无锁
多线程编程中,有lock-free(无锁),wait-free(无等待),blocking(阻塞),Non-blocking(非阻塞)。
阻塞blocking
在阻塞算法中,线程尝试获取一个不可用的资源时会被挂起(即进入阻塞状态),直到资源变为可用。阻塞同步是最简单的同步机制,但可能导致性能问题,因为线程在等待资源时无法执行任何操作。
阻塞状态下,线程被挂起,是在等待,不进行任何操作。
非阻塞 non-blocking
非阻塞算法确保线程在访问共享资源时不会被挂起。如果资源不可用,线程可以决定执行其他操作,比如重试操作或回退。这种方法提高了系统的整体响应性和吞吐量。
如果资源不可用就去做其他的事情,而不是在等待。
无锁lock-free
无锁算法是非阻塞同步策略的一种,它确保至少有一个线程能在有限的步骤中完成其操作,从而在全局上避免了死锁。无锁同步通常依赖于原子操作,如CAS(Compare-And-Swap)。
强调的是 无互斥锁阻塞。所有线程都持续前进,不会因为某个线程持有锁而被挂起。如果更新时发现冲突(如 CAS 失败),线程会通过重试、回退或帮助其他线程完成来解决冲突。
当一个线程占用共享资源,其他线程再去访问这个共享资源时,会发现有冲突,就去处理其他事情了(通常是进行重试)。不保证某个特定线程 能前进,但保证系统整体不会因为任何一个线程的延迟或挂起而完全停滞。
无等待wait-free算法
无等待算法是一种特殊类型的非阻塞同步,它保证所有线程都能在有限的步骤中完成其操作,从而为每个线程提供了最强的进度保障。实现无等待算法非常复杂,通常需要精心设计的数据结构。
无等待一定是无锁,无锁不一定是无等待。
在数据处理程序、实时系统等场景中要使用无锁。
生产者消费者队列
常见的是 MPMC多生产者多消费者队列 和 MPSC多生产者单消费者队列。
底层的数据结构是 数组 或 链表 或 两者混合。
基于数据的队列,处理速度更快,但需要提前分配好内存。
基于链表可以动态增长,但需要频繁申请销毁内存。
基于两者混合,具有两者的有点点,但实现复杂。
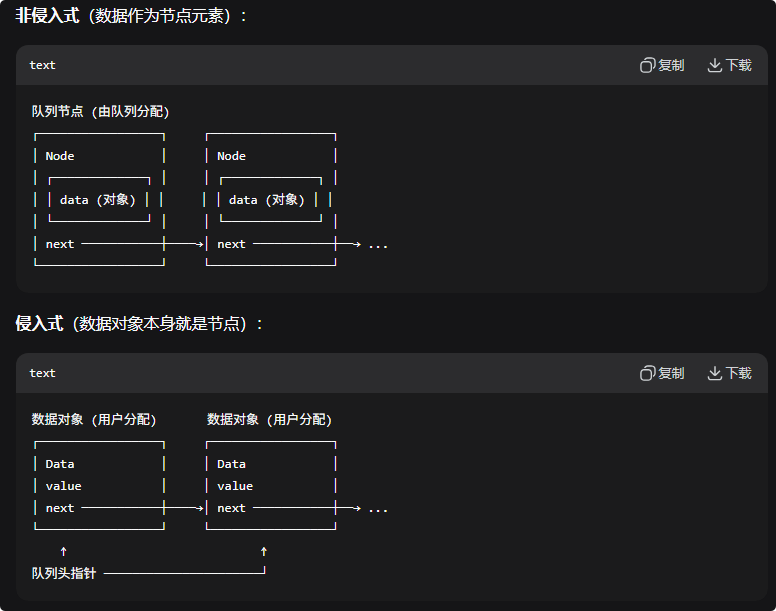
根据链表队列可以分为入侵式 和 非入侵式。
非侵入式:节点的指针存储在队列内部。存放入队列中的是数据对象本身。
侵入式:节点指针存储在数据对象内部。放入队列中的是指向数据对象的指针。
非侵入式是数据对象是队列的一个元素,next指针也是队列的一个元素。侵入式是数据对象就是队列节点,next指针在数据对象内部。
队列长度也可划分为 无界 和 有界。
无界:不设置数量上限,可以一直添加,直到内存耗尽。
有界:设置数量上限,如果达到上限就进行处理。一般为报错、丢弃、覆盖掉老数据。
为 无界 和 有界。
无界:不设置数量上限,可以一直添加,直到内存耗尽。
有界:设置数量上限,如果达到上限就进行处理。一般为报错、丢弃、覆盖掉老数据。