NCBI 就是 National Center for Biotechnology Information,美国 NIH 下面的国家生物技术信息中心 。它的作用可以理解成:一个大型生命科学/生物信息公共平台,提供数据库、网页检索、下载、API 和命令行工具,里面包含基因、基因组、变异、文献、表达数据等很多资源。
你前面看的 ClinVar ,就是 NCBI 旗下的一个数据库。ClinVar 自己说明,数据既可以在网页上看,也可以通过 FTP 下载 ,还可以通过 API 访问。
先区分:NCBI 不是一个单独"数据集",它更像一个"总平台"。里面常见的资源有:
- ClinVar:临床相关变异解释库。
- Gene / Genome / Taxonomy:基因、基因组和物种分类信息。
- GEO:基因表达和功能基因组学数据仓库。
- NCBI Datasets:一个统一的下载入口和工具,适合下载基因、基因组、序列、注释和元数据。
下载链接位于:
https://www.ncbi.nlm.nih.gov/home/download/
直接按照FTP的方式看一下有哪些数据:
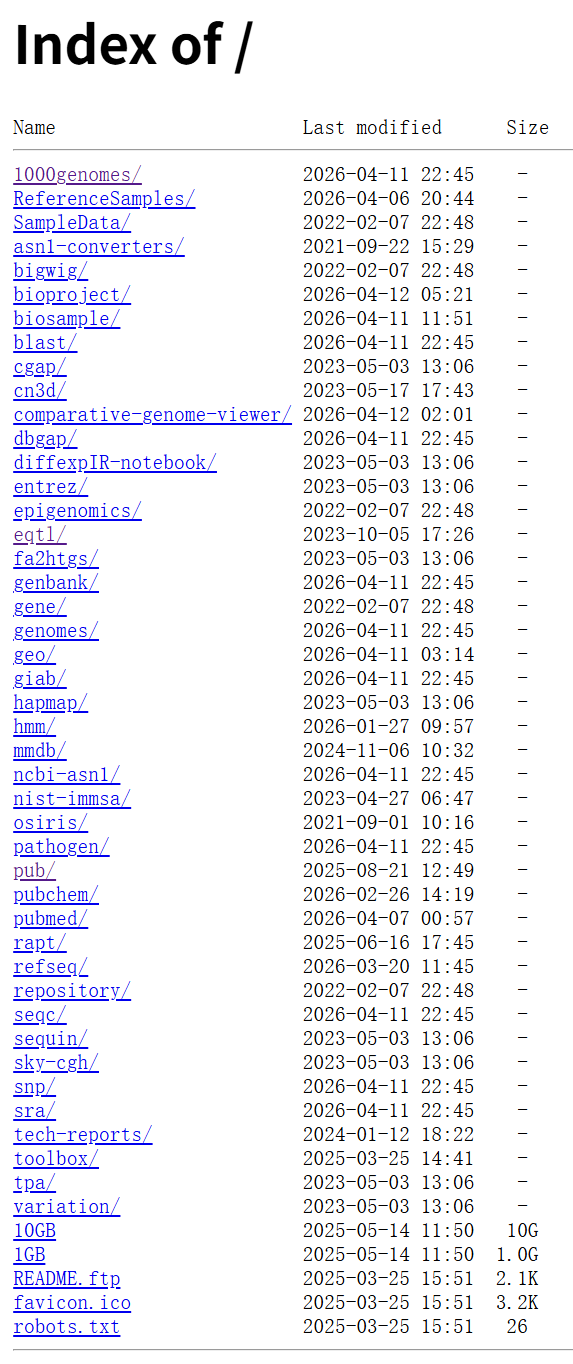
一、你做基因组/变异任务最常会用到的
pub/
这是最常见的公共发布目录 。很多数据库真正给用户批量下载的文件都放在这里。
比如你前面看的 ClinVar VCF,就是在 pub/clinvar/... 下面。它更像"公开发行区"。
snp/
和 dbSNP 相关,主要是已知单核苷酸变异、小变异 等。
如果你想找常见变异资源,这类目录很常见。根目录里它是独立入口。
variation/
这是更泛化的变异类资源目录 。
如果你找的是"变异相关但不一定就是 dbSNP/ClinVar 单一库"的内容,可以看看这里。
genbank/
GenBank 相关的序列数据。通常比 RefSeq 更"原始/更广",是 NCBI 经典序列资源之一。就是 NCBI 的公共核酸序列数据库,收全球提交的 DNA/RNA 序列及其注释;它更像原始大仓库
refseq/
RefSeq 相关,常用于参考序列、转录本、蛋白、注释等。如果你做基因、转录本、蛋白序列任务,这个目录很重要。而 RefSeq 更像整理genbank后的标准参考版
genomes/
和基因组装、物种基因组数据 相关。
如果你要下载某个物种的 genome assembly、参考基因组、注释文件,常会进这里。
gene/
和 NCBI Gene 数据相关。
偏基因层面的整合信息。
1000genomes/
1000 Genomes Project 的数据区。
如果你在找人群遗传变异数据,这个目录就很有代表性。
giab/
GIAB,通常指 Genome in a Bottle 这类高质量 benchmark/reference 样本资源。
做变异检测 benchmark 时很常见。
二、表达、测序原始数据相关
geo/
GEO 数据目录。
GEO 是表达谱、功能基因组学数据仓库,找 RNA-seq、microarray、表观组学实验时经常会用。(NCBI FTP)
sra/
SRA(Sequence Read Archive) ,测序原始 reads 的大仓库。
如果你要原始 FASTQ/BAM/测序运行数据,常常会从这里对应到 SRA 资源。NCBI 官方下载页也专门给了 SRA download 参考。(NCBI FTP)
epigenomics/
表观基因组相关资源。(NCBI FTP)
eqtl/
eQTL 相关资源。
你前面正好问过 eQTL,这个目录名就很直白。(NCBI FTP)
三、项目级元数据
bioproject/
BioProject 数据。
它更像项目层级的"总编号/总入口",把一个研究项目下的样本、测序、组学资源串起来。(NCBI FTP)
biosample/
BioSample 数据。
这是样本层级的元数据,比如样本来自什么组织、什么个体、什么处理条件。(NCBI FTP)
这两个经常一起出现:
-
BioProject:项目级
-
BioSample:样本级
四、文献、检索、结构、化学
pubmed/
PubMed 相关资源。偏文献。(NCBI FTP)
blast/
BLAST 相关数据库或支持文件。
如果你做序列比对,这类目录很常见。(NCBI FTP)
mmdb/
结构相关资源,MMDB 是分子结构数据库方向。(NCBI FTP)
pubchem/
PubChem 化学分子资源。
如果你做化学、小分子、药物信息,这个目录会有用。(NCBI FTP)
五、工具、格式、测试文件
toolbox/
一些下载/处理工具相关内容。(NCBI FTP)
asn1-converters/、ncbi-asn1/
和 NCBI 的 ASN.1 数据格式有关。
一般普通用户不太常直接碰,除非你在处理 NCBI 特定格式。(NCBI FTP)
bigwig/
bigWig 相关资源或示例区。(NCBI FTP)
1GB、10GB
这是测试下载用的大文件,通常用于测速或验证下载链路,不是生物学数据集。看文件名和大小就能判断出来。(NCBI FTP)
README.ftp
根目录说明文件。
通常会介绍 FTP 使用方式或一些约定。(NCBI FTP)
你现在最实用的理解方式
你不用逐个记全部目录,先记这几个就够了:
-
找 ClinVar / 公共发布文件 →
pub/ -
找参考序列/转录本 →
refseq/ -
找 GenBank 序列 →
genbank/ -
找 genome assembly →
genomes/ -
找原始测序数据 →
sra/ -
找表达数据 →
geo/ -
找项目/样本元数据 →
bioproject/、biosample/ -
找已知变异 →
snp/、variation/ -
找 1000 Genomes →
1000genomes/(NCBI FTP)
对你当前方向,最相关的是哪些
你现在做基因组模型、变异、剪接这类任务,通常最值得关注的是:
-
pub/:因为 ClinVar 等常用公开文件常在这里 -
refseq/:拿参考转录本、蛋白、注释 -
genomes//genbank/:拿参考基因组和装配 -
snp//variation/:拿变异资源 -
sra//geo/:拿实验原始数据和表达数据 -
1000genomes/、giab/:拿 benchmark 或人群资源 (NCBI FTP)