一,初步认识索引
大家要知道mysql需要实现的两个关键目标就是安全 和效率, 而索引就是提高效率的重要方法。使⽤索引的⽬的只有⼀个,就是提升数据检索的效率,在应⽤程序的运⾏过程中,查询操作的频率远远⾼于增删改的频率。
MySQL的索引是⼀种数据结构,它可以帮助数据库⾼效地查询、更新数据表中的数据。索引通过 ⼀定的规则排列数据表中的记录,使得对表的查询可以通过对索引的搜索来加快速度。
二,索引的数据结构选择
2.1 HASH(×)
时间复杂度为O(1),查询速度非常快,但不支持范围查找,所以未被使用
2.2 二叉树(×)
虽然中序遍历是一个有序数组,但最坏情况下时间复杂度为O(N),且节点个数过多无法保证树高(每次访问子节点都会发生一次磁盘IO,磁盘IO是数据库性能的瓶颈,减少IO可提升效率)
2.3 N叉树(×)
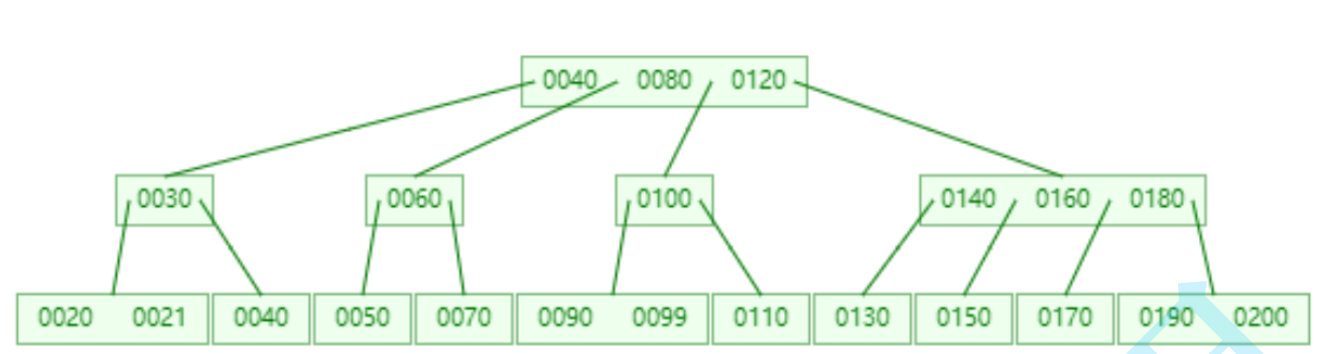
时间复杂度为O(logN)。相同数据量的情况下,N叉树的树⾼可以得到有效的控制,也就意味着在相同数据量的情况 下可以减少IO的次数,从⽽提升效率。但是MySQL认为N叉树做为索引的数据结构还不够好
2.4 B+树(√)

时间复杂度为O(logN)。
B+树特点:能够保持数据稳定有序,插⼊与修改有较稳定的时间复杂度
非叶子节点仅具有索引作⽤,不存储数据,所有叶子节点保真实数据
所有叶子节点构成⼀个有序链表,可以按照key排序的次序依次遍历全部数据
B+树和B树区别:
叶子节点中的数据是连续的,且相互链接,便于区间查找和搜索。
非叶子都包含在叶子节点中
对于B+树而言,在相同树高的情况下,查找任⼀元素的时间复杂度都⼀样,性能均衡
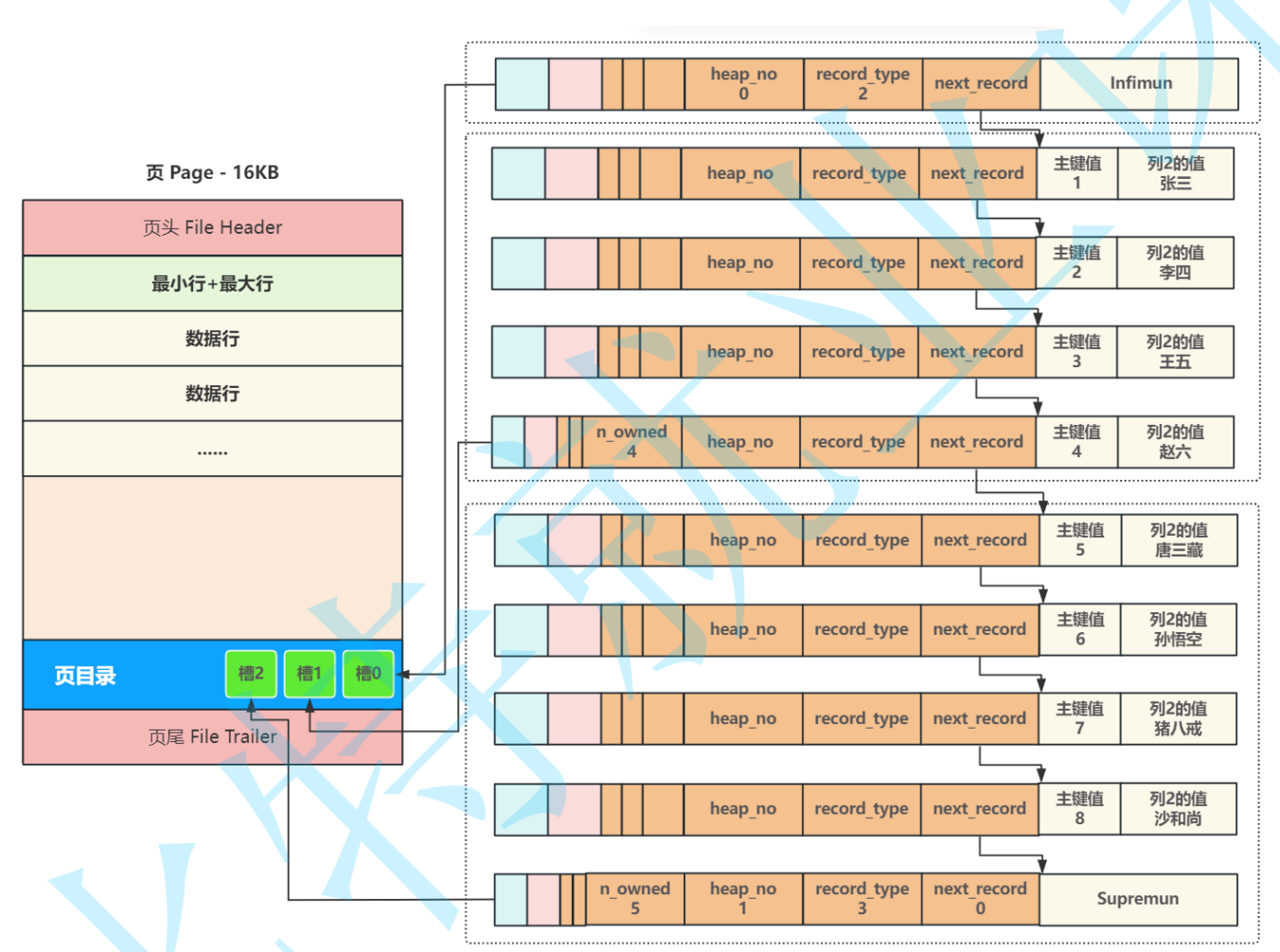
三,了解mysql中的页
在 .ibd 文件中最重要的结构体就是Page(页),页是内存与磁盘交互的最小单元,默认大小为
16KB,每次内存与磁盘的交互⾄少读取⼀页,所以在磁盘中每个页内部的地址都是连续的,之所
以这样做,是因为在使用数据的过程中,根据局部性原理,将来要使用的数据⼤概率与当前访问的
数据在空间上是临近的,所以⼀次从磁盘中读取⼀页的数据放⼊内存中,当下次查询的数据还在这
个页中时就可以从内存中直接读取,从而减少磁盘I/O提⾼性能。
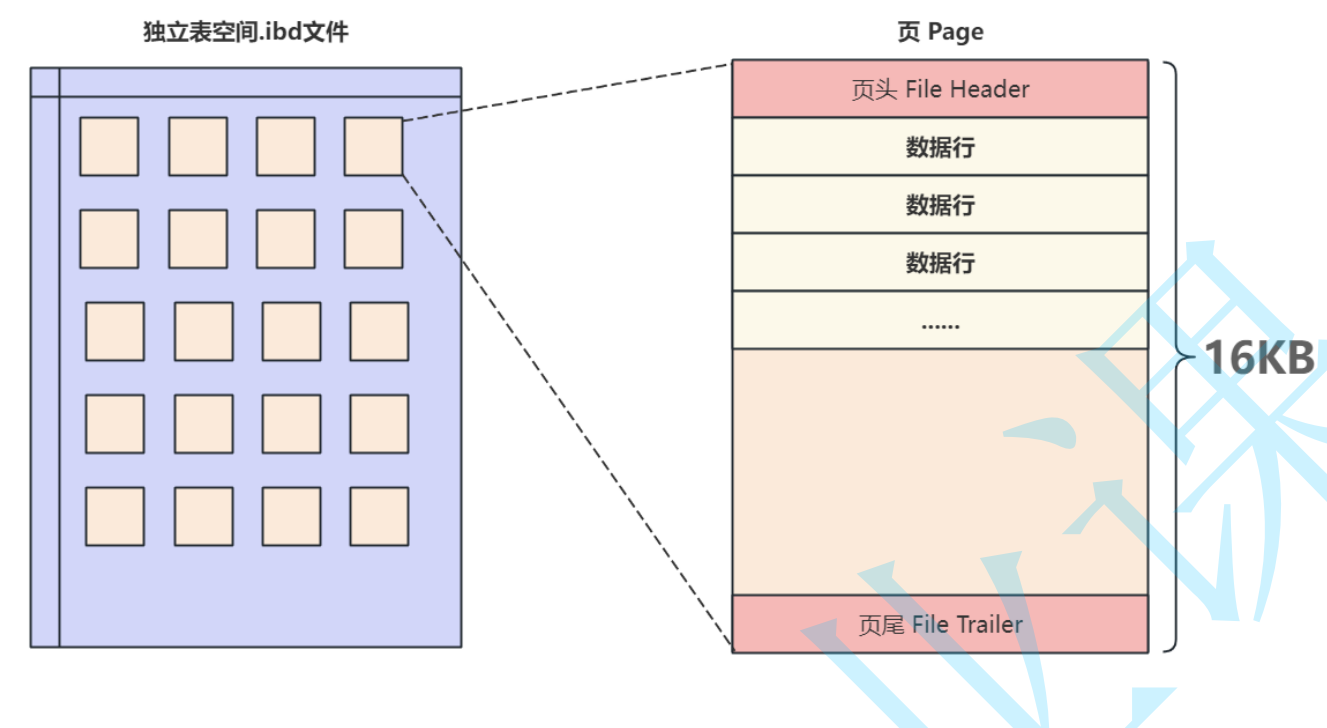
在MySQL中有多种不同类型的页,最常⽤的就是⽤来存储数据和索引的"索引页",也叫做"数据 页",但不论哪种类型的页都会包含页头(File Header)和页尾(File Trailer),页的主体信息使⽤数
据"行"进行填充,数据页的基本结构如下图所⽰:
页主体:
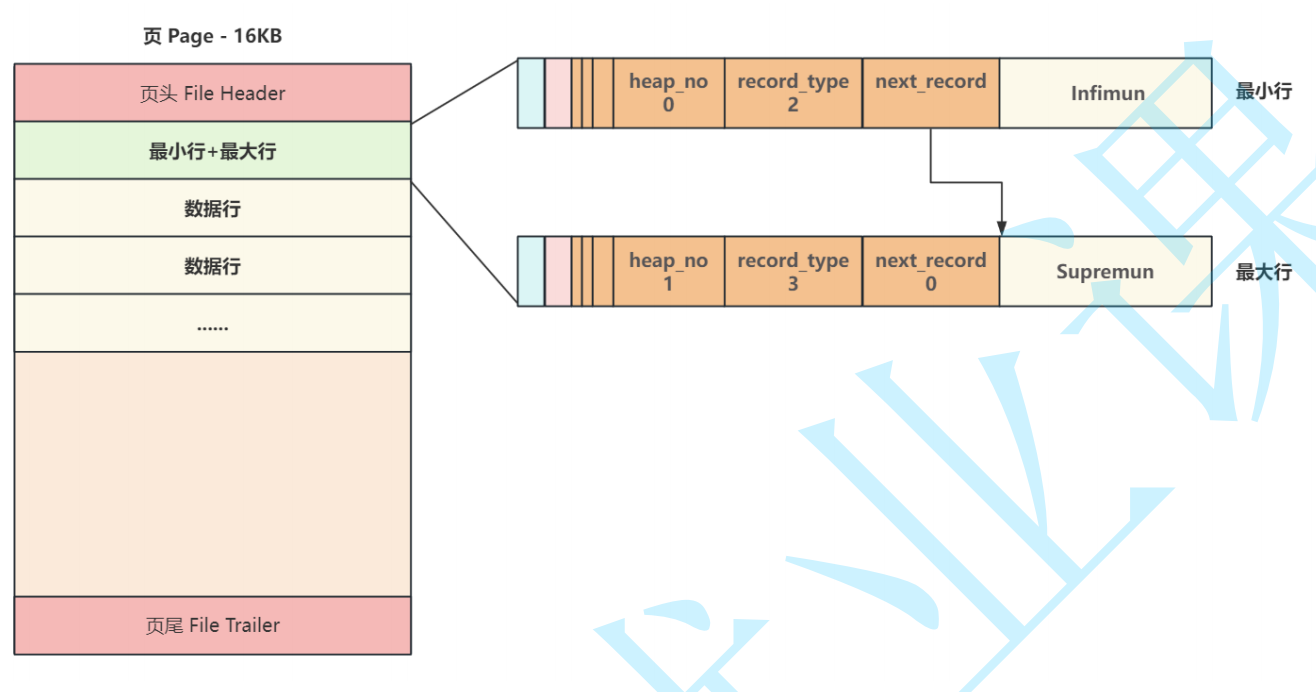
主体部分是保存真实数据的主要区域,每当创建⼀个新页,都会自动分配两个行,⼀个是页内最 小行Infimun ,另⼀个是页内最大行 Supremun ,这两个行并不存储任何真实信息,而是做为数据行链表的头和尾,第⼀个数据⾏有⼀个记录下⼀⾏的地址偏移量的区域 next_record 将页内所有数据行组成了⼀个单向链表,此时新页的结构如下::
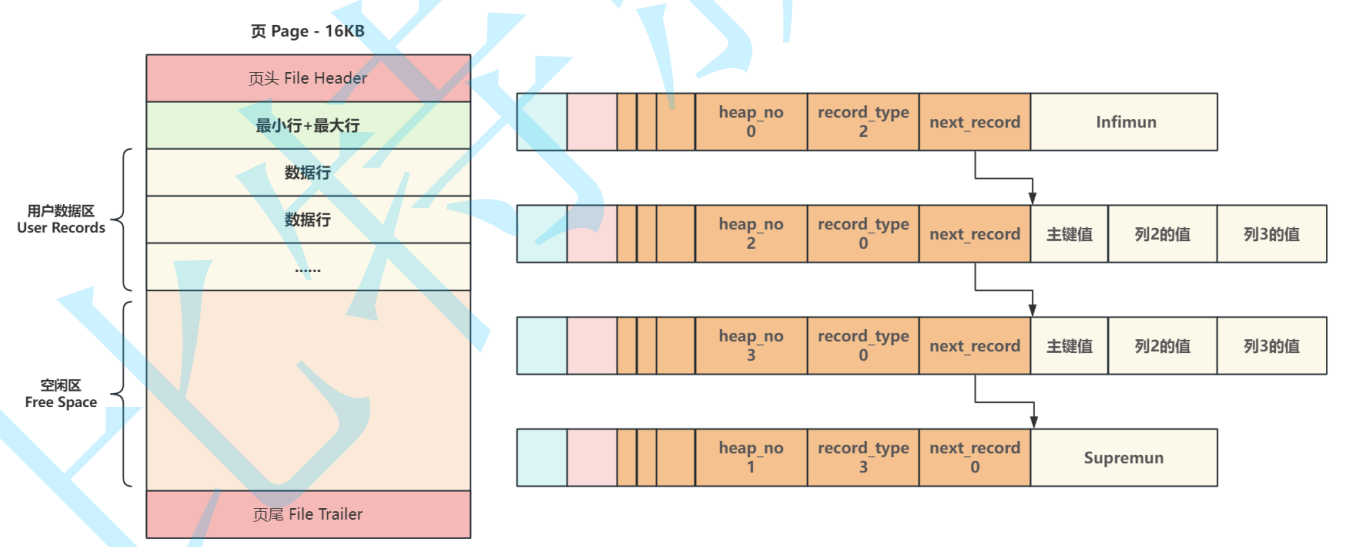
当向⼀个新页插⼊数据时,将 Infimun 连接第⼀个数据行,最后一行真实数据行连接 Supremun ,这样数据行就构建成了⼀个单向链表,更多的⾏数据插入后,会按照主键从小到大的顺序进行链接,如下图所示
页目录
当按主键或索引查找某条数据时,最直接简单的方法就是从头行infimun 开始,沿着链表顺序逐
个比对查找,但⼀个页有16KB,通常会存在数百行数据,每次都要遍历数百行,无法满足高效效查询,为了提高查询效率,InnoDB采用二分查找来解决查询效率问题;
具体实现:在每⼀个页中加如一个叫做页目录 Page Directory 的结构,将页内包括头行、尾行在内的所有行进行分组,约定头行单独为⼀组,其他每个组最多8条数据,同时把每个组
最后一行在页中的地址,按主键从小到大的顺序记录在页目录中在,页目录中的每⼀个位置称为⼀
个槽,每个槽都对应了⼀个分组,⼀旦分组中的数据行超过分组的上限8个时,就会分裂出⼀个新
的分组;
后续在查询某行时,就可以通过⼆分查找,先找到对应的槽,然后在槽内最多8个数据行中进行遍
历即可,从而大幅提高了查询效率,这时⼀个页的核心结构就完成了;
四,索引分类
4.1 主键索引
------ 当在⼀个表上定义⼀个主键 PRIMARY KEY 时,InnoDB使用它作为聚集索引。
------ 推荐为每个表定义⼀个主键。如果没有逻辑上唯⼀且⾮空的列或列集可以使用主键,则添加⼀个自增列。
4.2 普通索引
------最基本的索引类型,没有唯⼀性的限制。可包含一个列也可包含多个列,为提升查询效率,工作中常为查询频率高的列创建索引,列的值重复度不高
------可能为多列创建组合索引,称为复合索引或组全索引(创建后会生成一棵索引树,创建多少索引生成多少索引树,生成的索引树也占磁盘空间,故创建时慎重考虑是否真的需要,索引树越多,对增删改效率影响越大)
4.3 唯一索引
------当在⼀个表上定义⼀个唯⼀键 UNQUE 时,自动创建唯⼀索引。
------与普通索引类似,但区别在于唯⼀索引的列不允许有重复值。
4.4 全文索引
------基于文本列(CHAR、VARCHAR或TEXT列)上创建,以加快对这些列中包含的数据查询和DML操作
------用于全文搜索,仅MyISAM和InnoDB引擎⽀持。
4.5 聚集索引
------与主键索引是同义词
------如果没有为表定义 PRIMARY KEY, InnoDB使用第⼀个 UNIQUE 和 NOT NULL 的列作为聚集索引。
------如果表中没有 PRIMARY KEY 或合适的 UNIQUE 索引,InnoDB会为新插⼊的⾏⽣成⼀个⾏号并用6字节的 ROW_ID 字段记录, ROW_ID 单调递增,并使⽤ ROW_ID 做为索引。
4.6 非聚集索引
------聚集索引以外的索引称为⾮聚集索引或⼆级索引
------二级索引中的每条记录都包含该⾏的主键列,以及⼆级索引指定的列。
------InnoDB使⽤这个主键值来搜索聚集索引中的⾏,这个过程称为回表查询
4.7 索引覆盖
------当⼀个select语句使⽤了普通索引且查询列表中的列刚好是创建普通索引时的所有或部分列,这时就可以直接返回数据,⽽不⽤回表查询,这样的现象称为索引覆盖
五,使用索引
5.1 自动创建
当我们为⼀张表加主键约束(Primary key),外键约束(Foreign Key),唯⼀约束(Unique)时,
MySQL会为对应的的列自动创建⼀个索引。如果表不指定任何约束时,MySQL会自动为每一列生成⼀个索引并用 ROW_ID 进行标识
5.2 手动创建
5.2.1 主键索引
# ⽅法⼀,创建表时创建主键
create table t1 (
id bigint primary key auto_increment,
name varchar(20)
);
# ⽅法⼆,创建表时单独指定主键列
create table t2 (
id bigint auto_increment,
name varchar(20),
primary key (id)
);
# ⽅法三,修改表中的列为主键索引
create table t3 (
id bigint,
name varchar(20)
);
alter table t3 add primary key (id) ;
alter table t3 modify id bigint auto_increment;5.2.2 唯一索引
# ⽅法⼀,创建表时创建唯⼀键
create table t1 (
id bigint primary key auto_increment,
name varchar(20) unique
);
# ⽅法⼆,创建表时单独指定唯⼀列
create table t2 (
id bigint primary key auto_increment,
name varchar(20),
unique (name)
);
# ⽅法三,修改表中的列为唯⼀索引
create table t3 (
id bigint primary key auto_increment,
name varchar(20)
);
alter table t3 add unique(name);5.2.3 普通索引
# ⽅法⼀,创建表时指定索引列
create table t1 (
id bigint primary key auto_increment,
name varchar(20) unique
sno varchar(10),
index(sno)
);
# ⽅法⼆,修改表中的列为普通索引
create table t2 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10)
);
alter table t2 add index (sno) ;
# ⽅法三,单独创建索引并指定索引名
create table t3 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10)
);
create index idx_t3_sno on t3(sno);六,创建复合索引
# ⽅法⼀,创建表时指定索引列
create table t1 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10),
class_id bigint,
index (sno, class_id)
);
# ⽅法二,修改表中的列为复合索引
create table t2 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10),
class_id bigint
);
alter table t2 add index (sno, class_id);
# ⽅法三,单独创建索引并指定索引名
create table t3 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10),
class_id bigint
);
create index idx_t3_sno_classid on t3 (sno, class_id);七,查看索引
方法一:show keys from 表名
方法二:show index from 表名;
方法三:desc 表名;
八,删除索引
8.1 删除主键索引
alter table 表名 drop primary key;
8.2 删除其他索引
alter table 表名 drop index 索引名;
九,小结
这期也是拖了挺久的,只想着赶紧往后学新的东西,都忘记复盘了,三天之内必须吧事务+jdbc整理出来。感觉还有好多东西自己还差好多,有点心累,要对老己差一点了,上上压力。我想去pdd或者百度上班,我一定要去pdd或者百度上班,哪怕是扫地。如果方便的话请各位大哥大姐弟弟妹妹给我点点赞,谢谢啦。每次文章中涉及到的图片,都是我从课件上截下来的,也没去水印,因为个人能力有限,而我了解这部分知识也是通过这个图,感觉很清楚很好,就直接截过来了,大家见谅哈,如有问题可以私信我一起讨论