背景
日常工作中使用 pdf 文件时,拆分与合并是一个十分常见的操作。
特别是在使用问答形式的 AI 工具时,部分工具可能对 pdf 文件的大小有一定的限制,这时就需要将原来的大 pdf 文件拆分为若干个小文件。
当需要拆分和合并的 pdf 量级较少时,通过一些在线工具或桌面应用就可以很好的解决;但当需要批量处理时,可通过几句简单的 python 代码来实现。
以下基于 python 3.X 环境 + PyPDF2 第三方库,从多个实际使用场景出发,梳理出了一些可直接复制粘贴使用的完整代码及一些常见注意事项。
拆分,包括:逐页拆分、连续页拆分、指定页拆分(可以为非连续页)。
合并,包括:多个合并成一个、在原文件后添加一页。
环境安装
本文所有用法均是基于第三方库 PyPDF2 ,该库可直接通过 pip 命令实现安装。
完整命令如下:
python
pip install PyPDF2需要注意的是:PyPDF2 本身不支持 python 2.X,因此本文的所有用法都是基于 python 3.X 版本。
pdf 拆分
一、逐页拆分
逐页拆分 pdf ,即将原 pdf 中的每一页拆分为单独的 pdf,这种做法较为少用。
可作为了解 PyPDF2 基础用法的参考,复制以下代码,将路径修改为自己需要拆分的 pdf 路径,运行即可。
python
from PyPDF2 import PdfReader, PdfWriter
import os
# 逐页拆分pdf,将pdf中的每一页拆分为单独的pdf
def split_pdf(input_pdf_path, output_dir):
# 创建 PdfReader 对象
reader = PdfReader(input_pdf_path)
# 遍历原 PDF d的每一页,逐页拆分
for page_number in range(len(reader.pages)):
output_path = os.path.join(output_dir, f"page_{page_number}.pdf")
writer = PdfWriter()
writer.add_page(reader.pages[page_number])
with open(output_path, "wb") as output_file:
writer.write(output_file)
print(f"Page {page_number + 1} saved to {output_path}")
if __name__=="__main__":
# 需要拆分的PDF完整路径
input_pdf = 'data/test.pdf'
# 逐页拆分后每个单独PDF保存的文件夹路径,注意是文件夹的路径
output_file = 'data/'
split_pdf(input_pdf,output_file)上述代码,以 test.pdf 为例,运行后的结果如下图:
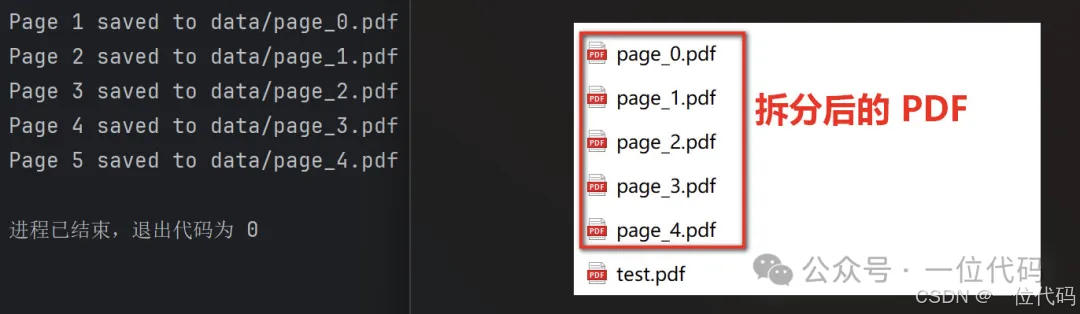
二、连续页拆分
连续页拆分,即提取原 pdf 中连续的几页。
如:原 test.pdf 中一共有 5 页,需要将第 2 页、第 3 页提取出来作为一个新的 pdf 文件。完整代码如下。
python
from PyPDF2 import PdfReader, PdfWriter
import os
# 指定连续页拆分pdf
def split_page_pdf(input_pdf_path, output_pdf_path,start_num,end_num):
# 创建 PdfReader 对象
reader = PdfReader(input_pdf_path)
# 创建 PdfWriter 对象
writer = PdfWriter()
# 指定连续的页码
for page_number in range(start_num,end_num):
writer.add_page(reader.pages[page_number])
# 保存到新pdf
with open(output_pdf_path, "wb") as output_file:
writer.write(output_file)
if __name__=="__main__":
# 需要拆分的PDF完整路径
input_pdf = 'data/test.pdf'
# 拆分PDF保存的完整路径
output_pdf = 'data/test1.pdf'
split_page_pdf(input_pdf,output_pdf,1,3)复制上述代码,将文件路径和需要提取的连续页码修改为自己需要的即可。
需要注意的是:代码中的页码从 0 开始,区间为左闭右开。如上面的【1,3】中的 1 代表的是第 2 页。
三、指定页拆分
指定页拆分,即是提取原 pdf 中的其中几页,不一定是连续的页。
如:原 test.pdf 中一共有 5 页,需要将第 1 页、第 3 页、第 5 页提取出来作为一个新的 pdf 文件。完整代码如下:
python
from PyPDF2 import PdfReader, PdfWriter
# 指定页拆分pdf
def split_page_pdf(input_pdf_path, output_pdf_path,page_list):
# 创建 PdfReader 对象
reader = PdfReader(input_pdf_path)
# 创建 PdfWriter 对象
writer = PdfWriter()
for page_number in page_list:
writer.add_page(reader.pages[page_number])
# 保存到新pdf
with open(output_pdf_path, "wb") as output_file:
writer.write(output_file)
if __name__=="__main__":
# 需要拆分的PDF完整路径
input_pdf = 'data/test.pdf'
# 拆分PDF保存的完整路径
output_pdf = 'data/test2.pdf'
# 指定需要的pdf页码列表
page_list = [0, 2, 4]
split_page_pdf(input_pdf,output_pdf,page_list)复制上述代码,将文件路径和需要提取的指定页的页码修改为自己需要的即可。
需要注意的是:代码中的页码从 0 开始。如上面的【0,2,4】,分别指的是第 1、3、5 页。
pdf 合并
相对拆分来说,pdf 合并的场景较少一点,"多个合并成一个"和"在原文件后添加一页"(可视为 2 个 pdf 的合并)的使用方式是一样的。
完整代码如下。复制上述代码,将需要合并的 pdf 文件路径和保存的合并后的文件路径改为自己需要的即可。
python
from PyPDF2 import PdfMerger
# 合并pdf
def merger_pdf(input_pdf,output_filename):
merger = PdfMerger()
for pdf_info in input_pdf:
merger.append(pdf_info)
with open(output_filename, "wb") as f_out:
merger.write(f_out)
print('合并完成!')
if __name__=="__main__":
# 需要合并的pdf文件完整路径列表
pdf_list = ['data/page_0.pdf','data/page_4.pdf']
# 传入需要合并的pdf文件完整路径列表,和合并后的文件路径及名称
merger_pdf(pdf_list,'data/page_test.pdf')以上就是基于 python 3.X + PyPDF2 的常见拆分与合并使用代码块,可供参考。