大模型工程三驾马车:Prompt Engineering、Context Engineering 与 Harness Engineering 深度解析
当大语言模型(LLM)从实验室走向生产环境,工程师们发现:会用模型 和用好模型之间,横亘着一条深沟。这条沟,正是由三大工程学科来填平的。

目录
- 引言:为什么需要三种工程?
- [Prompt Engineering:与模型沟通的艺术](#Prompt Engineering:与模型沟通的艺术 "#%E4%BA%8Cprompt-engineering%E4%B8%8E%E6%A8%A1%E5%9E%8B%E6%B2%9F%E9%80%9A%E7%9A%84%E8%89%BA%E6%9C%AF")
- [Context Engineering:构建模型的记忆与感知](#Context Engineering:构建模型的记忆与感知 "#%E4%B8%89context-engineering%E6%9E%84%E5%BB%BA%E6%A8%A1%E5%9E%8B%E7%9A%84%E8%AE%B0%E5%BF%86%E4%B8%8E%E6%84%9F%E7%9F%A5")
- [Harness Engineering:构建可靠的AI应用基础设施](#Harness Engineering:构建可靠的AI应用基础设施 "#%E5%9B%9Bharness-engineering%E6%9E%84%E5%BB%BA%E5%8F%AF%E9%9D%A0%E7%9A%84ai%E5%BA%94%E7%94%A8%E5%9F%BA%E7%A1%80%E8%AE%BE%E6%96%BD")
- 三者的协作关系与实战全景
- 综合对比与选型建议
- 结语
一、引言:为什么需要三种工程?
2023年以来,随着 GPT-4、Claude、Gemini 等超大规模语言模型的商业化落地,越来越多的团队开始尝试将 LLM 集成到真实的业务系统中。然而,一个令人沮丧的现实是:直接调用 API 所得到的效果,往往与预期相差甚远。
问题出在哪里?
通常有三个层面:
-
沟通层面 :你没有用模型"听得懂"的方式提问。模型是通过海量文本训练出来的,它对指令的理解高度依赖措辞方式、上下文铺垫和示例引导。这是 Prompt Engineering 要解决的问题。
-
信息层面 :模型不知道你的业务背景、用户历史、相关知识。它的训练数据有截止日期,不了解你的私有数据库,也记不住上一次对话。这是 Context Engineering 要解决的问题。
-
系统层面 :单次调用成功不等于系统稳定。生产环境中有网络抖动、模型幻觉、并发压力、成本控制......这是 Harness Engineering 要解决的问题。
三者分工明确、相互依存,共同构成了 LLM 应用工程的完整体系。
二、Prompt Engineering:与模型沟通的艺术
2.1 核心定义
Prompt Engineering(提示词工程) 是指通过精心设计输入文本(Prompt),引导大语言模型产生更准确、更有用、更符合预期输出的技术与方法论。
它的核心洞察是:同一个模型,面对不同的提问方式,会给出截然不同的答案。提示词工程师的任务,就是找到那个"最优提问方式"。
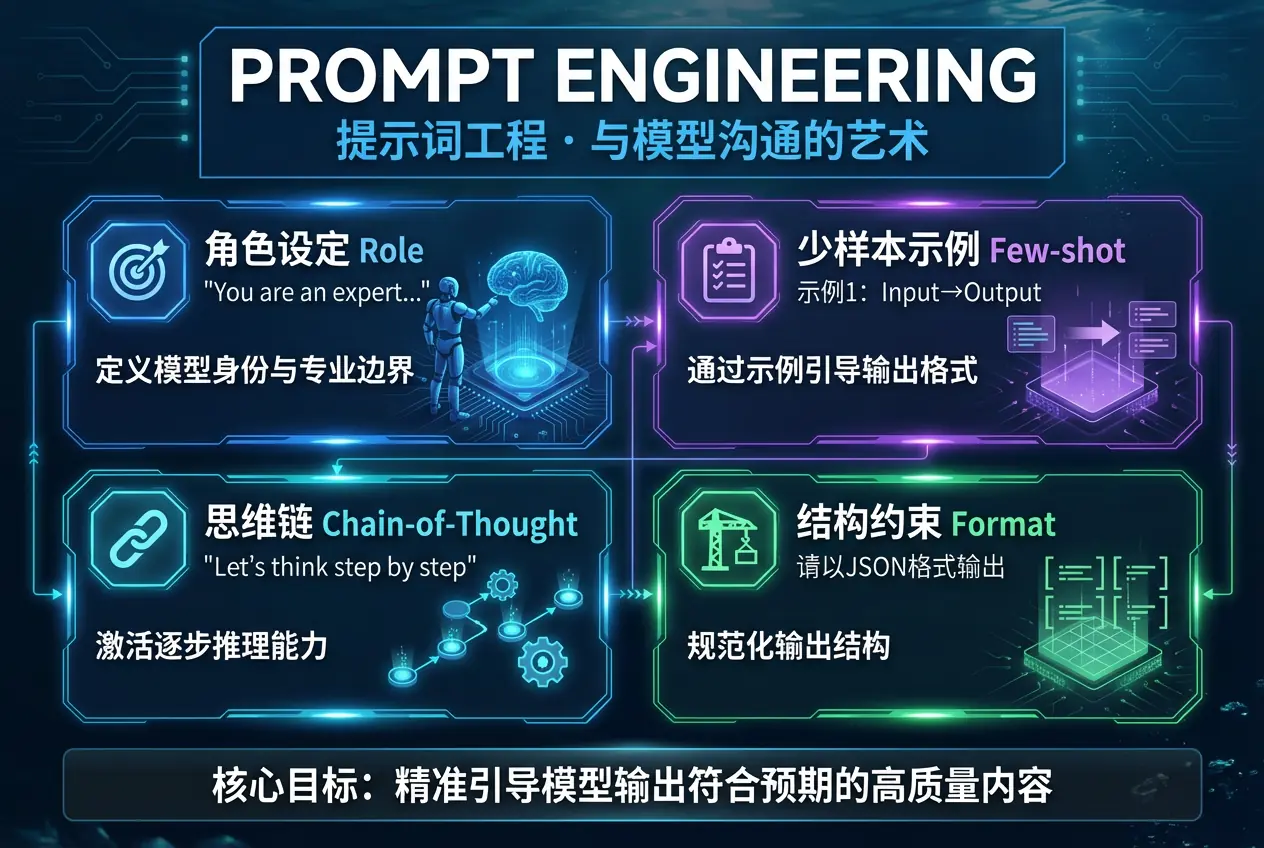
2.2 关键技术方法
2.2.1 零样本提示(Zero-shot Prompting)
最简单的形式:直接描述任务,不提供任何示例。
arduino
请将以下英文翻译成中文,保持专业术语准确:
"The transformer architecture revolutionized natural language processing."适用场景 :模型已充分训练的通用任务(翻译、摘要、格式转换)。
局限性:对于专业领域或特定格式要求,效果往往不稳定。
2.2.2 少样本提示(Few-shot Prompting)
通过提供 2-5 个示例,让模型学习期望的输入输出模式。
请判断以下评论的情感倾向(正面/负面/中性):
评论:这款手机拍照效果真的太棒了!
情感:正面
评论:电池续航一般,其他还好。
情感:中性
评论:客服态度极差,再也不买了。
情感:负面
评论:快递很快,包装精美,产品质量不错。
情感:实战案例:某电商平台用 Few-shot Prompting 构建评论分析系统,在不微调模型的情况下,将情感分类准确率从 72% 提升到 91%,仅通过调整 5 个示例就完成了。
2.2.3 思维链提示(Chain-of-Thought, CoT)
由 Google 研究人员在 2022 年提出,通过引导模型"逐步思考"来提升复杂推理能力。
ini
问题:小明有15个苹果,他给了小红1/3,又买了8个,现在有多少?
请一步一步思考:
第一步:小明给了小红多少苹果?15 × 1/3 = 5个
第二步:给出后小明还剩多少?15 - 5 = 10个
第三步:买了8个后总共多少?10 + 8 = 18个
所以答案是18个。
问题:工厂每天生产240个零件,其中20%是次品,次品中有一半可以返工修复。
每天实际合格品数量是多少?
请一步一步思考:实战数据:在 GSM8K 数学推理基准测试中,CoT 提示将 GPT-3 的准确率从 17.9% 提升到 56.9%,提升幅度超过 3 倍。
2.2.4 角色扮演提示(Role Prompting)
为模型赋予特定的专业身份,激活相应的知识储备和表达风格。
你是一位拥有20年经验的心脏科主任医师,擅长用通俗易懂的语言向患者解释复杂的医学概念。
请向一位刚被确诊为高血压的50岁患者解释:为什么需要长期服药,而不是血压正常后就停药?实战案例:某法律科技公司通过角色提示,让 GPT-4 扮演"专注于合同审查的资深律师",合同风险识别率提升 40%,且输出格式更符合法律专业规范。
2.2.5 结构化输出约束
通过明确指定输出格式,确保结果可被程序处理。
javascript
分析以下产品评论,并以严格的JSON格式返回结果,不要包含任何额外文字:
评论内容:「这款蓝牙耳机音质很好,但连接不稳定,价格也偏贵,总体来说还是值得买的」
返回格式:
{
"sentiment": "positive|negative|neutral|mixed",
"score": 1-10的整数,
"pros": ["优点1", "优点2"],
"cons": ["缺点1", "缺点2"],
"recommendation": true|false
}2.2.6 自动化提示优化(APE / DSPy)
2023年后兴起的进阶技术:让 AI 自动生成和优化 Prompt。
- APE(Automatic Prompt Engineer):给定输入输出示例,让模型自动生成最优提示词
- DSPy:斯坦福开发的框架,将提示词优化转化为可微分的优化问题,实现端到端自动调优
python
# DSPy 示例:自动优化情感分析提示词
import dspy
class SentimentAnalyzer(dspy.Signature):
"""分析文本的情感倾向"""
text = dspy.InputField(desc="需要分析的文本")
sentiment = dspy.OutputField(desc="情感标签:positive/negative/neutral")
# DSPy 会自动优化这个程序的提示词
analyzer = dspy.Predict(SentimentAnalyzer)
result = analyzer(text="这个产品真的太棒了!")2.3 主要应用场景
| 场景 | 技术选择 | 典型案例 |
|---|---|---|
| 客服问答 | Role + Few-shot | 某银行客服机器人,通过角色提示将专业度评分提升35% |
| 代码生成 | CoT + 结构约束 | GitHub Copilot 的注释→代码生成 |
| 内容创作 | Role + Zero-shot | 营销文案、新闻摘要 |
| 数据提取 | 结构化输出 | 从非结构化文本中提取实体信息 |
| 逻辑推理 | CoT + Self-consistency | 数学解题、法律分析 |
2.4 局限性
尽管 Prompt Engineering 强大,但它有几个根本性的局限:
- Token 上限的天花板:再精妙的提示词,也无法突破模型的上下文窗口限制。
- 知识截止日期:模型不知道训练数据截止日期之后的信息,无论 Prompt 多精心。
- 一致性挑战:同一个 Prompt 在不同运行时可能产生不同结果,难以保证生产稳定性。
- 领域深度有限:对于高度专业化的私有知识(如企业内部文档、特定行业数据),仅靠 Prompt 无法弥补。
- 维护成本高:模型版本更新后,原有 Prompt 可能失效,需要重新调优。
三、Context Engineering:构建模型的记忆与感知
3.1 核心定义
Context Engineering(上下文工程) 是指系统性地设计、管理和优化输入给大语言模型的上下文信息,以最大化模型在特定任务中的效能。
如果说 Prompt Engineering 关注的是"说什么 ",那么 Context Engineering 关注的是"给模型看什么"。
它的核心命题是:在有限的 Token 预算内,如何让每一个 Token 都发挥最大价值?
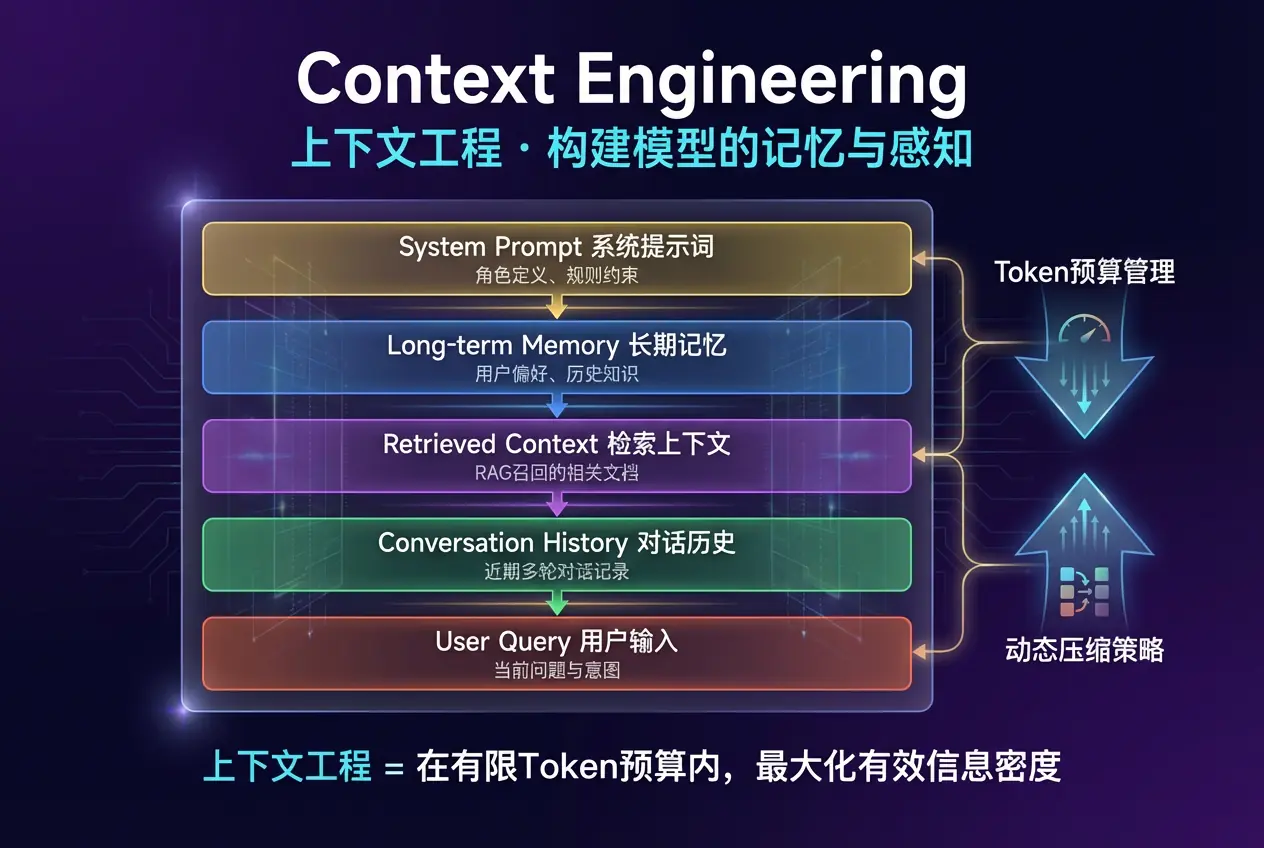
3.2 上下文窗口的分层架构
一个精心设计的上下文窗口,通常包含以下层次(从上到下优先级递减):
erlang
┌─────────────────────────────────────────┐
│ System Prompt(系统提示词) │ ~5%
│ 角色定义、行为规则、输出约束 │
├─────────────────────────────────────────┤
│ Long-term Memory(长期记忆) │ ~10%
│ 用户偏好、历史重要信息、个性化数据 │
├─────────────────────────────────────────┤
│ Retrieved Context(检索上下文) │ ~40%
│ RAG 召回的相关文档、知识库片段 │
├─────────────────────────────────────────┤
│ Conversation History(对话历史) │ ~35%
│ 近期多轮对话记录(经过压缩) │
├─────────────────────────────────────────┤
│ User Query(用户当前输入) │ ~10%
│ 当前问题 + 即时上下文 │
└─────────────────────────────────────────┘3.3 关键技术方法
3.3.1 检索增强生成(RAG)
RAG 是 Context Engineering 最重要的技术之一,通过实时检索相关知识来扩展模型的"知识边界"。
基础 RAG 流程:
用户提问 → 向量化编码 → 相似度检索 → 召回相关文档片段 → 注入上下文 → 模型生成答案实战案例:某保险公司智能客服系统
- 问题:保险条款复杂,模型经常"幻觉"出不存在的条款
- 解决方案:将 5000 页保险条款向量化存入 Milvus,每次对话实时检索 Top-5 相关条款
- 效果:幻觉率从 23% 降至 2.1%,客户满意度提升 28%
- 关键细节:文档切片策略采用"语义分块"而非固定长度切块,召回准确率提升 15%
python
# RAG 核心流程示例
from langchain.vectorstores import Milvus
from langchain.embeddings import OpenAIEmbeddings
def rag_query(user_question: str, vectorstore: Milvus) -> str:
# 1. 检索相关文档
relevant_docs = vectorstore.similarity_search(
user_question,
k=5,
score_threshold=0.7 # 过滤低相关性文档
)
# 2. 构建上下文
context = "\n\n".join([doc.page_content for doc in relevant_docs])
# 3. 注入上下文并生成
prompt = f"""基于以下保险条款,回答用户问题。
如果条款中没有相关信息,请明确说明"该条款中未找到相关规定"。
相关条款:
{context}
用户问题:{user_question}
"""
return llm.invoke(prompt)3.3.2 对话历史管理
多轮对话中,历史记录会快速占满上下文窗口。Context Engineering 提供了多种压缩策略:
策略一:滑动窗口(Sliding Window) 保留最近 N 轮对话,丢弃更早的历史。简单但会丢失重要早期信息。
策略二:摘要压缩(Summary Compression) 定期用 LLM 对历史对话做摘要,以少量 Token 保存关键信息。
python
def compress_history(history: list, max_tokens: int = 500) -> str:
"""将对话历史压缩为摘要"""
history_text = "\n".join([f"{h['role']}: {h['content']}" for h in history])
summary_prompt = f"""请将以下对话历史压缩成一段不超过200字的摘要,
保留所有关键信息、用户偏好和重要决策:
{history_text}
"""
return llm.invoke(summary_prompt)策略三:重要性过滤(Importance Filtering) 为每条历史记录打分,只保留高重要性内容。
实战数据:某智能助手产品使用摘要压缩策略后,在相同 Token 预算下,用户感知的"记忆深度"从 5 轮提升到 20+ 轮,用户留存率提升 19%。
3.3.3 长期记忆系统
超越单次会话的持久化记忆,是 Context Engineering 的高级形态。
实现架构:
markdown
用户交互 → 记忆提取器(LLM判断哪些值得记忆)→ 记忆存储(向量DB + 结构化DB)
↓
新会话开始 → 记忆检索(相关记忆召回)→ 注入 System Prompt → 个性化响应实战案例:个人 AI 助手产品
某 AI 助手将以下信息作为长期记忆:
- 用户职业、专业背景
- 偏好的回答风格(简洁/详细)
- 历史重要决策(如"用户选择了A方案而非B方案")
- 用户明确告知的个人信息
通过长期记忆,用户在第 10 次打开应用时,AI 还记得"上周你提到正在准备技术分享,需要我帮你整理PPT大纲"。
3.3.4 Token 预算管理
在成本和效果之间找到平衡,是 Context Engineering 的核心工程挑战。
python
class ContextBudgetManager:
"""Token 预算管理器"""
def __init__(self, total_budget: int = 8000):
self.total_budget = total_budget
self.allocation = {
"system_prompt": 0.05, # 5%
"long_term_memory": 0.10, # 10%
"retrieved_context": 0.45, # 45%
"conversation_history": 0.30, # 30%
"user_query": 0.10, # 10%
}
def build_context(self, components: dict) -> str:
"""按预算分配构建最优上下文"""
result = []
for component, ratio in self.allocation.items():
budget = int(self.total_budget * ratio)
content = components.get(component, "")
truncated = self._truncate_to_tokens(content, budget)
result.append(truncated)
return "\n\n".join(result)3.3.5 多模态上下文
随着 GPT-4V、Gemini 等多模态模型的普及,Context Engineering 也延伸到图像、音频、视频等领域。
实战案例:工业质检 AI 系统
某制造企业将产品图片、历史缺陷记录、检测标准文档共同注入上下文,实现了"看图说话+知识库对照"的智能质检,缺陷漏检率降低 67%。
3.4 主要应用场景
| 场景 | 核心技术 | 效果指标 |
|---|---|---|
| 企业知识库问答 | RAG + 向量检索 | 幻觉率降低 80%+ |
| 个性化推荐 | 长期记忆 + 用户画像 | 点击率提升 25%+ |
| 多轮对话助手 | 历史压缩 + 记忆管理 | 上下文连贯性提升 |
| 代码助手 | 代码库检索 + 文档注入 | 代码准确率提升 40%+ |
| 法律/医疗问答 | 专业文档 RAG | 专业准确性提升显著 |
3.5 局限性
- 检索质量瓶颈:RAG 的效果高度依赖向量检索的召回精度,"垃圾进,垃圾出"。
- 上下文窗口仍有限:即使是 128K Token 的模型,面对海量企业文档仍然捉襟见肘。
- 信息新鲜度问题:向量数据库需要定期更新,否则会出现"知识过期"问题。
- 噪声干扰:注入过多不相关上下文,反而会"分散"模型注意力,降低效果。
- 成本压力:更多的上下文意味着更高的 Token 消耗,需要精细化成本管理。
四、Harness Engineering:构建可靠的AI应用基础设施
4.1 核心定义
Harness Engineering(框架工程) 是指围绕大语言模型构建可靠、可扩展、可观测的生产级应用系统的工程实践。
"Harness"(马具/驾驭装置)这个词非常形象:就像给烈马套上马具,让其力量得以被安全驾驭。框架工程的目标是让强大但不稳定的 LLM 能力,在复杂的生产环境中可靠运行。
如果说 Prompt Engineering 和 Context Engineering 解决的是"让模型做出好的回答 ",那么 Harness Engineering 解决的是"让好的回答在生产环境中稳定交付"。
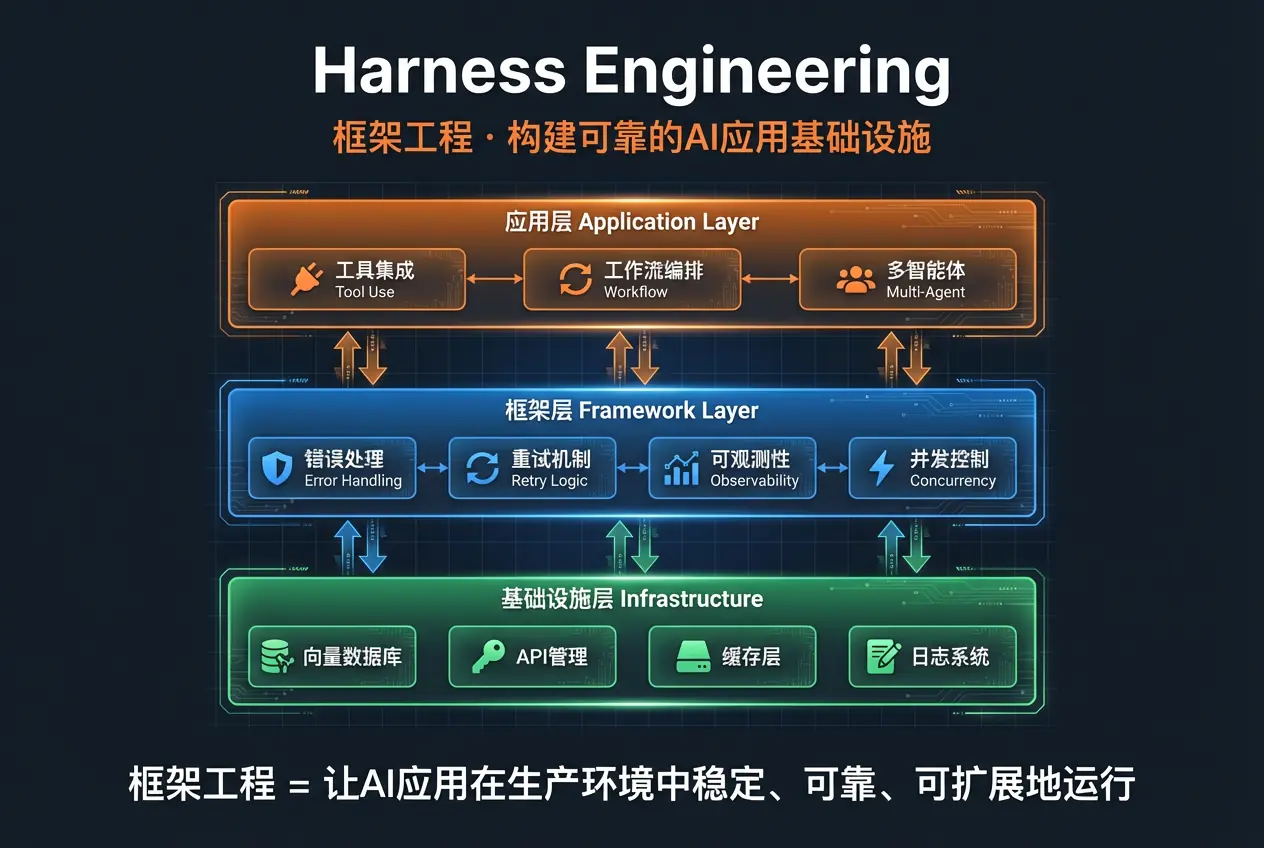
4.2 关键技术方法
4.2.1 可靠性工程:错误处理与重试机制
LLM API 调用面临的不可靠性来源:网络超时、速率限制、模型输出格式错误、内容过滤触发等。
python
import tenacity
import openai
from typing import Optional
class RobustLLMClient:
"""生产级 LLM 客户端,内置重试和降级机制"""
@tenacity.retry(
stop=tenacity.stop_after_attempt(3),
wait=tenacity.wait_exponential(multiplier=1, min=4, max=10),
retry=tenacity.retry_if_exception_type(
(openai.RateLimitError, openai.APITimeoutError)
),
before_sleep=lambda retry_state: print(
f"⚠️ 第{retry_state.attempt_number}次重试..."
)
)
async def call_with_retry(self, prompt: str) -> str:
return await self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
timeout=30
)
async def call_with_fallback(
self,
prompt: str,
fallback_model: str = "gpt-3.5-turbo"
) -> tuple[str, str]:
"""主模型失败时自动降级到备用模型"""
try:
result = await self.call_with_retry(prompt)
return result, "primary"
except Exception as e:
print(f"主模型失败: {e},切换到备用模型")
result = await self._call_model(prompt, fallback_model)
return result, "fallback"实战案例:某金融风控系统在引入重试机制和降级策略后,LLM 调用成功率从 94.2% 提升到 99.7%,P99 延迟从 12s 降至 4s。
4.2.2 输出验证与结构化解析
LLM 输出的不确定性是生产系统的最大挑战之一。Harness Engineering 通过多层验证确保输出质量。
python
from pydantic import BaseModel, validator
import json
class ProductAnalysis(BaseModel):
"""强类型的 LLM 输出结构"""
sentiment: str
score: int
pros: list[str]
cons: list[str]
recommendation: bool
@validator('sentiment')
def validate_sentiment(cls, v):
allowed = {'positive', 'negative', 'neutral', 'mixed'}
if v not in allowed:
raise ValueError(f'情感标签必须是 {allowed} 之一')
return v
@validator('score')
def validate_score(cls, v):
if not 1 <= v <= 10:
raise ValueError('评分必须在 1-10 之间')
return v
class StructuredLLMParser:
"""带验证的结构化输出解析器"""
def parse_with_retry(self, raw_output: str, max_retries: int = 3) -> ProductAnalysis:
for attempt in range(max_retries):
try:
# 提取 JSON
json_match = re.search(r'\{.*\}', raw_output, re.DOTALL)
if not json_match:
raise ValueError("未找到 JSON 内容")
data = json.loads(json_match.group())
return ProductAnalysis(**data)
except (json.JSONDecodeError, ValueError) as e:
if attempt < max_retries - 1:
# 重新提示模型修正输出
raw_output = self._fix_output(raw_output, str(e))
else:
raise4.2.3 可观测性与监控
生产 LLM 系统的可观测性包含三个维度:
指标(Metrics):
python
# 关键监控指标
metrics = {
"latency_p50": "中位响应时间",
"latency_p99": "99分位响应时间",
"token_usage_input": "输入 Token 消耗",
"token_usage_output": "输出 Token 消耗",
"cost_per_request": "每次请求成本",
"error_rate": "错误率",
"hallucination_rate": "幻觉检测率(通过评估模型)",
"user_satisfaction": "用户满意度(点赞/踩)",
}追踪(Tracing): 使用 LangSmith、Langfuse 等工具追踪每次 LLM 调用的完整链路:
scss
用户请求 → RAG检索(23ms) → Prompt构建(5ms) → LLM调用(1.2s) →
输出解析(8ms) → 验证(3ms) → 响应返回
总耗时: 1.239s | Token: 1847 | 成本: $0.0037日志(Logging): 记录完整的输入输出,用于问题排查和数据飞轮:
python
@dataclass
class LLMCallLog:
request_id: str
timestamp: datetime
model: str
input_prompt: str
output: str
tokens_used: int
latency_ms: int
error: Optional[str]
user_feedback: Optional[str] # 用于后续优化实战案例:某 AI 写作工具通过 LangSmith 发现,有 15% 的请求在"风格转换"步骤耗时超过 3 秒,原因是 Prompt 中包含了过多不必要的示例。优化后整体 P95 延迟降低 40%。
4.2.4 工具调用与 Function Calling
现代 LLM 应用不再是单纯的文本生成,而是通过工具调用与外部系统交互。
python
# 定义工具
tools = [
{
"type": "function",
"function": {
"name": "get_stock_price",
"description": "获取指定股票的实时价格",
"parameters": {
"type": "object",
"properties": {
"symbol": {
"type": "string",
"description": "股票代码,如 AAPL"
}
},
"required": ["symbol"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_trade",
"description": "执行股票交易",
"parameters": {
"type": "object",
"properties": {
"symbol": {"type": "string"},
"action": {"type": "string", "enum": ["buy", "sell"]},
"quantity": {"type": "integer"},
"price_limit": {"type": "number"}
},
"required": ["symbol", "action", "quantity"]
}
}
}
]
# 工具调用的安全护栏
class SafeToolExecutor:
"""带安全检查的工具执行器"""
HIGH_RISK_TOOLS = {"execute_trade", "send_email", "delete_file"}
def execute(self, tool_name: str, params: dict, user_id: str) -> dict:
# 1. 权限检查
if not self.check_permission(user_id, tool_name):
raise PermissionError(f"用户 {user_id} 无权执行 {tool_name}")
# 2. 高风险操作需要二次确认
if tool_name in self.HIGH_RISK_TOOLS:
if not self.require_confirmation(user_id, tool_name, params):
return {"status": "cancelled", "reason": "用户取消"}
# 3. 参数验证
self.validate_params(tool_name, params)
# 4. 执行并记录
result = self.tool_registry[tool_name](**params)
self.audit_log(user_id, tool_name, params, result)
return result4.2.5 多智能体编排(Multi-Agent Orchestration)
复杂任务需要多个专业化 Agent 协作完成。
python
# 研究报告生成系统:多 Agent 协作
class ResearchReportSystem:
def __init__(self):
self.agents = {
"planner": PlannerAgent(), # 任务分解
"researcher": ResearchAgent(), # 信息搜集
"analyst": AnalystAgent(), # 数据分析
"writer": WriterAgent(), # 内容撰写
"reviewer": ReviewerAgent(), # 质量审核
}
async def generate_report(self, topic: str) -> str:
# 1. 规划阶段
plan = await self.agents["planner"].create_plan(topic)
# 2. 并行研究(多个子任务同时执行)
research_tasks = [
self.agents["researcher"].research(subtopic)
for subtopic in plan.subtopics
]
research_results = await asyncio.gather(*research_tasks)
# 3. 分析
analysis = await self.agents["analyst"].analyze(research_results)
# 4. 撰写
draft = await self.agents["writer"].write(plan, analysis)
# 5. 审核与修订(循环直到通过)
for _ in range(3): # 最多3轮修订
review = await self.agents["reviewer"].review(draft)
if review.approved:
break
draft = await self.agents["writer"].revise(draft, review.feedback)
return draft实战案例:某咨询公司 AI 研究助手
使用多 Agent 系统替代人工研究流程:
- 原流程:1名研究员 × 3天 = 1份行业报告
- AI流程:Planner + 5个并行 Researcher + Analyst + Writer = 2小时
- 质量评估:经过 Reviewer Agent 的 3 轮迭代,报告质量达到初级研究员水平
4.2.6 成本控制与缓存
python
import hashlib
from functools import lru_cache
class CostOptimizedLLMClient:
"""成本优化的 LLM 客户端"""
def __init__(self, cache_ttl: int = 3600):
self.semantic_cache = SemanticCache(ttl=cache_ttl)
self.call_count = 0
self.total_cost = 0
async def call(self, prompt: str, use_cache: bool = True) -> str:
# 1. 语义缓存查询(相似问题复用答案)
if use_cache:
cached = await self.semantic_cache.get(prompt)
if cached:
print(f"💰 缓存命中,节省约 $0.003")
return cached
# 2. 路由到最合适的模型(简单任务用便宜模型)
model = self._select_model(prompt)
# 3. 调用并缓存
result = await self._call_model(prompt, model)
await self.semantic_cache.set(prompt, result)
return result
def _select_model(self, prompt: str) -> str:
"""根据任务复杂度选择模型"""
token_count = len(prompt.split())
if token_count < 100 and self._is_simple_task(prompt):
return "gpt-3.5-turbo" # 便宜 10 倍
return "gpt-4"实战数据 :某企业通过语义缓存 + 模型路由策略,将月度 LLM 成本从 12,000降至3,800,降幅 68%。
4.3 主要应用场景
| 场景 | 核心挑战 | Harness 解法 |
|---|---|---|
| 高并发 API 服务 | 延迟、成本、稳定性 | 缓存+限流+降级 |
| 金融/医疗合规场景 | 输出可靠性、审计 | 验证+日志+人工审核 |
| 自动化工作流 | 错误传播、任务失败 | 重试+检查点+回滚 |
| 多租户 SaaS | 隔离性、公平调度 | 队列+配额管理 |
| 实时交互系统 | 低延迟要求 | 流式输出+预取 |
4.4 局限性
- 复杂性代价:完善的 Harness 系统本身就是一个复杂工程项目,需要专业的工程团队维护。
- 过度工程风险:早期原型阶段引入过多基础设施,会拖慢迭代速度。
- 框架依赖风险:LangChain、LlamaIndex 等框架更新频繁,版本兼容性是持续挑战。
- 可观测性成本:完整的追踪和日志系统本身也会增加延迟和存储成本。
- 多 Agent 不确定性:多 Agent 系统的行为难以预测,调试和测试复杂度指数级上升。
五、三者的协作关系与实战全景
5.1 协作关系图解
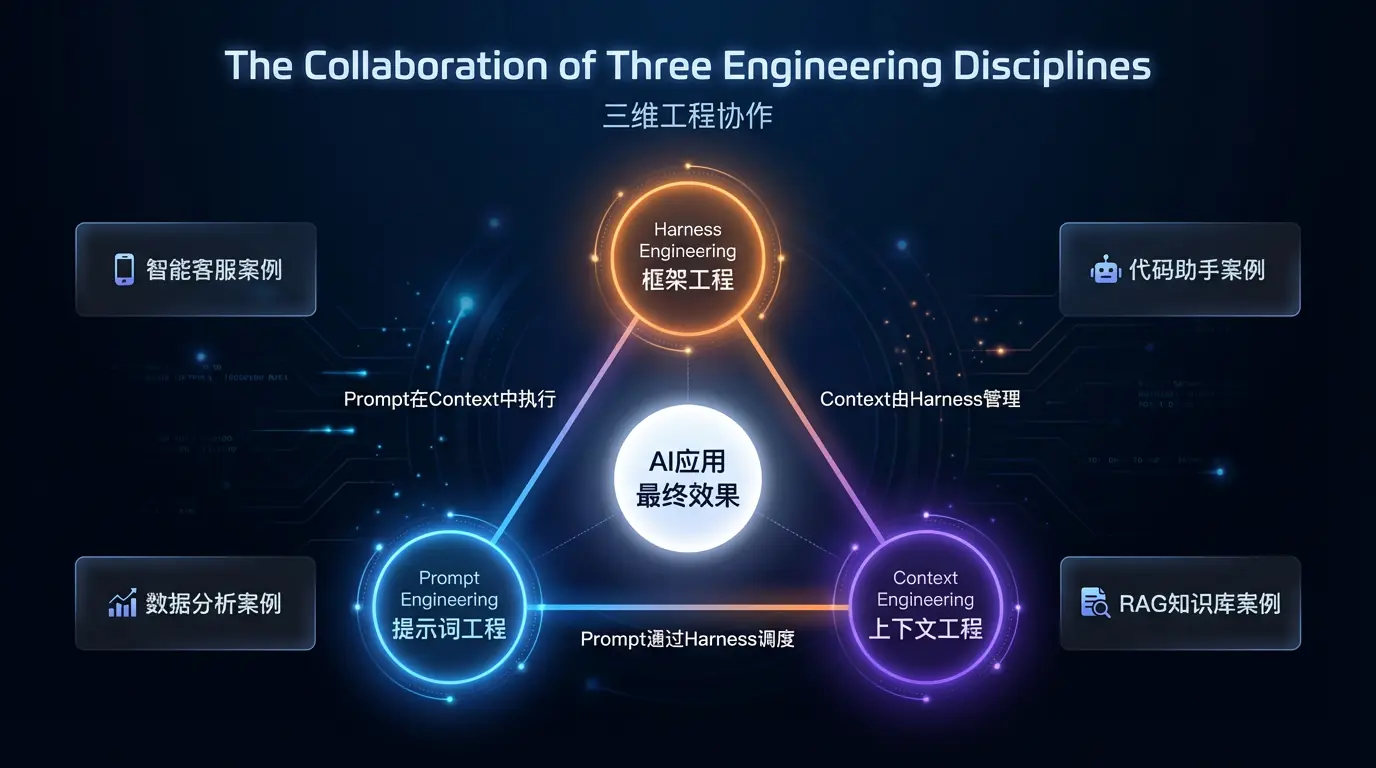
三者的关系可以用一个比喻来理解:
Prompt Engineering 是演员的台词 ------决定了说什么、怎么说。
Context Engineering 是演员的记忆与知识 ------决定了有什么素材可以发挥。
Harness Engineering 是剧场的基础设施------决定了演出能否稳定、持续地进行。
没有好台词,演出平淡无奇;没有背景知识,演员无从发挥;没有剧场基础设施,演出根本无法进行。
5.2 实战案例一:企业智能客服系统
业务背景:某大型零售集团,日均客服咨询量 50 万次,人工客服成本高昂。
三层工程协作设计:
diff
用户提问:"我上周买的蓝牙耳机还没收到,怎么回事?"
↓
【Context Engineering 层】
- 长期记忆:用户ID → 历史购买偏好(高价值客户)
- RAG检索:订单系统 → 查询该用户最近订单
召回:订单#20240401, 蓝牙耳机, 已发货, 快递单号SF1234567
- 实时数据:调用快递API → 当前状态"派送中,预计明日到达"
↓
【Prompt Engineering 层】
System: 你是XX零售集团的专业客服,语气亲切专业,优先安抚情绪,再解决问题。
该用户是VIP会员,需要给予额外关怀。
Context: [订单信息] [物流信息] [用户历史]
Task: 回答用户关于订单物流的疑问
↓
【Harness Engineering 层】
- 调用链路追踪:记录完整调用过程
- 输出验证:检查回复是否包含快递单号(必须要素)
- 情感检测:若用户情绪激动,自动升级人工客服
- 成本控制:简单查询用 GPT-3.5,复杂投诉用 GPT-4效果:
- 人工客服工作量减少 73%
- 客户满意度从 78 分提升到 89 分
- 平均响应时间从 3 分钟降至 8 秒
- 月度成本节省 ¥120 万
5.3 实战案例二:AI 代码审查系统
业务背景:某互联网公司,每日 PR 数量 500+,代码审查成为研发瓶颈。
三层工程协作设计:
python
class CodeReviewSystem:
"""AI 代码审查系统"""
async def review_pr(self, pr_id: str) -> ReviewResult:
# === Context Engineering ===
# 1. 获取代码变更
diff = await self.git_client.get_diff(pr_id)
# 2. 检索相关上下文
related_files = await self.code_rag.search(diff, top_k=10)
coding_standards = await self.standards_rag.search(diff, top_k=5)
similar_bugs = await self.bug_db.search(diff, top_k=3)
# 3. 构建上下文
context = ContextBuilder(budget=6000)\
.add("diff", diff, priority=1)\
.add("related_code", related_files, priority=2)\
.add("standards", coding_standards, priority=3)\
.add("known_bugs", similar_bugs, priority=4)\
.build()
# === Prompt Engineering ===
prompt = f"""你是一位资深软件工程师,专注于代码质量和安全性审查。
请审查以下代码变更,重点关注:
1. 潜在的安全漏洞(SQL注入、XSS、权限绕过等)
2. 性能问题(N+1查询、不必要的循环、内存泄漏)
3. 代码规范(命名、注释、错误处理)
4. 业务逻辑正确性
参考信息:
{context}
请以JSON格式返回审查结果,包含:severity(critical/major/minor)、
issues列表、suggestions列表、overall_score(1-10)。
"""
# === Harness Engineering ===
result = await self.llm_client.call_with_retry(prompt)
parsed = self.output_parser.parse(result, schema=ReviewResult)
# 安全门:critical 问题自动阻塞 PR
if any(issue.severity == "critical" for issue in parsed.issues):
await self.github_client.block_pr(pr_id, reason="AI发现严重安全问题")
# 记录用于持续优化
await self.feedback_collector.log(pr_id, parsed)
return parsed效果:
- 代码审查覆盖率从 40% 提升到 100%
- 安全漏洞发现率提升 3 倍(人工审查经常遗漏疲劳性错误)
- 资深工程师从重复性审查中解放,专注于架构设计
5.4 实战案例三:RAG 知识库问答系统
全栈实现架构:
markdown
┌─────────────────────────────┐
│ 用户提问 │
└──────────────┬──────────────┘
↓
┌──────────────────────────────────────────────────────┐
│ Harness Engineering │
│ ┌─────────────┐ ┌──────────────┐ ┌─────────────┐ │
│ │ 请求验证 │→ │ 限流/鉴权 │→ │ 负载均衡 │ │
│ └─────────────┘ └──────────────┘ └─────────────┘ │
└──────────────────────────┬───────────────────────────┘
↓
┌──────────────────────────────────────────────────────┐
│ Context Engineering │
│ ┌─────────────┐ ┌──────────────┐ ┌─────────────┐ │
│ │ 问题理解/ │ │ 向量检索 │ │ 上下文 │ │
│ │ 查询改写 │→ │ (Milvus) │→ │ 组装优化 │ │
│ └─────────────┘ └──────────────┘ └─────────────┘ │
└──────────────────────────┬───────────────────────────┘
↓
┌──────────────────────────────────────────────────────┐
│ Prompt Engineering │
│ ┌─────────────┐ ┌──────────────┐ ┌─────────────┐ │
│ │ 角色定义 │ │ CoT引导 │ │ 输出格式 │ │
│ │ + 规则约束 │→ │ + 引用要求 │→ │ 约束 │ │
│ └─────────────┘ └──────────────┘ └─────────────┘ │
└──────────────────────────┬───────────────────────────┘
↓
┌─────────────────────────────┐
│ LLM 生成答案 │
└──────────────┬──────────────┘
↓
┌──────────────────────────────────────────────────────┐
│ Harness Engineering │
│ ┌─────────────┐ ┌──────────────┐ ┌─────────────┐ │
│ │ 输出验证 │ │ 引用核验 │ │ 日志记录 │ │
│ │ + 格式化 │→ │ + 事实检查 │→ │ + 反馈收集 │ │
│ └─────────────┘ └──────────────┘ └─────────────┘ │
└──────────────────────────────────────────────────────┘六、综合对比与选型建议
6.1 三维对比矩阵
| 维度 | Prompt Engineering | Context Engineering | Harness Engineering |
|---|---|---|---|
| 核心关注点 | 指令质量与引导方式 | 信息供给与记忆管理 | 系统可靠性与基础设施 |
| 技术门槛 | ⭐⭐(相对较低) | ⭐⭐⭐(中等) | ⭐⭐⭐⭐⭐(较高) |
| 迭代速度 | 快(分钟级调整) | 中(小时级) | 慢(天级/周级) |
| 效果见效时间 | 立竿见影 | 较快 | 长期收益 |
| 成本投入 | 低 | 中(向量DB等) | 高(基础设施) |
| 对模型版本依赖 | 高(需随模型调优) | 中 | 低(相对稳定) |
| 团队角色 | AI工程师/产品经理 | AI工程师/数据工程师 | 后端工程师/SRE |
| 核心工具 | Prompt模板库/DSPy | LangChain/LlamaIndex | LangSmith/Kubernetes |
6.2 不同阶段的优先级建议
🌱 探索期(0-1 个月,POC 阶段)
优先级:Prompt Engineering >>> Context Engineering > Harness Engineering
建议:先用最简单的 Prompt 验证业务价值,不要过早引入复杂基础设施。🚀 成长期(1-6 个月,产品化阶段)
优先级:Context Engineering ≈ Prompt Engineering >> Harness Engineering
建议:随着用例增多,开始引入 RAG 和基础监控,但不要过度工程化。🏭 成熟期(6 个月以上,生产稳定阶段)
优先级:Harness Engineering ≈ Context Engineering > Prompt Engineering
建议:建立完善的可观测性、自动化测试和成本控制体系。6.3 常见误区
误区一:只做 Prompt Engineering,忽视其他两层
结果:系统在 Demo 时效果惊艳,上线后频繁出错、成本失控。
误区二:过度投入 Harness Engineering,忽视 Prompt 质量
结果:系统稳定但效果差,用户体验不佳,"稳定地输出垃圾"。
误区三:认为三者是串行关系,必须依次完成
实际:三者是并行演进的,应该根据当前瓶颈动态调整投入比例。
误区四:Context Engineering = 只是 RAG
实际:Context Engineering 包含记忆管理、对话压缩、多模态上下文等多个维度,RAG 只是其中一部分。
七、结语
Prompt Engineering、Context Engineering 和 Harness Engineering,三者共同构成了大模型应用工程的完整体系:
- Prompt Engineering 是与模型沟通的语言艺术,解决"说什么、怎么说"的问题;
- Context Engineering 是给模型配备的感知系统,解决"看什么、记什么"的问题;
- Harness Engineering 是驾驭模型能力的基础设施,解决"怎么跑、跑多稳"的问题。
在实际项目中,这三者从来不是孤立存在的。一个优秀的 LLM 应用工程师,需要在三个维度上都具备扎实的功底,并能根据项目阶段和业务瓶颈,灵活调整三者的投入比例。
大模型是发动机,Prompt Engineering 是油门,Context Engineering 是导航,Harness Engineering 是整辆车的工程质量。三者缺一,都无法到达目的地。
随着 LLM 能力的持续提升(更长的上下文窗口、更强的工具调用能力、更好的指令遵循),三大工程的边界会不断演化。但无论技术如何发展,让 AI 能力可靠、高效、安全地服务于真实业务,始终是工程师的核心使命。
本文基于 2024-2025 年 LLM 工程实践整理,如有疑问欢迎交流探讨。