引言
plain
## 内部深度思考(Step 1)
### 输入输出是什么?
- **输入**:一个 AWorld Agent 对象(含 MCP 工具配置、系统提示)+ Parquet/HuggingFace 数据集 + 一个奖励函数(Python 可调用对象或文件路径)+ YAML 训练配置
- **输出**:一个经过 GRPO 算法强化学习训练后的、具备更好 Agent 推理能力的 LLM 模型 checkpoint
### 最核心的难点在哪里?
1. **训练框架与 Agent Runtime 的解耦鸿沟**:VeRL 的训练 loop 是一个 C++/Python 混合的分布式系统(actor、rollout、reference model 分布在不同进程),而 AWorld 的 Agent 是一个高层次的异步 Python 框架,两者之间的通信协议完全不同。
2. **多轮 Tool Call 轨迹的正确 Tokenization**:Agent 执行一个任务会产生多轮对话(User→Assistant→Tool→Assistant→...),训练时必须正确地区分哪些 token 是"模型的行为"(应该计算梯度)、哪些是"环境反馈"(不计算梯度)。这需要精心设计 `response_mask`。
3. **动态代码生成的工程挑战**:用户的 Agent 对象配置多样(自定义工具、MCP 配置、自定义类型),需要把一个 Python 对象"序列化"成一段可在 VeRL 分布式环境中被反序列化执行的代码。
4. **奖励函数的规范化验证**:VeRL 要求奖励函数必须有严格的签名格式,需要在运行前做反射检查。
### 作者用了什么巧妙的 Engineering Trick?
1. **代码生成 (Code Generation) 作为序列化手段**:`check_agent()` 不做对象序列化(pickle 在多进程中有诸多限制),而是直接使用 `VERL_TEMPLATE` 字符串模板,把用户的 Agent 参数"烘焙"成一段新的 Python 源代码(`VerlAgentLoop`),然后写入磁盘,VeRL 通过文件路径加载这个类。这是本方案最精妙的 Engineering Trick。
2. **response_mask 的精细控制**:`encode_messages()` 函数通过逐条解析 message 的 role,给 assistant 消息赋 mask=1,给 tool 响应和 user 消息赋 mask=0,这样梯度只流经模型的决策行为,而不会误训练到环境反馈。
3. **Hermes Tool Parser 的 token-level 解析**:VerlProvider 直接在 token IDs 层面(而非文本层面)解析工具调用,避免了解码→解析→再编码的损耗,也避免了 Unicode 截断等问题。
4. **超时降级策略**:`run_agents()` 设置 1200s 超时,超时后返回一个预定义的"Timeout"轨迹,保证训练不会因为单个任务卡死而崩溃。
5. **OmegaConf 双层合并**:训练配置采用 VeRL 默认 `_generated_ppo_trainer.yaml` 作为基础,用户 YAML 通过 `OmegaConf.merge()` 进行覆盖,实现了"用户只写差异配置"的最小化配置设计。
### 合理推测(原文缺失部分)
- 核心 `aworld` 包(Agent、Swarm、Runners)的实现不在本仓库,推测基于 OpenAI 协议的 LLM 调用 + 异步 asyncio event loop 实现 Agent 循环。
- `CapabilityOntology` 推测使用图结构(TreeNode)来组织工具类别→能力→具体工具的三层层次,类似于领域本体论(Ontology)的 is-a 关系树。
- VeRL 的 `AgentLoopBase` 推测是 VeRL 0.5.0.dev0 版本新引入的实验性接口,专门为了支持 Agent 训练(区别于标准 RL 的单步生成)。Step 1: 项目全局视角 (Overview)
业务痛点
在 LLM Agent 领域,当前存在一个巨大的鸿沟:研究人员可以用 VeRL、TRL 等框架训练 LLM,但这些框架对"Agent 行为"的感知几乎为零。它们只知道 token 序列,不知道什么是"工具调用"、什么是"多轮对话"、什么是"任务完成"。
另一方面,开发者可以用 LangChain、AWorld 等框架构建 Agent,但这些 Agent 框架完全不具备训练能力。
AWorld Train 要解决的核心矛盾:"会构建 Agent 的人不会训练,会训练 LLM 的人不懂 Agent"。
核心价值主张 :让用户只需提供
Agent对象 + 数据集 + 奖励函数 + 配置,系统自动完成 Agent Runtime ↔ RL Training Framework 之间的全部"翻译"工作。
核心指标与赛道定位
- 目标任务:GAIA Benchmark(通用 AI Agent 评测,要求 Agent 在真实世界任务中综合使用工具)
- 训练算法:GRPO(Group Relative Policy Optimization)------DeepSeek-R1 同款算法
- 基础模型:Qwen/Qwen3-32B(配置文件中明确指定)
- 训练规模:8×GPU,FSDP2 + 8路 Ulysses 序列并行,bf16
该方案脱颖而出的"胜负手"
| 胜负手 | 技术实现 |
|---|---|
| 零代码对接 RL 框架 | 动态代码生成:Python 对象 → Python 源代码 → VeRL 类加载 |
| 精准的训练信号 | response_mask 只覆盖模型决策,排除工具反馈 |
| 完整的 Agent 生态 | MCP 协议支持 19+ 种工具(浏览器、PDF、代码执行等) |
| 自进化闭环 | EvolutionRunner:数据合成 → 训练 → 评估 → 人工确认 的完整 loop |
Step 2: 核心架构深度拆解
系统整体架构
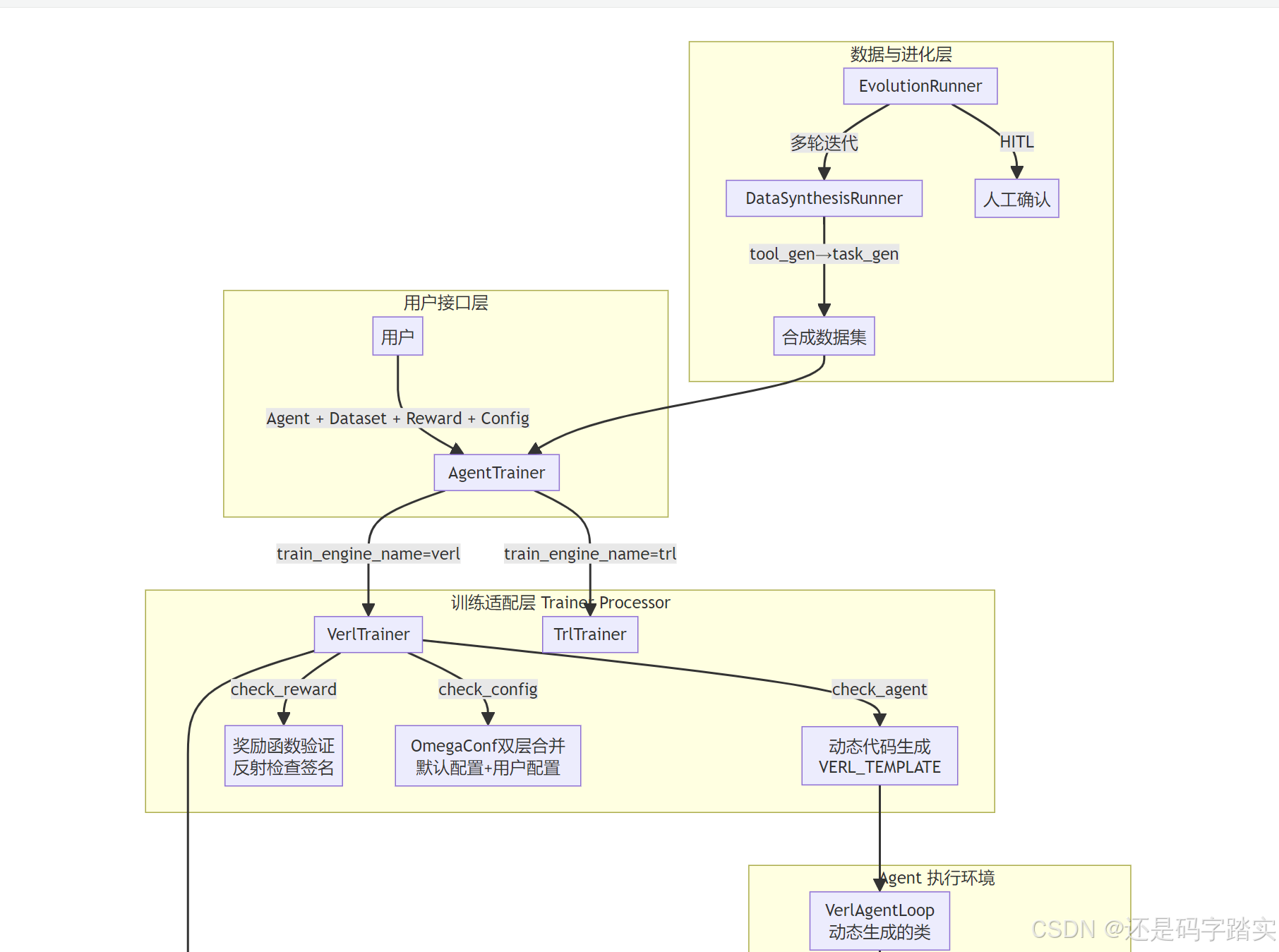
核心模块一:AgentTrainer 统一门面
What :一个对用户暴露的统一训练 API,背后通过 **TRAIN_PROCESSOR**** **字典路由到不同的训练框架实现。
Why :框架无关设计(Framework-Agnostic Design)。今天支持 VeRL/TRL,明天可以 register_processor("areal", ArealTrainer) 一行代码扩展到 AReaL,用户代码无需改变。
How:
python
# train/trainer/agent_trainer.py --- 核心初始化逻辑(精简注释版)
class AgentTrainer:
def __init__(self, agent, config, reward_func, train_dataset,
test_dataset, run_path=None, train_engine_name='verl'):
# 1. 从注册表获取后端 Processor 类
engine_cls = TRAIN_PROCESSOR.get(train_engine_name)
train_engine = engine_cls(self.run_path)
# 2. 按顺序检查并处理四大核心模块
# 注意:顺序很重要!check_agent 必须在 check_config 之前
# 因为 check_agent 会生成 agent_yaml 文件路径
# check_config 会把这个路径写入配置
train_engine.check_agent(agent=agent) # → 生成 VerlAgentLoop 代码文件
train_engine.check_dataset(...) # → 转换为 Parquet 格式
train_engine.check_reward(reward_func=...) # → 反射验证签名
train_engine.check_config(config=config) # → OmegaConf 合并,填充动态路径
train_engine.mark_initialized()关键设计细节 :四个 check_* 方法存在隐式依赖顺序 ------check_agent 在内存中写入 self.agent_yaml,check_config 读取它。这是一个轻微的代码异味(implicit coupling),但工程上简洁有效。
核心模块二:动态代码生成(最精妙的 Engineering Trick)
这是整个框架最硬核的设计,值得反复咀嚼。
What :VerlTrainer.check_agent() 将一个运行时的 Python Agent 对象"序列化"为一段 Python 源代码字符串,写入磁盘,供 VeRL 分布式系统加载。
Why :VeRL 是一个分布式训练系统,actor 进程、rollout 进程、reward 进程运行在不同机器的不同进程中。Python 的 pickle 序列化在跨进程时限制很多(lambda 无法序列化、自定义类需要在目标进程可导入)。用**代码文件**作为进程间共享 Agent 配置的载体,比对象序列化更稳健。
How(完整流程):
python
# 第一步:从 Agent 对象提取所有参数,填入模板字符串
con = VERL_TEMPLATE.format(
agent_name=agent.name(), # "gaia_agent"
system_prompt=agent.system_prompt,
mcp_config=agent.mcp_config, # {"mcpServers": {...}} 直接 repr 写入代码
tool_names=agent.tool_names,
model_kv_parameters=model_kv_parameters, # "top_k=80," 等参数
parser_module=type(agent.output_converter).__module__,
...
)
# 第二步:将生成的 Python 代码写入磁盘
with open(f"{self.run_path}/{agent.name()}.py", 'w+') as write:
write.writelines(con)
# 第三步:生成 VeRL agent.yaml 指向这个动态生成的类
con = f"""- name: {agent.name()}
_target_: {module}.VerlAgentLoop
"""
with open(f"{self.run_path}/agent.yaml", "w+") as write:
write.writelines(con)生成的代码(**VERL_TEMPLATE**** **实例化后)长这样:
python
# 这是运行时动态生成的文件,不是手写的!
class VerlAgentLoop(AworldAgentLoop):
async def build_agents(self) -> Union[Agent, Swarm]:
conf = AgentConfig(
llm_config=ConfigDict(
llm_model_name=await self.get_llm_server_model_name(),
llm_base_url=await self.get_llm_server_address(),
llm_api_key="123", # VeRL 内部 vLLM,无需真实 key
llm_provider="verl", # 注册的自定义 Provider
params={
'client': self.server_manager, # VeRL vLLM 客户端
"tokenizer": self.tokenizer,
"request_id": uuid.uuid4().hex,
"tool_parser": "hermes" # Hermes 格式工具解析
},
top_k=80, # 从 model_kv_parameters 注入
),
)
mcp_config = {"mcpServers": {"gaia_server": {...}}} # 烘焙进代码的配置
return Agent(
conf=conf,
name="gaia_agent",
system_prompt="Gaia agent",
mcp_config=mcp_config,
mcp_servers=["gaia_server"],
...
)这段代码在 VeRL 的** rollout 进程**中被执行,每次 run() 被调用时,它会:
- 从 VeRL 的
server_manager获取当前 vLLM 服务地址 - 构建 AWorld Agent,将 VeRL 的 vLLM 客户端注入为 LLM Provider
- 执行 Agent 任务,采集轨迹
这本质上是一种**依赖注入(Dependency Injection)通过代码生成实现的变体****。**
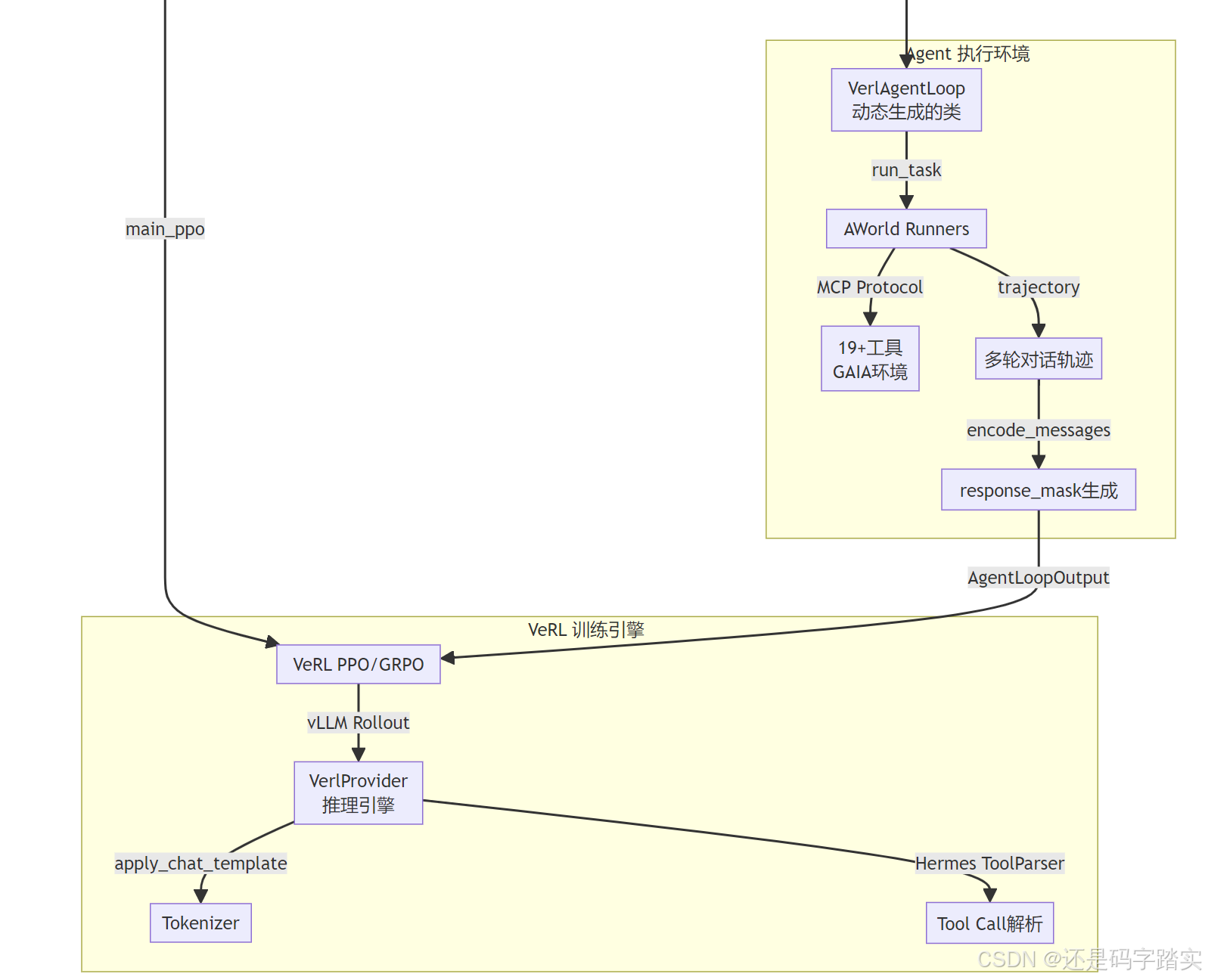
核心模块三:VerlProvider --- 打通 Agent 与 vLLM 的毛细血管
What :一个实现了 **LLMProviderBase**** **接口的 VeRL 专属 LLM 提供者,把 AWorld Agent 对 LLM 的调用请求转发给 VeRL 内部的 vLLM Rollout 服务。
Why :AWorld Agent 依赖一个 LLMProviderBase 来做推理,通过注册自定义 Provider(register_llm_provider("verl", VerlProvider)),可以在不修改 Agent 核心逻辑的前提下,把推理后端替换为 VeRL 的分布式 vLLM 服务。
How (acompletion 方法的完整执行链路):
plain
Step 1: messages + tools → tokenizer.apply_chat_template()
(在线程池执行器中异步调用,避免阻塞 async event loop)
→ 得到 prompt_ids: List[int]
Step 2: prompt_ids → vllm_client.generate(request_id, prompt_ids, sampling_params)
(VeRL 的 vLLM Actor 服务)
→ 得到 response_output.token_ids: List[int]
Step 3: response_output.token_ids → tokenizer.decode()
→ 得到 decoded_content: str
Step 4: response_output.token_ids → ToolParser.extract_tool_calls(token_ids)
(Hermes格式解析,token-level操作)
→ 得到 (content, function_calls)
Step 5: function_calls → JSON 验证 → ToolCall 对象列表
Step 6: 返回 ModelResponse(content, tool_calls, usage)关键工程细节 :Step 4 在 token IDs 层面 解析工具调用,而非文本层面。这样做的好处是可以精确定位工具调用的 token 边界 ,便于后续在
encode_messages中正确分割response_ids。
超时降级策略:
python
# 生产级容错设计:推理超时不崩溃,返回预定义响应
except asyncio.TimeoutError:
decoded_content = "Request timed out. Please try again."
class DefaultResponse:
def __init__(self, tokenizer, content):
self.token_ids = tokenizer.encode(content, add_special_tokens=False)
response_output = DefaultResponse(self.tokenizer, decoded_content)核心模块四:AworldAgentLoop --- 轨迹采集与转换引擎
What :继承 VeRL 的 AgentLoopBase,在 VeRL 的** rollout 阶段**执行 AWorld Agent 任务,并将多轮对话轨迹转换为 VeRL 训练所需的 AgentLoopOutput(prompt_ids, response_ids, response_mask)。
这是整个框架中技术密度最高的组件。
轨迹采集(run_agents)
python
async def run_agents(self, input, agent):
task = Task(
id=str(uuid.uuid4()),
input=input, # 来自数据集的问题文本
timeout=1200, # 20分钟超时,GAIA 任务可能很复杂
agent=agent
)
# 预设超时轨迹(降级策略)
resp = TaskResponse(id=task.id, trajectory=[{
"exp_data": {
"messages": [
{"role": "user", "content": str(input)},
{"role": "assistant", "content": "Timeout, please try again."}
],
"actions": []
}
}])
try:
return await asyncio.wait_for(run(task), timeout=task.timeout)
except asyncio.TimeoutError:
return resp # 超时返回降级轨迹,训练不中断轨迹转换(convert_agent_output → encode_messages)
这是整个框架最精密的核心算法,用于**将多轮对话轨迹转换为 VeRL 训练格式**。
python
# train/integration/common.py --- encode_messages(加满注释的研究版)
async def encode_messages(tokenizer, messages, response_length=128000, tools=None):
"""
将多轮 Agent 对话转换为 (prompt_ids, response_ids, response_mask)
核心设计:
- prompt_ids:第一轮 [system + user] 的 token ids
- response_ids:后续所有 token ids(含工具调用、工具结果、用户追问、助手回复)
- response_mask:1=模型生成(需要计算梯度);0=环境输入(不计算梯度)
示例对话与掩码:
[system] → 加入 prompt_ids(首次处理)
[user-turn1] → prompt_ids(首次 user)
[assistant] → response_ids, mask=1 ← 模型的决策,训练目标!
[tool] → response_ids, mask=0 ← 工具执行结果,不训练
[user-turn2] → response_ids, mask=0 ← 后续用户输入,不训练
[assistant] → response_ids, mask=1 ← 再次是模型决策
"""
i = 0
while i < len(messages):
role = messages[i].get("role")
if role == "system":
chat_list.append(messages[i])
i += 1
continue
if role == "user":
if i == 0 or messages[i-1].get("role") == "system":
# 第一个 user 消息 → 作为 prompt
prompt_ids = tokenizer.apply_chat_template(
chat_list + [messages[i]],
tools=tools, # 工具定义放在 prompt 中
add_generation_prompt=True,
tokenize=True
)
else:
# 后续 user 消息(多轮追问)→ response,但 mask=0
cur_ids = tokenizer.apply_chat_template(...)
response_ids += cur_ids
response_mask += [0] * len(cur_ids) # ← 不训练用户输入
i += 1
continue
if role == "assistant":
cur_ids = tokenizer.apply_chat_template(
[messages[i]],
add_generation_prompt=False,
tokenize=True
)
response_ids += cur_ids
response_mask += [1] * len(cur_ids) # ← 这是训练目标!
i += 1
continue
if role == "tool":
# 工具结果:需要先编码"含工具调用的 assistant 消息"
# 然后编码"assistant + tool 结果"
# 差集 = 纯工具结果的 token ids
token_assistant = tokenizer.apply_chat_template([last_assistant] + chat_list, ...)
while messages[i].get("role") == "tool":
chat_list.append(messages[i])
i += 1
token_assistant_tool = tokenizer.apply_chat_template(...)
tool_response_ids = token_assistant_tool[len(token_assistant):] # 差集!
response_ids += tool_response_ids
response_mask += [0] * len(tool_response_ids) # ← 工具结果不训练为什么用差集(token_assistant_tool - token_assistant)来提取工具结果的 token ids?
因为 apply_chat_template 会把上下文拼接并添加特殊 token,直接对工具消息单独 tokenize 会缺少上下文导致特殊 token 不一致。用**"带 assistant 的完整序列"减去"仅 assistant 序列"**,得到的差集精确对应工具结果部分的 token,是一个非常巧妙的工程技巧。
核心模块五:GAIA 奖励函数 --- 精确奖励信号设计
What:一个二值奖励函数(0或1),专为 GAIA 基准测试设计。
Why:GAIA 任务的答案可以是数字、字符串或逗号分隔的列表。简单的字符串匹配会因为格式差异(1,000 vs 1000,大小写,空格)漏判正确答案。
How:
python
def gaia_reward_func(data_source, solution_str, ground_truth, extra_info=None):
# 第一关:用正则提取 <answer>...</answer> 标签
# 如果模型没有按格式输出,直接返回 0
pattern = r'<answer>(.*?)</answer>'
comp_match = re.search(pattern, solution_str, re.DOTALL | re.MULTILINE)
if not comp_match:
return 0.0 # 格式违规,不奖励
comp_answer = comp_match.group(1).strip()
return 1.0 if question_scorer(comp_answer, ground_truth) else 0.0
def question_scorer(model_answer, ground_truth):
# 三层判断逻辑
if is_float(ground_truth):
# 数字类型:去掉 $, %, , 后比较浮点数
return normalize_number_str(model_answer) == float(ground_truth)
elif any(char in ground_truth for char in [",", ";"]):
# 列表类型:按分隔符拆分,逐元素比较
gt_elems = split_string(ground_truth)
ma_elems = split_string(model_answer)
if len(gt_elems) != len(ma_elems):
return False
return all(...)
else:
# 字符串类型:去空格、去标点、转小写后比较
return normalize_str(model_answer) == normalize_str(ground_truth)训练信号的双重约束 :奖励函数要求模型**既要使用
<font style="color:#DF2A3F;"><answer></font>标签格式**(格式奖励),**又要答对内容**(结果奖励)。这两个约束通过 GRPO 的 Group-level 相对优势自动权衡,无需手动调参。
核心模块六:DataSynthesisRunner --- 本体论驱动的数据合成
这是 AWorld 生态中最具研究价值的组件之一。
What:一个自动化的训练数据生成 pipeline,不需要人工标注,通过 LLM 生成**工具定义和对应的任务-答案对。**
Why:GAIA 等高质量 benchmark 数据集有限,模型自进化需要更多样化的训练样本。通过从**"能力本体论"**出发合成数据,可以控制数据的多样性和复杂度分布。
How (三阶段 pipeline):
plain
阶段一:Tool Synthesis(工具合成)
CapabilityOntology.build()
→ 构建能力分类树(类别→能力→具体规格)
→ OntologyOperator.single_capability(cate, ability)
→ ToolGeneratorAgent(LLM生成工具定义)
→ ToolRepository.save_to_json("tools.jsonl")
阶段二:Task Synthesis(任务合成)
ToolSelectAgent 选择相关工具组合
→ ToolOrchestratorAgent 规划任务步骤
→ TaskGeneratorAgent 生成 {task: "...", answer: "..."} 对
→ 9:1 切分 train/test
阶段三:Training(训练)
jsonlines → DataFrame → Parquet (VeRL格式)
或直接写 jsonlines (TRL格式)关键设计 :使用 asyncio.Event 实现 Tool Synthesis 和 Task Synthesis 的异步流水线 :工具合成完成后 tool_gen_event.set(),任务合成等待 await tool_gen_event.wait() 后立即开始,两者可以并行(工具合成产出批次后,任务合成可以开始消费)。
核心模块七:EvolutionRunner --- 自进化闭环
What:一个高层次的元级 Runner,实现**"任务描述 → 训练 → 评估 → 再训练"**的完整自进化循环。
Why:Agent 能力提升是一个迭代过程,需要不断根据评估结果调整训练数据和策略,而不是一次性训练后完事。
How:
plain
Step 1: EvolutionPipelineAgent(LLM规划)
input: "我想让 Agent 会做 xxx"
output: 进化计划 JSON {task, config, process_tasks}
→ 写入 evolve_config.yaml
Step 2: Human-in-the-Loop(可选)
await human_confirm("请检查生成的计划...")
→ exec_tool(HUMAN, "HUMAN_CONFIRM", ...)
Step 3: 多轮迭代(max_epoches 次)
for epoch in range(epoches):
data_synthesis() # 合成训练数据
train() # AgentTrainer.train()
evaluation() # trainer.inference() → 评估指标
human_confirm() # 人工审核结果(可选)HITL(Human-in-the-Loop)设计 :三个关键检查点都支持人工干预,hitl_plan(计划审核)和 hitl_all(每步审核)通过配置开关控制,执行时调用 HUMAN 工具暂停流程等待人工输入。
训练配置深度解读(grpo_trainer.yaml)
yaml
actor_rollout_ref:
model:
path: Qwen/Qwen3-32B
use_remove_padding: true # 去除 padding,节省显存
enable_gradient_checkpointing: true # 梯度检查点,以时间换显存
use_fused_kernels: true # FlashAttention 等融合算子
actor:
clip_ratio_low: 0.2 # PPO clip 下界
clip_ratio_high: 0.28 # PPO clip 上界(非对称裁剪,防止过激更新)
clip_ratio_c: 10.0 # GRPO 特有的超高裁剪上界(缓解奖励稀疏)
optim:
lr: 0.000006 # 6e-6,非常保守的学习率,防止遗忘
ulysses_sequence_parallel_size: 8 # 8路序列并行(处理超长上下文)
strategy: fsdp2 # PyTorch FSDP2 分片策略
fsdp_config:
param_offload: true # 参数卸载到 CPU(省 GPU 显存)
optimizer_offload: true # 优化器状态卸载(Adam 状态很大)
rollout:
name: vllm
mode: async # 异步 rollout(与 actor 训练并行)
n: 8 # GRPO:每个 prompt 生成 8 个候选答案
response_length: 8192 # 单次最大生成 8192 tokens
tensor_model_parallel_size: 8 # 8路张量并行(32B 模型需要)
multi_turn:
enable: false # 注意:这里 false!因为 Agent Loop 自己处理多轮
format: hermes # 工具调用格式:Hermes(NousResearch 格式)
algorithm:
adv_estimator: grpo # GRPO,而非 GAE(PPO默认)
use_kl_in_reward: false # 不把 KL 散度加入奖励(纯任务奖励)
kl_ctrl:
kl_coef: 0.0 # KL 系数为 0,完全依赖 clip 来控制策略变化关键细节 :rollout.multi_turn.enable: false 但 format: hermes。这是因为 AWorld 的 Agent Loop 自己处理了多轮交互 (通过 AworldAgentLoop.run()),不需要 VeRL 原生的多轮机制。但 Hermes 格式仍然需要指定,因为 VerlProvider 用它解析工具调用。
Step 3: 大白话费曼延伸
核心机制类比一:动态代码生成 ↔ 餐厅"代厨协议"
想象一个高端餐厅(VeRL 训练框架)和一位外来厨师(AWorld Agent)的合作。
餐厅有自己严格的出餐流程、厨房设备和计时系统,外来厨师的做菜方式、用料习惯(MCP 工具配置、系统提示等)和餐厅完全不同。
传统方案(直接对接):让外来厨师完全按餐厅流程重新学做菜 → 太复杂,完全不现实。
AWorld 方案(动态代码生成) :餐厅给外来厨师一份****"协议菜谱模板"****(VERL_TEMPLATE),外来厨师把自己的秘方(mcp_config、system_prompt、top_k=80)填进模板里,生成一份专属于自己、但完全符合餐厅流程的标准菜谱 (VerlAgentLoop 代码文件),放到餐厅档案柜里(写入磁盘)。
餐厅的出餐系统(VeRL 分布式进程)按需从档案柜取出这份菜谱执行,完全不需要知道这是**"动态生成"**的,以为是手工写的标准流程。
核心机制类比二:response_mask ↔ 法庭速记员的"选择性记录"
Agent 执行一个任务的过程就像一场法庭审判:
- 法官问话(User):速记员记录,但这不是判决,不需要"反思学习"
- 律师发言(Assistant) :速记员重点标记!这是要被评判的,是训练目标(
mask=1) - 证人证词(Tool Response) :速记员记录,但这是外部事实,不是律师的决策(
mask=0) - 律师再次发言(Assistant) :又一次重点标记(
mask=1)
最后法院(RL 算法)只针对**"律师发言"部分评分和调整策略,绝不会因为"证人说了什么"**而惩罚律师。
这就是 response_mask 的精髓:告诉训练系统哪些 token 是模型自己"说"的,哪些是从外部世界"听"来的。
Step 4: 降维打击与实战启发
神级代码技巧一:Python 对象 → 源代码的安全序列化
python
# ★ 可直接复用:将任意 Python 对象"烘焙"进代码模板的通用模式
# 适用场景:需要跨进程、跨机器传递配置对象的分布式系统
TEMPLATE = """
class MyWorker:
def run(self):
config = {config_dict} # 直接 repr() 展开
model_path = "{model_path}"
tools = {tool_list}
# ... worker 逻辑
"""
def serialize_to_code(config_obj, output_path):
"""将配置对象序列化为 Python 源代码文件"""
# 关键:使用 repr() 而非 json.dumps()
# repr() 可以处理 None、True/False 等 Python 原生类型
code = TEMPLATE.format(
config_dict=repr(config_obj.to_dict()),
model_path=config_obj.model_path,
tool_list=repr(config_obj.tool_list),
)
with open(output_path, 'w') as f:
f.write(code)
# 验证生成的代码可以被 import
import importlib.util
spec = importlib.util.spec_from_file_location("dynamic_module", output_path)
mod = importlib.util.module_from_spec(spec)
spec.loader.exec_module(mod) # 如果有语法错误,这里会提前暴露
return output_path神级代码技巧二:多轮对话的精确 Token Mask 生成
python
# ★ 可直接复用:多轮 Agent 对话的 response_mask 生成
# 核心原理:用序列差集隔离工具结果 token,用 role 判断分配梯度权重
def compute_response_mask(tokenizer, messages, tools=None):
"""
返回:(prompt_ids, response_ids, response_mask)
- response_mask[i] = 1 → 第i个token是模型输出,计算Loss
- response_mask[i] = 0 → 第i个token是环境输入,不计算Loss
"""
prompt_ids, response_ids, response_mask = [], [], []
chat_list = []
for i, msg in enumerate(messages):
role = msg["role"]
if role == "system":
chat_list.append(msg)
elif role == "user" and (i == 0 or messages[i-1]["role"] == "system"):
# 初始提问 → prompt
prompt_ids = tokenizer.apply_chat_template(
chat_list + [msg], tools=tools,
add_generation_prompt=True, tokenize=True
)
chat_list = []
elif role == "assistant":
# 模型回复 → 加入 response,mask=1(训练目标)
ids = tokenizer.apply_chat_template(
[msg], add_generation_prompt=False, tokenize=True
)
response_ids.extend(ids)
response_mask.extend([1] * len(ids))
elif role == "tool":
# 工具结果 → 用差集提取,mask=0(不训练)
prev_assistant = messages[i-1]
base_ids = tokenizer.apply_chat_template(
[prev_assistant], add_generation_prompt=False, tokenize=True
)
tool_msgs = []
j = i
while j < len(messages) and messages[j]["role"] == "tool":
tool_msgs.append(messages[j])
j += 1
full_ids = tokenizer.apply_chat_template(
[prev_assistant] + tool_msgs,
add_generation_prompt=False, tokenize=True
)
# 差集 = 纯工具结果部分
tool_ids = full_ids[len(base_ids):]
response_ids.extend(tool_ids)
response_mask.extend([0] * len(tool_ids))
return prompt_ids, response_ids, response_mask神级代码技巧三:OmegaConf 双层配置合并(用户只写差异)
python
# ★ 可直接复用:框架默认配置 + 用户自定义配置的优雅合并
# 适用于任何需要"默认配置 + 用户覆盖"的场景
from omegaconf import OmegaConf
from omegaconf.dictconfig import DictConfig
def merge_configs(framework_default_yaml_path, user_config):
"""
用户只需写自己关心的字段,其余自动继承框架默认值
Args:
framework_default_yaml_path: 框架提供的完整默认配置
user_config: 用户的差异配置(dict 或 yaml 路径)
"""
# 加载框架完整默认配置(可能有 500+ 个字段)
with open(framework_default_yaml_path) as f:
base_configs = yaml.safe_load(f)
# 加载用户的差异配置(只有 20 个字段)
if isinstance(user_config, str):
with open(user_config) as f:
user_configs = yaml.safe_load(f)
else:
user_configs = user_config
# OmegaConf.merge:用户配置中有的字段覆盖默认,没有的保留默认
merged = OmegaConf.merge(base_configs, user_configs)
# to_container(resolve=True):解析所有插值(${xxx} 语法)
resolved = DictConfig(OmegaConf.to_container(merged, resolve=True))
# 动态注入运行时生成的路径(代码生成后才知道的值)
if not resolved.actor_rollout_ref.rollout.agent.agent_loop_config_path:
resolved.actor_rollout_ref.rollout.agent.agent_loop_config_path = generated_agent_yaml
return resolvedMermaid 架构流程图:完整训练流程
MCP 工具环境 VerlProvider VerlAgentLoop VeRL 训练引擎 代码生成器 VerlTrainer AgentTrainer 用户 MCP 工具环境 VerlProvider VerlAgentLoop VeRL 训练引擎 代码生成器 VerlTrainer AgentTrainer 用户 loop Agent 多轮推理 loop GRPO 训练迭代 AgentTrainer(agent, dataset, reward, config) check_agent(agent) VERL_TEMPLATE.format(**agent_params) VerlAgentLoop.py 写入磁盘 agent.yaml 路径 check_config(config) OmegaConf.merge(verl_default, user_config) 注入 agent_yaml, reward_path, data_path train() main_ppo(merged_config) run(sampling_params, raw_prompt=question) build_agents() → Agent with VerlProvider Runners.run_task(task, timeout=1200s) 观察结果 acompletion(messages, tools) apply_chat_template → prompt_ids vllm.generate(prompt_ids) response token_ids Hermes ToolParser.extract_tool_calls() ModelResponse(content, tool_calls) 执行工具调用 convert_agent_output(trajectory) encode_messages() → response_mask AgentLoopOutput(prompt_ids, response_ids, mask) GRPO 计算 Group Advantage PPO Clip 更新 Actor gaia_reward_func() → 0 or 1 训练完成的 Checkpoint
总结:这套方案的本质哲学
AWorld Train 的核心哲学是**"把复杂性关在适配层里,把简洁性暴露给用户"**。
- 对用户 :
AgentTrainer(agent, dataset, reward, config).train()--- 四行代码,极致简洁 - 对内部 :
check_agent()的代码生成、encode_messages()的 mask 工程、VerlProvider的 token-level 解析 --- 极度精密
这是一个Agent 强化学习训练基础设施。它解决的不是"怎么检索"的问题,而是"**怎么让 Agent 在真实工具调用环境中通过 GRPO 自我进化"**的问题 ------ 这是 2025-2026 年 AI Agent 领域最前沿的工程挑战之一。