一、Canal 是什么?
Canal (发音 /kəˈnæl/,意为"管道")是阿里巴巴开源的一款基于 MySQL 数据库增量日志(Binlog)解析的数据同步工具 。它的核心目标是:提供高效、可靠、低侵入的数据库变更数据订阅与消费能力。
📌 一句话总结 :
Canal = MySQL 的"窃听器" + "广播站"它能实时捕获你对 MySQL 的增删改操作,并将这些变更以结构化格式推送给下游系统。
二、为什么需要 Canal?------ 起源与痛点
背景故事
早期阿里巴巴因杭州与美国双机房部署,存在跨机房数据同步需求。最初通过业务层 Trigger 捕获变更,但存在:
- ❌ 代码侵入性强
- ❌ 性能损耗大
- ❌ 难以保证顺序和一致性
于是,团队转向直接解析 MySQL 的 Binlog 日志,由此诞生了 Canal。
典型业务痛点
| 场景 | 传统方案问题 | Canal 方案优势 |
|---|---|---|
| 缓存同步 | 业务代码手动删 Redis,易遗漏 | 自动监听 DB 变更,精准失效 |
| 实时数仓 | 定时全量拉取,延迟高 | 秒级捕获增量,实时入仓 |
| 异构索引 | 手写同步逻辑,维护成本高 | 自动推送变更到 ES/HBase |
| 审计日志 | 业务层记录,可能被绕过 | 基于 DB 日志,100% 可靠 |
三、Canal 的核心原理
Canal 的设计非常巧妙------它把自己伪装成 MySQL 的一个 Slave 节点!
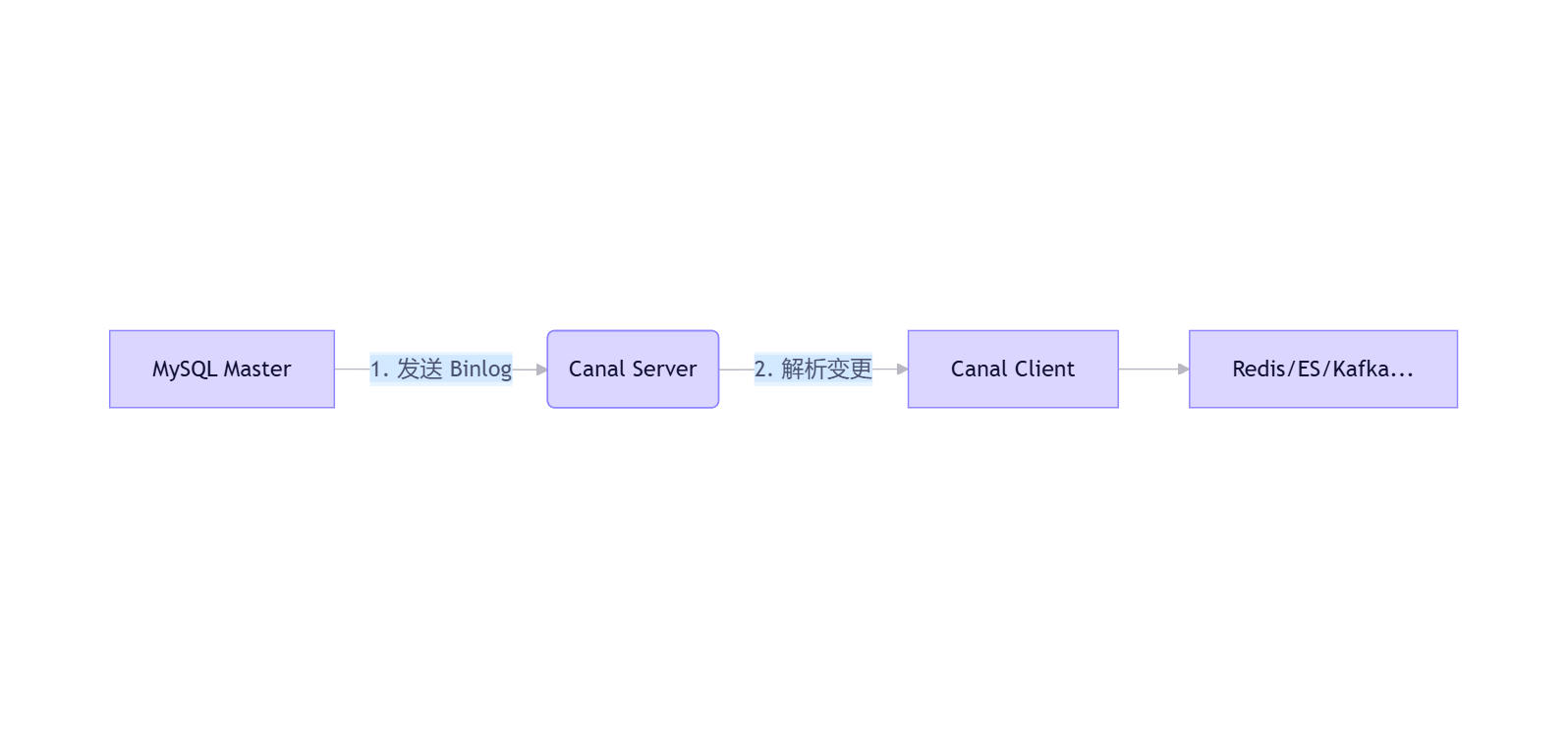
工作流程四步走:
- 伪装 Slave :Canal 向 MySQL Master 发送
dump协议请求 - 接收 Binlog:MySQL 将 Binary Log 流式推送给 Canal
- 解析日志:Canal 将原始字节流解析为结构化事件(INSERT/UPDATE/DELETE)
- 推送消费:客户端订阅这些事件,执行自定义逻辑(如更新缓存)
💡 关键优势:
- 零代码侵入:业务系统无需任何改造
- 强可靠性:基于 MySQL 主从复制协议,不丢数据
- 高性能:单实例可支撑 10w+ TPS
四、Canal 能做什么?------ 核心应用场景
1️⃣ 缓存同步(最常用!)
- 场景:用户修改资料 → 自动刷新 Redis 缓存
- 效果:避免"缓存与 DB 不一致"问题
2️⃣ 实时数据仓库
- 链路:MySQL → Canal → Kafka → Flink → Hive/Doris
- 价值:实现秒级延迟的实时报表
3️⃣ 异构数据索引
- 示例:订单表变更 → 自动同步到 Elasticsearch
- 优势:支持复杂查询(如"近7天销量Top100")
4️⃣ 数据库备份与灾备
- 方案:通过 Canal 构建准实时从库
- 特点:比原生主从更灵活(可过滤表/字段)
5️⃣ 业务审计与监控
- 用途:记录所有敏感操作(如资金变动)
- 可靠性:基于 Binlog,无法被业务绕过
五、Canal 的核心组件
Canal 采用Server-Client 架构:
| 组件 | 职责 | 说明 |
|---|---|---|
| Canal Server | Binlog 解析与事件分发 | 需部署在服务端,连接 MySQL |
| Canal Client | 事件消费与业务处理 | 由开发者编写,对接下游系统 |
| Instance | 一个 MySQL 数据源的抽象 | 一个 Server 可管理多个 Instance |
| Meta Manager | 位点管理 | 记录 Binlog 消费位置,支持断点续传 |
📦 扩展组件:
- Canal Adapter:无需写 Client,直接同步到 ES/HBase
- Canal Admin:Web 管理控制台(配置/监控/告警)
六、Canal 支持哪些数据库?
| 数据库 | 版本支持 | 状态 |
|---|---|---|
| MySQL | 5.1.x, 5.5.x, 5.6.x, 5.7.x, 8.0.x | ✅ 完整支持 |
| MariaDB | 5.5+ | ✅ 兼容 |
| Oracle | - | ⚠️ 社区版不支持(需商业方案) |
| PostgreSQL | - | ❌ 不支持 |
🔑 前提条件:
- MySQL 必须开启
binlogbinlog_format必须为ROW
七、Canal vs 其他方案
| 方案 | 侵入性 | 实时性 | 可靠性 | 复杂度 |
|---|---|---|---|---|
| 业务层双写 | 高(改代码) | 高 | 低(易丢数据) | 低 |
| 定时任务扫描 | 低 | 低(分钟级) | 中 | 低 |
| MQ 事务消息 | 中 | 高 | 高 | 中 |
| Canal (Binlog) | 零 | 高(秒级) | 极高 | 中 |
✅ 结论 :
对于 MySQL 场景,Canal 是平衡实时性、可靠性与成本的最佳选择。
八、快速体验 Canal
最简工作流:
- 配置 MySQL :开启 Binlog(
binlog-format=ROW) - 启动 Canal Server:连接 MySQL
- 编写 Client :订阅
example实例 - 操作 MySQL :
INSERT INTO user(name) VALUES('Alice') - 观察输出:Client 收到结构化事件
java
// Client 伪代码
Message msg = connector.get(1000);
for (Entry entry : msg.getEntries()) {
// 打印:table=user, type=INSERT, data={id=1, name='Alice'}
System.out.println(entry.toString());
}九、结语
感谢您的阅读!如果你有任何疑问或想要分享的经验,请在评论区留言交流!