实验三 - 第十二周实验窗口函数分析
验证数据是否已加载
在Hive CLI中执行以下命令确认数据存在:
sql
-- 查看tbDate数据
SELECT * FROM tbDate LIMIT 5;
-- 查看tbStock数据
SELECT * FROM tbStock LIMIT 5;
-- 查看tbStockDetail数据
SELECT * FROM tbStockDetail LIMIT 5;
-- 统计各表记录数
SELECT 'tbDate' AS table_name, COUNT(*) AS cnt FROM tbDate
UNION ALL
SELECT 'tbStock', COUNT(*) FROM tbStock
UNION ALL
SELECT 'tbStockDetail', COUNT(*) FROM tbStockDetail;方式1:通过Java JDBC执行(集成到现有代码)
在你的HiveJDBCExample.java中添加新的方法来执行窗口函数查询。以下是完整的增强版代码:
java
package com.example;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class HiveJDBCExample {
public static void main(String[] args) {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
// 1. 加载驱动
Class.forName("org.apache.hive.jdbc.HiveDriver");
// 2. 获取连接
conn = DriverManager.getConnection(
"jdbc:hive2://192.168.255.145:10000/default;auth=noSasl",
"aaaa",
"aaaa"
);
System.out.println("Hive 连接成功");
stmt = conn.createStatement();
stmt.execute("USE mytest");
System.out.println("已切换到数据库 mytest");
// ============================================
// 窗口函数分析实验
// ============================================
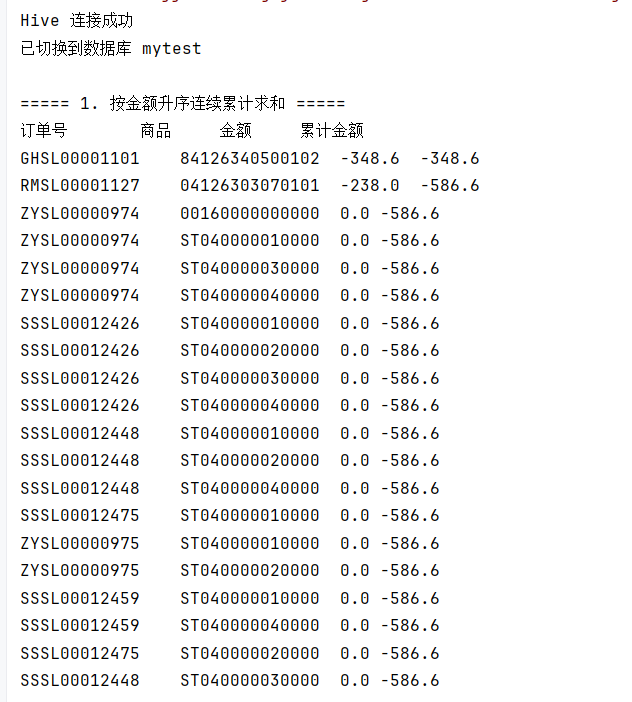
// 1. 窗口聚合函数 - 按金额升序连续累计求和
System.out.println("\n===== 1. 按金额升序连续累计求和 =====");
String sql1 = "SELECT order_id, product, amount, " +
"SUM(amount) OVER(ORDER BY amount) AS cumulative_sum " +
"FROM tbStockDetail " +
"ORDER BY amount LIMIT 20";
rs = stmt.executeQuery(sql1);
System.out.println("订单号\t\t商品\t\t金额\t\t累计金额");
while (rs.next()) {
System.out.println(rs.getString("order_id") + "\t" +
rs.getString("product") + "\t" +
rs.getDouble("amount") + "\t" +
rs.getDouble("cumulative_sum"));
}
rs.close();
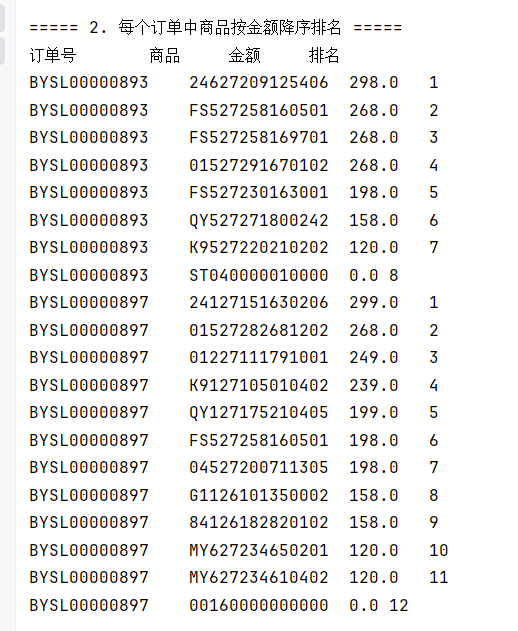
// 2. 排名函数 - 每个订单中商品按金额降序排名
System.out.println("\n===== 2. 每个订单中商品按金额降序排名 =====");
String sql2 = "SELECT order_id, product, amount, " +
"ROW_NUMBER() OVER(PARTITION BY order_id ORDER BY amount DESC) AS rank_num " +
"FROM tbStockDetail " +
"ORDER BY order_id, rank_num LIMIT 20";
rs = stmt.executeQuery(sql2);
System.out.println("订单号\t\t商品\t\t金额\t\t排名");
while (rs.next()) {
System.out.println(rs.getString("order_id") + "\t" +
rs.getString("product") + "\t" +
rs.getDouble("amount") + "\t" +
rs.getInt("rank_num"));
}
rs.close();
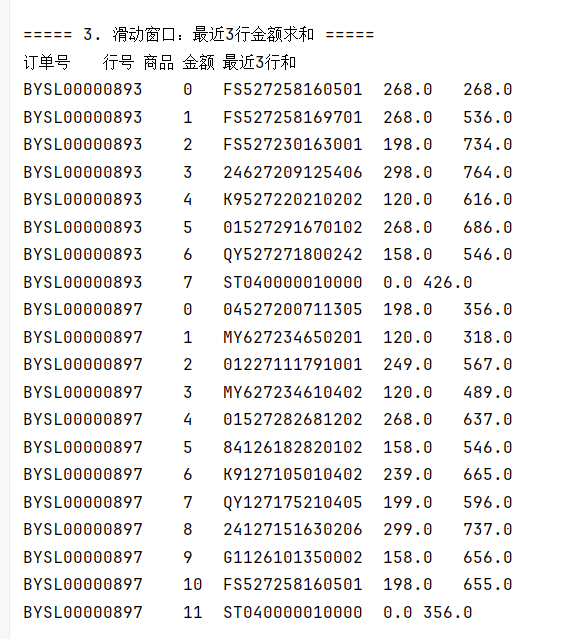
// 3. 滑动窗口 - 最近3行金额求和
System.out.println("\n===== 3. 滑动窗口:最近3行金额求和 =====");
String sql3 = "SELECT order_id, line_no, product, amount, " +
"SUM(amount) OVER(ORDER BY order_id, line_no ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS sum_last_3 " +
"FROM tbStockDetail LIMIT 20";
rs = stmt.executeQuery(sql3);
System.out.println("订单号\t行号\t商品\t金额\t最近3行和");
while (rs.next()) {
System.out.println(rs.getString("order_id") + "\t" +
rs.getInt("line_no") + "\t" +
rs.getString("product") + "\t" +
rs.getDouble("amount") + "\t" +
rs.getDouble("sum_last_3"));
}
rs.close();
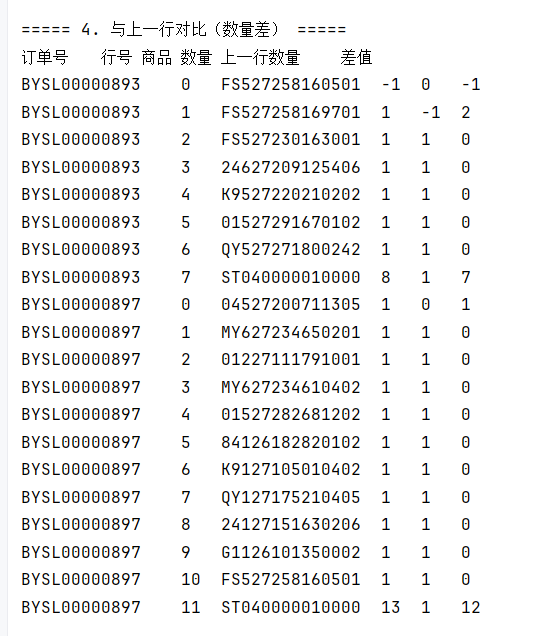
// 4. 对比分析 - 与上一行数量差
System.out.println("\n===== 4. 与上一行对比(数量差) =====");
String sql4 = "SELECT order_id, line_no, product, quantity, " +
"LAG(quantity, 1, 0) OVER(PARTITION BY order_id ORDER BY line_no) AS prev_quantity, " +
"quantity - LAG(quantity, 1, 0) OVER(PARTITION BY order_id ORDER BY line_no) AS diff " +
"FROM tbStockDetail LIMIT 20";
rs = stmt.executeQuery(sql4);
System.out.println("订单号\t行号\t商品\t数量\t上一行数量\t差值");
while (rs.next()) {
System.out.println(rs.getString("order_id") + "\t" +
rs.getInt("line_no") + "\t" +
rs.getString("product") + "\t" +
rs.getInt("quantity") + "\t" +
rs.getInt("prev_quantity") + "\t" +
rs.getInt("diff"));
}
rs.close();
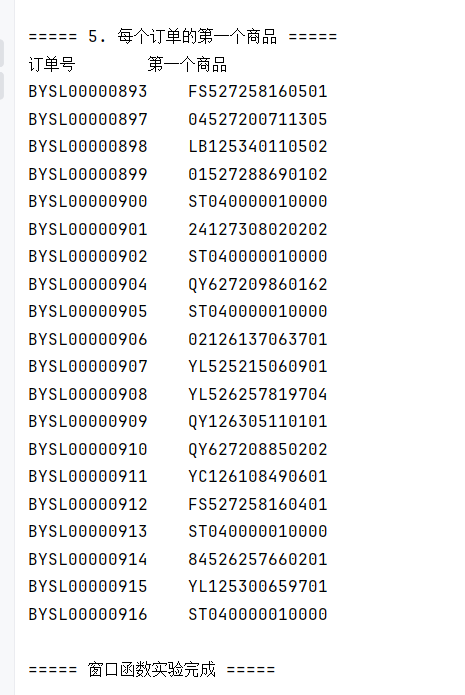
// 5. 获取每组第一个商品
System.out.println("\n===== 5. 每个订单的第一个商品 =====");
String sql5 = "SELECT DISTINCT order_id, " +
"FIRST_VALUE(product) OVER(PARTITION BY order_id ORDER BY line_no) AS first_product " +
"FROM tbStockDetail ORDER BY order_id LIMIT 20";
rs = stmt.executeQuery(sql5);
System.out.println("订单号\t\t第一个商品");
while (rs.next()) {
System.out.println(rs.getString("order_id") + "\t" +
rs.getString("first_product"));
}
rs.close();
System.out.println("\n===== 窗口函数实验完成 =====");
} catch (Exception e) {
e.printStackTrace();
} finally {
try { if (rs != null) rs.close(); } catch (Exception e) {}
try { if (stmt != null) stmt.close(); } catch (Exception e) {}
try { if (conn != null) conn.close(); } catch (Exception e) {}
}
}
}
本实验完成
方式2:通过Hive CLI执行
步骤1:进入Hive CLI
bash
# 在虚拟机终端执行
hive步骤2:切换到你的数据库
sql
USE mytest;
SHOW TABLES; -- 确认三张表存在步骤3:执行所有窗口函数SQL
复制以下SQL语句,逐条在Hive CLI中执行并观察结果:
sql
-- ============================================
-- 一、窗口聚合函数
-- ============================================
-- 1) 对tbStockDetail表所有行求金额总和
SELECT SUM(amount) OVER() AS total_amount
FROM tbStockDetail
LIMIT 1;
-- 2) 按金额升序进行连续累计求和
SELECT order_id, product, amount,
SUM(amount) OVER(ORDER BY amount) AS cumulative_sum
FROM tbStockDetail
ORDER BY amount;
-- 3) 按商品分组求金额总和
SELECT DISTINCT product,
SUM(amount) OVER(PARTITION BY product) AS sum_by_product
FROM tbStockDetail;
-- 4) 按商品分组并按行号累积求和(每个订单内按行号累加)
SELECT order_id, line_no, product, amount,
SUM(amount) OVER(PARTITION BY order_id ORDER BY line_no) AS cumulative_in_order
FROM tbStockDetail
ORDER BY order_id, line_no;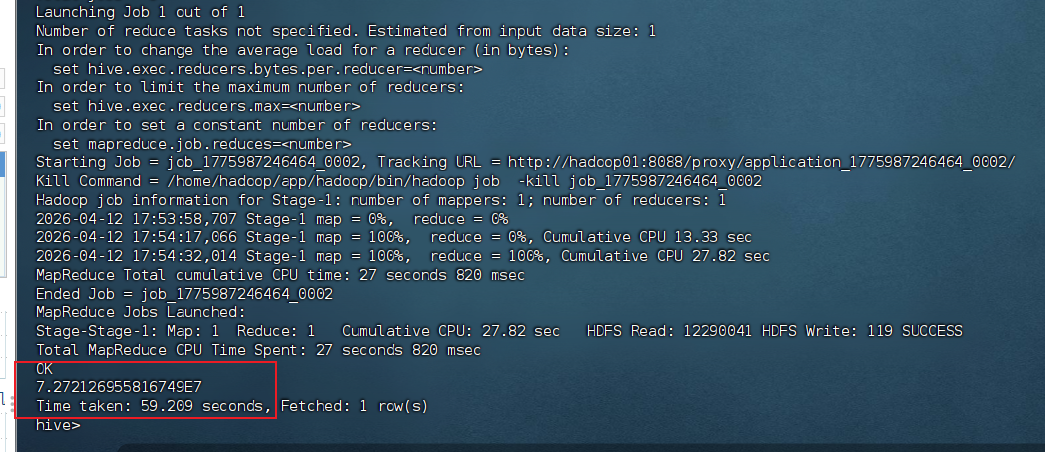
sql
-- ============================================
-- 二、窗口表达式(边界控制)
-- ============================================
-- 1) 最近3行的金额求和(滑动窗口:当前行+前2行)
SELECT order_id, line_no, product, amount,
SUM(amount) OVER(ORDER BY order_id, line_no ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS sum_last_3
FROM tbStockDetail;
-- 2) 从当前行开始直到订单末尾金额求和
SELECT order_id, line_no, product, amount,
SUM(amount) OVER(PARTITION BY order_id ORDER BY line_no ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS sum_to_end
FROM tbStockDetail
ORDER BY order_id, line_no;
sql
-- ============================================
-- 三、排名类窗口函数
-- ============================================
-- 1) 每个订单中商品按金额降序排名
SELECT order_id, product, amount,
ROW_NUMBER() OVER(PARTITION BY order_id ORDER BY amount DESC) AS row_num,
RANK() OVER(PARTITION BY order_id ORDER BY amount DESC) AS rank_num,
DENSE_RANK() OVER(PARTITION BY order_id ORDER BY amount DESC) AS dense_rank_num
FROM tbStockDetail
ORDER BY order_id, amount DESC;
-- 2) 将明细分为4组(NTILE)
SELECT order_id, product, amount,
NTILE(4) OVER(ORDER BY amount) AS quartile
FROM tbStockDetail;
sql
-- ============================================
-- 四、分析类窗口函数(对比分析)
-- ============================================
-- 1) 与上一行对比(数量差)
SELECT order_id, line_no, product, quantity,
LAG(quantity, 1, 0) OVER(PARTITION BY order_id ORDER BY line_no) AS prev_quantity,
quantity - LAG(quantity, 1, 0) OVER(PARTITION BY order_id ORDER BY line_no) AS diff_with_prev
FROM tbStockDetail
ORDER BY order_id, line_no;
-- 2) 获取每组中第一个商品
SELECT DISTINCT order_id,
FIRST_VALUE(product) OVER(PARTITION BY order_id ORDER BY line_no) AS first_product,
FIRST_VALUE(amount) OVER(PARTITION BY order_id ORDER BY line_no) AS first_amount
FROM tbStockDetail
ORDER BY order_id;
sql
-- ============================================
-- 扩展1:联表分析(按location分区聚合)
-- ============================================
SELECT s.location, d.year, d.quarter,
SUM(detail.amount) OVER(PARTITION BY s.location, d.year, d.quarter) AS location_quarter_sales,
RANK() OVER(PARTITION BY d.year, d.quarter ORDER BY SUM(detail.amount) DESC) AS rank_in_quarter
FROM tbStockDetail detail
JOIN tbStock s ON detail.order_id = s.order_id
JOIN tbDate d ON s.date_id = d.date_id
GROUP BY s.location, d.year, d.quarter, detail.amount;
-- ============================================
-- 扩展2:按季度、月份汇总(使用tbDate表)
-- ============================================
-- 按月份统计销售额
SELECT d.year, d.month,
SUM(detail.amount) AS monthly_sales,
SUM(SUM(detail.amount)) OVER(PARTITION BY d.year ORDER BY d.month) AS year_cumulative
FROM tbStockDetail detail
JOIN tbStock s ON detail.order_id = s.order_id
JOIN tbDate d ON s.date_id = d.date_id
GROUP BY d.year, d.month
ORDER BY d.year, d.month;需要回答的思考题:
- Hive窗口函数与传统聚合函数的核心差异是什么?
- 传统聚合函数会将多行压缩为一行
- 窗口函数保留每一行,同时显示聚合结果
- 为什么ROWS BETWEEN能更灵活地控制窗口?
- 可以精确指定窗口的起始和结束位置
- 支持滑动窗口、累计窗口等多种模式
- 使用LAG/LEAD有哪些常见的数据分析场景?
- 环比分析(与上一期对比)
- 计算增长率/下降率
- 用户行为序列分析
- 如何结合实际业务设计高性能的窗口分析逻辑?
- 合理使用PARTITION BY减少数据范围
- 避免不必要的ORDER BY
- 使用合适的窗口边界
第十三周实验
步骤1:在IDEA中创建新的Maven模块或项目
在你的HiveJDBCExample同一个项目中,添加UDF/UDAF/UDTF的Java类。
步骤2:编写三个函数(完整代码)
① UDF - StrToMapUDF.java
java
package com.example.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
import java.util.HashMap;
import java.util.Map;
public class StrToMapUDF extends UDF {
public Map<String, String> evaluate(Text input) {
if (input == null) {
return null;
}
String str = input.toString();
Map<String, String> result = new HashMap<>();
String[] pairs = str.split(",");
for (String pair : pairs) {
String[] kv = pair.split("=");
if (kv.length == 2) {
result.put(kv[0], kv[1]);
}
}
return result;
}
}② UDAF - ArraySumUDAF.java
java
package com.example.udaf;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import java.util.List;
public class ArraySumUDAF extends UDAF {
public static class Evaluator implements UDAFEvaluator {
private long sum;
public Evaluator() {
super();
init();
}
public void init() {
sum = 0;
}
public boolean iterate(List<Integer> array) {
if (array != null) {
for (Integer num : array) {
if (num != null) {
sum += num;
}
}
}
return true;
}
public long terminatePartial() {
return sum;
}
public boolean merge(long otherSum) {
sum += otherSum;
return true;
}
public Long terminate() {
return sum;
}
}
}③ UDTF - Explode3x3UDTF.java
java
package com.example.udtf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;
public class Explode3x3UDTF extends GenericUDTF {
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
List<String> fieldNames = new ArrayList<>();
List<ObjectInspector> fieldOIs = new ArrayList<>();
fieldNames.add("col1");
fieldNames.add("col2");
fieldNames.add("col3");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
if (args[0] == null) {
return;
}
String input = args[0].toString();
String[] numbers = input.split(",");
for (int i = 0; i < 3; i++) {
String[] row = new String[3];
for (int j = 0; j < 3; j++) {
int index = i * 3 + j;
if (index < numbers.length) {
row[j] = numbers[index];
} else {
row[j] = null;
}
}
forward(row);
}
}
@Override
public void close() throws HiveException {}
}
步骤3:配置pom.xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>hive-udf-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<!-- Hive Exec - UDF开发必需 -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.10</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Shade插件:打包并排除签名文件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>步骤4:打包JAR
在IDEA中:
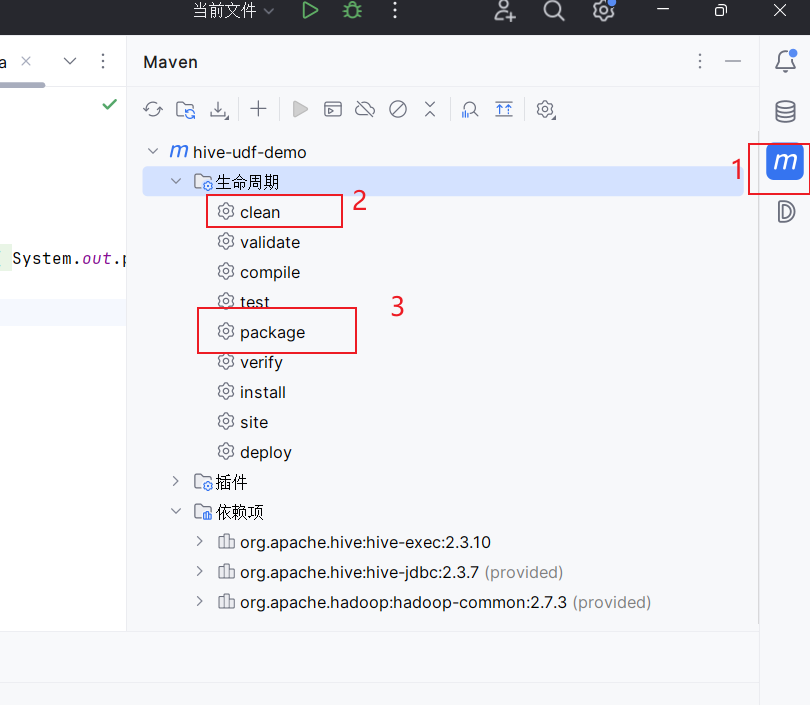
- 右侧 Maven → Lifecycle →
clean→ 然后package
或在终端:
bash
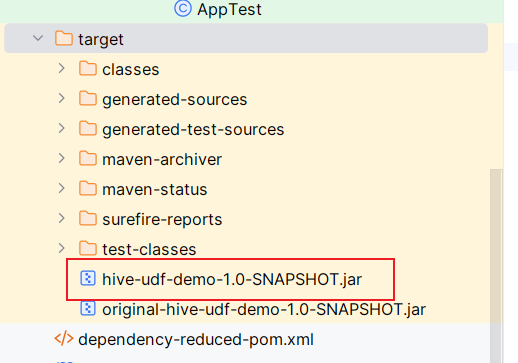
mvn clean package步骤5:上传JAR到虚拟机
bash
# 在虚拟机中创建目录
mkdir -p /home/hadoop/udf_jar
# 将JAR文件上传(从宿主机)
scp target/hive-udf-demo-1.0-SNAPSHOT.jar hadoop@192.168.255.145:/home/hadoop/udf_jar/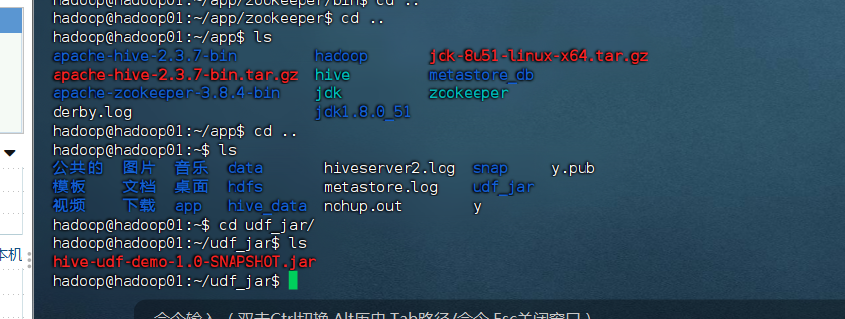
步骤6:在Hive中注册并使用函数
进入Hive CLI:
sql
-- 1. 添加JAR
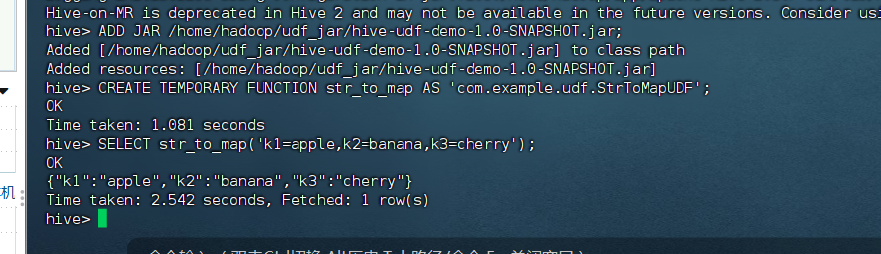
ADD JAR /home/hadoop/udf_jar/hive-udf-demo-1.0-SNAPSHOT.jar;
-- 2. 注册UDF
CREATE TEMPORARY FUNCTION str_to_map AS 'com.example.udf.StrToMapUDF';
-- 3. 测试UDF
SELECT str_to_map('k1=apple,k2=banana,k3=cherry');
-- 期望输出: {"k1":"apple","k2":"banana","k3":"cherry"}
-- 4. 注册UDAF
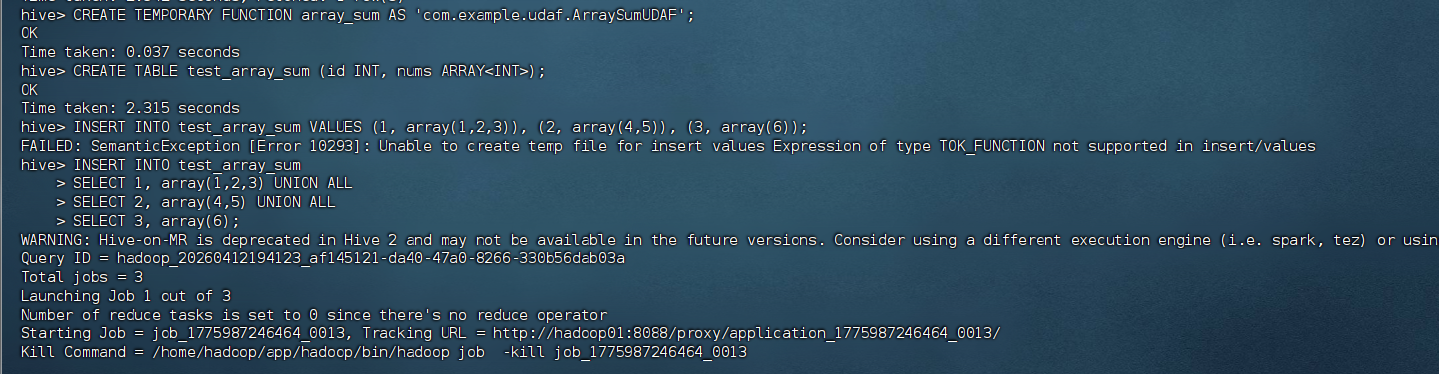
CREATE TEMPORARY FUNCTION array_sum AS 'com.example.udaf.ArraySumUDAF';
-- 5. 创建测试表并测试UDAF
CREATE TABLE test_array_sum (id INT, nums ARRAY<INT>);
INSERT INTO test_array_sum
SELECT 1, array(1,2,3) UNION ALL
SELECT 2, array(4,5) UNION ALL
SELECT 3, array(6);
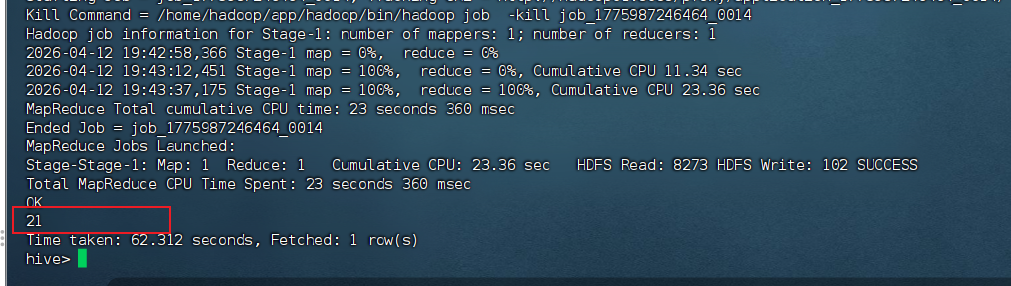
SELECT array_sum(nums) FROM test_array_sum;
-- 期望输出: 21
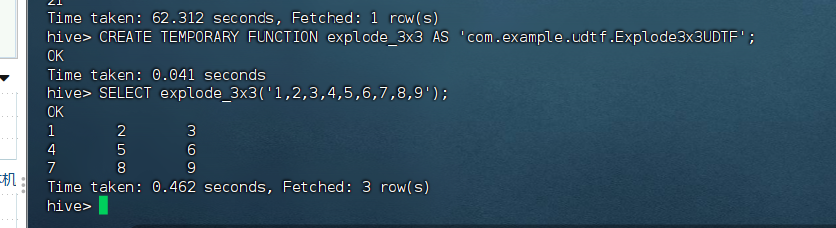
-- 6. 注册UDTF///
CREATE TEMPORARY FUNCTION explode_3x3 AS 'com.example.udtf.Explode3x3UDTF';
-- 7. 测试UDTF
SELECT explode_3x3('1,2,3,4,5,6,7,8,9');
-- 期望输出:
-- 1 2 3
-- 4 5 6
-- 7 8 9