提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
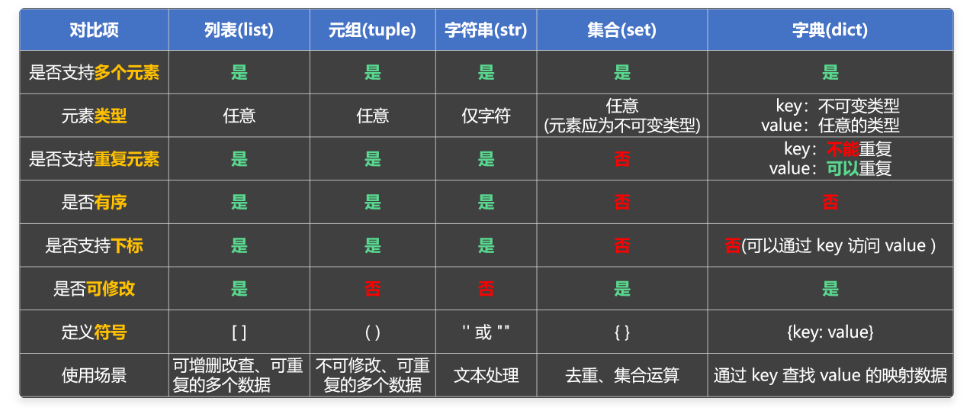
1.数据容器_通用操作

python
# 以下这五个函数:既能定义对应的【空容器】,又能将【其他类型】转换为对应的数据类型
# 1.list 函数:1.定义空列表。2.将【可迭代对象】转换为列表
res1 = list(range(8))
res2 = list('欢迎来到尚硅谷')
res3 = list({10, 20, 30, 40, 50})
res4 = list({'张三': 75, '李四': 60, '王五':85}.items())
print(type(res1), res1)
print(type(res2), res2)
print(type(res3), res3)
print(type(res4), res4)
# 2.tuple 函数:1.定义空元组。2.将【可迭代对象】转换为元组
res1 = tuple(range(8))
res2 = tuple('欢迎来到尚硅谷')
res3 = tuple({10, 20, 30, 40, 50})
res4 = tuple({'张三': 75, '李四': 60, '王五':85})
print(type(res1), res1)
print(type(res2), res2)
print(type(res3), res3)
print(type(res4), res4)
# 3.set 函数:1.定义空集合。2.将【可迭代对象】转换为集合
res1 = set(range(8))
res2 = set('欢迎来到尚硅谷')
res3 = set({10, 20, 30, 40, 50})
res4 = set({'张三': 75, '李四': 60, '王五':85})
print(type(res1), res1)
print(type(res2), res2)
print(type(res3), res3)
print(type(res4), res4)
# 4.str 函数:1.定义空字符串。2.将【任意类型】转换为字符串
res1 = str(range(8))
res2 = str('欢迎来到尚硅谷')
res3 = str({10, 20, 30, 40, 50})
res4 = str({'张三': 75, '李四': 60, '王五':85})
res5 = str(False)
res6 = str(None)
res7 = str(100)
print(type(res1), res1)
print(type(res2), res2)
print(type(res3), res3)
print(type(res4), res4)
print(type(res5), res5)
print(type(res6), res6)
print(type(res6), res6)
print(type(res7), res7)
# 5.dict 函数:1.定义空字典。2.将【可迭代对象】转换为字典
# 备注:交给dict函数的内容必须是键值对才可以,否则就会报错
res1 = dict({'张三': 75, '李四': 60, '王五':85})
res2 = dict([('张三', 75), ('李四', 60), ('王五', 85)])
res3 = dict((('张三', 75), ('李四', 60), ('王五', 85)))
res4 = dict({('张三', 75), ('李四', 60), ('王五', 85)})
print(type(res1), res1)
print(type(res2), res2)
print(type(res3), res3)
print(type(res4), res4)
# 所有的数据容器,都支持【成员运算符】: in / not in 作用:判断某个"元素"是否在于容器中。
hobby = ['抽烟', '喝酒', '烫头']
nums = (10, 20, 30, 40, 50)
message = 'hello,atgiugu'
citys = {'北京', '天津', '上海', '重庆'}
score = {'张三': 75, '李四': 60, '王五':85}
print('喝酒' not in hobby)
print(20 not in nums)
print('hel' not in message)
print('上海' not in citys)
print('李华' not in score)2.数据容器_小练习
练习一:水果清单
python
# 练习一:水果清单
fruits = {
'苹果': 4.5,
'香蕉': 3.2,
'橙子': 5.8,
'草莓': 12.0,
'哈密瓜': 8.8
}
# 需求1:打印所有的水果
for key in fruits:
print(f'{key}:{fruits[key]} 元/斤')
# 需求2:找到最贵水果
key = max(fruits, key=fruits.get)
print(f'最贵的水果是{key},价格是{fruits[key]} 元/斤')练习二:学生成绩表
python
# 练习二:学生成绩表
students = [
{
'name': '张三',
'scores': {'语文': 88, '数学': 92, '英语': 95}
},
{
'name': '李四',
'scores': {'语文': 75, '数学': 83, '英语': 80}
},
{
'name': '王五',
'scores': {'语文': 92, '数学': 95, '英语': 88}
}
]
# 需求1:计算每位学生的平均分
for stu in students:
# 获取当前学生的成绩列表
score_list = stu['scores'].values()
# 计算平均值
avg = sum(score_list) / len(score_list)
print(f'{stu['name']}的平均成绩是:{avg:.1f}')
# 需求2:找到总分最高的学生
def find_best():
# 记录分数最高的学生
best_students = []
# 记录最高分
best_score = 0
# 循环遍历
for stu in students:
# 获取当前学生的总成绩
total = sum(stu['scores'].values())
# 当前学生的成绩,如果大于best_score,就会更新数据
if total > best_score:
best_students = [stu['name']]
best_score = total
# 当前学生的成绩与最高分相同,就加入列表
elif total == best_score:
best_students.append(stu['name'])
print(f'最高分为{best_score},取得最高分的学生有:{best_students}')
find_best()练习三:评论内容
python
comment = '这家奶茶真好喝,环境也不错,就是价格有点贵,好喝好喝好喝!强烈推荐!'
# 需求1:统计"好喝"出现次数
print(comment.count('好喝'))
# 需求2:将字符串中的"贵"替换为"略高"
comment2 = comment.replace('贵', '略高')
print(comment2)
# 需求3:是否包含"推荐"两个字
print('推荐' in comment)3.数据容器_总结