# 初始化顺序模型:神经网络层按顺序线性堆叠
model = Sequential()
# 第一层:全连接层,24个神经元,激活函数tanh(双曲正切,将输出压缩到-1~1)
model.add(Dense(units=24, activation='tanh'))
# 第二层:全连接层,18个神经元,tanh激活
model.add(Dense(units=18, activation='tanh'))
# 第三层:全连接层,23个神经元,tanh激活
model.add(Dense(units=23, activation='tanh'))
# Dropout层:随机丢弃50%的神经元,防止模型过拟合( memorize训练集数据)
model.add(Dropout(0.5))
# 第四层:全连接层,12个神经元,tanh激活
model.add(Dense(units=12, activation='tanh'))
# Dropout层:随机丢弃20%的神经元,进一步防止过拟合
model.add(Dropout(0.2))
# 输出层:全连接层,1个神经元(二分类任务输出1个概率值)
# 激活函数sigmoid:将输出压缩到0~1之间,表示「明天下雨的概率」
model.add(Dense(units=1, activation='sigmoid'))
# 定义优化器:Adam优化器,学习率=0.0001(学习率越小,模型训练越稳定)
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
# 编译模型:配置训练参数
# loss='binary_crossentropy':二分类交叉熵损失函数(专门用于二分类任务)
# optimizer=optimizer:使用定义好的Adam优化器
# metrics="accuracy":训练时监控「准确率」指标
model.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics="accuracy")
# 配置早停法(防止过拟合的核心技巧)
early_stop=EarlyStopping(
monitor='val_loss', # 监控:验证集的损失值
mode='min', # 模式:损失值越小越好
min_delta=0.001, # 最小变化量:损失值下降小于0.001视为无提升
verbose=1, # 打印早停日志
patience=25, # 耐心值:25轮无提升就停止训练
restore_best_weights=True # 停止后,恢复训练中效果最好的模型权重
)
# ===================== 12. 训练模型 =====================
model.fit(
x=x_train, # 训练集特征
y=y_train, # 训练集标签
validation_data=(x_test,y_test), # 验证集:用测试集评估模型
verbose=1, # 打印训练日志
callbacks=[early_stop], # 启用早停法
epochs=10, # 最大训练轮数(最多训练10轮)
batch_size=32 # 批次大小:每次训练32个样本
)
'''
以下是原代码中的训练参数注释,保留供参考:
x:输入数据。在这里,我们将训练集数据 X_train 作为输入。
y:标签数据。在这里,我们将训练集标签 y_train 作为标签。
validation_data:验证集数据和标签。在这里,我们将测试集数据 X_test 和测试集标签 y_test 组成的元组作为验证集数据。
verbose:详细程度。控制输出信息的详细程度,通常设置为 0、1 或 2。
callbacks:回调函数列表。我们在这里传入了 EarlyStopping 回调函数对象。
epochs:训练轮数。每次训练都会用整个数据集进行训练,一次训练完成后称为一个 epoch。
batch_size:批次大小。即每次训练时所选取的样本数量。
在训练过程中,模型将使用 Adam 优化器最小化损失函数(binary_crossentropy),同时监控和输出训练和验证的准确率。如果模型在验证集上的损失没有提升,则 EarlyStopping 回调函数将停止训练,并恢复具有最佳验证损失的模型权重(如果 restore_best_weights 设置为 True)
'''
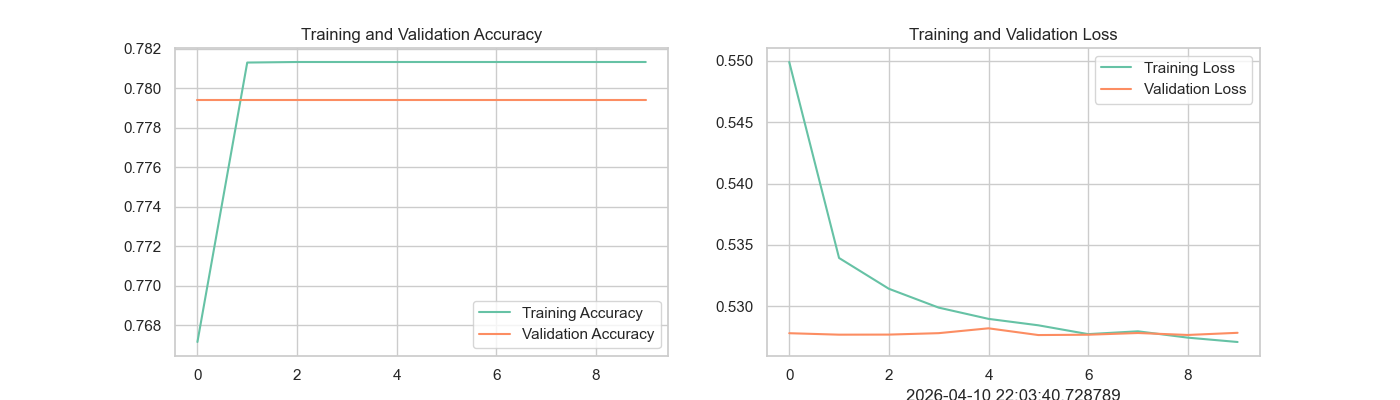
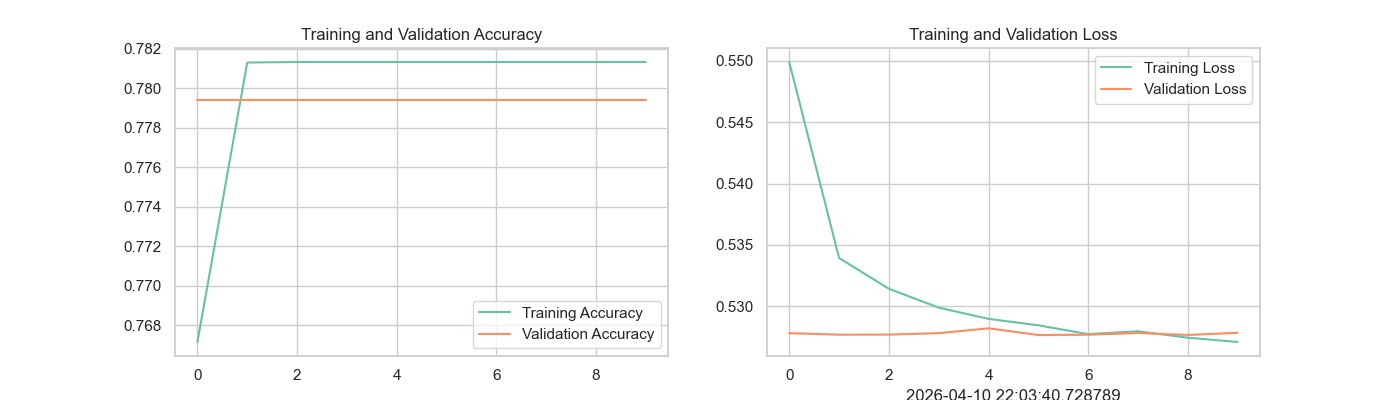
# ===================== 13. 模型训练效果可视化 =====================
# 从模型训练日志中提取:训练集准确率、验证集准确率
acc = model.history.history['accuracy']
val_acc = model.history.history['val_accuracy']
# 从模型训练日志中提取:训练集损失、验证集损失
loss = model.history.history['loss']
val_loss = model.history.history['val_loss']
# 定义训练轮数范围(10轮)
epochs_range = range(10)
# 创建画布,尺寸14x4英寸
plt.figure(figsize=(14, 4))
# 第一个子图:训练/验证准确率曲线
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy') # 训练准确率曲线
plt.plot(epochs_range, val_acc, label='Validation Accuracy') # 验证准确率曲线
plt.legend(loc='lower right') # 显示图例,位置右下角
plt.title('Training and Validation Accuracy') # 子图标题
# 第二个子图:训练/验证损失曲线
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss') # 训练损失曲线
plt.plot(epochs_range, val_loss, label='Validation Loss') # 验证损失曲线
plt.legend(loc='upper right') # 显示图例,位置右上角
plt.title('Training and Validation Loss') # 子图标题
plt.xlabel(nowtime)
# 显示训练曲线图表
plt.show()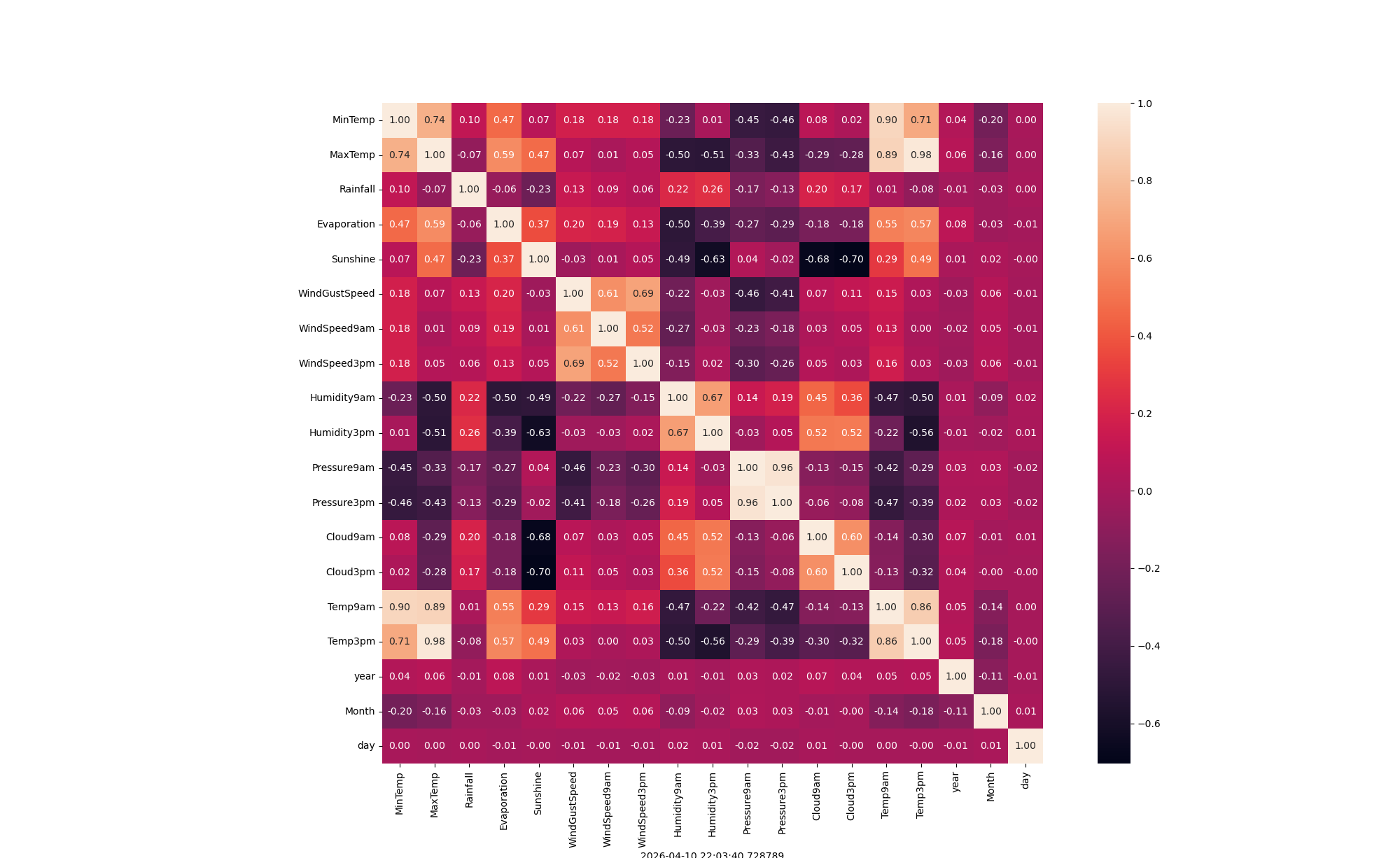
bash
3410/3410 [==============================] - 22s 6ms/step - loss: 0.5499 - accuracy: 0.7671 - val_loss: 0.5278 - val_accuracy: 0.7794
Epoch 2/10
3410/3410 [==============================] - 20s 6ms/step - loss: 0.5339 - accuracy: 0.7813 - val_loss: 0.5277 - val_accuracy: 0.7794
Epoch 3/10
3410/3410 [==============================] - 19s 6ms/step - loss: 0.5314 - accuracy: 0.7813 - val_loss: 0.5277 - val_accuracy: 0.7794
Epoch 4/10
3410/3410 [==============================] - 15s 4ms/step - loss: 0.5299 - accuracy: 0.7813 - val_loss: 0.5278 - val_accuracy: 0.7794
Epoch 5/10
3410/3410 [==============================] - 22s 6ms/step - loss: 0.5290 - accuracy: 0.7813 - val_loss: 0.5282 - val_accuracy: 0.7794
Epoch 6/10
3410/3410 [==============================] - 16s 5ms/step - loss: 0.5285 - accuracy: 0.7813 - val_loss: 0.5277 - val_accuracy: 0.7794
Epoch 7/10
3410/3410 [==============================] - 21s 6ms/step - loss: 0.5277 - accuracy: 0.7813 - val_loss: 0.5277 - val_accuracy: 0.7794
Epoch 8/10
3410/3410 [==============================] - 20s 6ms/step - loss: 0.5280 - accuracy: 0.7813 - val_loss: 0.5278 - val_accuracy: 0.7794
Epoch 9/10
3410/3410 [==============================] - 19s 5ms/step - loss: 0.5275 - accuracy: 0.7813 - val_loss: 0.5277 - val_accuracy: 0.7794
Epoch 10/10
3410/3410 [==============================] - 12s 4ms/step - loss: 0.5271 - accuracy: 0.7813 - val_loss: 0.5278 - val_accuracy: 0.7794